시작하며
오늘은 최근들어 가장 컨디션이 안 좋은 날이었다. 그래도 최대한 내용들의 이미지는 가져가려고 집중을 했기 때문에 주말부터 시작되는 연휴 간 복습을 꾸준히 해야겠다.
실습 데이터셋 준비
데이터 확인
df.head()
df.info()
df.isna().sum()
df.describe().round(3)- 타겟 변수
quality= 서열형
df['quality'].value_counts().sort_index()
# quality
# 3 20
# 4 163
# 5 1457
# 6 2198
# 7 880
# 8 175
# 9 5
# Name: count, dtype: int64데이터 전처리
- 서열형 → 명목형 변환
df['grade'] = np.where(df['quality'].ge(7), 1, 0)- 불필요한 컬럼 제거
df = df.drop(columns=['free sulfur dioxide', 'quality'])데이터 시각화로 관계 확인
- 목표변수 도수 확인
hds.plot.bar_freq(data=df, x='grade')- 연속형 변수 간 상관관계 확인
hds.plot.corr_heatmap(data=df, fontsize=7)- 입력변수와 관계 확인
- 컬럼을 순회하면서 시각화 진행
- 타겟 변수 제외를 위해
[-1]
for var_name in df.columns.to_list()[:-1]:
hds.plot.box_group(data=df, x='grade', y=var_name, palette=['skyblue', 'orange'])
plt.show()특성 행렬과 타겟 벡터로 분리
yvar = 'grade'
X = df.drop(columns=yvar)
y = df[yvar].copy()데이터셋 분할
from sklearn.model_selection import train_test_splitX_train, X_valid, y_train, y_valid = train_test_split(X, y, test_size=0.3, random_state=0)- 분할 데이터 확인
X_train.shape
# (3428, 10)
X_valid.shape
# (1470, 10)- 타겟 데이터 상대도수 확인
y_train.value_counts(normalize=True).sort_index()
# grade
# 0 0.782089
# 1 0.217911
# Name: proportion, dtype: float64
y_valid.value_counts(normalize=True).sort_index()
# grade
# 0 0.787075
# 1 0.212925
# Name: proportion, dtype: float64외부 파일로 저장
objs = {
'X_train': X_train,
'X_valid': X_valid,
'y_train': y_train,
'y_valid': y_valid
}pd.to_pickle(obj=objs, filepath_or_buffer='WhiteWine.pkl')KNN(K-Nearest Neighbors Classification)
k-최근접 이웃 개요
- 새로운 관측값과 훈련셋의 모든 관측값 간의 거리를 계산
- 가장 가까운 k개의 이웃을 선택하여 예측을 수행
- 범주형 → 분류 문제 : 최빈값
- 연속형 → 회귀 문제 : 평균
- 사례 기반 추론(Case Based Reasoning)
- 명시적인 모델 학습 단계 없이 거리를 기준으로 선택된 이웃으로부터 예측을 수행
- 사전에 분포에 대한 가정 없이 주어진 데이터를 그래로 활용
- 비모수적 기법
- 주로 유클리드 거리 사용
- 훈련셋의 크기에 비례하여 거리 계산량 증가
- 열 개수가 많아질수록 데이터 포인트가 희소해져 유사도 판단 어려움
- 차원의 저주 발생
- 이상치에 민감
- k가 작을수록 인접 소수의 이웃에 의존하여 이상치에 영향 → 과적합
- k가 클수록 국소적 패턴 반영이 어려워짐 → 과소적합
KNN 성능 향상을 위한 핵심 전략
- 탐색 속도 개선을 위해 트리 구조 활용
- 공간을 분할하는 트리 구조로 KDTree, BallTree 등이 있음
- 불필요한 연산량을 크게 줄일 수 있음 → 멀리 있음이 확실한 영역은 배제
- 이상치의 영향을 완화하기 위해 이웃과의 거리에 반비례하는 가중치를 부여
- 교차검증을 통해 최적의 k를 선택
데이터 표준화
globals().update(objs)from sklearn.preprocessing import StandardScaler- 표준화 객체 생성
scaler = StandardScaler()X_train = scaler.fit_transform(X_train)
X_valid = scaler.transform(X_valid)가중치 없는 KNN 분류 모델 학습
from sklearn.neighbors import KNeighborsClassifier- 가중치 없는 KNN 분류 모델 생성
model_unif = KNeighborsClassifier()- 모델 학습
model_unif.fit(X=X_train, y=y_train)- 정확도 확인
model_unif.score(X=X_train, y=y_train)
# 0.8865227537922987
model_unif.score(X=X_valid, y=y_valid)
# 0.8061224489795918- 이웃간 거리 및 인덱스 확인
distances, indices = model_unif.kneighbors(X=X_valid)distances[0]
# array([0.84149839, 1.18088628, 1.25421004, 1.25455938, 1.25766403])
indices[0]
# array([1833, 1041, 1351, 3203, 2240])최근접 이웃과의 거리 분포 확인
- k번째 최근접 이웃과의 거리 데이터를 시리즈로 생성
kth_distances = pd.Series(data=distances[:, -1])
kth_distances.describe().round(3)
# count 1470.000
# mean 1.369
# std 0.650
# min 0.000
# 25% 1.073
# 50% 1.269
# 75% 1.546
# max 17.231
# dtype: float64- 거리가 가장 떨어진 데이터 확인
kth_distances.sort_values().tail()
# 5 4.638065
# 625 4.843886
# 903 5.734853
# 1025 5.997965
# 190 17.231431
# dtype: float64sns.histplot(x=kth_distances, binrange=(0, 6), binwidth=0.5)
plt.show()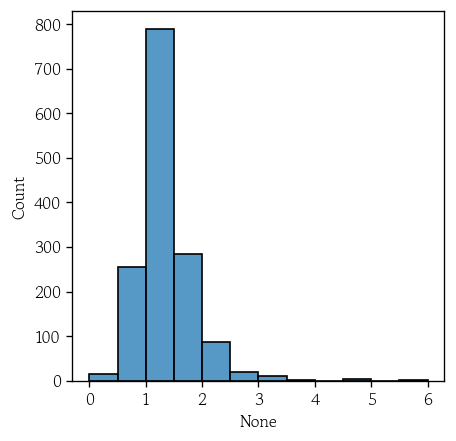
가중치 있는 KNN 분류 모델 학습
model_dist = KNeighborsClassifier(weights='distance')- 가중치가 있는 KNN 분류 모델로 학습
model_dist.fit(X_train, y_train)- 가중치가 있는 정확도를 확인
model_dist.score(X=X_train, y=y_train)
# 1.0
model_dist.score(X=X_valid, y=y_valid)
# 0.8469387755102041분류 모델 성능 평가
y_pred_unif = model_unif.predict(X_valid)
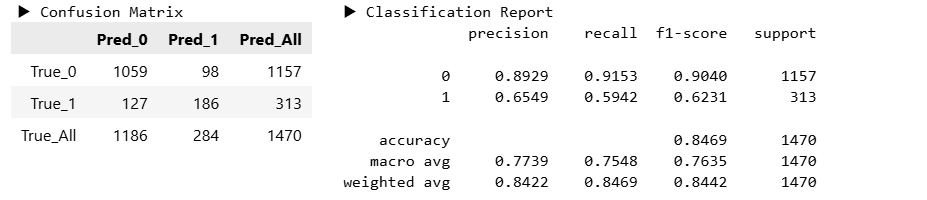
y_pred_dist = model_dist.predict(X_valid)hds.stat.clfmetrics(y_true=y_valid, y_pred=y_pred_unif)
hds.stat.clfmetrics(y_true=y_valid, y_pred=y_pred_dist)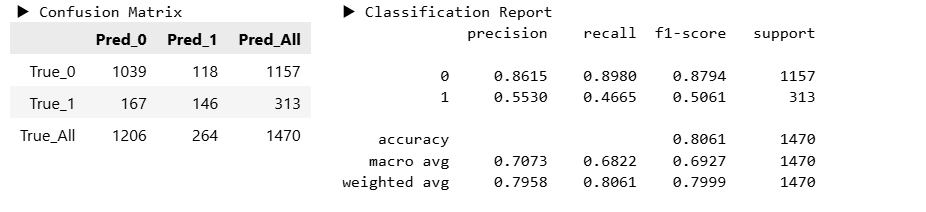
최적의 k 탐색
def valid_score(k):
model = KNeighborsClassifier(n_neighbors=k, weights='distance')
model.fit(X=X_train, y=y_train)
score = model.score(X=X_valid, y=y_valid)
return score- 탐색할 k의 범위 설정
ks = range(1, 100, 2)- 검증셋 정확도를 원소로 갖는 리스트로 생성
vl_acc = [valid_score(k) for k in ks]- 그래프로 시각화
sns.lineplot(x=ks, y=vl_acc)
plt.show()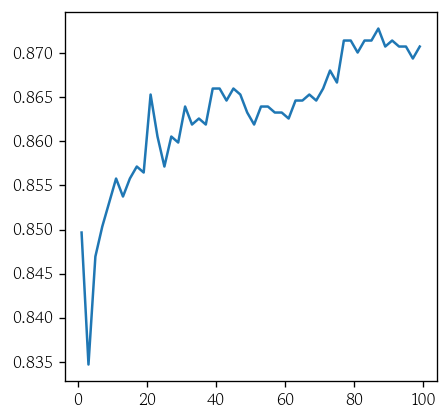
최적의 KNN 분류 모델 학습
index = np.argmax(vl_acc)
best_k = ks[index]model_best = KNeighborsClassifier(n_neighbors=best_k, weights='distance')
model_best.fit(X=X_train, y=y_train)- 정확도 확인
model_best.score(X=X_train, y=y_train)
# 1.0
model_best.score(X=X_valid, y=y_valid)
# 0.8727891156462585F1 스코어 값 출력 함수
from sklearn.metrics import f1_scoredef valid_f1_score(k):
model = KNeighborsClassifier(n_neighbors=k, weights='distance')
model.fit(X=X_train, y=y_train)
y_pred = model.predict(X=X_valid)
score = f1_score(y_true=y_valid, y_pred=y_pred)
return score데이터 균형화
from imblearn.over_sampling import SMOTE- SMOTE 모델 생성
smote = SMOTE(k_neighbors=5, random_state=0)- 소수 클래스를 다수 클래스 개수만큼 오버 샘플링
X_bal, y_bal = smote.fit_resample(X=X_train, y=y_train)- 범주별 도수 확인
y_bal.value_counts(normalize=True)
# grade
# 0 0.5
# 1 0.5
# Name: proportion, dtype: float64표준화된 데이터로 모델 학습
model_bal = KNeighborsClassifier(n_neighbors=best_k, weights='distance')
model_bal.fit(X=X_bal, y=y_bal)model_bal.score(X=X_bal, y=y_bal)
# 1.0
model_bal.score(X=X_valid, y=y_valid)
# 0.7952380952380952회귀 대체
from sklearn.experimental import enable_iterative_imputer
from sklearn.impute import IterativeImputerimputer = IterativeImputer()
df_imp = pd.DataFrame(data=imputer.fit_transform(X=df), columns=df.columns)df_imp['Insulin'] = df_imp['Insulin'].clip(lower=16)데이터 전처리
cond1 = df_imp['SkinThickness'].lt(80)
cond2 = df_imp['BMI'].lt(60)
df_imp = df_imp.loc[cond1 & cond2, :].drop(columns='Outcome')
df_imp = df_imp.reset_index(drop=True)k-최근접 이웃 회귀
- 타겟의 산술 평균을 예측값으로 산출
- 거리의 역수를 적용한 가중 평균을 예측값으로 산출
가중치 없는 KNN 회귀 모델 학습
from sklearn.neighbors import KNeighborsRegressormodel_unif = KNeighborsRegressor(p=1)
model_unif.fit(X=X_train, y=y_train)model_unif.score(X=X_train, y=y_train)
# 0.5783751948120422
model_unif.score(X=X_valid, y=y_valid)
# 0.34874094754106255distances, indices = model_unif.kneighbors(X=X_valid)distances[0]
# array([1.57368314, 2.08625259, 2.10585654, 2.23487783, 2.30612248])kth_distance = pd.Series(data=distances[:, -1])sns.histplot(x=kth_distance, binrange=(1, 7), binwidth=0.5)
plt.show()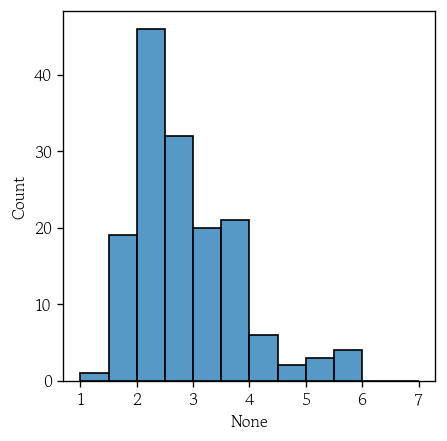
거리 계산 방식의 차이
- 유클리드 거리
- 제조 : 센서 데이터 간의 차이가 연속적이고 노이즈가 적어 L2가 실제 오차를 반영
- 에너지 : 기후 변수 간 조합적 변화가 중요 → L2가 전체 패턴을 포착
- 의료 : 임상 지표 간 조합적 변동을 포착 → L2가 유리
- 맨하탄 거리
- 리테일 : 고객 행동 데이터는 횟수이므로 L1이 민감하게 반영
- 금융 : 거래 패턴 데이터는 희소 행렬 → L1이 특성 간 중요도를 균일하게 반영
- 텍스트 : 희소 행렬 → L1이 소수 단어 간 차이를 민감하게 구분
가중치 있는 KNN 회귀 모델 학습
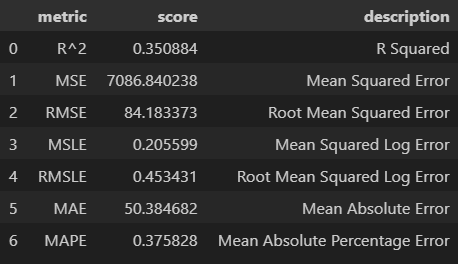
model_dist = KNeighborsRegressor(weights='distance', p=1)model_dist.fit(X=X_train, y=y_train)model_dist.score(X=X_train, y=y_train)
# 1.0
model_dist.score(X=X_valid, y=y_valid)
# 0.35088449132245114y_pred_unif = model_unif.predict(X=X_valid)
y_pred_dist = model_dist.predict(X=X_valid)hds.stat.regmetrics(y_true=y_valid, y_pred=y_pred_unif)
hds.stat.regmetrics(y_true=y_valid, y_pred=y_pred_dist)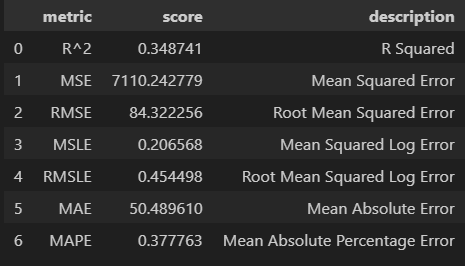
최적의 k 탐색
def valid_score(k):
model = KNeighborsRegressor(n_neighbors=k, weights='distance', p=1)
model.fit(X_train, y_train)
score = model.score(X=X_valid, y=y_valid)
return scoreks = range(1, 100)
vl_rsq = [valid_score(k) for k in ks]index = np.argmax(vl_rsq)
best_k = ks[index]sns.lineplot(x=ks, y=vl_rsq)
plt.show()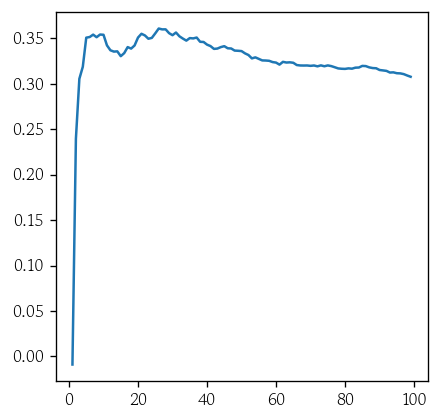
최적의 KNN 회귀 모델 학습
model_best = KNeighborsRegressor(n_neighbors=best_k, p=1, weights='distance')
model_best.fit(X=X_train, y=y_train)model_best.score(X=X_train, y=y_train)
# 1.0
model_best.score(X=X_valid, y=y_valid)
# 0.36093215506286147서포트 벡터 머신 분류
서포트 벡터 머신 개요
- 분류와 회귀 모두에 사용할 수 있는 지도 학습 알고리즘
- 클래스 간 마진이 최대가 되도록 하는 초평면을 찾는 것
- 마진 : 클래스에서 경계에 가장 가까운 데이터 포인트까지의 거리
- 마진 최대 → 과적합 방지 및 일반화 성능 향상
- 마진 : 클래스에서 경계에 가장 가까운 데이터 포인트까지의 거리
- 고차원 공간에서도 성능이 잘 나옴
- 커널 트릭을 사용하면 선형으로 분리할 수 없는 데이터를 분리 가능
- 데이터 포인트의 개수가 커질수록 학습 시간이 크게 증가
초평면
- SVM은 범주형 목표변수를 최대한 넓은 간격으로 분리하는 초평면을 찾음
- 입력 변수가 p개일 때 초평면은 p-1 차원의 부분 공간
초평면과 마진
- 마진이 작은 초평면은 과적합되기 쉬움
하드 마진 vs 소프트 마진
- 하드 마진 : 모든 관측값을 마진 바깥쪽에 위치하도록 구분하는 방식
- 소프트 마진 : 일부 관측값이 마진 안쪽으로 들어오는 것을 허용하는 방식
- 안쪽으로 들어오는 관측값에 벌점을 부과하기 위해 비용상수(C) 사용
- 비용상수 값이 클수록 마진이 작아짐
커널 트릭
- 2차원 공간에서 직선으로 구분할 수 없는 클래스를 3차원 공간으로 변환
- 종류
- 선형(Linear)
- 다항식
- 쌍곡 탄젠트
- 가우시안(RBF)
서포트 벡터 회귀
- 오차 허용 범위 안에 데이터가 들어오도록 하는 최적의 초평면을 찾는 것
- 초평면과 경계면 사이의 간격을 오차 허용 범위 으로 설정
마치며
내일은 의사결정나무부터 시작되는 머신러닝의 꽃 랜덤포레스트 및 앙상블에 대한 내용을 배운다. 머신러닝에 대해 배우면 배울수록 데이터 전처리와 이론 지식을 더 철저하게 복습하고 공부해야겠다는 생각이 들었다.

Hello I'm TaeHyunAn, Currently Studying Data Analysis