[논문리뷰] From Show to Tell: A Survey on Deep Learning-based Image Captioning(2)(Language Model을 중심으로)
Multimodal Deep Learning
Paper:https://arxiv.org/abs/2107.06912
1. Introduction ~ 2. Visual Encoding
3. Language Model
이미지 캡셔닝에서 언어 모델의 역할은 문장이 될 일련의 단어들이 나올 확률을 예측하는 것입니다.
일반적으로, 개의 words가 주어졌을 대, 언어 모델의 알고리즘은 확률 를 아래와 같이 할당하게 됩니다.
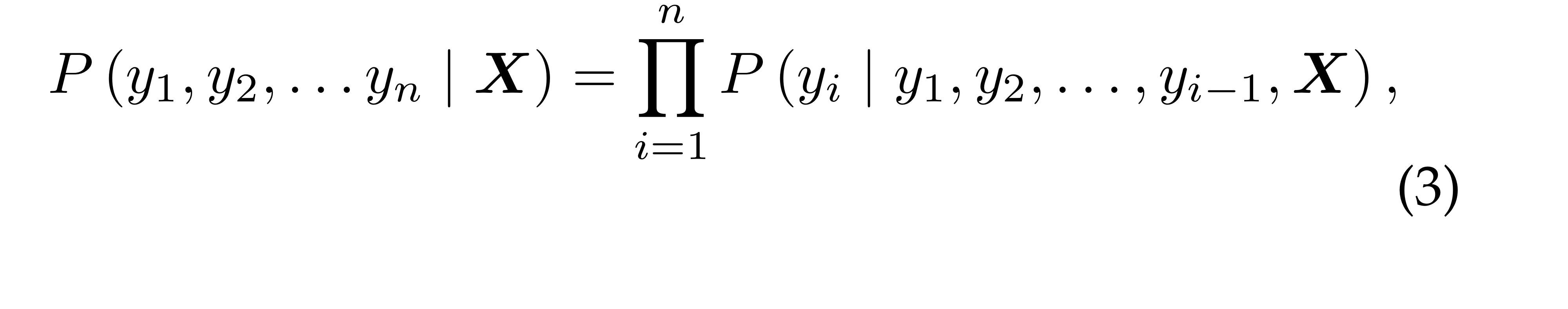
결합 확률 분포를 조건부 확률의 auto-regressive하게 나타낼 수 있다.
이 때, 이미지 캡셔닝이기 때문에 특별하게 이미지 인코딩 정보인 이 조건으로 들어갑니다.
즉, language model is conditioned on visual encoding
마찬가지로 다음 단어를 예측하기 위해 이전 단어들이 조건으로 들어가구요.
[eos] token이 나오면 문장 종료.
본 글에서 다룰, 그리고 일반적인 언어 모델링 분야에서 다루는 모델들은 아래와 같이 나눌 수 있습니다.
- LSTM-based(single or two layers)
- CNN-based
- Transformer-based(fully-attentive)
- image-text early-fusion(BERT-like)
3.1. LSTM-based Models
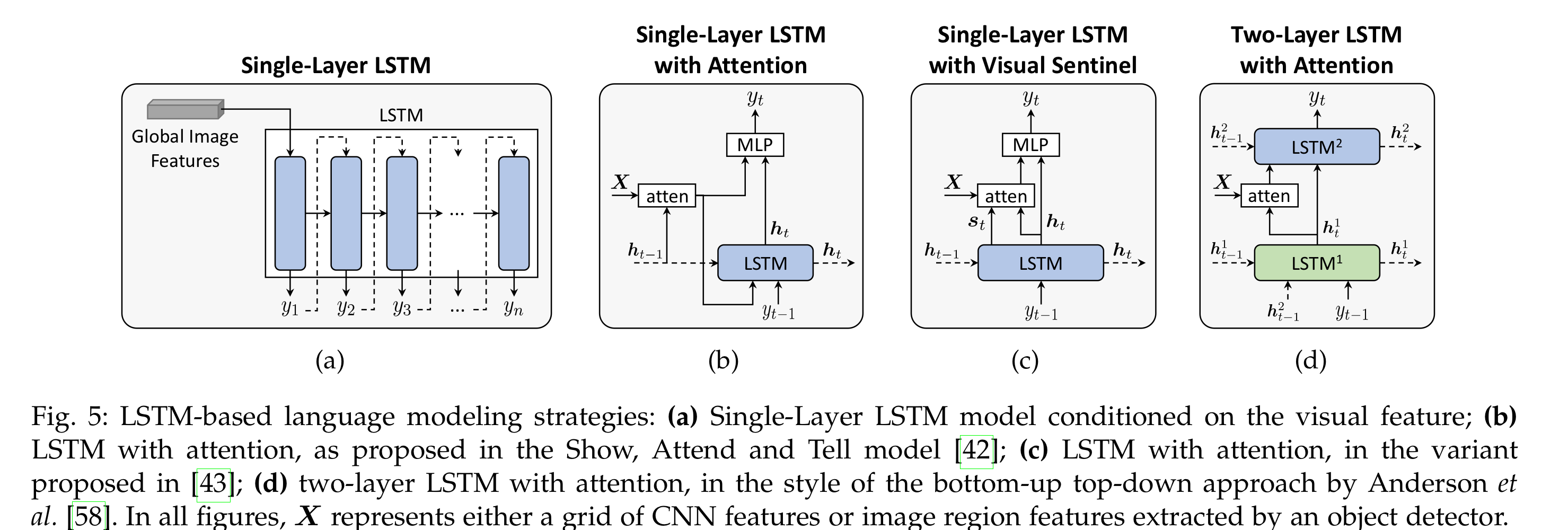
3.1.1. Single-layer LSTM
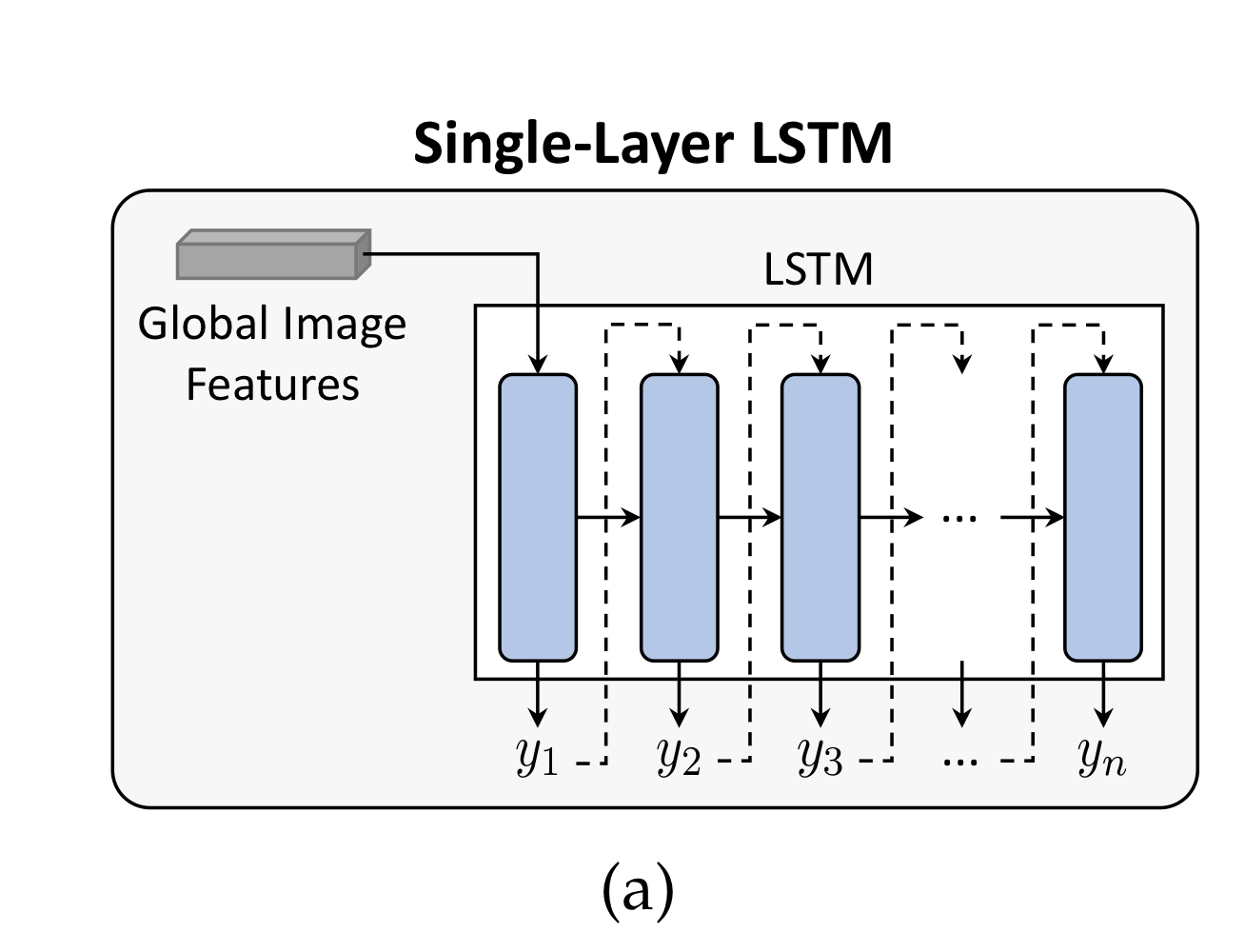
가장 기본적인 LSTM 모델로, Image features가 LSTM의 hidden state로 들어갑니다(initialize).
매 step마다 softmax activation을 활용해 word의 확률 분포를 반환, 최종적인 word를 예측합니다.
확률이 가장 높은 단어를 사용하든, 아니면 상위 n개를 이용해 시퀀스 후보들을 가져가든.
학습 단계에서는, 기본적으로, input words가 ground-truth sentence에서 들어갑니다(teacher forcing).
Inference에서는 당연히 이전에 생성된 단어.
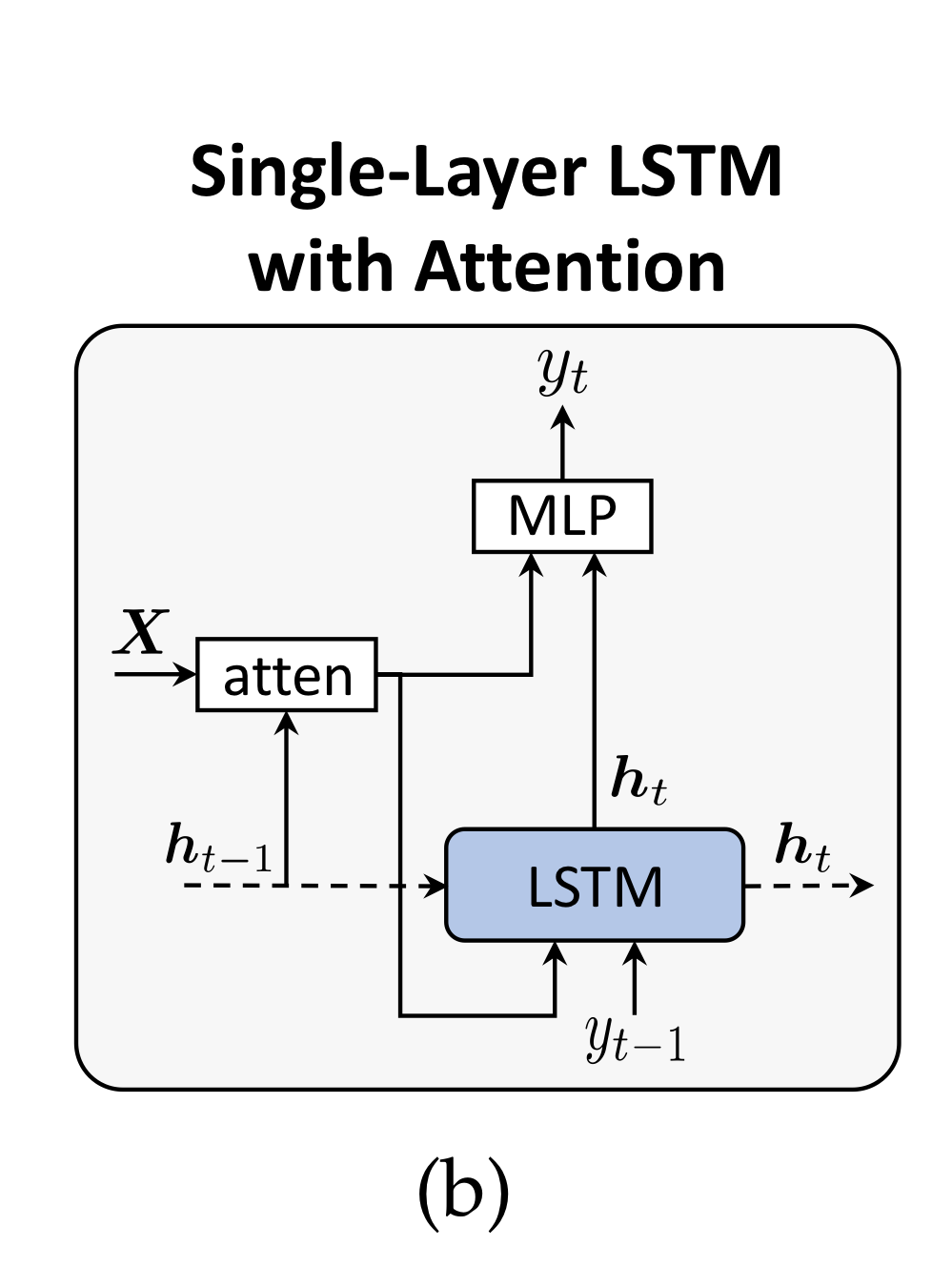
반면, 연구 "Show, Attend and Tell"에서 처음 제안된 아키텍처로, LSTM의 매 time step 마다 Image Encoding 와의 context vector를 연산해 output을 반환하게끔 하는 어텐션 매커니즘을 사용할 수 있습니다.
이제는 사실상의 표준이 된.
그 외에 수 많은 변형 모델들이 존재합니다.
Visual Sentinel
- the, of, on 같은 non-visual featuresdmf 따로 처리하기 위한 visual sentinel 모델(fig 5c)
Hidden state reconstruction
- 두번 째 LSTM을 활용해 previous hidden state를 재구성하는 Hidden state reconsturction모델
- 양방향으로 정보가 흐르는 Bi-Directional LSTM
- 그리고 이 Bi-Directional LSTM에서 나온 두 개의 sentence를 grid visual features와 결합하는 cross-model attention
Multi-state generation
그 외에도, 캡션을 coarse한 중심부 부터 fine한 주변부로 나눠서 캡션을 생성하는 모델도 있습니다.
즉,
- skeleton sentence 생성
- attributes enriching
로 구성됩니다.
각각 LSTM으로 수행.
이런 모델이 강화되면, 위처럼 2개뿐만 아니라 여러 개의 LSTMs을 사용해서 corase한 문장에서 시작해서, 점점 fine한 문장으로 정제되는 coar-se-fine multi-stage framework를 구축할 수도 있습니다.
Semantic-guided LSTM
캡션 생성을 더욱 잘하기 위해 이미지로부터 semantic information을 뽑아내 LSTM에 제공할 수도 있습니다.
즉, semantic information(어떻게 뽑는지는 생략)이 LSTM block의 추가적인 input으로 쓰입니다.
3.1.2. Two-layer LSTM
더욱 높은 수준의 관계를 포착하기 위해 LSTMs의 레이어를 늘릴 수도 있습니다.
for higher-order relations
Two-layers and additive attention
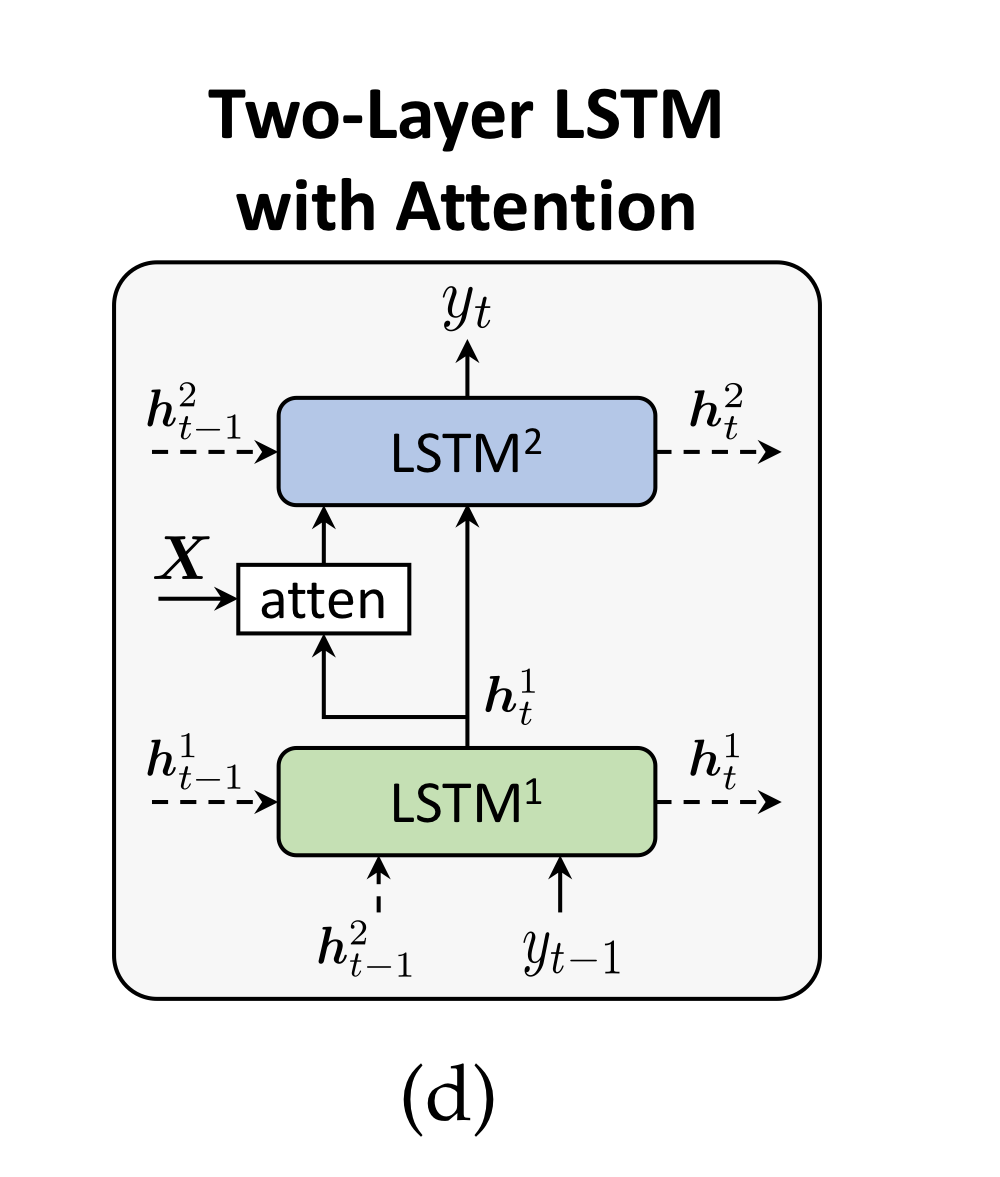
visual attention과 랭귀지 모델링을 더욱 잘 수행하기 위해 고안된 Two-layer LSTM은 bottom-up top-down apporach입니다.
대략적으로 과정을 나타내면 아래와 같습니다.
- LSTM 1 : 이전 단어, 이전 hidden state, mean-pooled image features를 받아 current hidden state를 반환(top-down).
- LSTM 1 : 이를 토대로 image regions에 대한 확률 분포를 additive-attentive한 방식으로 생성.
- LSTM 2 : 그렇게 얻어진 attended image features vectors와 LSTM1이 생성한 hidden state를 받아 최종적인 단어를 예측.
Variants of two-layers LSTM
- Neural Baby Talk
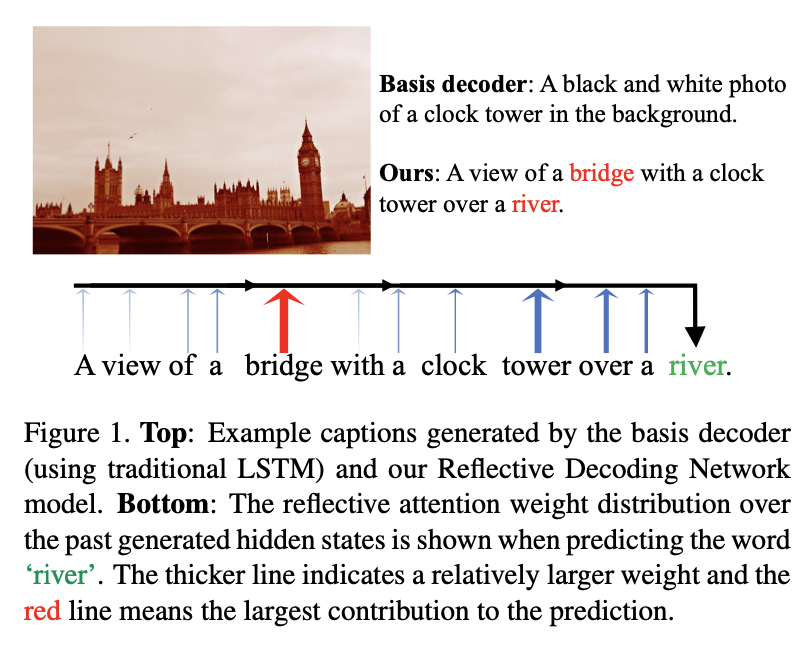
- Reflective attention
- Look back and predict forward
- Adaptive attention time
등 다양한 방법들이 있습니다 !!
보통 과거의 hidden state를 이용해 미래 단어를 예측하거나, 미래 단어를 한 번에 2개씩 예측하거나, content-based networks를 구축하거나..
3.1.3. Boosting LSTM with Self-Attention
몇몇 연구는 additive-attention 대신 self-attention operator를 사용했습니다.
특히, Huang et al의 연구 “Attention on Attention for Image Captioning,”(2019)는 visual self-attention의 끝에서 또 다른 attention을 계산하는 방법을 사용했습니다.
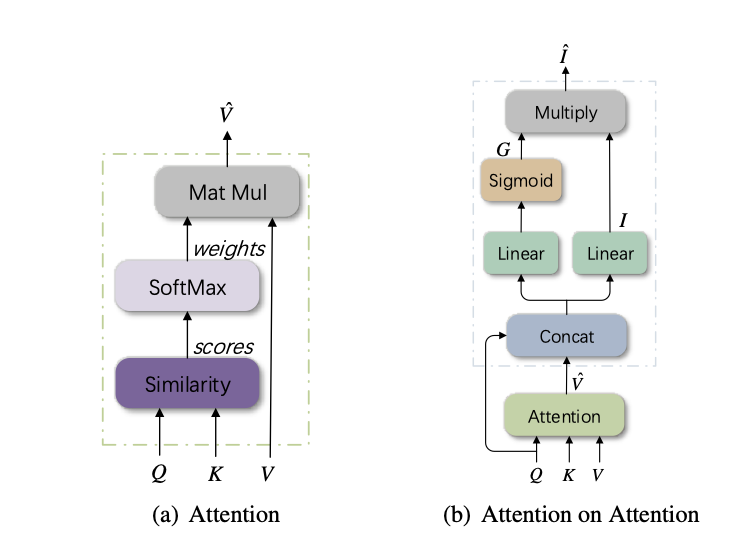
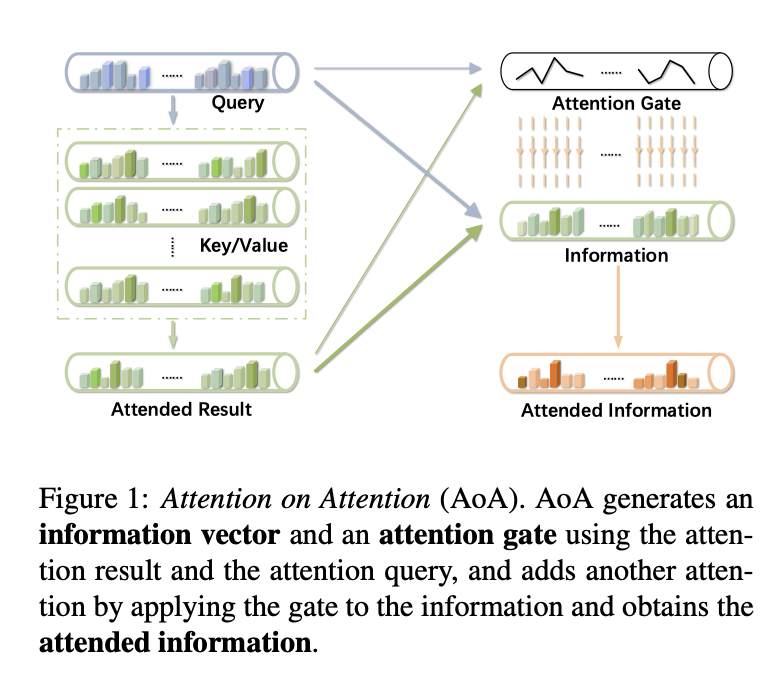
혹은, second-order interaction을 위해서 self-attention 과정을 조금 더 강화하고, visual encoding/language model 성능을 높히는 X-Linear Attention Block 모델도 있습니다.
3.2. Convolutional Language Models
CNN 기반 언어 모델로는 Aneya et al의 모델을 예시로 들 수 있습니다.
J. Aneja, A. Deshpande, and A. G. Schwing, “Convolutional image captioning,” in CVPR, 2018.
CNN 기반 비주얼 인코더로 얻은 global image features가 word embeddings과 합쳐져, CNN으로 다시 들어가 모든 단어가 병렬적으로 학습됩니다.
Inference할 때는 Sequential하게 단어가 생성되구요.
단, 병렬적으로 학습할 때 미래의 정보를 훔쳐보는 것을 방지하기 위해 right-masked convolution을 사용합니다.
병렬적으로 학습하는 데에는 분명한 장점이 있긴 했지만, 성능이 잘 안 나왔을 뿐만 아니라, 병렬적으로 학습하며 성능도 좋은 트랜스포머의 등장으로 인해 인기를 얻지는 못했습니다.
3.3. Transformer-based Architectures
많은 분들이 알다시피, Transformer가 등장한 이후 BERT, GPT 등 의 모델은 언어 모델링 분야에서 사실상의 표준이 됐습니다.
이미지 캡셔닝 또한 어떻게 보면 sequence-to-sequence로 바라볼 수 있기 때문에(Image Encodingssequences) 마찬가지로 트랜스포머 기반 모델들이 많이 쓰였습니다.
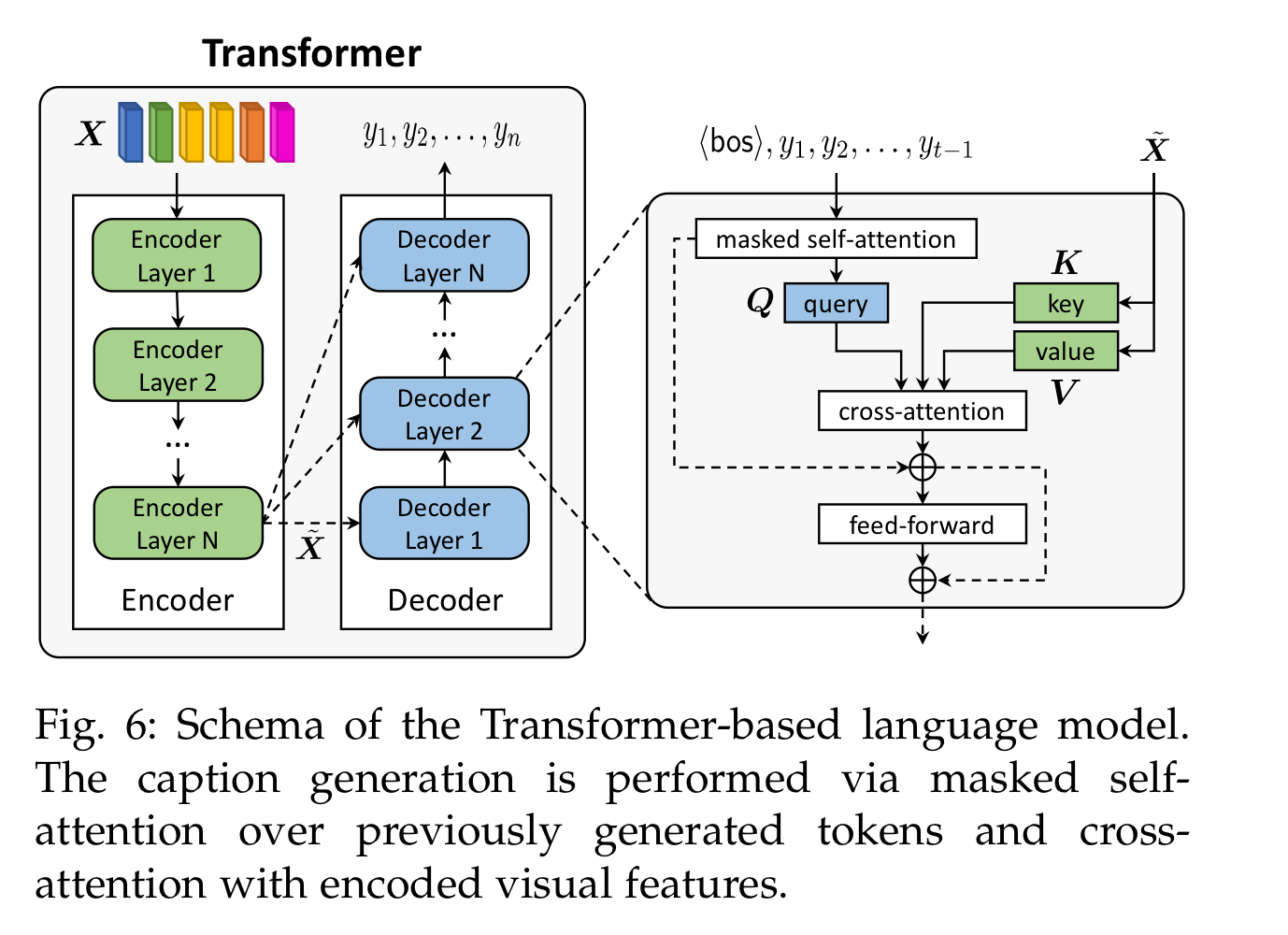
가장 기본적인 트랜스포머 디코더 모델은 words에 대해 masked self-attention을 수행해 query로, 인코더의 마지막 output은 key와 value로 여겨, cross-attention을 수행할 수 있습니다.
마지막으로 feed-forward network를 통과하게 됩니다.
유사도를 게산하는 attention 뿐만 아니라 사실상 Query가 Skip-connection으로 더해진다는 것도 중요합니다.
3.3.1. Gating Mechanisms
Li et al은 external tagger로 얻은 semantic attributes를 image representation과 같이 사용하여 visual & semantic information의 흐름을 컨트롤하는 cross-attention operator를 제안했습니다.
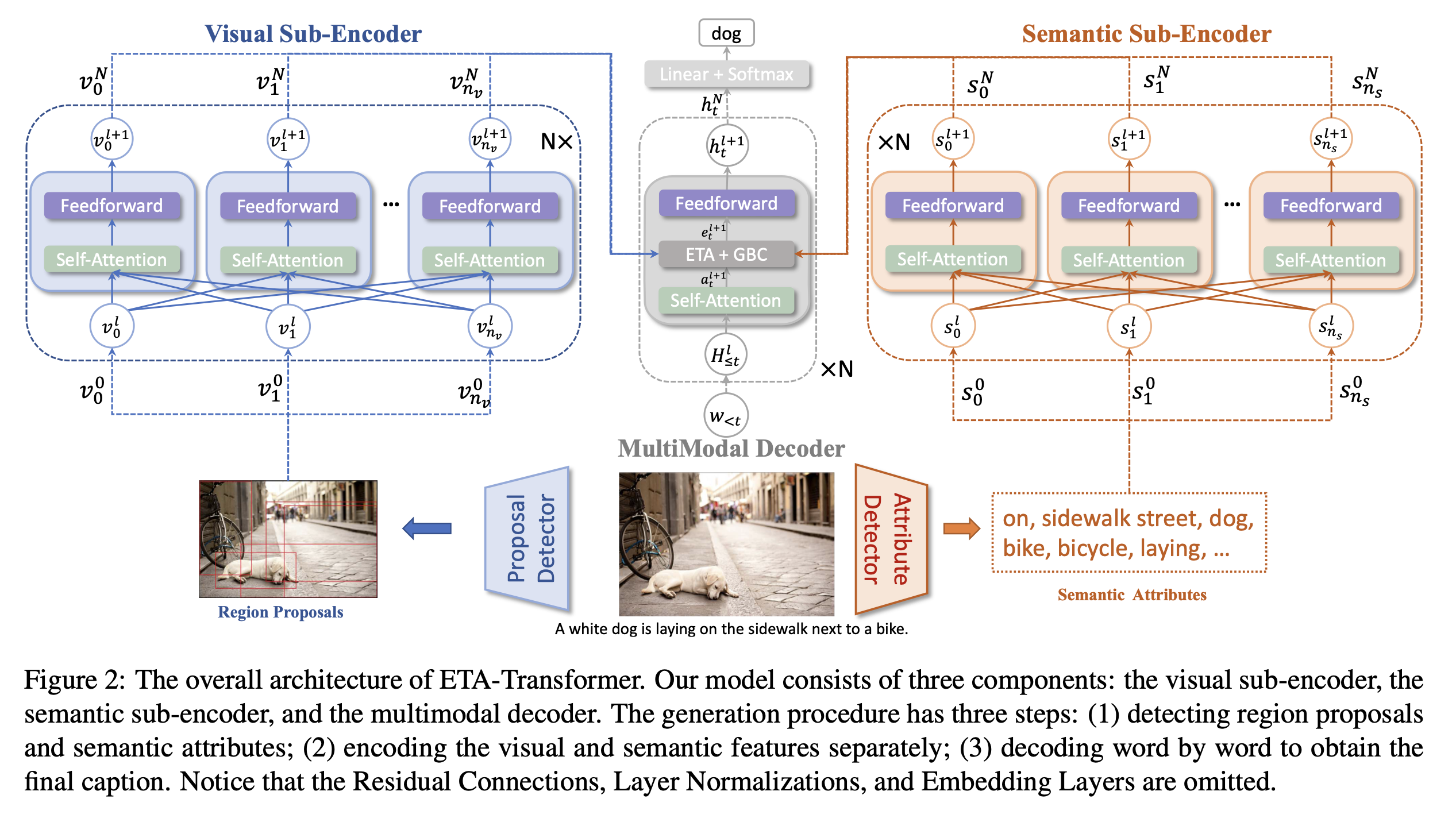
G. Li, L. Zhu, P. Liu, and Y. Yang, “Entangled Transformer for Image Captioning,” in ICCV, 2019.
같은 맥락에서, Ji et al은 global image representation을 활용하기 위해 context gating mechanism을 통합했습니다.
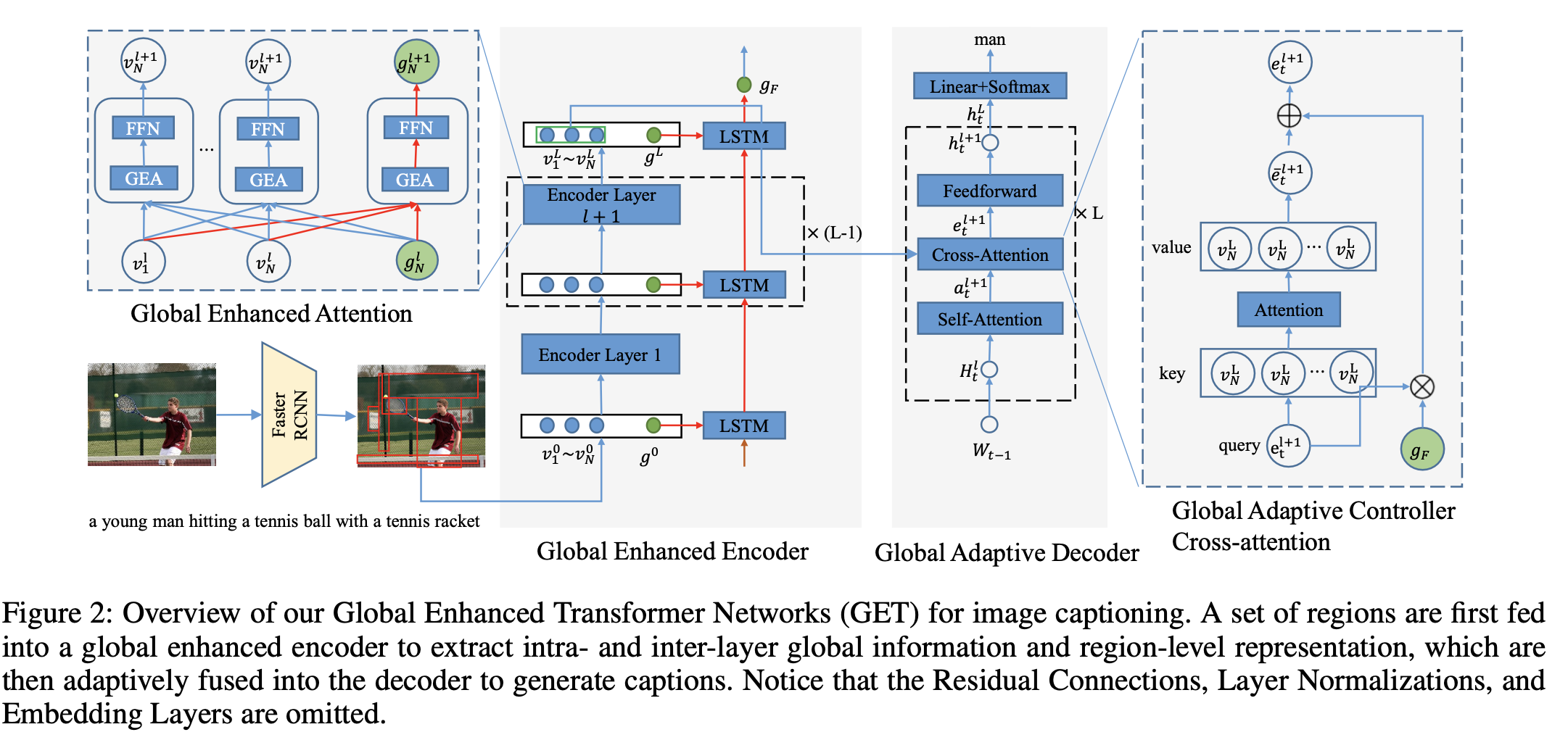
J. Ji, Y. Luo, X. Sun, F. Chen, G. Luo, Y. Wu, Y. Gao, and R. Ji, “Improving Image Captioning by Leveraging Intra- and Inter- layer Global Representation in Transformer Network,” in AAAI, 2021.
(Global Enhanced Transformer Networks)
뿐만 아니라 cross-attention을 인코더의 마지막 레이어에 대해서만 수행하지 않고 모든 인코딩 레이어에 대해 수행하는 방법도 있습니다.
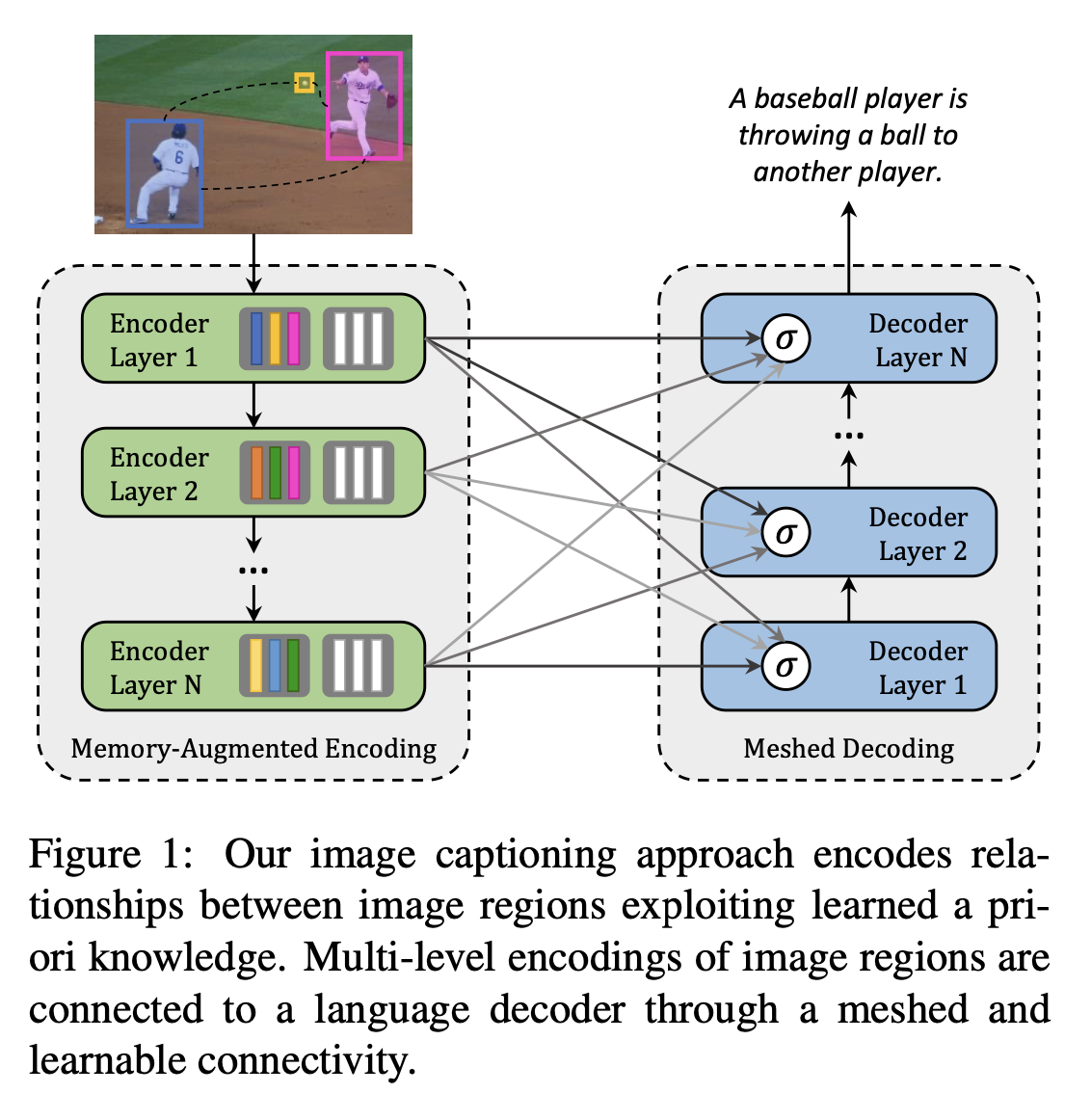
M. Cornia, M. Stefanini, L. Baraldi, and R. Cucchiara, “Meshed-Memory Transformer for Image Captioning,” in CVPR, 2020.
인코더의 모든 레이어에서 생기는 contribution을 독립적으로 다루고, text query를 사용해 이 contribution들에 가중치를 부여하는 방법.
3.4. BERT-like Architectures
encoder-decoder 구조가 이미지 캡셔닝에 널리 쓰이는 방법이긴 했지만, 몇 몇 연구는 visual & textual modalities를 early-stage에서 fusion하는 BERT 기반 구조를 활용했습니다.
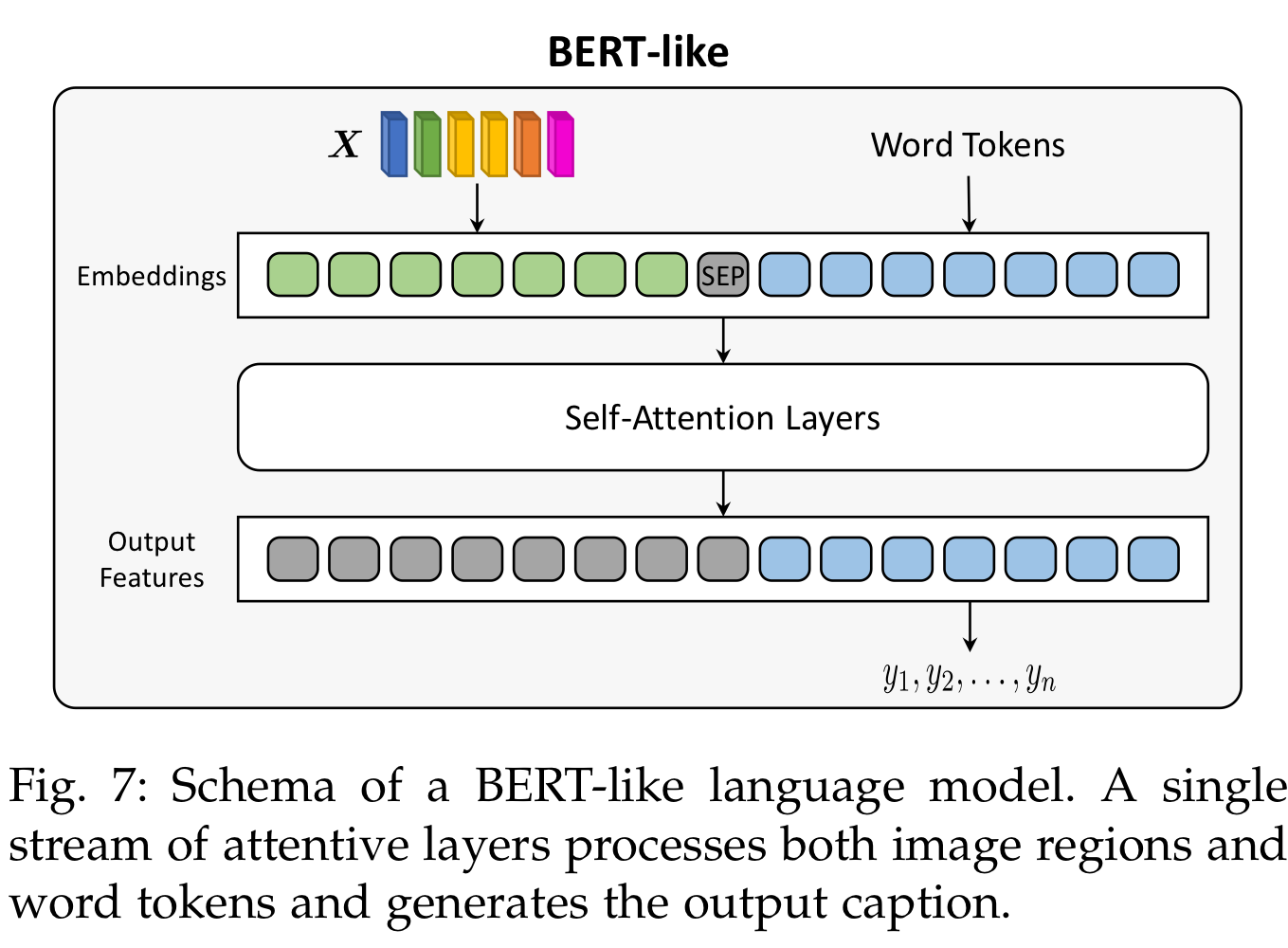
사실, GPT든 BERT든 이런 모델을 사용하는 가장 큰 이유는 large-scale textual copora에 사전학습시킨 파라미터를 사용할 수 있다는 것입니다.
아무튼, 이미지 캡셔닝 분야에서의 첫번째 예시는 Zhou et al의 연구로, visual / textual modalities를 BERT기반 아키텍처를 활용해 융합한 사전학습 연구입니다.
모델은 shared multi-layer Transformer encoder를 사용해 encoding, decoding을 모두 진행했고, large-scale image-caption paris에 사전학습 시킨 다음 image captioning을 위해 fine-tuning했습니다.
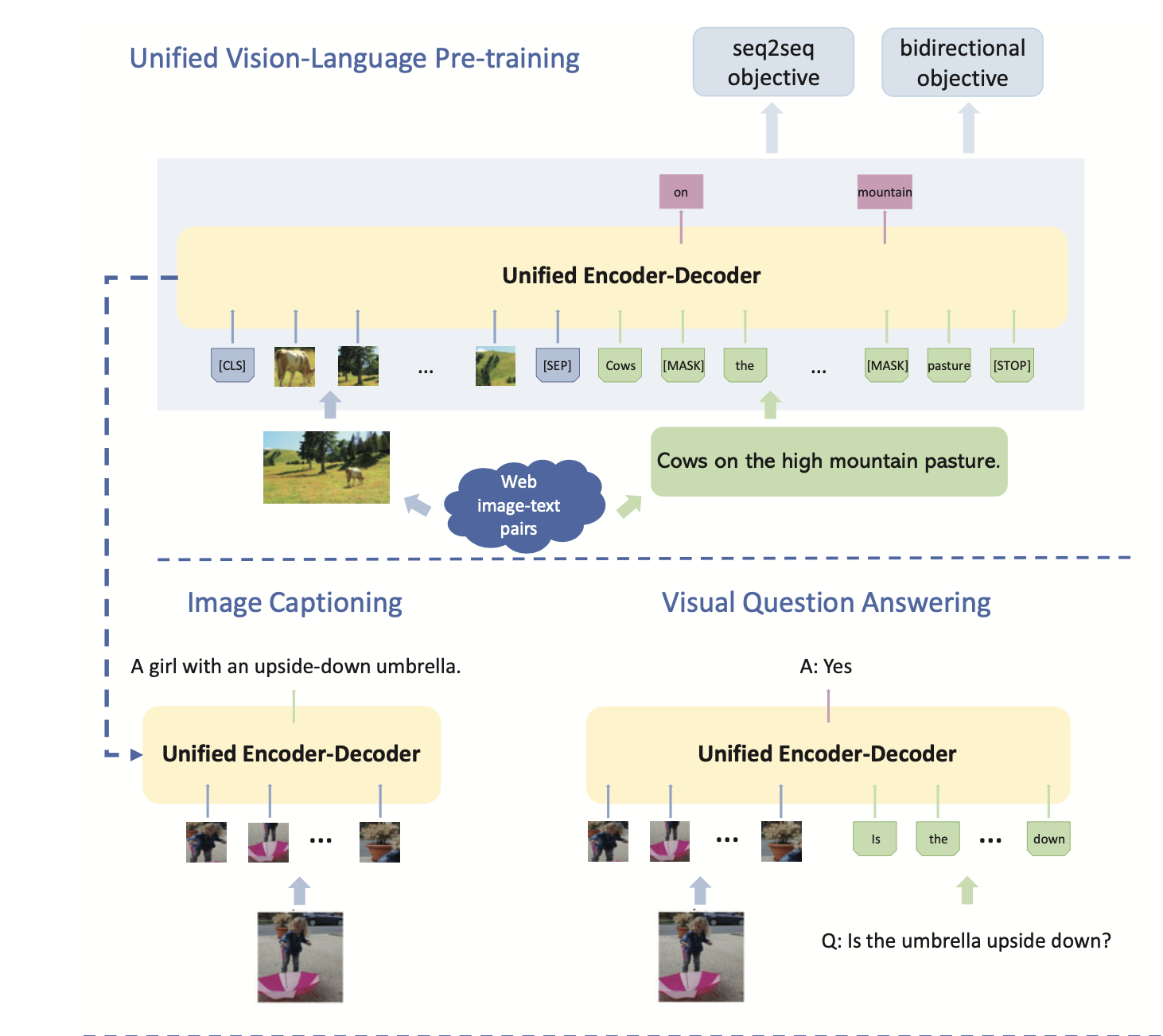
L. Zhou, H. Palangi, L. Zhang, H. Hu, J. J. Corso, and J. Gao, “Unified Vision-Language Pre-Training for Image Captioning and VQA,” in AAAI, 2020.
더 나아가서, Li et al은 object tags를 이미지와 텍스트 사이의 연결고리(anchor point)로 활용해, 더 나은 vision-language joint representation을 학습하는 사전학습 모델을 제안했습니다.
즉, image-text pair가 아닌 [region features - object tags - word tokens] triplet을 받아 더 나은 vision-language alignment를 활용하게 됩니다.
3.5. Non-autoregressive Language model
- pass
3.6. Discussion
Transformer 기반 모델의 성공으로, large-scale dataset에 사전학습시켜서 사용하는 방법론들이 널리 쓰이고 있습니다.
BERT기반 방법론들도 그런 pre-training에 좋은 모델이지만, 생성모델에는 잘 맞지 않습니다(설계적으로).
GPT가 쓰이죠.
그래서, SimVLM같은 사전학습 모델이 개발되기도 했습니다.
4. Training Strategies
이미지 캡셔닝은 이전의 단어들과 이미지를 기반으로 다음 단어를 예측하는 방법이라 할 수 있습니다.
일반적으로는, greedy한 방식(-voca 중 가장 높은 확률단어를 선택)으로 문장을 생성하는 것이 가장 간단한 디코딩 과정이긴 합니다..만은, 때로는 단어 하나가 잘못 나오면 그 이후 문장도 엉망이 되어버리기 때문에 단점도 명확한 방법입니다.
이를 해결하기 위해서는 여러 문장 후보를 고려하는 beam-search 방법을 사용할 수 있습니다.
대부분의 학습 과정은 아래와 같은 요소를 기반으로 합니다.
1. cross-entropy loss
2. masked language model
3. reinforcement learning
4. vision-language pre-training
cross-entropy loss처럼 미분이 가능하지 않은 captioning-specific metric을 최적화하기 위해 reinforcement learning을 사용합니다.
가령, trian 환경과 test 환경 사이의 불일치성을 줄인다거나..
4.1. Cross-Entropy loss
대부분의 이미지 캡셔닝 과정에서 사용하는 loss입니다.
보통 likelihood를 최대화, 즉 negative log likelihood를 최소화하는 방향으로 최적화가 진행됩니다.
(일반적으로는) 아래와 같이 이전 스텝의 ground-truth words와 Image가 순차적으로 주어졌을 때, 다음 스텝의 ground-truth word의 확률을 높혀야 합니다(Loss를 낮춰야 합니다).
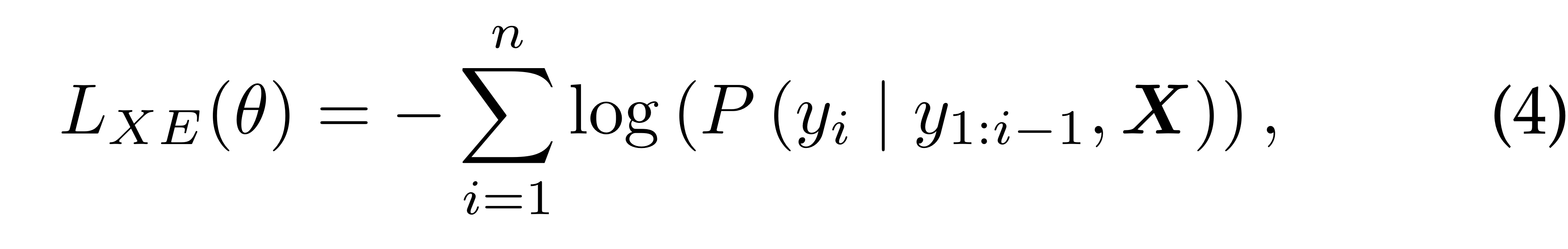
일반적 : teacher forcing
는 전체 랭귀지 모델의 확률분포.
cross-entropy loss는 위 식에서도 알 수 있다 시피 각 단어의 확률을 최적화하는 데 목표를 하지, 전체 문장에 대한 맥락을 고려하지는 않습니다.
어떠한 테크닉도 없이 전통적인 ce-loss만 도입할 경우 exposure bias 문제를 겪을 수 있습니다.
exposure bias : training과 test(validation) 사이의 불일치.
(scsl 등 강화학습 기반 방법으로도 개선 가능)
4.2. Masked Language Model(MLM)
최초의 masked language model은 BERT 알고리즘을 학습할 때 제안됐씁니다.
이 optimization function 뒤에 있는 메인 아이디어는 input tokens sequence의 일부분을 랜덤하게 마스킹하고, 모델이 남아 있는 토큰들로만 하여금 마스킹된 토큰을 예측하게끔 구축하는 것입니다.
애초에 BERT는 양방향이기 때문에 가리지 않는다면 의미 있는 학습을 하지 못할가능성이 높습니다.
4.3. Reinforcement Learning
[38] S. J. Rennie, E. Marcheret, Y. Mroueh, J. Ross, and V. Goel, “Self- critical sequence training for image captioning,” in CVPR, 2017.
Gao, S. Wang, S. Wang, S. Ma, and W. Gao, “Self-critical n-step Training for Image Captioning,” in CVPR, 2019.
- Self Critical Sentence Learning을 BeamSearch와 병행
- 특히, 강화학습은 fine-tuning 단계에서 자주 사용함(평소처럼 학습한 다음, 마지막에)
이는, 평소의의 cross-entropy는 word-level 학습이기 때문에, 강화학습으로 sentence-level의 metric(BLEU, ROUGE, ...)을 강화해주는 역할을 함.
4.4. Large-Scale pre-trained Model
[97] M. Cornia, L. Baraldi, G. Fiameni, and R. Cucchiara, “Universal Captioner: Long-Tail Vision-and-Language Model Training through Content-Style Separation,” arXiv preprint arXiv:2111.12727, 2021.
[100] X. Li, X. Yin, C. Li, P. Zhang, X. Hu, L. Zhang, L. Wang, H. Hu, L. Dong, F. Wei et al., “Oscar: Object-semantics aligned pre- training for vision-language tasks,” in ECCV, 2020.
[101] L. Zhou, H. Palangi, L. Zhang, H. Hu, J. J. Corso, and J. Gao, “Unified Vision-Language Pre-Training for Image Captioning and VQA,” in AAAI, 2020.
[103] P. Zhang, X. Li, X. Hu, J. Yang, L. Zhang, L. Wang, Y. Choi, and J. Gao, “VinVL: Revisiting visual representations in vision- language models,” in CVPR, 2021.
[125]Q. Xia, H. Huang, N. Duan, D. Zhang, L. Ji, Z. Sui, E. Cui, T. Bharti, and M. Zhou, “XGPT: Cross-modal Generative Pre- Training for Image Captioning,” arXiv preprint arXiv:2003.01473, 2020.
