
- 전체보기(62)
- Computer Vision(17)
- cs231n(13)
- Deep Learning(13)
- C++(5)
- 알고리즘(4)
- 코딩테스트(4)
- 추천시스템(4)
- 가상환경(3)
- CNN(3)
- 딥러닝(2)
- DL(2)
- python(2)
- ubuntu(2)
- linux(2)
- 데이터분석(2)
- 데이터 사이언스(2)
- 강화학습(2)
- adp30회(1)
- ML(1)
- python문법(1)
- vscode(1)
- 선형대수학(1)
- 에러해결(1)
- 데이터분석가(1)
- ssh(1)
- adp실기(1)
- 논문(1)
- 강의요약(1)
- adp후기(1)
- notion(1)
- machine learning(1)
- 머신러닝(1)
- 컴퓨터비전(1)
- 책 추천(1)
- jenkins(1)
- 서평(1)
- 강의정리(1)
- 논문리뷰(1)
- adp(1)
- 개발 공부(1)
YOLO 멀티 GPU 학습 시 좀비 메모리 삭제 방법 - CUDA Out of Memory 에러
YOLO 모델을 멀티 GPU(4,5,6,7)로 학습시키려 했으나, 동일한 설정으로 GPU(0,1,2,3)에서는 정상 작동하는데 CUDA Out of Memory 에러가 발생했다.실행 결과, GPU 4,5,6,7에 프로세스는 보이지 않지만 메모리가 점유되어 있는 상태였다

임시
$q(xt|x{t-1}) = N\\left(xt; \\sqrt{1 - \\beta_t} , x{t-1}, \\beta_t I\\right)$$q(xt|x{t-1}) = N\\left(xt; \\sqrt{1 - \\beta_t} , x{t-1}, \\beta_t I\\r
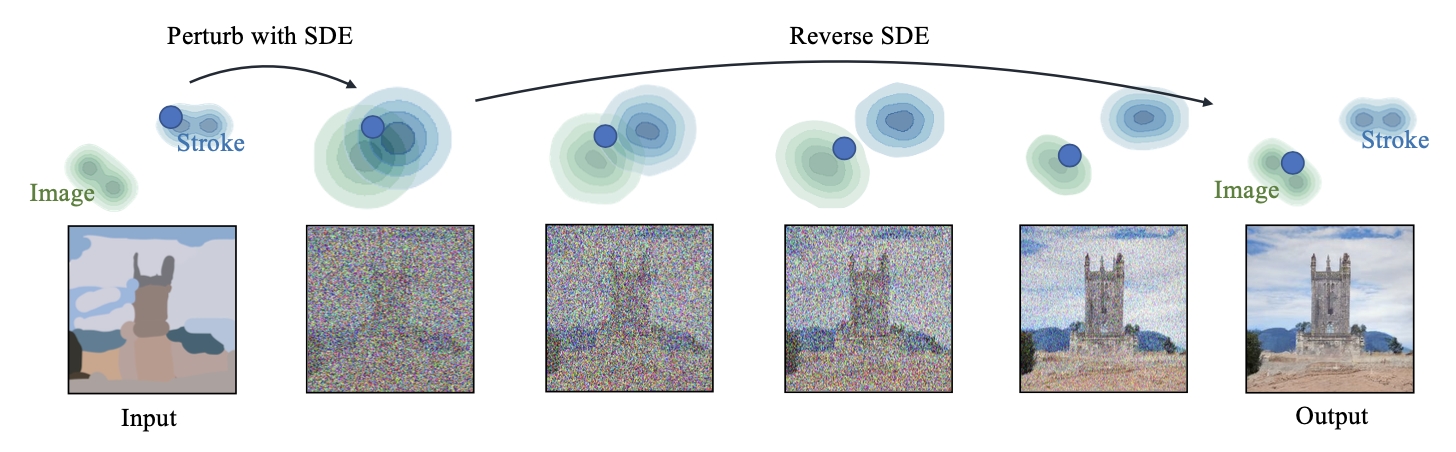
SDEdit
gpt4.5로 작성됨.기존의 GAN(Generative Adversarial Network) 기반 방법들은 사용자의 입력과 사실적 이미지 간 균형을 유지하는 데 어려움이 있었고, 매번 새로운 데이터 수집 및 학습 과정이 필요했다. 이에 대한 대안으로 등장한 것이 바로
LDM (Latent Diffusion Model)
기존의 Diffusion Model은 픽셀 단위에서 동작해서 고해상도 이미지 생성 시 연산량과 시간이 매우 많이 필요했다.LDM = Autoencoder + Diffusion Model1\. 계산 효율성 극대화기존 픽셀 단위 Diffusion Model은 매우 높은 계
Autoencoder, VAE
압축(Encoding) → 복원(Decoding) 과정이미지를 압축해서 중요한 특징만 남김. 중복된 정보나 노이즈는 자연스럽게 제거되어 연산이 가벼움.비지도 학습출력과 입력을 비교하기 때문에 정답 라벨 필요x.Latent Space (잠재 공간): 핵심 특징만 담은 벡

Denoising Diffusion Probabilistic Models(DDPM) - 비전공자(바로 나!)를 위한 정리
사실 dpm도 ddpm을 이해하기 위한 배경 지식인데 클났다. 이미지에 점진적으로 노이즈를 추가하고, 노이즈를 다시 없애면서 원본 이미지를 복원목표:고품질 이미지 생성이미지 복원 등Forward Process$q(xt | x{t-1}) = \\mathcal{N}(xt
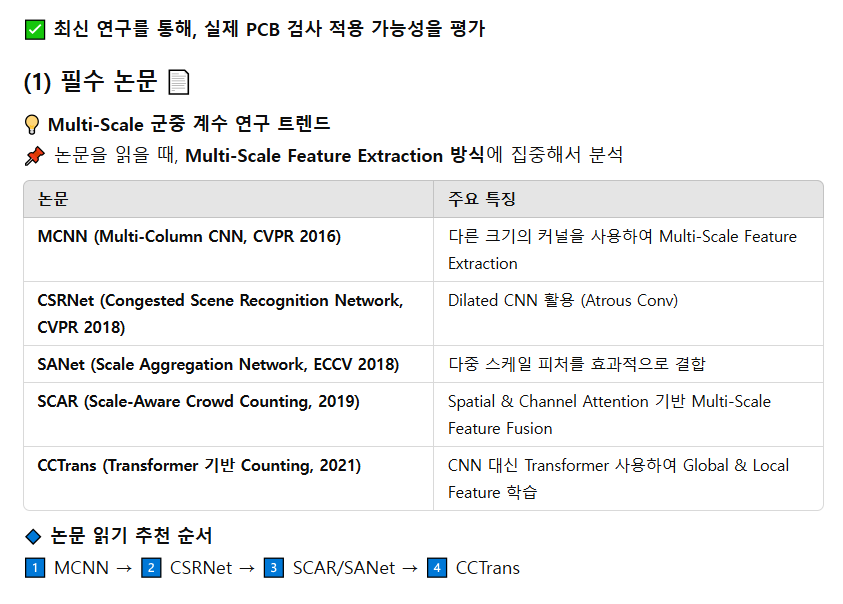
Multi-Scale Embedding을 활용한 Crowd Counting 모델
CNN 백본(VGG-16)과 dilated convolution을 활용하여 넓은 수용영역을 확보하고, 군중 밀집 지역의 밀도를 예측하는 방식.서로 다른 커널 크기를 가진 3개의 병렬 CNN을 사용하여 다양한 스케일의 정보를 학습하는 모델.다중 스케일 특징을 동적으로 조
ASPP (Atrous Spatial Pyramid Pooling)
요즘 multi-scaling 공부가 필요함 1. Atrous convolution (= Dilated Convolution) dilation이 적용된 합성곱 dilation이란 아래 사진과 같이 픽셀 사이에 빈 공간을 사이사이에 넣는 것을 말한다. 수용 영역(Receptive Field)가 확장되어 더 넓은 범위의 정보 학습이 가능. 2. SSP (S...
서버 동작 멈춤 문제 해결: 프로세스 관리
서버가 갑자기 멈추거나 비정상적인 동작을 보일 때, 특정 프로세스가 문제를 일으킬 가능성이 크다.서버에 SSH 또는 로컬로 접속ps -ef: 현재 실행 중인 모든 프로세스를 상세히 출력.| (파이프): ps -ef 명령의 출력을 grep 명령에 전달.grep 사용자명:
C++ 입문 5일차 - 포인터, 네임 스페이스
팀장님이 틈새 C++ 과외해주셨는데 GPT보다 머리에 잘 들어오는 것이다? \*: 포인터&: 참조자::: 범위 지정 연산자std: 네임 스페이스.: 멤버 연산자이렇게 5개의 개념을 중점으로 설명해주셨다.메모리 주소를 저장하는 변수&는 두가지 기능이 있다. 문맥상 기능을
C++ 입문 4일차 - 파일 입출력
프로그램이 외부 파일에서 데이터를 읽고, 파일에 데이터를 쓰는 데에 사용된다.<fstream> 헤더를 사용ifstream: 파일에서 데이터를 읽을 때 사용.ofstream: 파일에 데이터를 쓸 때 사용.fstream: 파일에서 읽고 쓰는 기능을 모두 사용할 때 사
C++ 입문 3일차 - 클래스, 생성자, 소멸자, 상속, 다형성, 추상 클래스, 인터페이스
class: 클래스를 정의할 때 사용하는 키워드.public: 외부에서 접근 가능한 멤버 지정. \- 클래스 내부에서만 사용할 멤버는 private으로 설정할 수 있다.멤버 함수: 클래스 내부에 포함된 함수. 데이터를 처리하는 로직을 포함 구조체를 사용해 학생
UNet 구조
의료 영상 분할(Semantic Segmentation)을 위한 딥러닝 모델로 2015년에 개발됨.오토인코더(autoencoder)와 같은 인코더-디코더(encoder-decoder) 기반 모델인코딩(압축)과 디코딩(복원) 과정을 거치는 U자형 구조.인코딩 단계에서 이
순전파, 역전파, 인코딩, 디코딩
이번 회사에 입사 후 모델 구조를 이해하는데 저 4개의 개념이 너무 어려웠다. 머리론 알겠지만 가슴 속으론 이해하지 못했다. 직접 하드코딩 해보면서 깨달아야지 이해가 되는 돌머리 ㅠ지금은 시간이 없으니까 빠르게 개념만 정리해보자. (GPT canvas 이용)인코딩은 입
Mermaid란 / GPT로 mermaid 코드 추출 / notion에 옮기기
Mermaid는 코드만으로 복잡한 다이어그램을 쉽게 만들 수 있는 강력한 도구다. Markdown과 같은 텍스트 기반 도구들과 결합하면 더욱 효과적으로 기술 문서와 다이어그램을 작성할 수 있다.위 사진은 https://mermaid.live/ 에서 내가
vscode에서 ssh로 서버 접속하는 방법
vscode 켠다.ctrl + shift + p 단축키 눌러서 Remote-SSH: Connect to Host를 클릭.포트 번호 입력하고 enter비밀번호 입력하고 enterCtrl+O 로 오픈할 폴더 위치를 입력할 창을 열고 파일 경로를 입력! 지금 내가 할 프로젝
이미지 증강
데이터 증강이란(Data Augmentation) 모델의 성능을 향상시키기 위해 기존 데이터를 변형하여 새로운 데이터를 생성하는 기법. 주로 딥러닝에서 모델의 일반화 성능을 높이고 과적합(overfitting)을 방지하기 위해 사용된다.
C++ 입문 2일차: 포인터를 이용한 함수 호출, 동적 메모리 할당
1. 포인터를 이용한 함수 호출 (Call by Reference) 함수를 호출할 때, 파이썬에서는 값만 넘겨줬지만, C++에서는 포인터를 사용해서 변수의 주소를 넘겨줄 수 있다. 이렇게 하면 함수가 변수를 직접 수정할 수 있다.