시작하며
오늘부터 본격적으로 머신러닝 파트에 들어갔다. 전반적으로 통계학보다는 할만했지만 내용이 너무 많고 복잡한 내용이 조금씩 있어서 따라가기만 해도 힘든 수업이었던 것 같다.
머신러닝의 이해
AI / ML / DL
- AI
- 인간의 학습, 추론 등 다양한 능력을 인공적으로 구현하려는 분야
- 인간에게 어려운 과업을 컴퓨터는 쉽게 해결
- ML
- 데이터에 내재되어 있는 패턴을 학습
- 유의미한 정보를 추출하여 예측
- 다양한 알고리즘을 포괄
- DL
- 인공신경망 기반 고도화된 머신러닝 기법
- 다층 구조를 통해 복잡한 패턴과 특징을 학습 가능
- 컴퓨터 비전, 이미지 분류, 자연어 처리 분야에서 사용
머신러닝의 종류
- 머신러닝은 지도학습, 비지도학습 및 강화학습으로 구분
- 지도학습 : 정답이 있는 데이터를 학습
- 타겟의 형태에 따라 회귀와 분류로 구분
- 비지도 학습 : 타겟이 없어 패턴 및 구조를 파악하는 데 중점
- 차원 축소(열)와 군집화(행), 연관 규칙(장바구니 분석)으로 구분
- 강화 학습 : 에이전트가 환경과 상호작용하면서 보상을 최대화하는 방향으로 행동을 학습
- 지도학습 : 정답이 있는 데이터를 학습
머신러닝 알고리즘의 종류
분류
- Logistic Regression
- Decision Tree
- Naive Bayes
- kNN(k-nearest neighbors)
- Random Forest
- Gradient Boosting, XGBoost, LGBM
- Support Vector Machine
- ANN(Artificial Neural Network)
회귀
- Linear Regression
- Regularized Linear Regression
- Regression Tree
- kNN(k-nearest neighbors)
- Random Forest
- Gradient Boosting, XGBoost, LGBM
- Support Vector Machine
- ANN(Artificial Neural Network)
차원 축소
- PCA(Principal Component Analysis)
- t-SNE(Stochastic Neighbor Embedding)
- SVD(Singular Value Decomposition)
- MDS(Multi-Dimensional Scaling)
- Factor Analysis
군집화
- Hierarchical Clustering
- k-means Clustering
- k-medoids Clustering
- DBSCAN
- SOM(Self-Organizing Map)
연관 규칙 및 추천
- MBA(Market Basket Analysis)
- Sequence MBA
- Collaborative Filtering
지도학습
지도학습의 종류
- 타겟이 연속형이면 회귀모델(Regression) 사용
- 연속적인 수치 예측값을 반환
- 실제값과 예측값 사이의 오차를 최소화하는 모델 파라미터를 학습
- 타겟이 범주형이면 분류모델(Classification) 사용
- 범주가 두 개일 때 이진 분류, 세 개 이상일 때 다항 분류를 수행
- 각 범주에 대한 예측 확률(0~1)과 함께 예측값(라벨)을 반환
- 실제값에 가까운 확률을 출력하도록 모델 파라미터를 학습
지도학습 프로세스
- 문제 선정
- 데이터셋 준비
- 데이터셋 분할 : 훈련셋, 검증셋, 테스트셋으로 분할
- 훈련셋 : 모델 학습용
- 검증셋 : 최종모델 선택용
- 테스트셋 : 일반화 능력 및 최종 테스트용
- 모델 학습
- 최적 모델 선택
- 여러 후보 모델에 동일한 검증셋을 정용하여 예측값 생성 후 성능 지표 계산
- 성능 지표를 바탕으로 성능이 가장 우수한 모델을 최적 모델로 선정
데이터셋 분할 방법
- 데이터셋이 충분히 크다고 판단되면 자료분할(Hold-out Validation) 방식 사용
- 데이터셋이 작다고 판단되면 k폴드-교차검증(k-folds Cross Validation) 방식 사용
- 전체 데이터를 훈련셋과 테스트셋으로 분할
- 훈련셋을 k개로 등분
- k-1개로 모델 학습 → 남은 1개로 예측값 생성하여 성능 지표 계산
- k번 반복하여 얻은 성능 지표의 평균을 해당 모델의 성능으로 반영
지도학습의 원리
- 지도학습은 새로운 입력에 대한 예측값 를 잘 맞추는 모델 파라미터 를 찾는 것
- 모델 파라미터가 많으면, 모든 조합을 무작위로 시도하는 것이 비효율적
- 경사하강법과 같은 최적화 기법 사용
- 경사하강법은 목적 함수의 기울기를 계산하고, 그 반대 방향으로 일정한 보폭(학습률) 만큼 이동시키는 것을 반복
- 손실함수를 사용하여 비용 함수(목적 함수)를 최솟값(Global Minimum)에 수렴하게 하는것이 목적
경사하강법 프로세스
- 모델 파라미터 를 무작위로 초기화
- 현재 파라미터에서 비용 함수의 기울기를 계산
- 기울기의 반대 방향으로 보폭(학습률)만큼 이동하여 파라미터를 업데이트
- →
- 수렴 조건을 만족하면 종료
학습률
모델 파라미터 : 모델이 찾아내는 파라미터
하이퍼파라미터 : 사람이 지정하는 파라미터
- 목적 함수의 전역 최솟값을 찾는 속도에 큰 영향을 미치는 하이퍼파라미터
- 학습률이 너무 큰 경우
- 탐색 속도 빠름
- 최솟값을 지나쳐 발산할 위험이 있음
- 학습률이 너무 작은 경우
- 이동 거리가 작아져 수렴 속도가 느려짐
- 반복 횟수가 늘어나 연산 비용 증가
- 적절한 학습률 설정을 위해 경험적 실험과 스케쥴링 기법 활용
목적 함수 : 손실 함수와 비용 함수
- 경사하강법의 목표는 실제값과 예측값 간의 차이를 최소화하는 모델 파라미터를 찾는 것
- 손실 함수(Loss, L)는 개별 데이터 포인트(행)가 모델 예측에 얼마나 어긋났는가를 계산
- 실제값과 예측값 차이를 오차라고 함
- 비용 함수(Cost, J)는 전체 데이터셋에 대한 손실의 평균 또는 합계를 계산하여 모델 전체의 성능을 평가
- 손실 함수(Loss, L)는 개별 데이터 포인트(행)가 모델 예측에 얼마나 어긋났는가를 계산
회귀모델 비용 함수 : Mean Squared Error
- 회귀모델의 비용 함수는 오차를 최소화하는 파라미터를 찾는 것
- 대표적으로는 Mean Squared Error(MSE)가 있음
- 목적 함수가 최솟값일 때의 파라미터
회귀모델 비용 함수의 기울기
- 회귀모델의 비용 함수를 j번째 특성의 파라미터로 편미분한 기울기
- 특성의 파라미터 업데이터 공식
- →
- = 모든 변수에 대한 파라미터 벡터
- = 모든 변수에 대한 편미분의 벡터
- →
분류모델
- 분류모델은 특성의 선형 결합을 활성화 함수에 대입하여 예측값을 얻음
- Linear Regression - identity
- Logistic Regression - sigmoid
- Softmax Regression - softmax
- Perception - step
분류모델 비용 함수 : Cross Entropy
- 분류모델의 비용 함수는 오차를 최소화하는 파라미터를 학습하는 것
- 대표적으로는 Cross Entropy, Log Loss가 있음
- 동일한 공식이지만 ML/DL과 통계학에서의 용어 차이
- 손실 함수에서 실제값이 1이면 첫 번째 항목만 남고, 0이면 두 번째 항목만 남음
- 의 로그값은 음수이므로, 마이너스 부호를 추가하여 양수로 변환
분류모델 비용 함수의 기울기
- 분류모델의 비용 함수를 j번째 특성의 파라미터로 편미분한 기울기
- 특성의 파라미터 업데이터 공식(회귀모델과 같음)
- →
- = 모든 변수에 대한 파라미터 벡터
- = 모든 변수에 대한 편미분의 벡터
- →
훈련 데이터셋 규모의 중요성
- 일반화 능력 향상 가능
- 훈련 데이터셋의 규모가 클수록 다양한 패턴과 변동성을 학습 가능
- 새로운 데이터에 대한 일반화 능력 향상
- 훈련 데이터셋이 작을 경우 특정 데이터에 과적합할 가능성이 높음
- 새로운 데이터에 대한 예측 성능 저하
- 복잡한 모델 학습 가능
- 딥러닝 모델은 파라미터의 수가 매우 많음
- 효과적으로 학습하기 위해서는 대규모의 훈련 데이터셋이 필요
- 드문 패턴 대응 가능
- 드문 패턴에 효과적으로 대응 가능
훈련 데이터셋 품질의 중요성
머신러닝 및 딥러닝 모델의 학습 시간 단축과 예측 정확도 향상에 결정적인 영향을 줌
- 정확한 레이블링의 중요성
- 타겟에 대한 레이블링이 정확하지 않으면 모델은 올바른 패턴을 학습할 수 없음
- 데이터의 다양성과 대표성 필요
- 실제 환경에서 발생할 수 있는 다양한 상황과 조건을 포함해야 안정적으로 동작
- 노이즈와 이상치의 최소화
- 노이즈가 많으면 모델이 불필요한 패턴을 학습
- 이상치가 많으면 편향에 영향을 받음
회귀모델 성능 평가 기준
- 회귀모델은 타겟이 연속형 벡터이므로 오차를 계산하여 성능을 평가
- 개별 오차를 단순히 합산하면 결과가 0에 수렴할 수 있음
- 이를 방지하기 위해 오차를 제곱하거나 절대값을 사용
- 머신러닝 알고리즘은 MSE, 사람은 해석하기 쉬운 RMSE를 많이 사용
회귀모델 성능 평가 지표
| 구분 | 상세 내용 | 공식 | 평가 |
|---|---|---|---|
| MSE, RMSE | • MSE는 오차를 제곱하여 평균을 계산한 값 • MSE는 절대적인 차이를 평가하므로 이상치에 민감 • RMSE는 MSE의 양의 제곱근 | MSE : RMSE : | 0에 가까울수록 좋음 |
| MSLE, RMSLE | • MSLE는 로그 오차를 제곱하여 평균을 계산한 값 • MSLE는 상대적인 차이를 평가하므로 비율적인 오류에 민감 • RMSLE는 MSLE의 양의 제곱근 | MSLE : RMSLE : | 0에 가까울수록 좋음 |
| MAE | • MAE는 오차의 절대값에 대한 평균을 계산한 값 • MAE는 오차의 크기를 그대로 평가하므로 이상치에 덜 민감 | MAE : | 0에 가까울수록 좋음 |
| MAPE | • MAPE는 실제값 대비 오차의 백분율 평균을 계산한 값 • MAPE는 오차의 상대적인 비율로 평가하므로 값의 크기에 관계없이 다양한 데이터 간의 비교가 가능 | MAPE : | 0~1의 비율 |
- 의 진수는 0보다 커야함
- 에 1을 더함
분류모델 성능 평가 기준
- 분류모델을 선택할 때, 정확도 또는 서로 다른 정도를 나타내는 오분류율 사용
- 다수 범주에 초점을 맞춘 가중편균된 값
- 소수 범주를 제대로 분류하지 못하는 모델도 높은 값을 가질 수 있음
- 타겟의 각 범주별 비율이 비슷할 때 효과적인 지표
- 불균형 데이터의 경우 정확도보다는 민감도와 정밀도가 더 중요한 지표로 간주
분류모델 성능 평가 지표
- 혼동 행렬(Confusion Matrix)은 실제값과 예측값 도수를 성분으로 갖는 행렬
- 실제값을 얼마나 다르게 예측했는지 확인
- 예측 라벨로 계산
- 민감도와 정밀도가 상반된 방향으로 변화하는 경우가 흔히 발생
- F1 점수는 민감도와 정밀도의 조화평균이며 두 지표가 모두 높아야 큰 값을 가짐
- ROC 곡선은 예측 확률을 기반으로 시각화 함
- x축이 1-특이도, y축이 민감도
- 왼쪽 위 모서리에 가장 가까운 모델이 좋은 모델
- 곡선 아래 면적인 AUC 값이 가장 큰 모델이 좋은 모델
혼동 행렬
- Positive는 관심있는 소수 범주로 설정
- TP : 모델이 긍정으로 예측 → 실제도 긍정
- FP : 모델이 긍정으로 예측 → 실제는 부정
- FN : 모델이 부정으로 예측 → 실제는 긍정
- TN : 모델이 부정으로 예측 → 실제도 부정
혼동 행렬 성능 평가 지표
| 구분 | 상세 내용 | 공식 | 평가 |
|---|---|---|---|
| 정확도(Accuracy) | • 정확도는 전체 데이터에서 실제값과 예측값이 일치하는 비율 • 데이터 전체에 중점을 둔 평가 지표 | 0~1 사이의 값 1에 가까울수록 좋음 | |
| 민감도(Sensitivity) | • 민감도는 실제값이 긍정인 건에서 분류모델이 맞춘 비율 • 재현율(Recall) 또는 참긍정비율이라고도 함 | 0~1 사이의 값 1에 가까울수록 좋음 | |
| 정밀도(Precision) | • 정밀도는 예측값이 긍정인 건에서 실제값도 긍정인 건의 비율 • 분류모델에 중점을 둔 평가 지표 | 0~1 사이의 값 1에 가까울수록 좋음 | |
| 특이도(Specificity) | • 특이도는 실제값이 부정인 건에서 분류모델이 맞춘 비율 | 0~1 사이의 값 1에 가까울수록 좋음 | |
| 1-특이도 | • 1-특이도는 실제값이 부정인 건에서 분류모델이 틀린 비율 • 거짓긍정비율(FPR)이라고도 함 | 0~1 사이의 값 0에 가까울수록 좋음 |
혼동 행렬 특징
- 정확도는 다수 범주에 크게 영향 받음
- 민감도와 정밀도가 높을수록 좋음
- 민감도/정밀도 ⬆️ = 정확도 ⬆️
- 정확도 ⬆️ ≠ 민감도/정밀도 ⬆️
- 민감도와 정밀도는 trade-off 관계
- F1 점수 : 민감도와 정밀도의 조화평균
- 민감도와 정밀도가 동시에 높은 분류모델을 선택하기 위함
- 민감도와 특이도는 반비례 관계
다중 분류모델의 예측 라벨링
- 모델이 로짓 점수를 산출하면 Softmax 변환을 통해 확률로 변환
- 이진 분류 : 시그모이드 → 로짓 → 확률로 변환
- 다중 분류 : 소프트맥스 → 로짓 → 확률로 변환
다중 분류모델의 혼동 행렬
- 민감도와 정밀도는 one-vs-all 방식으로 각 클래스마다 계산
- 정확도는 각 클래스별 TP의 합계를 전체 샘플 수로 나누어 계산
ROC 곡선
- ROC 곡선은 분류모델의 성능을 평가하는 그래프
- x축 : 1-특이도(FPR)
- y축 : 민감도(TPR)
- 항상 (0, 0)과 (1, 1)을 지남
- 왼쪽 위 모서리에 가까울수록 좋음
- 모든 관측값을 N으로 → (0, 0)
- 모든 관측값을 P으로 → (1, 1)
AUC
- AUC(Area Under Curve)는 ROC 곡선 아래의 면적
- 분류모델의 성능을 정량적으로 나타냄
- ROC 곡선이 왼쪽 위 모서리에 가까울수록 1에 근접
- 랜덤 모델의 ROC 곡선의 AUC 값은 0.5
- AUC가 0.5 미만인 모델은 사용할 가치가 없음
PR 곡선
- 분류모델의 성능을 평가하는 그래프
- x축 : 민감도
- y축 : 정밀도
- 트레이드오프 관계로 인해 한쪽을 높이면 다른 쪽이 낮아지는 경향이 있음
- 오른쪽 위 모서리에 가까울수록 더 우수한 모델로 평가
- PR 곡선 아래 면적은 AP(Average Precision)이라고 함
- PR 곡선은 불균형이 심한 데이터셋에서 ROC곡선보다 모델의 성능을 더 잘 반영
ROC vs PR 곡선
| 구분 | ROC 곡선 | PR 곡선 |
|---|---|---|
| 축 | • X축 : FPR(False Positive Rate) • Y축 : TPR(True Positive Rate, Recall) | • X축 : Recall(재현율), Sensitivity(민감도) • Y축 : Precision(정밀도) |
| 강조점 | • 전체 클래스 구분 능력 | • 소수 클래스 예측 성능 |
| 불균형 데이터 | • 성능이 과대 평가됨 | • 불균형 데이터에서 성능을 잘 반영함 |
| 무작위 추측 | • 대각선(AUC = 0.5) | • 양성 비율에 해당 |
| 주요 용례 | • 데이터가 균형적이거나 양성과 음성 클래스 모두 중요할 때 | • 데이터가 불균형이거나 소수 클래스가 더 중요한 경우 |
| 평가 지표 | • ROC, AUC | • PR AUC(AP) |
모델의 복잡도와 오차의 관계
- 총오차는 편향 제곱과 분산의 합
- 학습 초기에는 모델이 과소적합 상태에 있어 편향 제곱이 높음
- 학습이 진행되면서 데이터를 더 잘 학습하게 되어 편향은 감소
- 학습이 과도하게 진행되면 모델이 훈련 데이터에 과적합 상태가 되면서 분산이 증가
| 훈련셋의 성능 | 검증셋의 성능 | 판단 결과 |
|---|---|---|
| 높음 | 높음 | 성능 좋은 모델 |
| 높음 | 낮음 | 과대적합 의심(기피 상황) |
| 낮음 | 낮음 | 과소적합 의심(알고리즘 변경) |
| 낮음 | 낮음 | 매우 드문 사례(샘플링 문제) |
비지도학습의 종류
- 차원 축소
- p개의 열을 m개로 축소하는 기법
- 주로 주성분 분석을 활용
- 군집화
- n개의 행을 k개의 군집으로 나누는 과정
- 전체 관측값(행) 중에서 거리가 가까운 행들을 같은 군집으로 묶는 방식
- 군집화는 계층적 군집화와 비계층적 군집화로 구분
- 연관 규칙(장바구니 분석)
- 조건부 확률을 활용하여 연관성이 높은 규칙을 발견
- 추천 시스템이나 마케팅에 활용
- 지지도, 신뢰도, 향상도
- 너무 뻔한 규칙 X
- 실행 불가능한 규칙 X
스케일링 및 인코딩
데이터 변환
- 머신러닝의 목표는 타겟 벡터의 실제값과 모델이 예측한 값의 차이를 최소화 하는 것
- KNN, Clustering과 같은 거리 기반 알고리즘에서는 변수 간 거리 계산이 핵심
- 수치형 변수들의 스케일을 맞추는 정규화(Normalization) 과정 필수
- 평균 0, 표준편차 1로 표준화(Standardization)를 적용하는 것이 일반적
데이터 표준화
- 연속형 데이터를 평균이 0, 표준편차가 1인 분포로 변환하는 과정
- 거리 기반 알고리즘에서는 변수마다 스케일이 다르면 거리 계산이 왜곡됨
- 스케일 차이(표준편차)를 제거하여 거리 계산이 공정
- 릿지와 라쏘 같은 정칙화된 회귀모델을 학습하기 전 데이터 표준화를 실행
- 수렴 속도와 수치 안정성 향상
- 평균과 표준편차는 이상치에 민감
- 이상치가 있는 데이터를 표준화하면 분포가 왜곡될 수 있음
- 로버스트 정규화나 로그 변환 등을 고려
StandardScaler사용 코드
from sklearn.preprocessing import StandardScalerscaler = StandardScaler()
scaled = scaler.fit_transform(X=df)StandardScaler클래스는 표준편차의 자유도로 n을 사용- DF의
describe메서드는 표준편차의 자유도로 n-1 사용
pd.DataFrame(data=scaled, columns=df.columns).describe().round(3)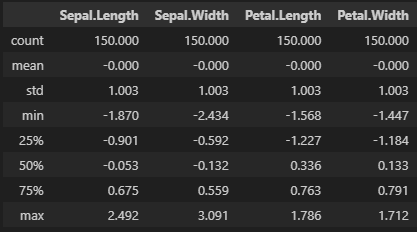
pd.DataFrame(data=scaled, columns=df.columns).std(ddof=0)
# Sepal.Length 1.0
# Sepal.Width 1.0
# Petal.Length 1.0
# Petal.Width 1.0
# dtype: float64zscore사용 코드
from scipy.stats import zscorescaled = pd.DataFrame(data=zscore(a=df, ddof=1), columns=df.columns)
scaled.describe().round(3)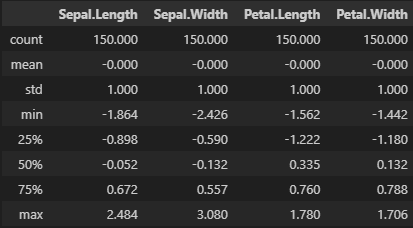
최소-최대 정규화
- 수치형 변수를 0~1의 값으로 변환하는 기법
- 모든 수치형 변수의 범위를 (0, 1)로 동일하게 맞춰 변수 간 비교가 쉬워짐
- 상대적인 위치를 직관적으로 파악할 수 있음
- 최솟값, 최댓값이 이상치일 경우 전체 스케일이 심하게 왜곡될 수 있음
- 로버스트 정규화나 로그 변환 등 고려
MinMaxScaler사용 코드
from sklearn.preprocessing import MinMaxScalerscaler = MinMaxScaler()
scaled = scaler.fit_transform(X=df)
pd.DataFrame(data=scaled, columns=df.columns).describe().round(3)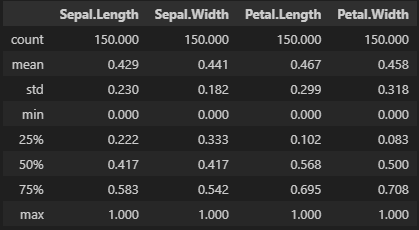
로버스트 정규화
- 중위수와 사분범위를 이용하여 데이터를 변환하는 기법
- 중위수가 0, 사분범위가 1이 되도록 변환
- 이상치가 많은 경우 사용하는 것이 적절
- 정규화된 값들의 범위가 넓어질 수 있음
- 이상치가 중심값에서 밀려나 두드러지게 나타날 수 있음
범주형 특성의 변환 : 인코딩
- 원-핫 인코딩
- 명목형 변수의 각 범주마다 0, 1 값을 갖는 변수를 생성
- 범주가 많으면 열 개수가 급격히 증가
- 서열형 변수는 순서 정보를 잃어버림
- 더미 변수
- 원-핫 인코딩에서 첫 번째 범주를 제거한 형태
- 다중공선성 문제를 방지하기 위해 사용
- 레이블 인코딩
- 명목형 변수를 0부터 시작하는 정수로 변환
- 변수의 고유값을 사전순으로 정렬해 ID를 부여
- 순서가 없는 변수에 정수를 부여하면 수치 간 거리를 실제 의미로 오해할 수 있음
- 오디널 인코딩
- 서열형 변수를 0부터 시작하는 실수로 변환
- 타겟 인코딩
- 각 범주를 해당 범주의 타겟 평균값으로 변환
- 과적합 또는 데이터 누수 위험이 있어 스무딩 기법 추가
원-핫 인코딩
pd.get_dummies(
data=df, dtype=int
)data: 데이터프레임 또는 시리즈 지정prefix: 변수명에 붙일 접두사를 문자열 또는 리스트로 지정- 기본값 :
None
- 기본값 :
columns: 변환할 열이름 리스트를 지정drop_first: 첫 번째 범주의 삭제 여부를 지정- 기본값 :
False
- 기본값 :
dtype: 변수의 자료형 지정- 기본값 :
bool
- 기본값 :
레이블 인코딩
from sklearn.preprocessing import LabelEncoderle = LabelEncoder()
encoded = le.fit_transform(y=df['Species'])
pd.Series(data=encoded).unique()
# array([0, 1, 2])encoded→ 1차원 배열
오디널 인코딩
- 서열형에 사용하면 성능 향상
from sklearn.preprocessing import OrdinalEncoderoe = OrdinalEncoder(categories=[['versicolor', 'virginica', 'setosa']])categories: 범주의 순서를 리스트로 지정dtype: 변수의 자료형 지정- 기본값 :
numpy.float64
- 기본값 :
encoded = oe.fit_transform(X=df[['Species']])
pd.Series(data=encoded[:, 0]).unique()
# array([2., 0., 1.])X: 열 개수가 p인 데이터프레임 지정df[['Species']]→[ 시리즈 ]형태
encoded는 n X p 크기의 2차원 배열
타겟 인코딩
- 범주형 특성을 해당 범주의 타겟 평균값으로 변환하는 기법
- 타겟의 정보를 직접 사용하기 때문에 데이터 누수의 위험이 큼
- 데이터셋을 훈련셋, 검증셋, 테스트셋으로 분리
- 훈련셋만으로 범주별 타겟 평균을 계산
- 검증셋과 테스트셋은 훈련셋에서 계산한 평균값으로 인코딩
- k-겹 교차검증 또는 베이지안 스무딩을 적용하면 과적합 위험 감소
import category_encoders as cete = ce.TargetEncoder()smoothing: 스무딩 강도 지정- 기본값 : 10
encoded = te.fit_transform(X=df['Species'], y=df['Sepal.Length'])
encoded['Species'].unique()
# array([5.04571126, 5.9316052 , 6.55268353])encoded는 데이터프레임
다양한 거리 계산
비유사성의 척도
- 일부 머신러닝 알고리즘은 관측값 간의 비유사도(거리)를 측정
- 주로 유클리드 거리 또는 코사인 유사도를 기준으로 계산
- k-최근접 이웃 알고리즘은 모든 관측값 간의 거리를 계산
- 특정 관측값에서 가장 가까운 k개의 이웃을 선택하여 예측
- 분류 문제는 k개 이웃 중 다수 범주를 선택
- 회귀 문제는 평균값을 계산
- 군집화에서는 관측값 간의 거리가 가까울수록 같은 군집에 속한다고 판단
- 협업 필터링에서는 사용자 간 평가 점수의 유사도를 계산할 때 사용
- 선호도가 유사한 그룹을 찾고 이를 기반으로 개인화된 추천을 수행
거리의 개념
- 두 관측값 간의 거리가 짧을수록 서로 유사한 특성을 가진 것으로 간주
- 특성 간 스케일이 다르면 스케일이 큰 특성이 전체 거리 계산에 과도한 영향을 미침
- 반드시 데이터 정규화 실행
- 문제의 특성에 따라 맨하탄 거리, 유클리드 거리, 민코프스키 거리, 맥시멈 거리, 통계적 거리 등을 사용
거리의 특징
- 비음수성, 항등성 : 모든 거리는 0보다 크거나 같음, 같은 두 점의 거리는 0
- 대칭성 : 교환법칙이 성립
- 삼각 부등식 : 두 점의 거리는 다른 점 C를 경유하는 거리의 합보다 작거나 같음
맨하탄 거리
- 범주형 변수의 거리
- 특성 간 차이의 절대값을 모두 더한 값으로 계산
- L1-Norm
- Norm(노름) : 벡터 공간에서 원점으로부터 벡터까지의 거리를 측정하는 방법
- 맨하탄 거리는 ‘택시캡 거리’라는 별칭으로 알려져 있음
- 택시는 도로를 따라 직선으로만 이동해야 하는 상황을 가정한 거리이기 때문
유클리드 거리
- 특성 간 차이의 제곱합에 제곱근을 취하여 계산
- L2-Norm
- 일상적으로 인식하는 가장 익숙한 거리 개념(피타고라스 정리)
- 지면의 도로 구조를 따르지 않고 하늘을 가로질러 두 지점 간의 최단 거리를 가정
- ‘헬리콥터 거리’로 비유됨
- 대부분의 거리 기반 알고리즘에서 기본적으로 사용
표준화 거리
- 표준화된 데이터를 사용하여 계산한 유클리드 거리
- ‘통계적 거리’라고도 부름
- 각 특성의 분산과 공분산까지 고려한 마할라노비스 거리(이상치 탐지)의 특수한 형태
맥시멈 거리
- 특성 간 차이의 절대값 중 가장 큰 값으로 정의
- 가장 큰 값 하나만이 거리 전체를 결정
- 가장 큰 변화를 보이는 특성을 파악하는데 유용
- ‘체비세프 거리’라고도 함
민코프스키 거리
- 일반화된 거리 척도
- Lp-Norm
- p는 1보다 큰 실수이며, 거리 계산 방식에 영향을 줌
- p = 1 : 맨하탄 거리
- p = 2 : 유클리드 거리
- p = np.inf : 맥시멈 거리
거리 계산 관련 함수
df_dist = pd.DataFrame(
data=[[1, 1], [4, 5], [3, 2]],
index=['A', 'B', 'C'],
columns=['X', 'Y']
)
df_dist
# X Y
# A 1 1
# B 4 5
# C 3 2from sklearn.metrics import DistanceMetric- 맨하탄 거리
DistanceMetric.get_metric(metric='manhattan').pairwise(X=df_dist)
# array([[0., 7., 3.],
# [7., 0., 4.],
# [3., 4., 0.]])- 유클리드 거리
DistanceMetric.get_metric(metric='euclidean').pairwise(X=df_dist)
# array([[0. , 5. , 2.23606798],
# [5. , 0. , 3.16227766],
# [2.23606798, 3.16227766, 0. ]])- 체비세프 거리(맥시멈)
DistanceMetric.get_metric(metric='chebyshev').pairwise(X=df_dist)
# array([[0., 4., 2.],
# [4., 0., 3.],
# [2., 3., 0.]])- 민코프스키 거리
np.inf설정
DistanceMetric.get_metric(metric='minkowski', p=np.inf).pairwise(X=df_dist)
# array([[0., 4., 2.],
# [4., 0., 3.],
# [2., 3., 0.]])마치며
오늘은 분량이 역대급이었던 것 같다. 그래도 통계 파트보다는 크게 어려운 내용은 없어서 다행이었다.

Hello I'm TaeHyunAn, Currently Studying Data Analysis