Turning off each head's attention maps of Decoder in DETR : Focusing on raw attention map
XAI / Object Detection

아래의 모든 시각화는 DETR 내 Transformer Decoder의 6개 layer 중 마지막 Layer에서 8개의 attention head에 대해 시각화한 것 입니다 !
또한, 6개의 모든 decoder layer에서 attention maps을 zero로 만들었습니다.
Turn Off Sequntial attention head in decoder in transformer in DETR
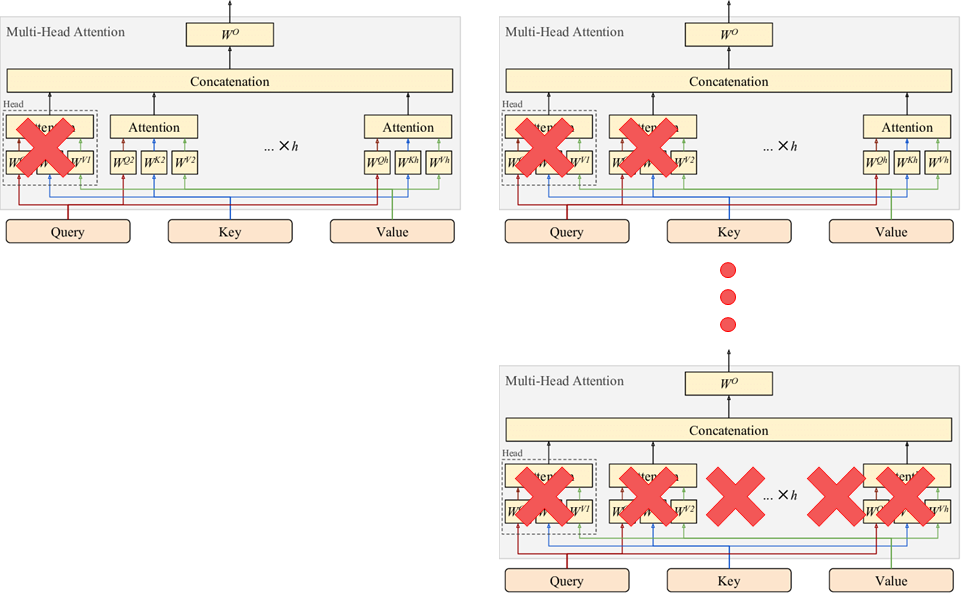
위 그림에서와 같이, 첫 번째 head에서 마지막 head(총 8개)까지 누적해가며 모든 Decoder layer(총 6개)의 attention weights를 zero로 만듭니다.
즉, 자세히 보면 아래와 같은 과정을 반복해 진행합니다.
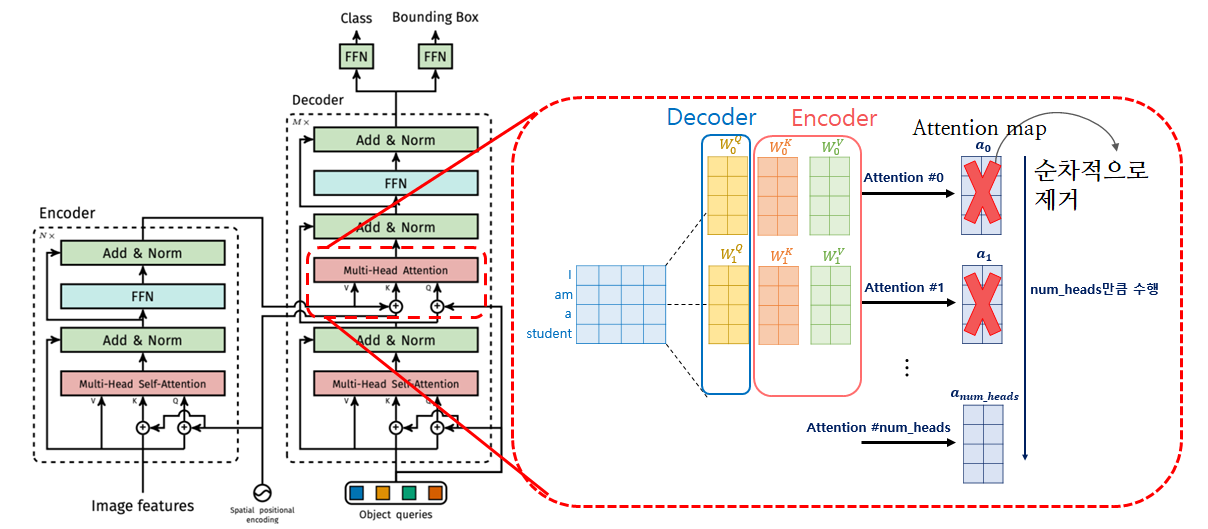
Modified Code
in DETR.modules.layers
class MultiheadAttention(RelProp): # in layers.py
...
def __init__(self, embed_dim, num_heads, dropout=0., no_weight:'[num_heads] idx vector'=False): #수정-0927:Deocder attention off
...
self.attn_gradients = None
# 수정-0927:Deocder attention off
self.no_weight = no_weight
def forward(self, query, key, value, key_padding_mask=None,
need_weights=True, attn_mask=None):
...
# 추가-0927:Deocder attention off
if self.no_weight: # self.no_weight : length : multiheads. ex) [0,1,0,1,1,0,0,0] --> 2,4,5th head off
mask = torch.stack([torch.zeros_like(a[0]) if (idx==1)
else torch.ones_like(a[0]) for idx in self.no_weight])
attn_output_weights=attn_output_weights * mask
self.save_attn(attn_output_weights)
attn_output_weights.register_hook(self.save_attn_gradients)
...in DETR.models.transformer_jsp(new
class Transformer(nn.Module):)
def __init__(self, d_model=512, nhead=8, num_encoder_layers=6,
num_decoder_layers=6, dim_feedforward=2048, dropout=0.1,
activation="relu", normalize_before=False,
return_intermediate_dec=False, off_decoder_head=False):
...
self.encoder = TransformerEncoder(encoder_layer, num_encoder_layers, encoder_norm)
#추가-0927 : add decoder head
decoder_layer = TransformerDecoderLayer(d_model, nhead, dim_feedforward,
dropout, activation, normalize_before, off_decoder_head=off_decoder_head)
decoder_norm = LayerNorm(d_model)
self.decoder = TransformerDecoder(decoder_layer, num_decoder_layers, decoder_norm,
return_intermediate=return_intermediate_dec)
...
class TransformerDecoderLayer(nn.Module):
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1,
activation="relu", normalize_before=False, off_decoder_head=False): #추가:0927-off_decoder_head : Off.
super().__init__()
self.self_attn = MultiheadAttention(d_model, nhead, dropout=dropout)
...
def build_transformer_jsp(args):
return Transformer(
...
return_intermediate_dec=True,
off_head = False #수정(1) : Out heads(input : [layers x heads ] matrix)
)in DETR.detr
from DETR.models.transformer_jsp import build_transformer_jsp #추가-0927: add off decoder
...
...
def build(args):
...
#추가-0927 : add decoder off
if args.off_decoder_head:
transformer = build_transformer_jsp(args) #추가-0927 : add decoder off
else :
transformer = build_transformer(args)DETR(Object Detection)
Non-off
1~4 Heads Off

5~8 Heads Off

Raw-attention(After Object Detection)
Non-off

1~4 Heads off




5~8 Heads off


6, 8 heads off는 detect한 object가 2개 미만이라 시각화하지 않았습니다.
Turn Off head, attentioning for Specific area


각 head가 물체를 탐지하는 데 위와 같은 역할을 할 것이라 가정하고 진행합니다. 가설일 뿐이므로 제 주관에 맞는 용어를 써서 나타냈습니다.
Turn Off head, attentioing for Specific area - in All Layer
여기서는, 모든 Decoder Layer(6개)의 attention maps을 zero로 대치시킵니다.
각 head가 물체를 탐지하는 데 위와 같은 역할을 할 것이라 가정하고 진행합니다. 가설일 뿐이므로 제 주관에 맞는 용어를 써서 나타냈습니다.
Head를 하나씩 끌 경우 --> DETR 성능에 무관
이 경우 물체를 탐지하는 데 큰 악영향을 끼치지 않습니다.

위에서 볼 수 있다시피, Heads를 3개 이상 끄는 순간 성능이 떨어졌었으므로,
여기서도 3개 이상의 Heads만 끄는 걸로 진행했습니다.

Head를 3개 끌 경우
for layer in model.transformer.decoder.layers:
layer.multihead_attn.no_weight = [1,0,1,0,0,1,0,0]
gen=Generator(model)
evaluate(model, gen, im, 'cuda', show_all_layers=True, show_raw_attn=True, confidence=0.5)
1,3,6
1 : Part of object(Top)
3 : Part of object(Left)
6 : Whole object

5,6,7
5 : Extremity(Right)
7 : Extremity(Bottom)
6 : Whole object

2,4,6
2 : Background
4 : Around the object
6 : Whole object

2,4,8
2 : Background
4 : Around the object
8 : very small area

Turn Off head, attentioing for Specific Object - in Only last layer
여기서는, Decoder의 Last layer에 대한 Attention map만 zero로 대치시킵니다.
시각화 자체를 Last layer of Decoder Layers 에서만 진행하기 때문에 엄밀히 따지면 Decoder의 마지막 layer에서만 attention maps을 끄는 것이 옳은 방향이긴 합니다.
for layer in model.transformer.decoder.layers: # 모든 layer 초기화
layer.multihead_attn.no_weight = False
model.transformer.decoder.layers[-1].multihead_attn.no_weight = [1,0,1,0,0,1,0,0]
gen=Generator(model)
evaluate(model, gen, im, 'cuda', show_all_layers=True, show_raw_attn=True, confidence=0.5)
Head를 3개 끌 경우
1,3,6
1 : Part of object(Top)
3 : Part of object(Left)
6 : Whole object

5,6,7
5 : Extremity(Right)
7 : Extremity(Bottom)
6 : Whole object

2,4,6
2 : Background
4 : Around the object
6 : Whole object

2,4,8
2 : Background
4 : Around the object
8 : very small area

5개 heads off
1,3,5,6,7(all heads related object)

역시나 마지막 layer는 모두 제외한다고 해서 성능에 큰 변화는 없습니다(최종 output이 마지막 layer에서만 나오는 게 아니기 때문).
결론
- 일부 Attention head의 역할을 없앤다 하더라도 성능에 큰 변화가 있지는 않습니다.
- 이는, Attention map은 애초에 연산 중 일부일 뿐이며, Residual term 등도 존재하기 때문입니다.- 또한, Decoder Layer는 6번 가량 Recurrent하게 돌면서
- 그리고, Attention map은 input과 Weights의 연산의 결과로 나온 것뿐이라, Input(queries), Weights(key, value - 최초엔 encoder에서 받는다)가 어떻게 변하는 지 추적할 필요가 있습니다.
- Attention maps을 끄더라도, Decoder의 매 layer에서는 Key, Value를 Encoder에서 온전한 값을 받습니다.
- 즉, Attention maps을 끈다는 거는 해당 head에 대해 decoder layer output을 0으로 만드는 역할입니다.
- 다만, 모든 layer에 대해 attention 무력화시킨다면 head의 종류에 따라 성능 저하가 확연히 있습니다(3개 이상의 heads가 역할을 못 한다면).
Decoder는 각 layer에 대한 output을 모두 받는다(return_intermediate).
Decoder의 output은 아래 그림과 같다(decoder layer : 6개).
단, 이는 class_embed를 지났을 때 마지막 layer를 고르긴 하는데.. 상관 없는건지 detr.class_embed, detr.index_select 를 볼 필요는 있다.
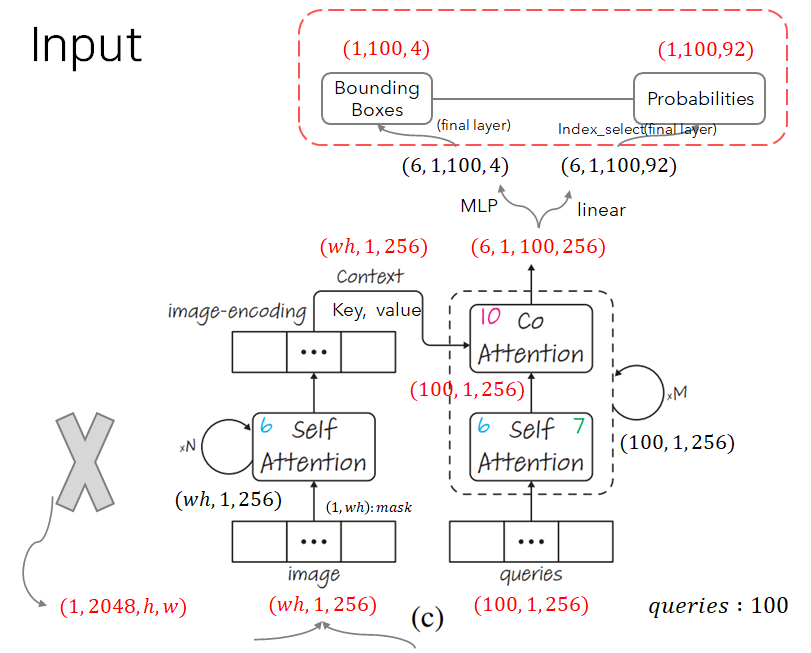
model을 build할 때 args와 기타 transformer code에서도 볼 수 있다(return_intermediate).
def build_transformer_jsp(args):
return Transformer(
...
normalize_before=args.pre_norm,
return_intermediate_dec=True, # Decoder의 output을 모두 반환한다.
off_head = False #수정(1) : Out heads(input : [layers x heads ] matrix)
)class TransformerDecoder(nn.Module):
def __init__(self, decoder_layer, num_layers, norm=None, return_intermediate=False):
super().__init__()
...
def forward(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None):
...
for i, layer in enumerate(self.layers):
output = layer(output, mem_list[i], tgt_mask=tgt_mask,
memory_mask=memory_mask,
tgt_key_padding_mask=tgt_key_padding_mask,
memory_key_padding_mask=memory_key_padding_mask,
pos=pos, query_pos=query_pos)
if self.return_intermediate:
if i == self.num_layers - 1:
intermediate.append(self.norm(output))
else:
output, output_norm = self.clone_list[i](output, 2)
intermediate.append(self.norm(output_norm))
...
if self.return_intermediate:
return torch.stack(intermediate)
print('End Transformer.decoder.forward(tgt, memory...). shape of output :', output.shape)
return output.unsqueeze(0)Implementation Code
Object Detection
def detect(im, model, confidence=0.5):
img=transform(im).unsqueeze(0).to(device)
outputs=model(img)
assert img.shape[-2] <= 1600 and img.shape[-1] <= 1600
probas = outputs['pred_logits'].softmax(-1)[0, :, :-1]
keep = probas.max(-1).values > confidence
# 0과 1사이의 boxes 값을 image scale로 확대합니다.
bboxes_scaled = rescale_bboxes(outputs['pred_boxes'].cpu()[0, keep], im.size)
scores, boxes=probas[keep], bboxes_scaled
return scores, boxesBounding box Visualization
def plot_results(pil_img, prob, boxes, line_width=8, font_size=20):
# plt.figure(figsize=(16,10))
plt.imshow(pil_img)
ax = plt.gca()
colors = COLORS * 100
for p, (xmin, ymin, xmax, ymax), c in zip(prob, boxes.tolist(), colors):
ax.add_patch(plt.Rectangle((xmin, ymin), xmax - xmin, ymax - ymin,
fill=False, color=c, linewidth=line_width))
cl = p.argmax()
text = f'{CLASSES[cl]}: {p[cl]:0.2f}'
ax.text(xmin, ymin, text, fontsize=font_size,
bbox=dict(facecolor='yellow', alpha=0.4))
plt.axis('off')
# plt.show()Evaluation & Visualization
def evaluate(model, gen, im, device, image_id=None, show_all_layers=False, show_raw_attn=False, confidence=0.7):
# 평균-분산 정규화 (train dataset의 통계량을 (test) input image에 사용
img=transform(im).unsqueeze(0).to(device)
# model 통과
outputs =model(img)
# 정확도 70% 이상의 예측만 사용
probas = outputs['pred_logits'].softmax(-1)[0, :, :-1] # background 제외
keep = probas.max(-1).values > confidence
if keep.nonzero().shape[0] <=1 : # detect된 object
print('detected object is under 2')
return
# 원래 cuda에 적재되어있던 좌표들
outputs['pred_boxes'] = outputs['pred_boxes'].cpu()
# [0,1]의 상대 좌표를 원래의 좌표로 복구
bboxes_scaled = rescale_bboxes(outputs['pred_boxes'][0, keep], im.size)
#attention weight 저장
hooks=[]
conv_features_out, enc_attn_out, dec_attn_out = [], [], []
for layer_name in model.backbone[-2].body:
hook=model.backbone[-2].body[layer_name].register_forward_hook(
lambda self, input, output : conv_features_out.append(output)
)
hooks.append(hook)
model(img)
# hook 제거
for hook in hooks:
hook.remove()
# get the shape of feature map
h, w = conv_features_out[-1].shape[-2:] # Nested tensor -> tensors
#######################
######## Modified Code
if not show_all_layers == True:
fig, axs = plt.subplots(ncols=len(bboxes_scaled), nrows=2, figsize=(22,7))
else:
n_layers=len(model.transformer.encoder.layers)
if not show_raw_attn:
fig, axs = plt.subplots(ncols=len(bboxes_scaled), nrows=n_layers+1, figsize=(22, 4*n_layers))
else:
fig, axs = plt.subplots(ncols=len(bboxes_scaled), nrows=model.transformer.nhead+1,
figsize=(22, 4*model.transformer.nhead))
# object queries는 100차원(default)이기 때문에 그 중에
# 0.7(default) 이상의 신뢰도를 보이는 query만을 사용해야 한다.
for idx, ax_i, (xmin, ymin, xmax, ymax),p in zip(keep.nonzero(), axs.T, bboxes_scaled, probas[keep]):
ax = ax_i[0]
ax.imshow(im)
ax.add_patch(plt.Rectangle((xmin.detach(), ymin.detach()),
xmax.detach() - xmin.detach(),
ymax.detach() - ymin.detach(),
fill=False, color='blue', linewidth=3))
# 0929, 확률추가
cl = p.argmax()
text = f'{CLASSES[cl]}: {p[cl]:0.2f}'
ax.text(xmin, ymin, text, fontsize=10,
bbox=dict(facecolor='yellow', alpha=0.4))
ax.axis('off')
ax.set_title(CLASSES[probas[idx].argmax()])
if not show_all_layers == True:
ax = ax_i[1]
cam = gen.generate_ours(img, idx, use_lrp=False)
cam = (cam - cam.min()) / (cam.max() - cam.min()) # 점수 정규화
cmap = plt.cm.get_cmap('Blues').reversed()
ax.imshow(cam.view(h, w).data.cpu().numpy(), cmap=cmap)
ax.axis('off')
ax.set_title(f'query id: {idx.item()}')
else:
if not show_raw_attn:
cams = gen.generate_ours(img, idx, use_lrp=False, use_all_layers=True)
else:
cams = gen.generate_raw_attn(img, idx, use_all_layers=True)
num_layer=n_layers
if show_raw_attn:
num_layer=model.transformer.nhead
for n, cam in zip(range(num_layer), cams):
ax = ax_i[1+n]
cam = (cam - cam.min()) / (cam.max() - cam.min()) # 점수 정규화
cmap = plt.cm.get_cmap('Blues').reversed()
ax.imshow(cam.view(h, w).data.cpu().numpy(), cmap=cmap)
ax.axis('off')
ax.set_title(f'query id: {idx.item()}, layer:{n}', size=12)
#######################