시작하며
오늘도 머신러닝에 대해 배웠다. 확실히 머신러닝 파트에 들어오고부터는 이론도 많지만 코드로 접근하는 시간이 많아져서 한결 편한 것 같다. 그러면서 동시에 생각보다 코드는 어려운 부분이 없고 많은 부분이 정해져 있어서 그 이전 과정인 데이터 전처리와 핸들링, 통계 분석 부분의 실력을 쌓는 것이 더 중요한 것 같은 느낌이 들었다.
선형 회귀
선형 회귀계수 추정 : 최소제곱법
- 선형 회귀의 비용함수는 아래로 볼록 함수이므로 전역 최솟값이 단 하나 존재
- 미분해서 푸는 최소제곱법과 경사하강법이 같은 지점에서 수렴
결정계수
- 머신러닝 모델은 SSR을 계산할 수 없음
- SSE를 사용한 결정계수를 반환
데이터 분할
from sklearn.model_selection import train_test_splitX_train, X_valid, y_train, y_valid = train_test_split(X, y, test_size=0.2, random_state=1234)y_train.mean()
# np.float64(9697.907297830374)
y_valid.mean()
# np.float64(9692.633858267716)선형 회귀모델 학습
from sklearn.linear_model import LinearRegressionfit_intercept: y절편 계산 여부- 기본값 :
True
- 기본값 :
copy_X: 특성 행렬 X의 복사 여부 지정- 기본값 :
True
- 기본값 :
tol: X가 희소행렬인 경우 최소제곱문제를 풀기 위한 알고리즘 오차 허용 범위- 기본값 :
1e-6
- 기본값 :
n_jobs: 연산에 사용할 코어 지정- 기본값 :
None None= 1- -1 지정 시 모든 코어 사용
- 기본값 :
positive: 회귀계수를 양수로 강제할지 여부- 기본값 :
False
- 기본값 :
model_linear = LinearRegression()
model_linear.fit(X=X_train, y=y_train)- 하이퍼파라미터 확인
model_linear.get_params()
# {'copy_X': True,
# 'fit_intercept': True,
# 'n_jobs': None,
# 'positive': False,
# 'tol': 1e-06}score()- 회귀모델의 경우 결정계수 반환
- 분류모델의 경우 정확도 반환
model_linear.score(X=X_train, y=y_train)
# 0.7453200377582148
model_linear.score(X=X_valid, y=y_valid)
# 0.7350351379962555- 회귀계수 확인
model_linear.coef_
# array([-9.93166454e+01, -1.67673109e-02, -2.96617966e+01, -1.05935604e+01,
# 3.84406446e+01, 2.65917973e+00, -2.74794384e+01, 1.74106123e+01,
# 6.13430567e+02, -1.94223202e+03, 1.32880146e+03])- y절편 확인
model_linear.intercept_
# np.float64(-3566.4391928929563)정칙화된 회귀모델의 필요성
- 과적합 문제 해결 방법
- 특성의 개수를 줄여 모델 복잡도를 낮춤
- 훈련셋의 행 개수를 늘리거나, 이상치를 제거
- 정칙화(Regularization)를 통해 회기계수의 크기 축소
- 정칙화된 선형 회귀모델은 회귀계수를 인위적으로 축소 → 복잡도를 줄여 예측값의 분산 감소 및 과적합 방지
- 릿지(L2) : 회귀계수를 작게 만드는 방향으로 제어
- 라쏘(L1) : 일부 계수를 0으로 만들어 변수 선택 효과를 제공
- 일반적으로 라쏘의 성능이 좋지만 데이터에 따라 달라짐
정칙화된 선형 회귀
- 회귀계수에 대한 제약조건을 추가하여 축소하거나 일부를 0으로 만드는 효과
- 목적함수에 제약 조건을 추가하고 그 앞에 규제 상수 람다( )를 곱함
- 람다가 커질수록 목적 함수를 최소화하기 위해 회귀계수를 더 많이 축소
릿지 선형 회귀모델
from sklearn.linear_model import Ridgefit_intercept: y절편 계산 여부- 기본값 :
True
- 기본값 :
copy_X: 특성 행렬 X의 복사 여부 지정- 기본값 :
True
- 기본값 :
tol: X가 희소행렬인 경우 최소제곱문제를 풀기 위한 알고리즘 오차 허용 범위- 기본값 :
1e-6
- 기본값 :
positive: 회귀계수를 양수로 강제할지 여부- 기본값 :
False
- 기본값 :
alpha: 규제 상수( )- 기본값 : 1
- 0 지정 시 선형 회귀모델과 동일
max_iter: 최대 반복 횟수- 기본값 :
None
- 기본값 :
solver: 최적화 알고리즘- 기본값 :
auto
- 기본값 :
model_ridge = Ridge(alpha=1)- 모델 학습
model_ridge.fit(X=X_train, y=y_train)- 결정계수 확인
model_ridge.score(X=X_train, y=y_train)
# 0.745024558772102라쏘 선형 회귀모델
from sklearn.linear_model import Lassofit_intercept: y절편 계산 여부- 기본값 :
True
- 기본값 :
copy_X: 특성 행렬 X의 복사 여부 지정- 기본값 :
True
- 기본값 :
tol: X가 희소행렬인 경우 최소제곱문제를 풀기 위한 알고리즘 오차 허용 범위- 기본값 :
1e-6
- 기본값 :
positive: 회귀계수를 양수로 강제할지 여부- 기본값 :
False
- 기본값 :
alpha: 규제 상수( )- 기본값 : 1
- 0 지정 시 선형 회귀모델과 동일
max_iter: 최대 반복 횟수- 기본값 :
None
- 기본값 :
precompute: 그람 행렬 미리 계산- 기본값 :
False
- 기본값 :
selection: 계수 업데이트 순서- 기본값 :
‘cyclic’
- 기본값 :
warm_start: 이전 결과를 초기값으로 재사용 여부- 기본값 :
False
- 기본값 :
model_lasso = Lasso(alpha=1)- 모델 학습
model_lasso.fit(X=X_train, y=y_train)- 결정계수 확인
model_lasso.score(X=X_train, y=y_train)
# 0.7451306731162222
model_lasso.score(X=X_valid, y=y_valid)
# 0.7368623585441034세 모델 비교
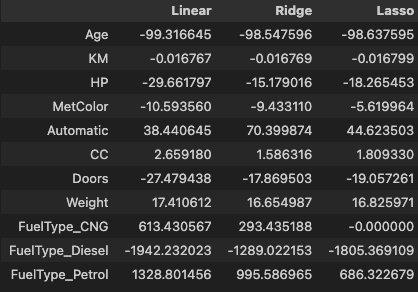
pd.DataFrame(
data={
'Linear': model_linear.coef_,
'Ridge': model_ridge.coef_,
'Lasso': model_lasso.coef_
},
index=X_train.columns
)
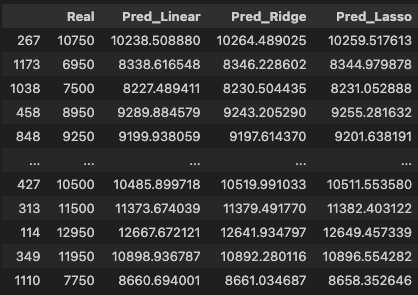
예측값 생성
y_pred_linear = model_linear.predict(X=X_valid)
y_pred_ridge = model_ridge.predict(X=X_valid)
y_pred_lasso = model_lasso.predict(X=X_valid)pd.DataFrame(
data={
'Real': y_valid,
'Pred_Linear': y_pred_linear,
'Pred_Ridge': y_pred_ridge,
'Pred_Lasso': y_pred_lasso
}
)
회귀모델 성능 평가
from sklearn.metrics import mean_squared_error
from sklearn.metrics import root_mean_squared_error
from sklearn.metrics import mean_absolute_percentage_errormean_squared_error(y_true=y_valid, y_pred=y_pred_linear)
# 972596.4199871043root_mean_squared_error(y_true=y_valid, y_pred=y_pred_ridge)
# 981.7528319556632mean_absolute_percentage_error(y_true=y_valid, y_pred=y_pred_lasso)
# 0.08251582058445193hds.stat.regmetrics(y_true=y_valid, y_pred=y_pred_linear)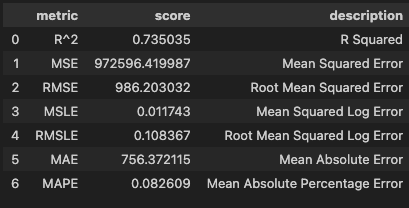
최적의 규제 상수 탐색
- 규제 상수 범위를 1차원 배열로 생성
alphas = np.arange(0.1, 20.1, 0.1)- 검증셋 결정계수를 담은 리스트 생성
vl_req = []
for alpha in alphas:
model_ridge.set_params(alpha=alpha).fit(X=X_train, y=y_train)
vl_req.append(model_ridge.score(X=X_valid, y=y_valid))- 결정계수 최댓값과 인덱스 확인
np.max(vl_req)
# np.float64(0.7397932326581274)
index = np.argmax(vl_req)
# np.int64(106)- 결정계수 최댓값일 때의 alpha 확인 → 최적의 람다값
alphas[index]
# np.float64(10.700000000000001)로지스틱 회귀
원-핫 인코딩
- 타겟 벡터는 원-핫 인코딩 변환하지 않아도 됨
df = pd.get_dummies(data=df, columns=['rank'], dtype=int)
df.head()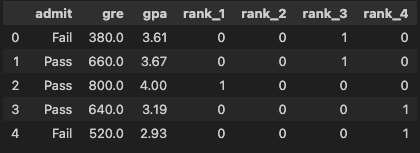
yvar = 'admit'
X = df.drop(columns=yvar)
y = df[yvar].copy()
display(X)
display(y)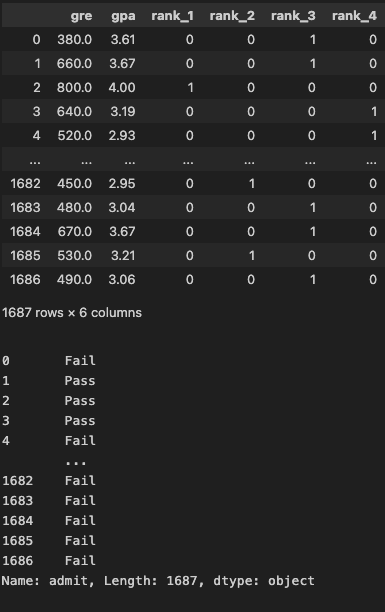
데이터 분할
from sklearn.model_selection import train_test_splittrain_test_split함수의stratify속성에 범주형 시리즈를 지정하면 해당 변수의 원소별 상대도수 기준으로 층화추출을 실행
X_train, X_valid, y_train, y_valid = train_test_split(X, y, test_size=0.2, random_state=1, stratify=df['admit'])
display(y_train.value_counts(normalize=True).sort_index())
# admit
# Fail 0.6894
# Pass 0.3106
# Name: proportion, dtype: float64
display(y_valid.value_counts(normalize=True).sort_index())
# admit
# Fail 0.689349
# Pass 0.310651
# Name: proportion, dtype: float64로지스틱 회귀모델
from sklearn.linear_model import LogisticRegressionC: 정규화 강도(작을수록 강한 규제)- 기본값 : 1.0
class_weight: 클래스별 가중치(불균형 데이터 처리)- 기본값 :
None
- 기본값 :
dual: 각 행별 영향력 관점으로 최적화- 기본값 :
False
- 기본값 :
fit_intercept: y절편 계산 여부- 기본값 :
True
- 기본값 :
intercept_scaling: 절편 정규화 스케일링- 기본값 : 1
l1_ratio:L1, L2, ElasticNet비율 선택- 규제없음 :
C=np.inf - L2(Ridge) :
l1_ratio=0.0 - L1(Lasso) :
l1_ratio=1.0, solver=’liblinear’
- 규제없음 :
penalty: 1.10 버전에서 제거 예정max_iter: 최대 반복 횟수- 기본값 :
None
- 기본값 :
n_jobs: 연산에 사용할 코어 지정- 기본값 :
None None= 1- -1 지정 시 모든 코어 사용
- 기본값 :
random_state: 난수 시드- 기본값 :
None
- 기본값 :
solver: 최적화 알고리즘- 기본값 :
‘lbfgs’
- 기본값 :
tol: 수렴 판단 기준- 기본값 : 0.0001
verbose: 로그 출력 수준- 기본값 : 0
warm_start: 이전 결과를 초기값으로 재사용 여부- 기본값 :
False
- 기본값 :
model_logit = LogisticRegression(C=np.inf, max_iter=1000, random_state=0)- 모델 학습
model_logit.fit(X=X_train, y=y_train)- 정확도 확인
model_logit.score(X=X_train, y=y_train)
# 0.7323943661971831
model_logit.score(X=X_valid, y=y_valid)
# 0.6863905325443787- y절편 확인
model_logit.intercept_
# array([-5.35142011])- 회귀계수 확인
model_logit.coef_[0]
# array([ 0.0038324 , 1.07656158, -0.2272636 , -1.1787027 , -1.78295985,
# -2.16249395])주요 solver 종류 및 특징
‘lbfgs’- 2차 도함수를 사용하여 경사하강법보다 더 빠르고 안정적으로 수렴
- L2만 사용 가능
‘liblinear’- 작은 규모의 데이터셋에 적합
- L1, L2 모두 지원
‘newton-cg’- 계산 비용이 높지만 수렴 정확도가 뛰어남
- 다중 클래스 분류에서 L2 지원
‘sag’- 입력 틍성이 정규화되어 있을 때 잘 작동
- L2만 지원
‘saga’- 다중 클래스 분류 처리 가능
- L1, L2 모두 지원
solver 선택 기준
- 특성 행렬을 정규화하면 반복 횟수가 적어도 빠르게 수렴
- 기본값인
‘lbfgs’는 안정적으로 사용- L1을 지원 X
- L1을 사용 시 작은 데이터는
‘liblinear’큰 데이터는‘saga’를 선택‘liblinear’는 이진 분류만 지원
릿지 로지스틱 회귀모델
model_ridge = LogisticRegression(l1_ratio=0, max_iter=1000, random_state=0, C=0.1, solver='lbfgs')- 모델 학습
model_ridge.fit(X=X_train, y=y_train)- 정확도 확인
model_ridge.score(X=X_train, y=y_train)
# 0.7249814677538917
model_ridge.score(X=X_valid, y=y_valid)
# 0.6952662721893491라쏘 로지스틱 회귀모델
model_lasso = LogisticRegression(l1_ratio=1, max_iter=1000, random_state=0, solver='liblinear', C=0.1)- 모델 학습
model_lasso.fit(X=X_train, y=y_train)- 정확도 확인
model_lasso.score(X=X_train, y=y_train)
# 0.7220163083765753
model_lasso.score(X=X_valid, y=y_valid)
# 0.6804733727810651세 모델 비교
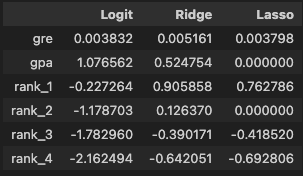
pd.DataFrame(
data={
'Logit': model_logit.coef_[0],
'Ridge': model_ridge.coef_[0],
'Lasso': model_lasso.coef_[0],
},
index=X_train.columns
)
예측값 생성
y_pred_logit = model_logit.predict(X=X_valid)
y_pred_ridge = model_ridge.predict(X=X_valid)
y_pred_lasso = model_lasso.predict(X=X_valid)hds.stat.clfmetrics(y_true=y_valid, y_pred=y_pred_logit)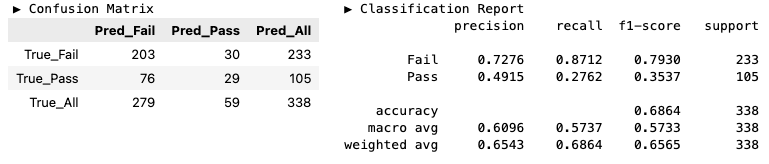
예측 확률 생성
y_prob_logit = model_logit.predict_proba(X=X_valid)
y_prob_ridge = model_ridge.predict_proba(X=X_valid)
y_prob_lasso = model_lasso.predict_proba(X=X_valid)ROC 곡선 시각화
hds.plot.roc_curve(y_true=y_valid, y_prob=y_prob_logit, color='red')
hds.plot.roc_curve(y_true=y_valid, y_prob=y_prob_ridge, color='green')
hds.plot.roc_curve(y_true=y_valid, y_prob=y_prob_lasso, color='blue')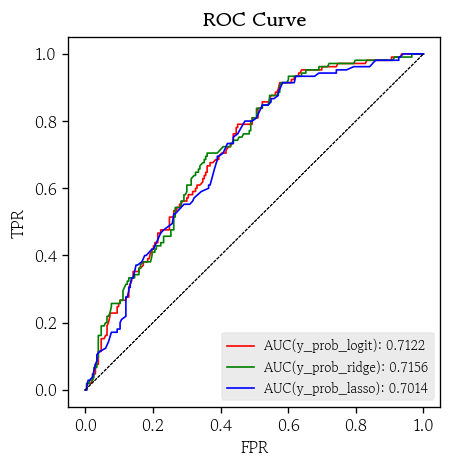
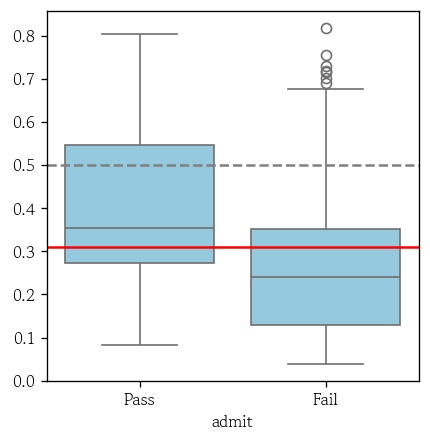
sns.boxplot(x=y_valid, y=y_prob_logit[:, 1])
plt.axhline(y=0.5, color='0.5', linestyle='--')
plt.axhline(y=0.31, color='red', linestyle='-')
plt.show()- 분류기준점(cut-off)가 0.5인 것은 기본값이지만 최적은 아님
- 0.0부터 1.0까지 조금씩 변경해가면서 최고의 분류기준점을 탐색하는 그리드 서치 방식이 필요
PR 곡선
hds.plot.pr_curve(y_true=y_valid, y_prob=y_prob_logit, color='red')
hds.plot.pr_curve(y_true=y_valid, y_prob=y_prob_ridge, color='green')
hds.plot.pr_curve(y_true=y_valid, y_prob=y_prob_lasso, color='blue')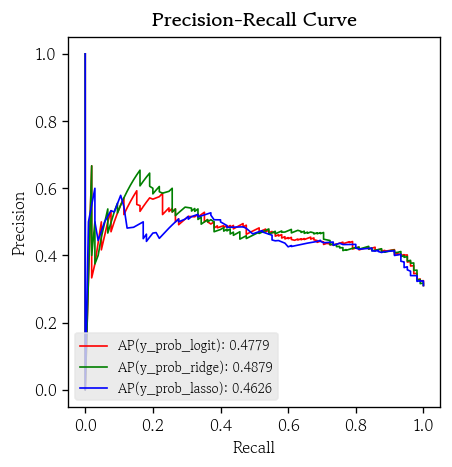
마치며
강사님께서 주신 실제 데이터를 사용해서 데이터 전처리부터 통계 분석을 진행하면서 나만의 통계 분석 템플릿을 만들고 있는데 워낙 케이스도 많고 아직 잘 아는 게 아니다 보니 막히는 부분이 많다. 단계별로 조금씩 해결해가면서 템플릿을 완성하면 이후에는 조금 수월하게 작업을 할 수 있지 않을까 싶다.

Hello I'm TaeHyunAn, Currently Studying Data Analysis