[논문리뷰] Generic Attention-model Explainability for Interpreting Bi-Modal and Encoder-Decoder Transformers(2)
XAI / Object Detection

Paper: arxiv.org
Code: github.com
DETR을 중심으로 (BaseLine, Experiments, and Conclusion)
0. Abstract ~ 3. Method
4. Baselines
저자는 설명가능성 연구에도 존재하고, 광범위한 테스트에 적용가능한 방법에 집중합니다. 해당 파트에서 우리는 세 종류의 베이스라인을 제공하는데, 이는 아래와 같습니다.
1. Attention map baselines
- raw attention
- attention map of last layer ()
- rollout
- rollout for all the self-attention layers
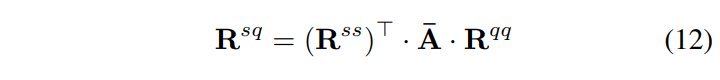 이 때, 는 rollout 방식으로 계산된 self-attention relevancies이며,
이 때, 는 rollout 방식으로 계산된 self-attention relevancies이며,
는 last bi-attention map입니다.
- rollout for all the self-attention layers
2. Gradient baselines
- Grad-CAM
- last attention layer. 또한, attention map의 heads에 대해 Grad-CAM을 수행합니다.
3. Relevancy map baselines
- partial LRP
- heads 차원을 따라 평균을 냄으로써 last attention layer의 LRP relevancy value를 사용합니다.
- Transformer attribution method[5]
- 아래와 같은 방식을 모든 attention layers에 대해 적용하여 heads를 따라 평균을 냅니다
- 단, [5]은 raw attention map을 사용한 본 연구와 다르게 Attention map 의 LRP relevancy value 를 사용합니다.
본 연구
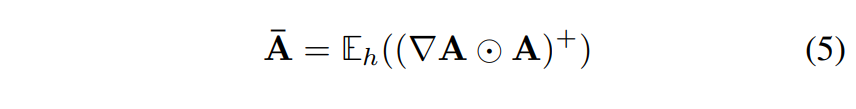 Transformer attribution method
Transformer attribution method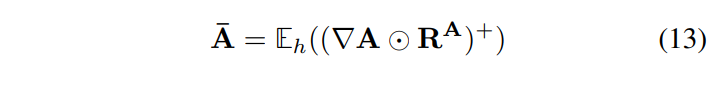
- 추가적으로, [5]은 식 (6)을 모든 self-attention layer에 적용합니다. -attention layer가 아닌 layer에 대해서는 last attention map을 취해 식 (13)을 사용해 heads를 따라 평균을 냅니다.
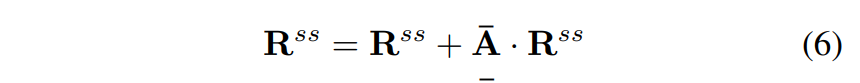
위에서 말하는 TRansformer attribution method는 모든 네트워크의 layer에 대해 custom implementation을 필요로 하지만, 본 연구가 제안하는 방법은 그저 attention modules에 간단한 hooks만 걸어주면 되는 간결함이 있습니다.
5. Experiments
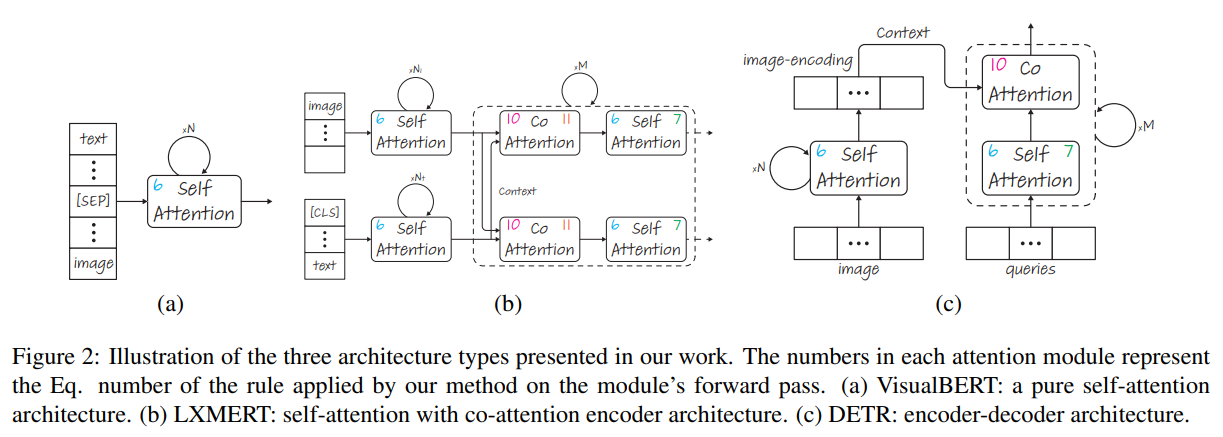
위의 그림은 본 연구에서 실험을 거친 세가지 타입의 트랜스포머 기반 모델입니다. 각 attention module의 숫자는 모듈의 forward pass에 저자들의 방식을 적용하는데 있어서 쓰인 방정식의 숫자입니다. 세 가지 구조로 (1) self-attention만 사용하는 visual BERT , (2) self-attention과 co-attention를 같이 사용하는 encoder 네트워크인 LXMERT, (3) encoder-decoder 구조를 갖는 DETR이 있습니다.
저자들은 이전 연구들(Transformer attribution method, rollout)과 비교를 위해 같은 세팅을 했으며, 추가적으로 Vision Transformer까지 고려했습니다. 각 모델의 Relevancy propagation은 Section 3.2에서 볼 수 있습니다.
5.1. VisualBERT and 5.2. LXMERT**
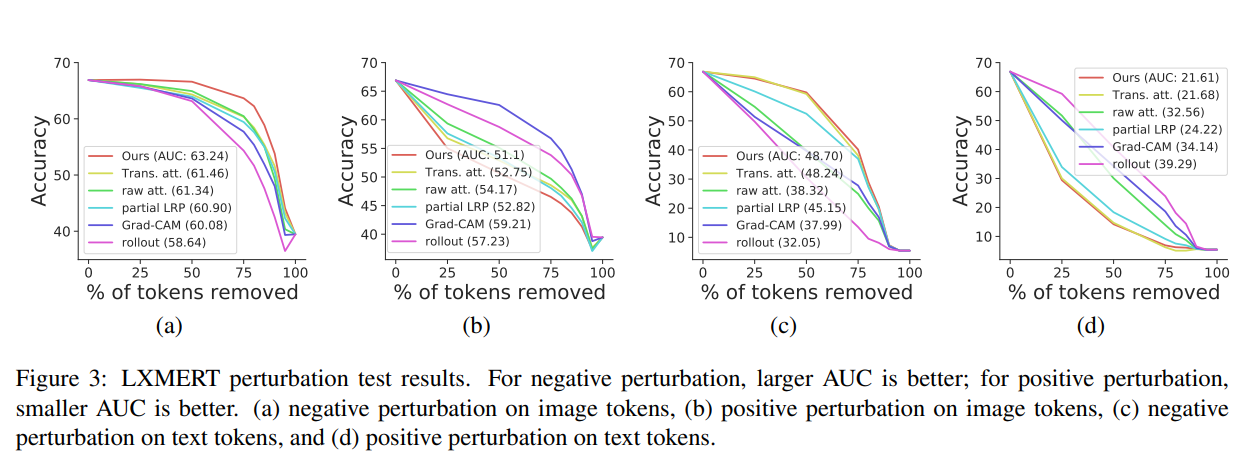

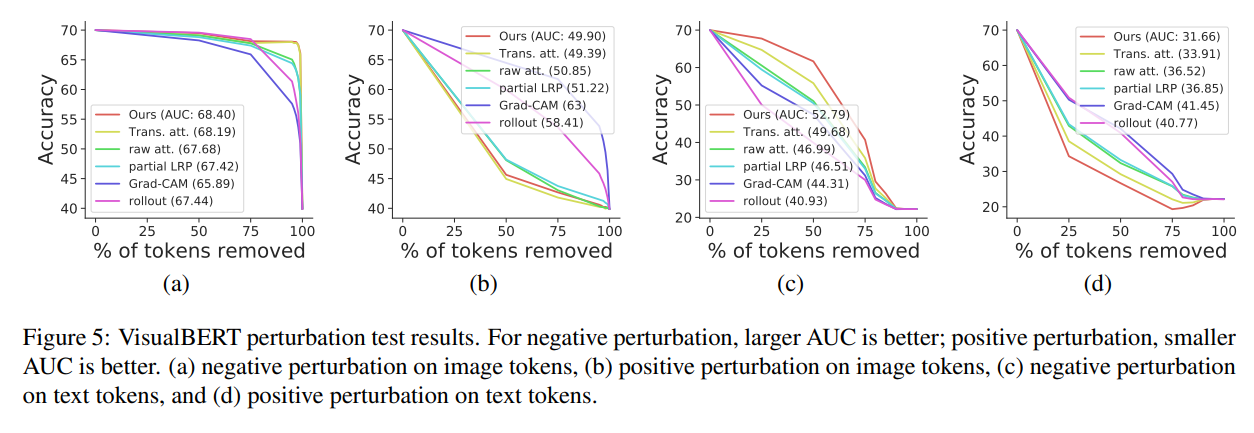
본 파트는 나중 연구에 대해 Evaluation을 실시할 때 다시 작성할 예정입니다.
5.2. DETR
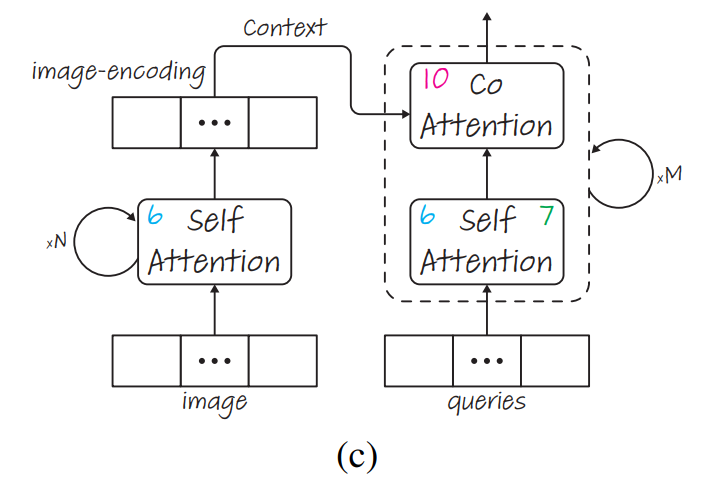
저자들이 해당 설명 방법을 적용한 세번째 구조는 DETR(End-to-End Object Detection model using transformer)입니다. Object Detection task를 하는 데 있어서 transformer의 encoder-decoder 구조를 채택함으로써 굉장히 간단한 구조로 좋은 성능을 기록한 모델입니다. ImageNet에 pre-train시킨 Backbone ResNet-50을 가지며, MSCOCO에 Object Detection을 위해 학습시킨 pre-trained DETR을 사용해 실험을 진행했습니다.
가장 중요한 것은, 해당 모델이 그저 object detection을 위해서만 학습됐다는 것입니다. 즉, 해당 모델은 input으로 image를 받아, output으로 bounding boxes와 각 object에 대한 classification을 생성하는 모델입니다.
다양한 explainability methods를 평가하기 위해, 저자들은 MSCOCO Dataset의 validation set을 사용해 segmentation masks를 생성합니다. 즉, 각 방법의 output을 segmentation masks로 간주합니다. 첫번째로, 분류 확률이 50%이 넘어가는 요소들만 남도록 쿼리를 필터링합니다. 그 후, segmentation의 background와 foreground를 분리하기 위해 Otsu's thresholding method 를 적용합니다.
**Otsu's thresholding method(Gray-Level Histograms)[1975]

사실, Segmentation masks를 이용해 Explainability methods를 평가하는 게 옳은 방식인지는 잘 모르겠습니다. 방법론들의 특성 상 해당 Evaluation 방법에 특화되지 않은 방식들도 있을 수 있으며, 기껏해야 Pixel-Level Explanation만 적용할 수 있고, Part or Object-Level에서는 적용하기도 힘들 것 같다고 느껴집니다.
저자들의 방법으로 생성한 segmentation masks는 DETR에 의해 예측된 BOUNDING BOXES를 시각화합니다. 그렇기 때문에 근본적으로 생성된 masks는 그에 상응하는 bounding boxes에 의존할 수 밖에 없습니다. 즉, 예측된 bounding box가 충분하지 않다면, 자연스럽게도 생성된 masks 또한 정확하지 않을 것입니다.
또한, explainability methods는 애초에 segmentation maps을 생성하는 데 초점이 맞춰져 있지는 않다 보니까 종종 연속적이지 않은 마스크를 생성할 때도 있고, 그에 따라 Otsu threshold를 적용한 뒤에는 masks에 마치 구멍이 생긴 것처럼 보일 수도 있습니다.
이런 저런 이유로, 저자들은 MSCOCO evaluation에 쓰는 minimal IoU를 0.5에서 0.2로 낮췄고, 그로 인해 모든 설명 방법들의 성능은 높아졌습니다.
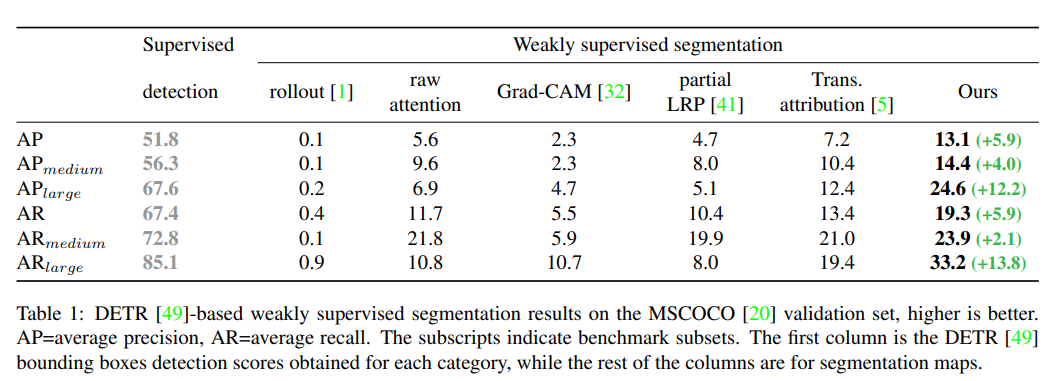
위에 테이블에서 볼 수 있다시피, 저자의 방법은 다른 방법들을 굉장히 큰 차이로 앞지릅니다. 이로 인해 non self-attention 구조를 가질 때에도 저자들의 방법론이 중요하다는 것을 알 수 있습니다. 위 테이블에서는 DETR과 우리의 segmentation 방법 사이의 상관관계를 또한 볼 수 있습니다.

6. Conclusions
트랜스포머는 컴퓨터 비전 분야에서 점점 결정적인 역할을 하고 있습니다. image-text 트랜스포머는 물론이고, 분류를 통해 라벨을 내뱉는 것보다 훨씬 복잡한 도메인을 갖는 트랜스포머 또한 널리 사용되고 있으며, 성능 또한 굉장히 좋습니다. 그러한 모델들을 디버깅하기 위해서는 downstream tasks를 받쳐줘야할 뿐만 아니라 완전하고 정확한 설명 방법론 또한 필요합니다. 하지만, 현재 트랜스포머에 쓰이는 설명방법들은 굉장히 제한된 상태고, 대부분 pure attention maps에만 집중하고 있어 co-attention maps을 다루는 방법론을 부족한 상태입니다.
저자의 방법은 attention maps의 evolution과 mixing을 조심스럽게 추적합니다. 이 방법은 (적어도 저자가 아는 한에선) 모든 attention model에 적용할 수 있는 일반적인 처방을 제공합니다. 해당 방법은 경험적으로 모든 트랜스포머 구조에 있어서 기존의 방법들을 압도하는 성능을 보이는 것 같습니다. self-attention이 굉장히 중요한 약간의 케이스에 있어서는 Transformer attribution method(저자들의 이전 연구)의 성능이 해당 방법의 성능에 겨우 필적할 정도입니다.
아무튼, 저자들의 성능은 좋다고 합니다.
P.S
눈으로 보기에도 저자들의 방법은 Attention-based 모델이 예측을 내뱉는 과정을 정확하게 역추적하고 있다고 생각합니다. 다만, 위에서 서술했다시피 현재 트랜스포머에 적용될 수 있는 설명 방법론들은 pixel-level에서만 다루어지고 있는 것 같습니다. 당연히 추가 학습을 진행하지 않는 모델 선에서는 거의 유일한 선택지이기도 하구요.
이렇게 정확한 트랜스포머 기반 모델 분석을 토대로 앞으로는 모델이 집중하고 있는 pixel 외에도 더욱 고차원적인 분석이 필요하다고 생각합니다. 그 결과가 일반인들도 납득할 수 있을 정도의 설명이라면 더욱 좋겠죠? 이러나 저러나 해당 연구는 Explainability Methods를 트랜스포머 기반 구조에 광범위하게 적용될 수 있는 기틀을 마련해준 좋은 연구입니다.
