
- 전체보기(44)
- PostgreSQL(39)
- DBA(11)
- sql(8)
- Optimizer(5)
- monitoring(4)
- log(3)
- oracle(3)
- Database(3)
- vacuum(3)
- BOAZ(3)
- PerformanceMonitoring(2)
- deepdive(2)
- Index(2)
- DBMS(2)
- opensource(2)
- extension(2)
- aws(2)
- HammerDB(1)
- SQLMonitoring(1)
- pg_cron(1)
- Uptrace(1)
- oralce(1)
- features(1)
- replication(1)
- &&(1)
- query(1)
- Partitioning(1)
- supabase(1)
- pmf(1)
- backup(1)
- pdf(1)
- PEV(1)
- gset(1)
- Query_Optimizer(1)
- cdf(1)
- prometheus(1)
- AI(1)
- Grafana(1)
- dead tuple(1)
- apm(1)
- 통계(1)
- e(1)
- get_ddl(1)
- group by(1)
- Anonymization(1)
PMF, PDF, CDF 정리
이산형 확률 변수는 특정 값들이 분리되어 있는 경우를 말하며, 셀 수 있는 유한 개 또는 무한 개의 값을 가질 수 있습니다. 예를 들어, 주사위를 굴려 나오는 값 ( X )는 1, 2, 3, 4, 5, 6과 같은 개별적인 값으로 구성되므로 이산형 확률 변수입니다.
양자화란?
양자화(Quantization)는 딥러닝 모델의 크기를 줄이고 계산 효율성을 높이는 기술입니다. 원래 딥러닝 모델은 부동소수점(32비트 또는 16비트) 데이터를 사용하지만, 양자화를 통해 이 데이터를 정수(8비트 또는 4비트 등)로 변환합니다. 이를 통해 모델이 더 적
PostgreSQL GROUP BY 최적화: 열 순서와 성능 최적화 방법
데이터베이스 작업에서 GROUP BY 절의 성능은 대규모 데이터셋에서 중요한 영향을 미칩니다. PostgreSQL은 데이터를 그룹화하거나 정렬할 때, 정렬 순서에 따라 쿼리의 속도와 자원 소모량이 달라질 수 있습니다. PostgreSQL 사용자는 종종 데이터를 다양한
PostgreSQL Dead Tuple 완벽 이해: Duplicate Key와 제약 조건 에러의 숨겨진 차이
PostgreSQL에서 Dead Tuple은 DELETE나 UPDATE에 의해 생성된다고 많이 알려져 있습니다. 하지만 놀랍게도, Duplicate Key 에러에서도 Dead Tuple이 발생하는 반면, 자릿수 초과나 도메인 제약 조건 위반에서는 Dead Tuple이

PostgreSQL B-Tree 인덱스의 장단점과 관리 방법
PostgreSQL은 효율적인 데이터 검색을 위해 인덱스를 사용하며, 그 중 가장 많이 사용되는 인덱스 유형은 B-Tree 인덱스입니다. 이 글에서는 PostgreSQL B-Tree 인덱스의 기본 개념과 장단점, 그리고 이를 관리하는 방법을 초보자도 쉽게 이해할 수 있
PL/SQL vs PL/pgSQL: 오라클과 PostgreSQL의 절차적 언어 비교 가이드
PL/SQL은 Oracle 데이터베이스 내에서 비즈니스 로직을 구현하기 위한 강력한 언어입니다. SQL의 기능을 확장하여 오류 처리, 트랜잭션 관리 및 조건부 논리를 추가할 수 있도록 설계되었습니다.PL/SQL의 주요 특징:고급 오류 처리: NO_DATA_FOUND 및
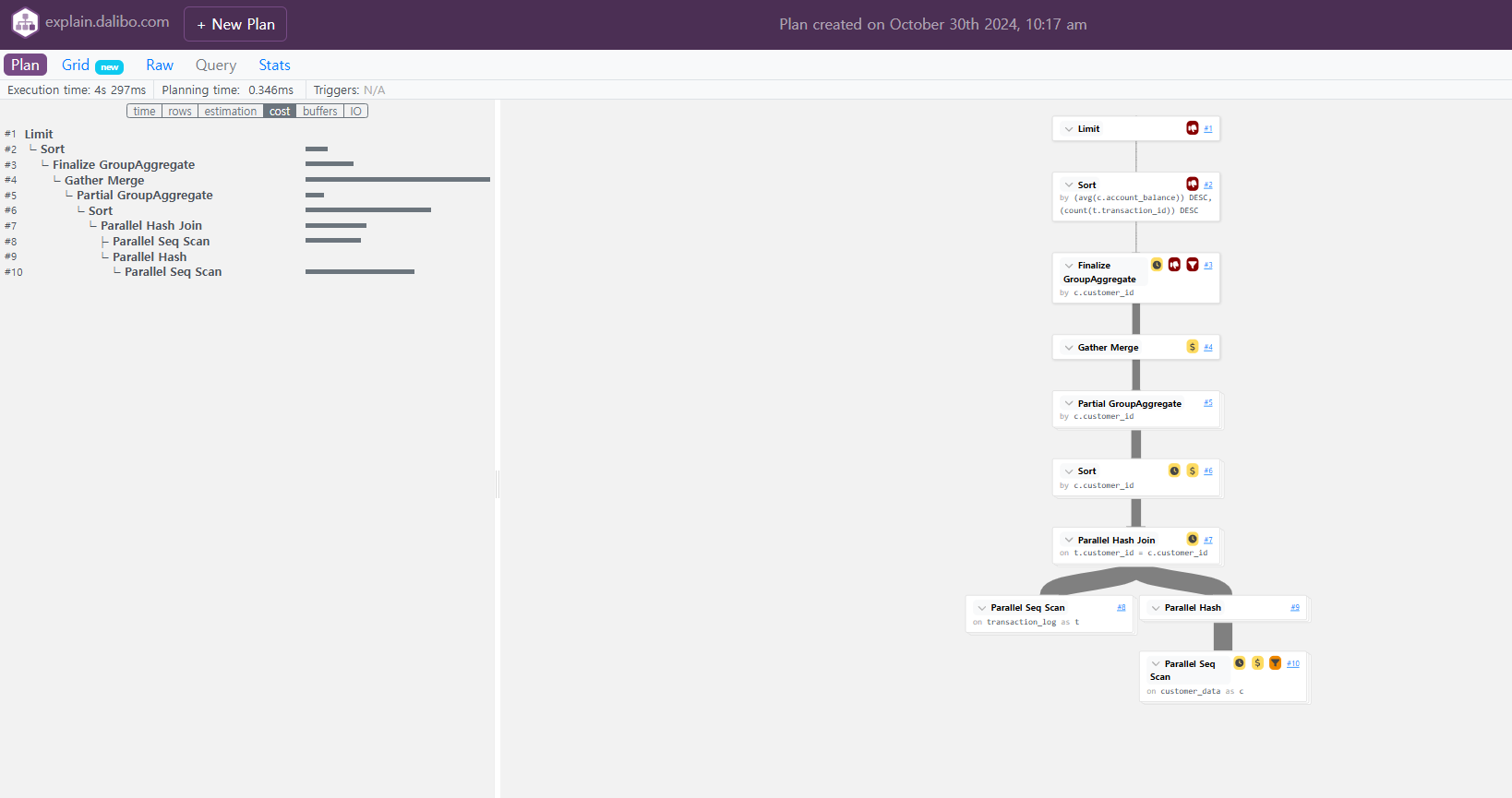
PostgreSQL 쿼리 최적화와 실행 계획 분석 with PEV
대량의 데이터를 다루는 현대의 데이터베이스 환경에서 쿼리 최적화는 성능 개선의 핵심 요소입니다. 이번 포스팅에서는 PostgreSQL의 EXPLAIN 명령어와 PEV(Execution Visualizer)를 활용하여 복잡한 JOIN 쿼리의 성능을 분석하고 최적화하는 방
PostgreSQL에서 \gset으로 쿼리 결과를 변수로 저장하는 방법과 활용 예제
psql에서 제공하는 \\gset 명령어는 SQL 쿼리의 결과를 변수로 저장하여 후속 쿼리에서 활용할 수 있도록 하는 기능입니다. 이 기능은 특히 조건에 따라 여러 단계를 거치는 복잡한 쿼리나 일괄 작업(batch 작업)을 수행할 때 유용합니다. \\gset을 사용하면
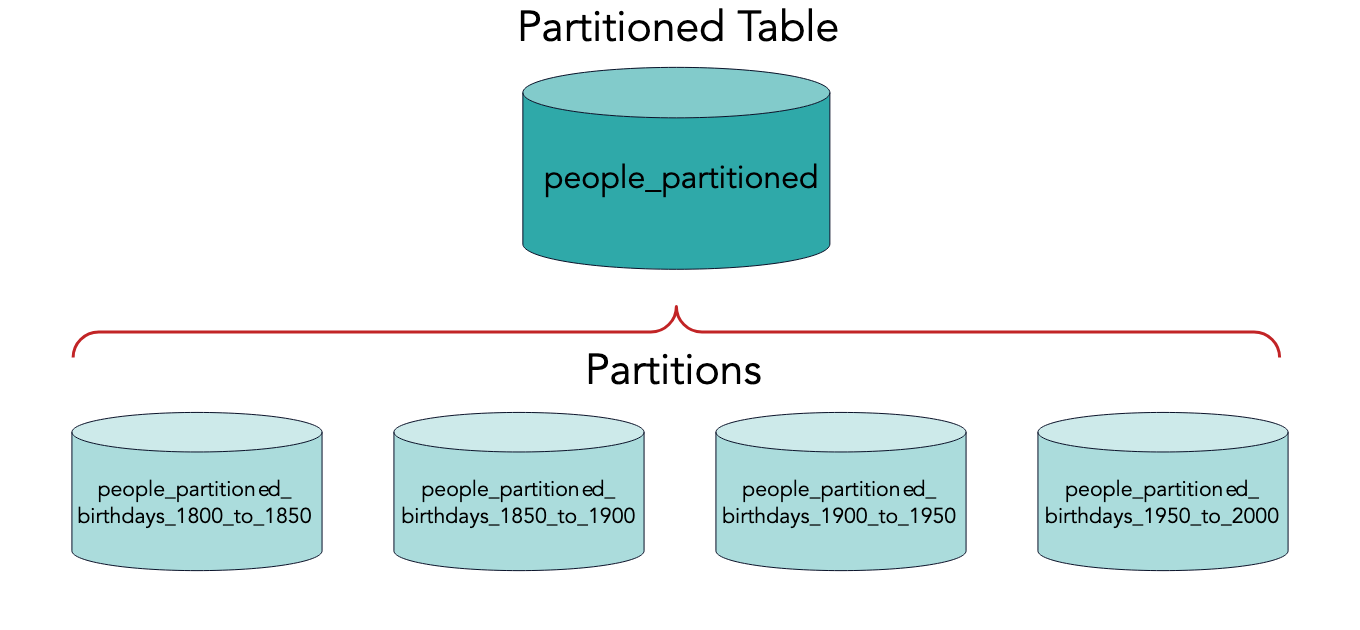
PostgreSQL 테이블 파티셔닝 (Table Partitioning)
파티셔닝은 큰 데이터베이스 테이블을 더 작은 자식 테이블로 나누어 관리하는 과정입니다. 이 과정은 확장성, 쿼리 성능 개선 등 여러 이유로 수행됩니다.올바른 파티셔닝 전략을 선택하는 것은 더 나은 성과를 달성하기 위한 중요한 결정입니다. 잘못된 파티셔닝 전략은 오히려

pg_dump는 백업 도구인가?
최근에 PostgreSQL을 오랫동안 사용한 사람들이 "pg_dump는 백업 도구가 아니다"라는 말을 반복하는 것을 자주 듣습니다. 사실 문서도 최근에 수정되어 pg_dump를 백업 도구로 설명하지 않도록 변경되었고, 많은 사람들이 이에 안도하는 분위기입니다. 경험이
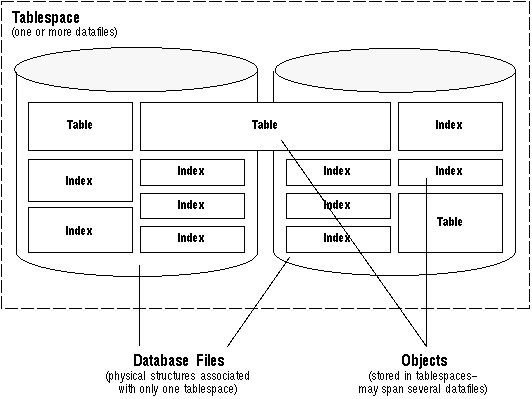
Oracle에서 PostgreSQL로의 전환 2탄: 테이블스페이스의 차이점 분석
금융권에서 Oracle to PostgreSQL DBMS 전환을 8개월동안 진행하였고, 현재는 Korail 운행정보시스템 차세대 프로젝트에 속해서 Oracle,DB2 DBMS를 PostgreSQL로 전환하는 프로젝트를 올해 1월부터 진행 중입니다. 이기종 DB의 전환으
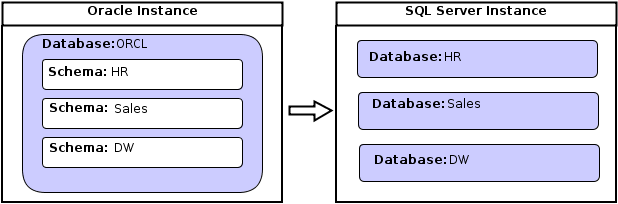
Oracle에서 PostgreSQL로의 전환 1탄: 스키마의 차이점 분석
금융권에서 Oracle to PostgreSQL DBMS 전환을 8개월동안 진행하였고, 현재는 Korail 운행정보시스템 차세대 프로젝트에 속해서 Oracle,DB2 DBMS를 PostgreSQL로 전환하는 프로젝트를 올해 1월부터 진행 중입니다. 이기종 DB의 전환으
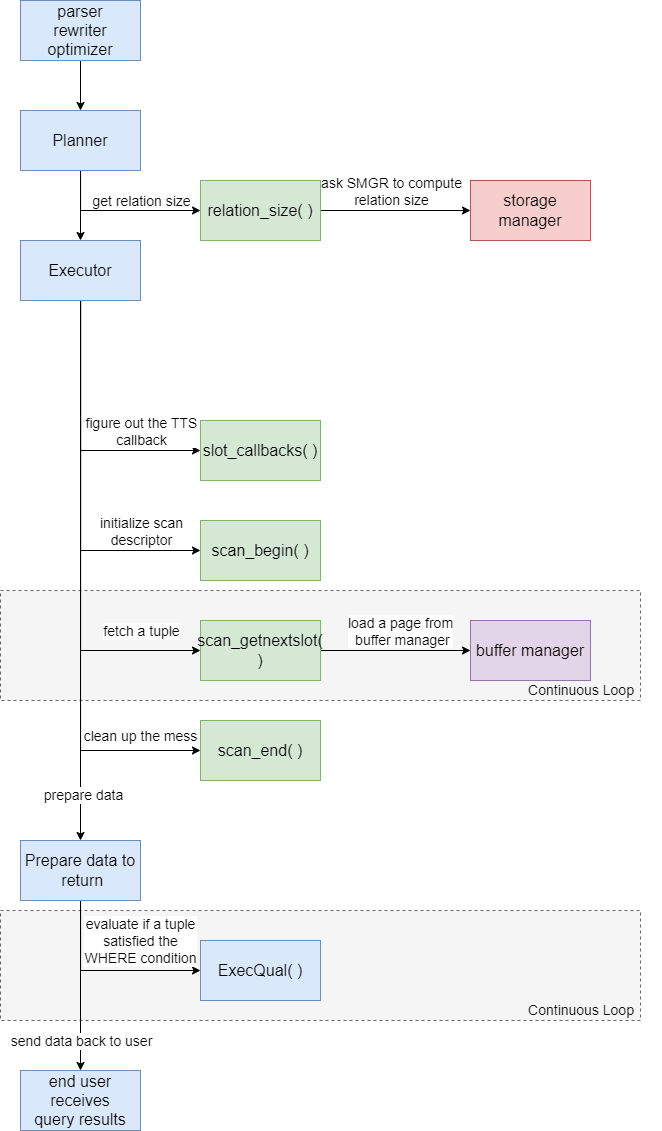
DeepDive: PostgreSQL의 순차 스캔 핵심
PostgreSQL은 다양한 테이블 접근 방법을 제공하여 데이터베이스의 성능을 극대화합니다. 이전 블로그 포스트에서 PostgreSQL의 테이블 접근 방법 API와 힙 튜플과 튜플 테이블 슬롯(TTS) 간의 차이를 살펴보았습니다. 이번 포스트에서는 순차 스캔을 구현하는
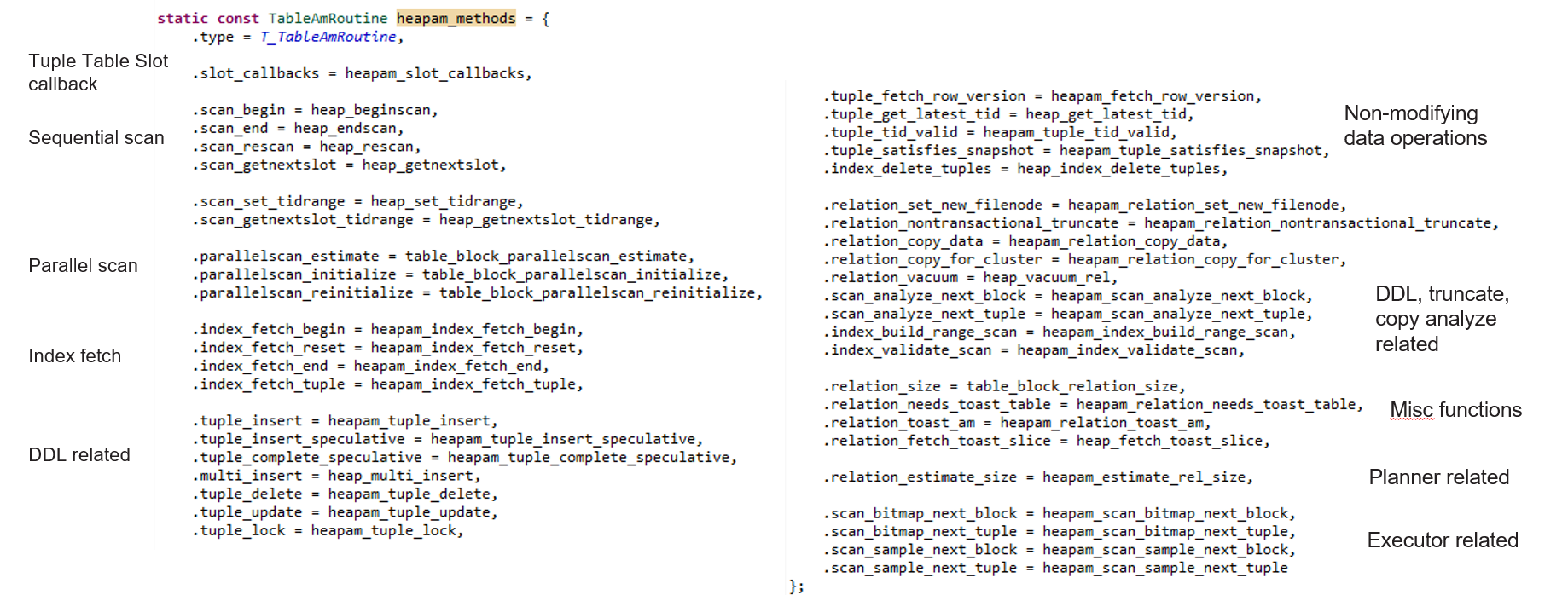
PostgreSQL 테이블 액세스 메서드 완벽 가이드: Tuple Table Slot과 Heap Tuple 간의 상호작용
PostgreSQL은 강력하고 확장 가능한 오픈 소스 데이터베이스로, 그 내부 아키텍처는 효율적인 데이터 저장과 검색을 위해 매우 정교하게 설계되어 있습니다. 그중에서도 테이블 액세스 메서드는 PostgreSQL의 핵심적인 요소로, 데이터가 디스크에 어떻게 저장되고 조
PostgreSQL 성능 최적화: VACUUM, VACUUM FULL, pg_repack, pg_reorg 완벽 비교
PostgreSQL에서 테이블의 성능을 유지하고, 비효율적인 공간을 회수하는 것은 매우 중요합니다. 이 작업을 위해 네 가지 대표적인 방법이 있는데, 각각의 특성에 따라 상황에 맞는 선택이 필요합니다. 이번 글에서는 PostgreSQL 초보자를 위해 VACUUM, VA
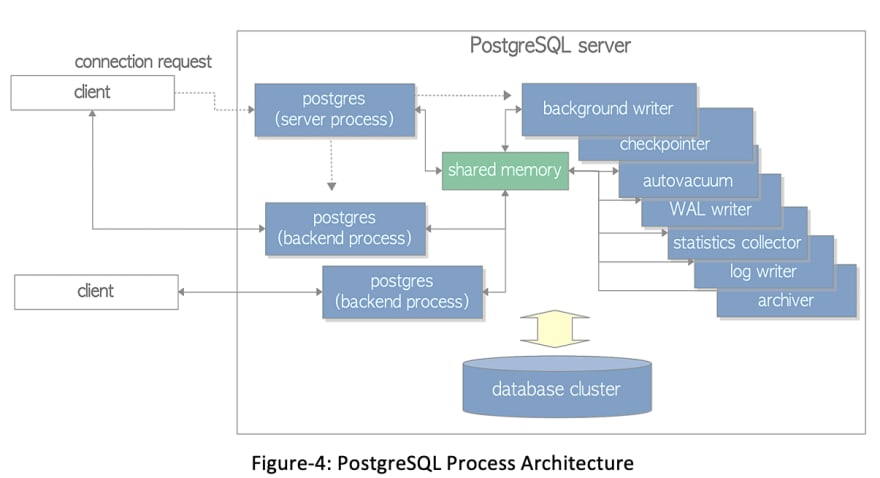
PostgreSQL의 멀티 프로세스 구조와 Autovacuum 문제 해결
PostgreSQL은 다른 데이터베이스 시스템들과 달리, 멀티 프로세스(Multi-Process) 구조를 사용합니다. 이 구조는 각 클라이언트 연결마다 독립적인 프로세스를 생성하여 데이터베이스 질의와 응답을 처리합니다. 이 방식은 격리성과 안정성을 보장하는데 탁월하지만
PostgreSQL 로그 완전 정복: 성능 튜닝과 문제 해결의 핵심
PostgreSQL은 전 세계에서 널리 사용되는 강력한 데이터베이스 관리 시스템입니다. 데이터베이스를 운영하면서 발생하는 각종 이벤트나 오류를 기록하는 로그는 시스템 관리와 성능 튜닝에 중요한 역할을 합니다. 이 글에서는 PostgreSQL 로그 시스템의 기초부터 설정

PostgreSQL 16버전 New Features
1.1 pg_stat_io 시스템 뷰설명: 새로운 시스템 뷰로, 테이블, 인덱스, 기타 객체의 IO 통계를 제공합니다. 이를 통해 데이터베이스 관리자들은 IO 활동을 모니터링하고 성능 병목 현상을 파악할 수 있습니다.1.2 pg_checkpointer 백그라운드 작업
PostgreSQL 로그 파일 완벽 가이드: 포맷팅부터 구조화된 로깅까지
서론: PostgreSQL은 강력한 데이터베이스 시스템으로, 적절한 로그 설정은 성능 모니터링과 문제 해결에 필수적입니다. 이 블로그에서는 PostgreSQL 로그 파일을 커스터마이징하는 다양한 방법에 대해 알아보겠습니다. 특히 로그 포맷팅, JSON 형식의 구조화된
PostgreSQL에서 VACUUM: 개념, 중요성
PostgreSQL는 오랜 기간 동안 신뢰성과 성능으로 많은 개발자와 기업들 사이에서 널리 사용되고 있는 데이터베이스 관리 시스템(DBMS)입니다. 특히 트랜잭션 처리에서 강력한 기능을 제공하는데, 이는 여러 사용자가 동시에 데이터베이스에 접근하고 수정하는 상황에서 매