- 수치형 데이터는 산점도나 선 그래프를 이용하면 보기 좋게 표현할 수 있다.
scatter plot
- 산점도 그래프 예제
import pandas as pd
import seaborn as sns
tips = sns.load_dataset("tips")
df = pd.DataFrame(tips)
sns.scatterplot(data=df , x='total_bill', y='tip', palette="ch:r=-.2,d=.3_r")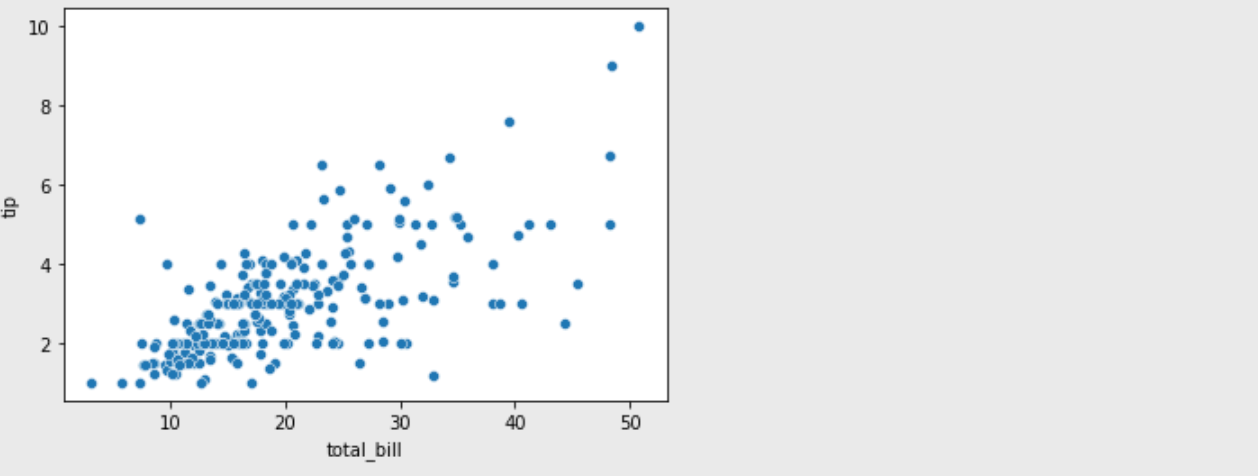
sns.scatterplot(data=df , x='total_bill', y='tip', hue='day')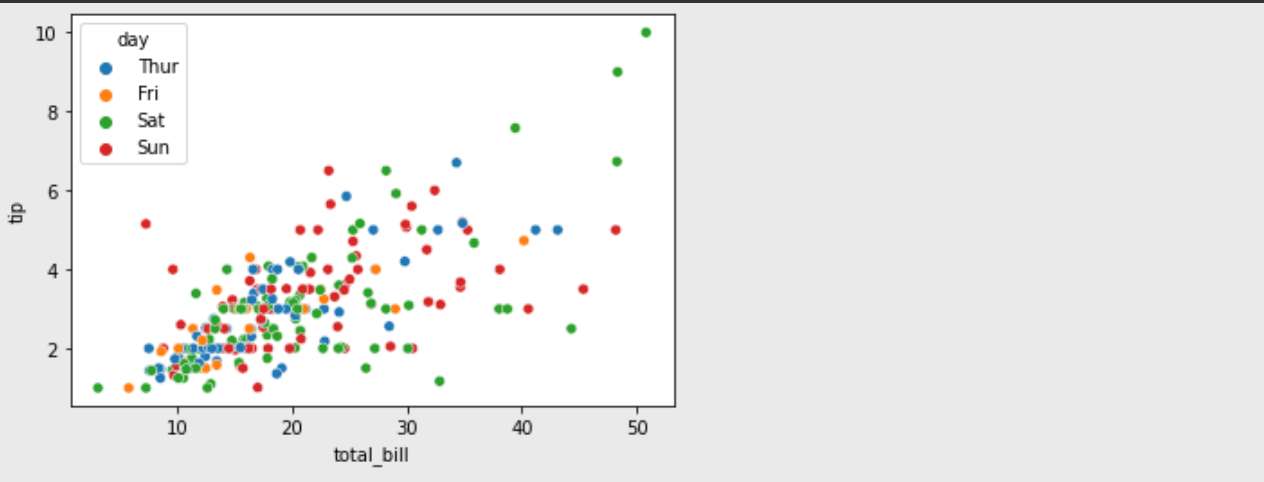
line graph
- 선 그래프 예제
tips()데이터 대신 numpy의 랜덤 함수를 사용한다.
import matplotlib.pyplot as plt
import numpy as np
# np.random.randn 함수는 표준 정규분포에서 난수를 생성
# cumsum()은 누적합을 구하는 함수
plt.plot(np.random.randn(50).cumsum())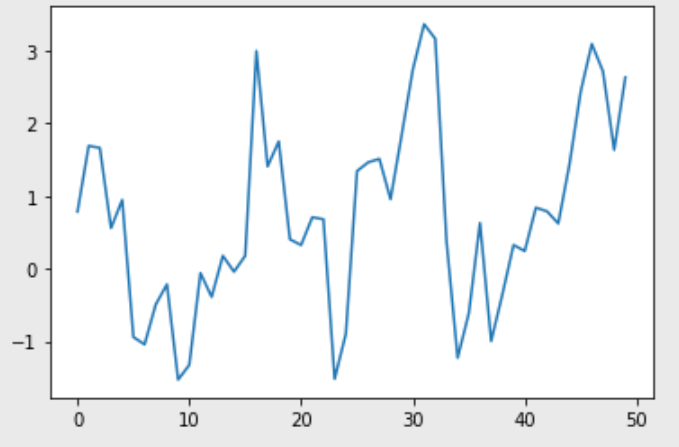
seaborn을 활용해서 그릴 수도 있다.
x = np.linspace(0, 10, 100)
sns.lineplot(x=x, y=np.sin(x))
sns.lineplot(x=x, y=np.cos(x))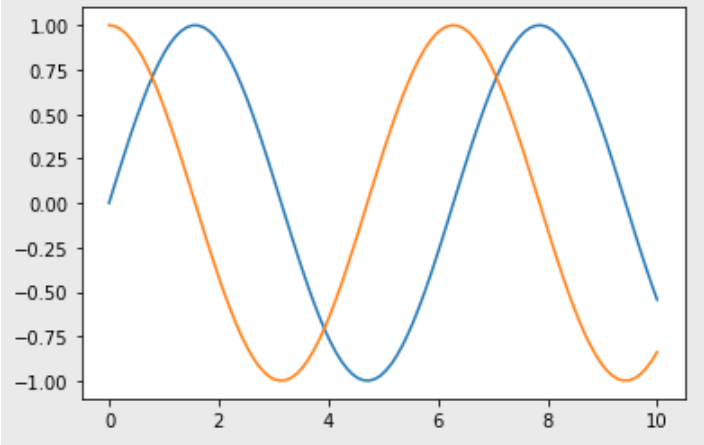
histogram
-
히스토그램은 도수분포표를 그래프로 나타낸 것이다.
즉, 히스토그램을 통해 전체 데이터의 분포 상황을 직관적으로 파악할 수 있다. -
가로축(계급): 변수의 구간, bin (or bucket)
세로축(도수): 빈도수, frequency
#그래프 데이터
mu1, mu2, sigma = 100, 130, 15
x1 = mu1 + sigma*np.random.randn(10000)
x2 = mu2 + sigma*np.random.randn(10000)
# 축 그리기
fig = plt.figure()
ax1 = fig.add_subplot(1,1,1)
# 그래프 그리기
# bins는 x값을 총 50개 구간으로 나눔
patches = ax1.hist(x1, bins=50, density=False)
patches = ax1.hist(x2, bins=50, density=False, alpha=0.5)
# x축의 눈금을 아래 표시
ax1.xaxis.set_ticks_position('bottom')
# y축의 눈금을 왼쪽에 표시
ax1.yaxis.set_ticks_position('left')
# 라벨, 타이틀 달기
plt.xlabel('Bins')
plt.ylabel('Number of Values in Bin')
ax1.set_title('Two Frequency Distributions')
plt.show()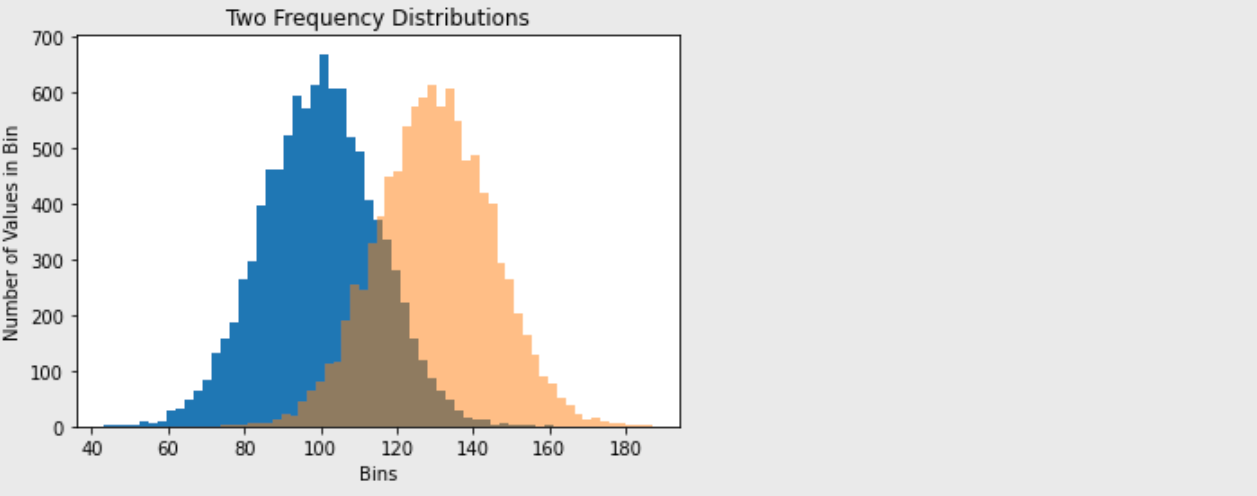
kernel density estimation
kde()메소드를 사용하면 확률 밀도 그래프를 표현할 수 있다.
# 앞에서 불러왔던 tips 데이터를 사용
sns.histplot(df['total_bill'], label = "total_bill")
# legend()를 이용하여 label을 표시
sns.histplot(df['tip'], label = "tip").legend()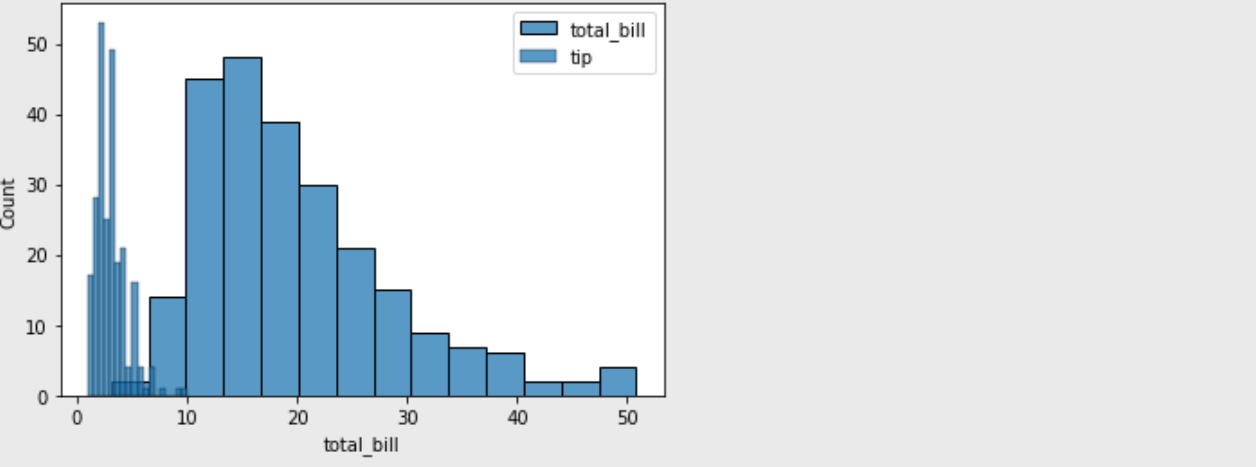
# 전체 결제 금액 대비 팁의 비율
df['tip_pct'] = df['tip'] / df['total_bill']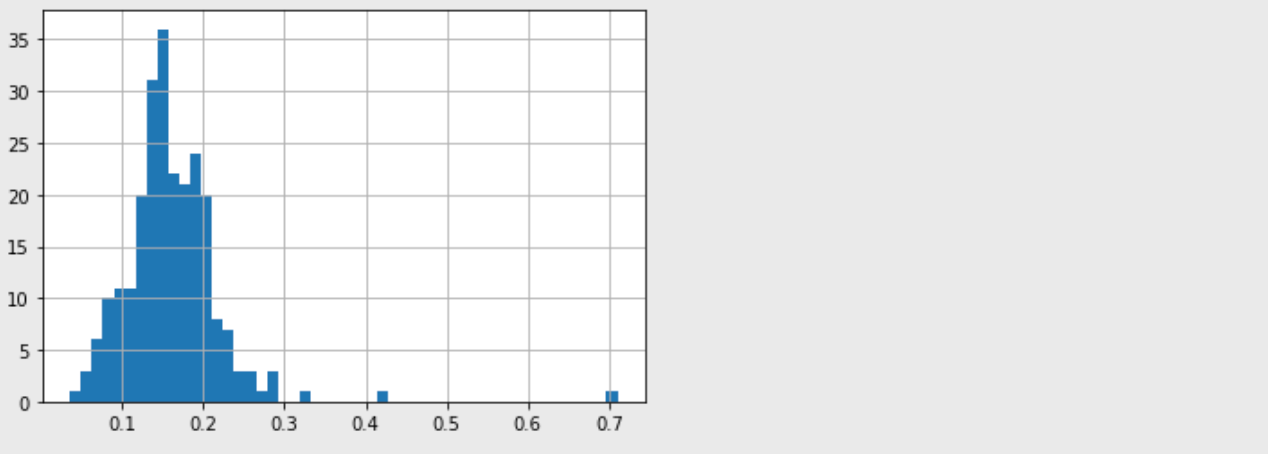
# kde 그래프
df['tip_pct'].plot(kind='kde')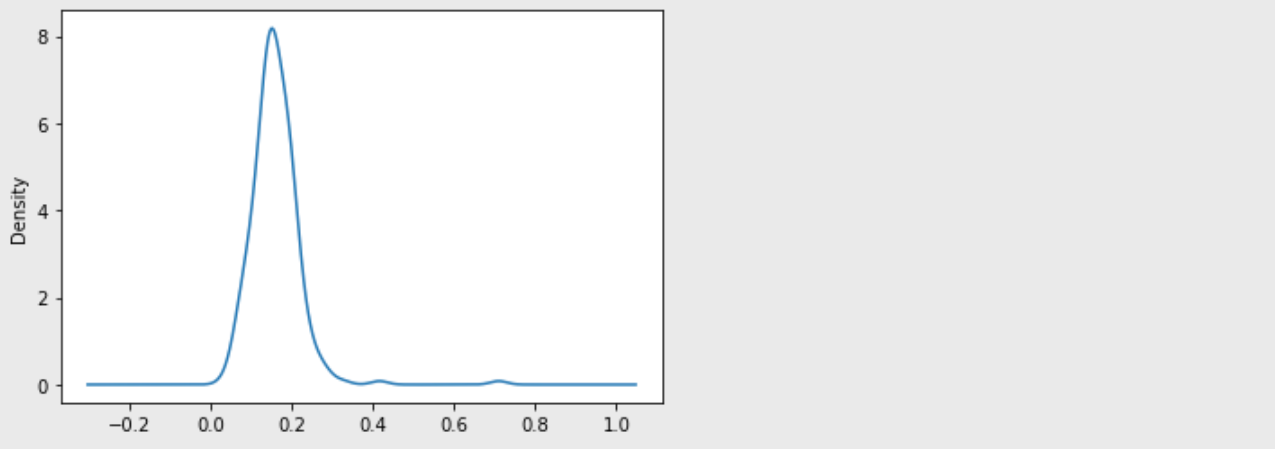
- 일반적으로 밀도 그래프에 커널
kernel메소드를 섞어서 위와 같이 그린다.
그러면 가우시안(정규분포)으로 나타낼 수 있게 된다.

재미있게 살고 싶은 대학원생