Turning off each head's attention maps of Decoder in DETR : Focusing on generic attention model explainability
XAI / Object Detection
목록 보기
23/24

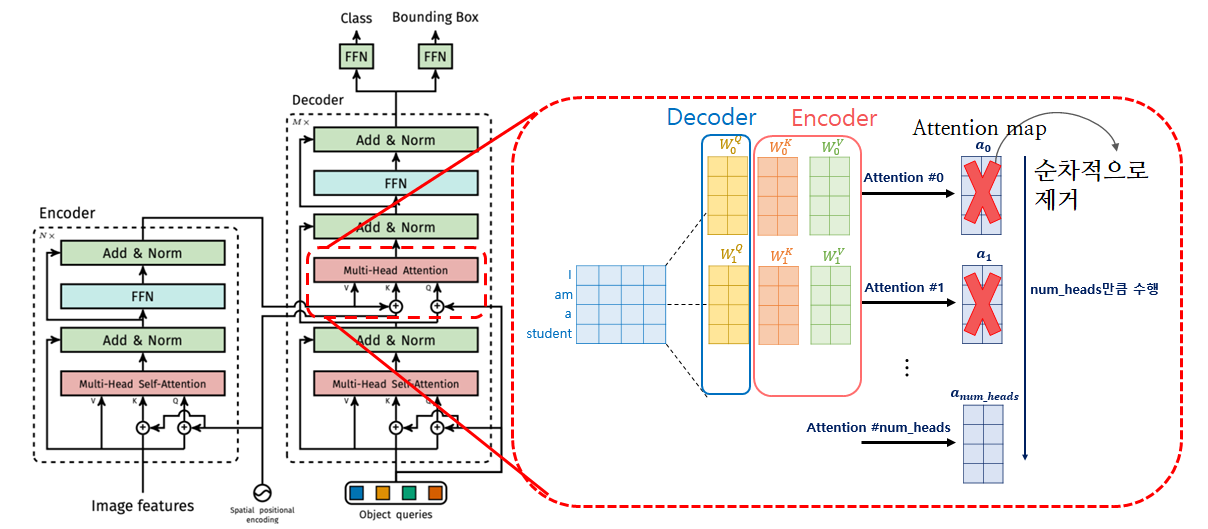
아래 그림들은 generic attention model explainability.. 연구의 '예측 타당성 유지 방법'을 적용해 DETR 내 Transformer Decoder의 6개 layer를 거치면서 시각화한 것 입니다.
특정한 Average 방법을 토대로 8개의 attention heads를 평균내기 때문에 각각의 head에 대한 insight는 존재하지 않습니다).
DETR 내부 Decoder의 Multiheadattn에서 특정 head를 off
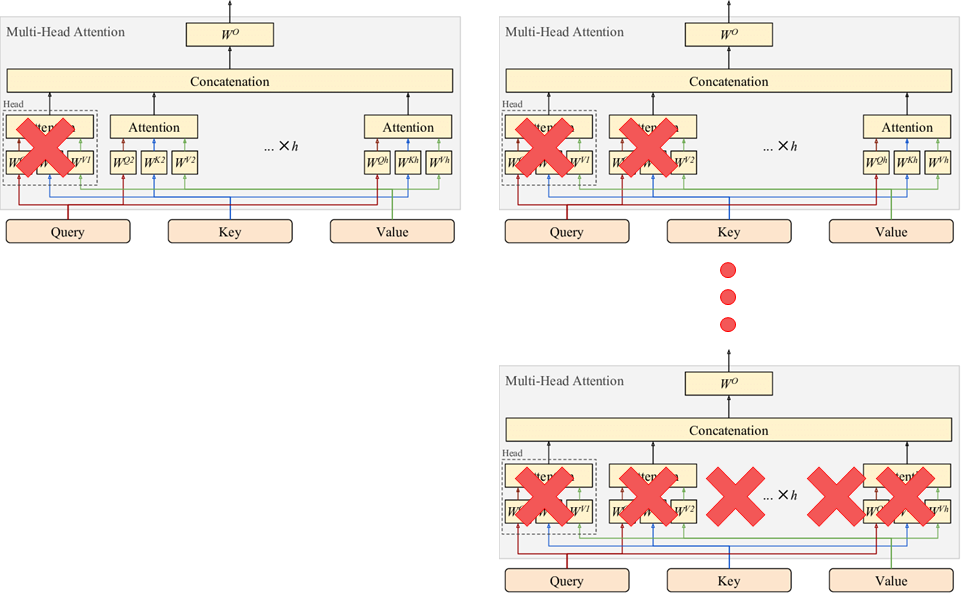
위 그림에서와 같이, 첫 번째 head에서 마지막 head(총 8개)까지 누적해가며 모든 Decoder layer(총 6개)의 attention weights를 zero로 만듭니다.
즉, 자세히 보면 아래와 같은 과정을 반복해 진행합니다.
Modified Code
in DETR.modules.layers
class MultiheadAttention(RelProp): # in layers.py
...
def __init__(self, embed_dim, num_heads, dropout=0., no_weight:'[num_heads] idx vector'=False): #수정-0927:Deocder attention off
...
self.attn_gradients = None
# 수정-0927:Deocder attention off
self.no_weight = no_weight
def forward(self, query, key, value, key_padding_mask=None,
need_weights=True, attn_mask=None):
...
# 추가-0927:Deocder attention off
if self.no_weight: # self.no_weight : length : multiheads. ex) [0,1,0,1,1,0,0,0] --> 2,4,5th head off
mask = torch.stack([torch.zeros_like(a[0]) if (idx==1)
else torch.ones_like(a[0]) for idx in self.no_weight])
attn_output_weights=attn_output_weights * mask
self.save_attn(attn_output_weights)
attn_output_weights.register_hook(self.save_attn_gradients)
...in DETR.models.transformer_jsp(new
class Transformer(nn.Module):)
def __init__(self, d_model=512, nhead=8, num_encoder_layers=6,
num_decoder_layers=6, dim_feedforward=2048, dropout=0.1,
activation="relu", normalize_before=False,
return_intermediate_dec=False, off_decoder_head=False):
...
self.encoder = TransformerEncoder(encoder_layer, num_encoder_layers, encoder_norm)
#추가-0927 : add decoder head
decoder_layer = TransformerDecoderLayer(d_model, nhead, dim_feedforward,
dropout, activation, normalize_before, off_decoder_head=off_decoder_head)
decoder_norm = LayerNorm(d_model)
self.decoder = TransformerDecoder(decoder_layer, num_decoder_layers, decoder_norm,
return_intermediate=return_intermediate_dec)
...
class TransformerDecoderLayer(nn.Module):
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1,
activation="relu", normalize_before=False, off_decoder_head=False): #추가:0927-off_decoder_head : Off.
super().__init__()
self.self_attn = MultiheadAttention(d_model, nhead, dropout=dropout)
...
def build_transformer_jsp(args):
return Transformer(
...
return_intermediate_dec=True,
off_head = False #수정(1) : Out heads(input : [layers x heads ] matrix)
)in DETR.detr
from DETR.models.transformer_jsp import build_transformer_jsp #추가-0927: add off decoder
...
...
def build(args):
...
#추가-0927 : add decoder off
if args.off_decoder_head:
transformer = build_transformer_jsp(args) #추가-0927 : add decoder off
else :
transformer = build_transformer(args)DETR
Non-off
plt.figure(figsize=(16,16))
scores, bboxes = detect(im, model, confidence=0.5)
plot_results(im, scores, bboxes, line_width=5, font_size=15)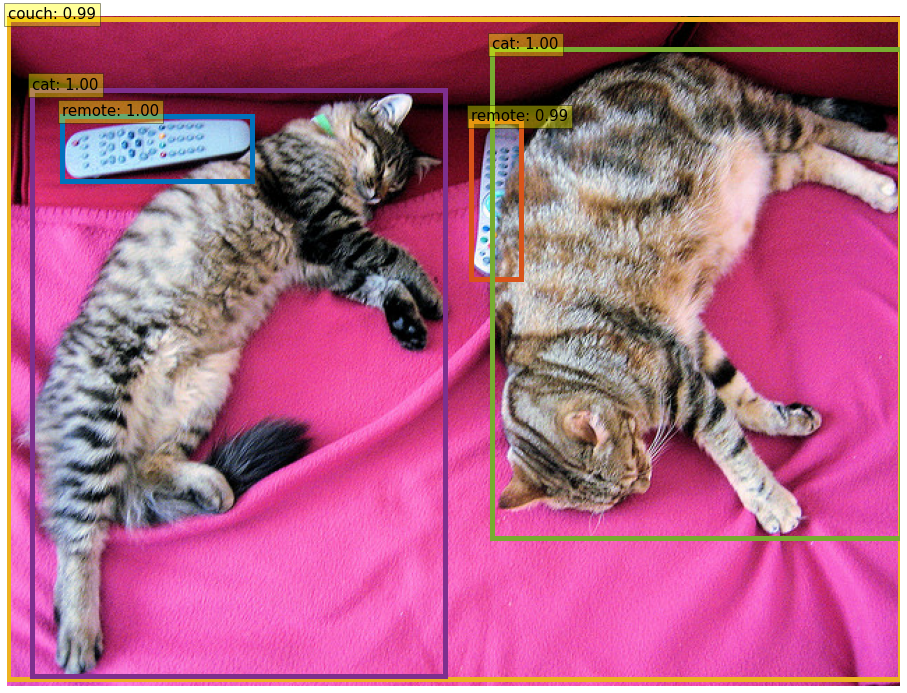
1~4 Heads Off
plt.figure(figsize=(20,20))
for idx, head in enumerate(range(4)):
for layer in model.transformer.decoder.layers:
layer.multihead_attn.no_weight = [1 if j<=(head) else 0 for j in range(8)]
plt.subplot(2,2,idx+1)
scores, bboxes = detect(im, model, confidence=0.5)
plot_results(im, scores, bboxes, line_width=5, font_size=15)
plt.title(f'first {head+1} heads off')
5~8 Heads Off
plt.figure(figsize=(20,20))
for idx, head in enumerate(range(4,8)):
for layer in model.transformer.decoder.layers:
layer.multihead_attn.no_weight = [1 if j<=(head) else 0 for j in range(8)]
plt.subplot(2,2,idx+1)
scores, bboxes = detect(im, model, confidence=0.5)
plot_results(im, scores, bboxes, line_width=5, font_size=15)
plt.title(f'first {head+1} heads off')
Generic Attention-model Explainability
Non-off
for layer in model.transformer.decoder.layers:
layer.multihead_attn.no_weight = False
gen=Generator(model)
evaluate(model, gen, im, 'cuda', show_all_layers=True, confidence=0.5)
1~4 Heads Off
for idx, head in enumerate(range(4)):
for layer in model.transformer.decoder.layers:
layer.multihead_attn.no_weight = [1 if j<=(head) else 0 for j in range(8)]
gen=Generator(model)
evaluate(model, gen, im, 'cuda', show_all_layers=True, confidence=0.5)



5~8 Heads Off
for idx, head in enumerate(range(4,8)):
for layer in model.transformer.decoder.layers:
layer.multihead_attn.no_weight = [1 if j<=(head) else 0 for j in range(8)]
gen=Generator(model)
evaluate(model, gen, im, 'cuda', show_all_layers=True, confidence=0.5)

6, 8 heads off는 detect한 object가 2개 미만이라 시각화하지 않았습니다.
Turn Off head attentioing for Specific Object
Implementation Code
Object Detection
def detect(im, model, confidence=0.5):
img=transform(im).unsqueeze(0).to(device)
outputs=model(img)
assert img.shape[-2] <= 1600 and img.shape[-1] <= 1600
probas = outputs['pred_logits'].softmax(-1)[0, :, :-1]
keep = probas.max(-1).values > confidence
# 0과 1사이의 boxes 값을 image scale로 확대합니다.
bboxes_scaled = rescale_bboxes(outputs['pred_boxes'].cpu()[0, keep], im.size)
scores, boxes=probas[keep], bboxes_scaled
return scores, boxesBounding box Visualization
def plot_results(pil_img, prob, boxes, line_width=8, font_size=20):
# plt.figure(figsize=(16,10))
plt.imshow(pil_img)
ax = plt.gca()
colors = COLORS * 100
for p, (xmin, ymin, xmax, ymax), c in zip(prob, boxes.tolist(), colors):
ax.add_patch(plt.Rectangle((xmin, ymin), xmax - xmin, ymax - ymin,
fill=False, color=c, linewidth=line_width))
cl = p.argmax()
text = f'{CLASSES[cl]}: {p[cl]:0.2f}'
ax.text(xmin, ymin, text, fontsize=font_size,
bbox=dict(facecolor='yellow', alpha=0.4))
plt.axis('off')
# plt.show()Evaluation & Visualization
def evaluate(model, gen, im, device, image_id=None, show_all_layers=False, show_raw_attn=False, confidence=0.7):
# 평균-분산 정규화 (train dataset의 통계량을 (test) input image에 사용
img=transform(im).unsqueeze(0).to(device)
# model 통과
outputs =model(img)
# 정확도 70% 이상의 예측만 사용
probas = outputs['pred_logits'].softmax(-1)[0, :, :-1] # background 제외
keep = probas.max(-1).values > confidence
if keep.nonzero().shape[0] <=1 : # detect된 object
print('detected object is under 2')
return
# 원래 cuda에 적재되어있던 좌표들
outputs['pred_boxes'] = outputs['pred_boxes'].cpu()
# [0,1]의 상대 좌표를 원래의 좌표로 복구
bboxes_scaled = rescale_bboxes(outputs['pred_boxes'][0, keep], im.size)
#attention weight 저장
hooks=[]
conv_features_out, enc_attn_out, dec_attn_out = [], [], []
for layer_name in model.backbone[-2].body:
hook=model.backbone[-2].body[layer_name].register_forward_hook(
lambda self, input, output : conv_features_out.append(output)
)
hooks.append(hook)
model(img)
# hook 제거
for hook in hooks:
hook.remove()
# get the shape of feature map
h, w = conv_features_out[-1].shape[-2:] # Nested tensor -> tensors
#######################
######## Modified Code
if not show_all_layers == True:
fig, axs = plt.subplots(ncols=len(bboxes_scaled), nrows=2, figsize=(22,7))
else:
n_layers=len(model.transformer.encoder.layers)
if not show_raw_attn:
fig, axs = plt.subplots(ncols=len(bboxes_scaled), nrows=n_layers+1, figsize=(22, 4*n_layers))
else:
fig, axs = plt.subplots(ncols=len(bboxes_scaled), nrows=model.transformer.nhead+1,
figsize=(22, 4*model.transformer.nhead))
# object queries는 100차원(default)이기 때문에 그 중에
# 0.7(default) 이상의 신뢰도를 보이는 query만을 사용해야 한다.
for idx, ax_i, (xmin, ymin, xmax, ymax),p in zip(keep.nonzero(), axs.T, bboxes_scaled, probas[keep]):
ax = ax_i[0]
ax.imshow(im)
ax.add_patch(plt.Rectangle((xmin.detach(), ymin.detach()),
xmax.detach() - xmin.detach(),
ymax.detach() - ymin.detach(),
fill=False, color='blue', linewidth=3))
# 0929, 확률추가
cl = p.argmax()
text = f'{CLASSES[cl]}: {p[cl]:0.2f}'
ax.text(xmin, ymin, text, fontsize=10,
bbox=dict(facecolor='yellow', alpha=0.4))
ax.axis('off')
ax.set_title(CLASSES[probas[idx].argmax()])
if not show_all_layers == True:
ax = ax_i[1]
cam = gen.generate_ours(img, idx, use_lrp=False)
cam = (cam - cam.min()) / (cam.max() - cam.min()) # 점수 정규화
cmap = plt.cm.get_cmap('Blues').reversed()
ax.imshow(cam.view(h, w).data.cpu().numpy(), cmap=cmap)
ax.axis('off')
ax.set_title(f'query id: {idx.item()}')
else:
if not show_raw_attn:
cams = gen.generate_ours(img, idx, use_lrp=False, use_all_layers=True)
else:
cams = gen.generate_raw_attn(img, idx, use_all_layers=True)
num_layer=n_layers
if show_raw_attn:
num_layer=model.transformer.nhead
for n, cam in zip(range(num_layer), cams):
ax = ax_i[1+n]
cam = (cam - cam.min()) / (cam.max() - cam.min()) # 점수 정규화
cmap = plt.cm.get_cmap('Blues').reversed()
ax.imshow(cam.view(h, w).data.cpu().numpy(), cmap=cmap)
ax.axis('off')
ax.set_title(f'query id: {idx.item()}, layer:{n}', size=12)
#######################
-