AICE Basic 공부
1.[이론편] AI의 이해-머신러닝(2)

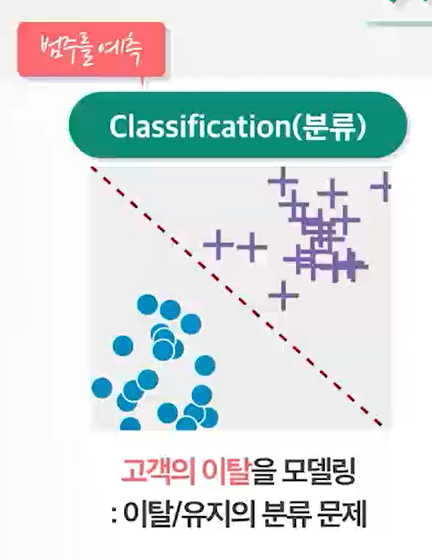
문제만 주는 비지도 학습비지도 학습입력데이터만 주어졌을 때 모델 스스로 데이터안에 관계를 찾아내는 것당근과 채찍, 강화학습강화학습머신러닝 학습 방법 비교(지도 VS 비지도 VS 강화)지도학습학습데이터labeled past data환경피드백direct응용분야분류, 회귀
2.[이론편] AI의 이해-딥러닝(1)
인기 머신러닝 알고리즘앙상블 기법kaggle에서 인기있는 알고리즘이라는 것을 알려줌앙상블 기법의 구현체xgboost, lightGBM딥러닝중요한 Feature에 가중치를 부여하여 학습뇌의 정보처리방식을 모사한 "인공신경망"과 유사하게 여러 층(Layer)으로 깊이있게(
3.[이론편] AI의 이해-딥러닝(2)
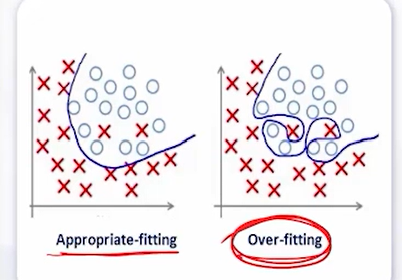
딥러닝이 주목 받는 이유Feature 추출을 기계가 직접, 알아서 함.AI 모델에 필요한 X값을 스스로 찾음빅데이터의 경우 정확도 가 높음주의할 점과적합(Over-fitting)학습 데이터에만 잘 맞는 모델이 될 가능성Too Slow복잡한 로직으로 학습 시간 증가Bla
4.[이론편] AI의 이해-업무적용

AI 업무 적용 프로세스1\. 문제 정의목적과 목표예시목적고객 해지 방어 활동목표사용패턴으로 혜지예측사용패턴 반영한 상품추천목적과 목표에 따라 어떤 AI 모델을 만들 것인지 선택가능AI 과제 정의서2\. 데이터 수집가능한 많고 깨끗한 데이터데이터가 편향되거나 손실되었다
5.[이론편] AI의 이해 - AI 업무 적용 사례
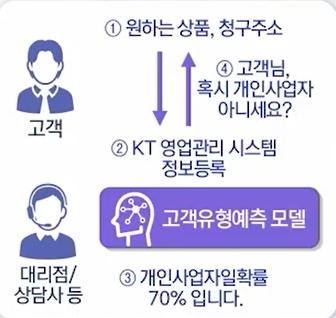
1\. 신규가입정보 기반 고객유형 예측문제 정의사업자 고객이 개인 고객으로 잘못 등록되는 경우 발생\-> 부가세 환급이 불가, 가산세 적용\-> 부가세 신고 달에 사업자 등록여부 확인 및 변경 요청으로 고객센터 콜 폭주목적고객이 말하지 않아도 고객 유형을 분류, 예측해
6.[이론편] AI의 이해 - AI 이해 리뷰

문제1. 인공지능의 한 분야로 사람이 기계에게 직접 규칙을 알려주어 학습하는 것을 머신러닝이라한다.답: X풀이: 머신러닝은 학습을 통해 스스로 규칙을 만들어나가는 알고리즘/기술의 총칭인공지능에 필요한 3가지 : 빅데이터, HW, 알고리즘문제2. 머신러닝의 학습 방법을
7.[실습편] 코딩이 필요없는 AIDU ez 활용법 - 데이터분석
포인트위주머신러닝지도학습문제와 정답을 모두 알려주고 공부시키는 방법예측, 분류비지도 학습답을 가르쳐주지 않고 공부시키는 방법연관 규칙, 군집강화학습상은 최대화, 벌은 최소화하는 방향으로 행위를 강화하는 학습보상머신러닝 알고리즘지도학습K-최근접 이웃(KNN)선형 회귀로지
8.[실습편] 코딩이 필요없는 AIDU ez 활용법 - 데이터 가공
범주형/텍스트 데이터수치형 데이터
9.[실습편] 코딩이 필요없는 AIDU ez 활용법 - AI 모델링 & 머신러닝(이론)
AI 모델링어떤 항목을 활용?어떻게 학습?AI 적용모델의 성능은?모델을 어떻게 활용?
10.[실습편]코딩이 필요없는 AIDU ez 활용법 - 정형 데이터 모델링 (딥러닝)

포인트 위주로 정리함.평가지표성능평가시에는 녹색 그래프(Test)를 체크Early stop이 적용되는 예예) early stop : 5 \-> 검증 데이터에 대해 loss값이 5epoch 동안 줄지 않으면 Stop 성능분석에서 Precision(정밀도)과 Recall(
11.[실습편]코딩이 필요없는 AIDU ez 활용법 - 사례실습
포인트 위주 정리
12.[이론편]AI 구현 프로세스 - 문제정의
AI가 적용될 수 있는 상황데이터나 규칙이 너무 복잡한 경우다양한 형태의 데이터를 활용하는 경우정형 데이터예) RDMS, 엑셀반정형 데이터로그, 스크립트비정형 데이터텍스트, 이미지, 오디오, 비디오미지의 영역에 대한 연구와 해결이 필요한 경우AI의 5가지 주요 기능예측
13.[이론편]AI 구현 프로세스 - 데이터 수집
1\. 수집할 데이터의 종류내부 데이터업무 영역 내부데이터 수명주기 관리가 용이민간 점보 포함서비스(인증, 거래), 네트워크(방화벽, 시스템), 마케팅(VOC, 판매정보)외부 데이터소셜(SNS, 커뮤니티), 공공(의료, 지역, 기상정보)외부 시스템공개된 데이터편향성 확
14.[이론편]AI 구현 프로세스 - 데이터 분석 및 전처리(1)
데이터 분석1\. 데이터 타입 확인데이터 타입 구분하기수치형연속형연속되는 값예) 키, 몸무게이산형셀수 있는 값예) 사람 수문자형범주형범주를 나눌 수 있는 데이터사칙연산 X순서형순서를 매길 수 있음예) 학점명목형순서를 매길 수 없음성별, 5지선다 선택지불리언형참, 거짓기
15.[이론편]AI 구현 프로세스 - 데이터 분석 및 전처리(3)
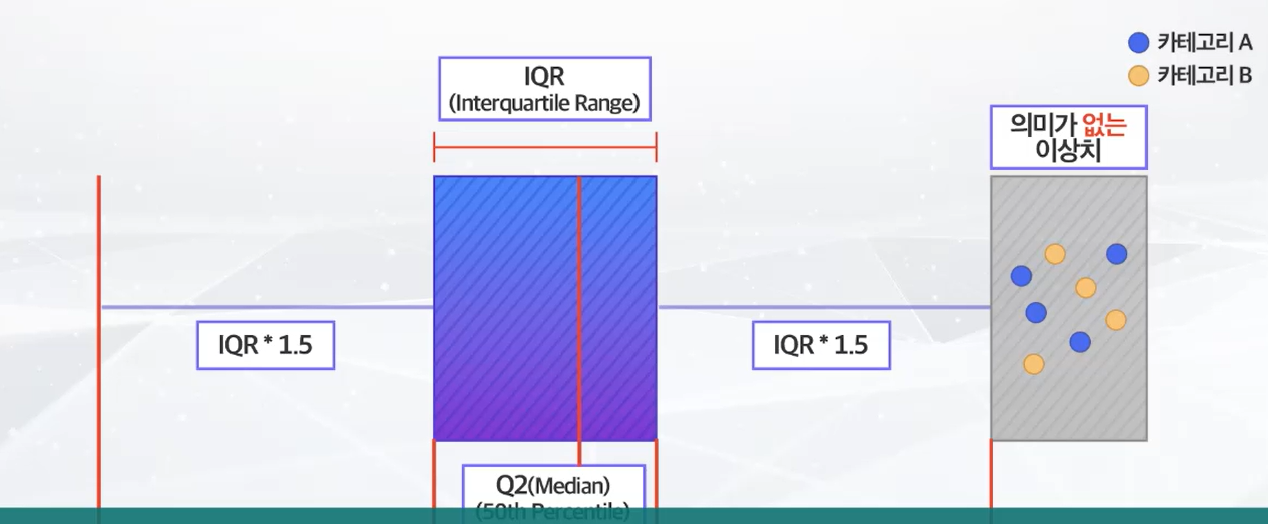
1\. 결측치 처리결측치 처리 방법 \- 제거 \- 데이터가 충분히 많은 경우 \- 대체 \- 데이터가 충분하지 않은 경우 \- 결측치 대체 방법 \- 수치형 \- 평균값 \- 중앙값
16.[이론편]AI 구현 프로세스 - 데이터 분석 및 전처리(4)

인코딩데이터간 순서 여부에 따른 분류Ordinal Encoding데이터 간에 순서가 있는 카테고리 데이터에 대해 적용One-Hot Encoding카테고리 수만큼 0과 1로만 구성된 새로운 컬럼을 만들어 맵핑스케일링수치형 데이터에 사용변수 간 비교를 위해 수치 단위를 맞
17.AI 구현 프로세스 - AI 모델링

AI 모델링1\. 데이터에 적합한 AI 알고리즘 선택요소타겟변수지도학습분류를 위한 데이터수치 예측(회귀)을 위한 데이터Linear Regression목적설명결과의 원인 분석결과에 영향을 주는 변수(컬럼) 분석예) 월별 커피 매출 원인, 변수 분석예측결과 자체가 중요한
18.[이론편]AI 구현 프로세스 - AI 적용
AI 적용지속적인활용 목적 + 시스템화 + 유지보수엔지니어링에 가까운 분야AI 모델을 지속 가능하게 하려면지속적인 데이터 필요KubeFlow
19.[이론편]머신러닝 동작원리 Basic - 머신러닝 기본 개념
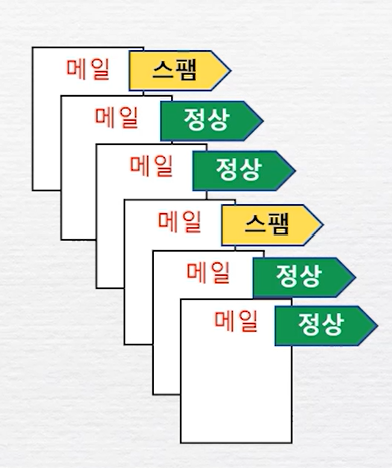
머신러닝의 유형지도학습정답을 알려주면서 진행하는 실습라벨링타겟변수범주를 예측분류예) Yes/No, A/B/C/D/E수치를 예측회귀예) 시험첨수, 단순 선형 회귀오차와 비용함수(1)MSE평균제곱오차작을수록 정확한것비지도학습정답없이 진행되는 학습
20.[이론편]머신러닝 동작원리 Basic - 머신러닝 학습방법
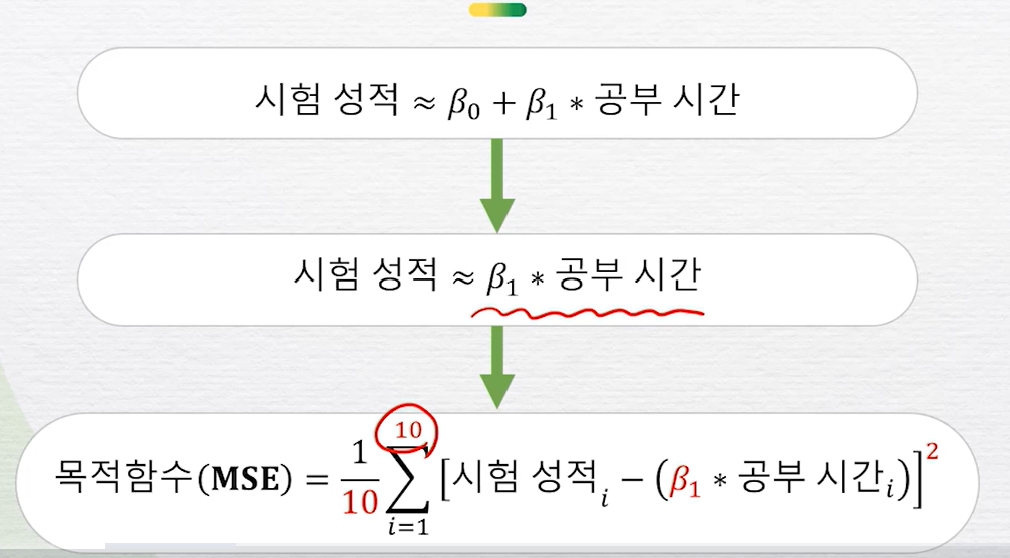
최적 모델 찾기경사 하강법경사하강법에서 학습률다음 베타1으로 가는 간격을 학습률이라고 함.학습률이 너무 크면 목표지점(목적함수의 최솟값)을 지나칠수있고학습률이 너무 작으면 시간이 너무 오래 걸릴수있다.
21.[이론편]머신러닝 동작원리 Basic - 머신러닝 대표모델
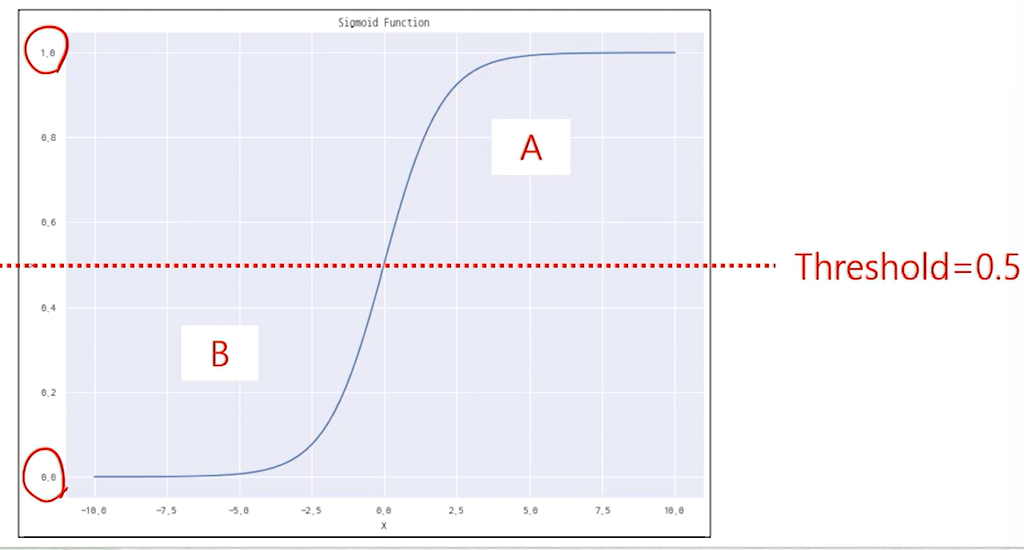
머신러닝 대표모델다중 선형 회귀(Linear Regression)데이터를 설명할 수 있는 여러개의 독립변수를 이용하여 종속변수를 예측로지스틱 회귀(Logistic Regression)분류에 사용되는 알고리즘0~1 확률을 알아냄Sigmoid 알고리즘을 사용K-최근접 이웃
22.[이론편]머신러닝 동작원리 Basic - 머신러닝 실습
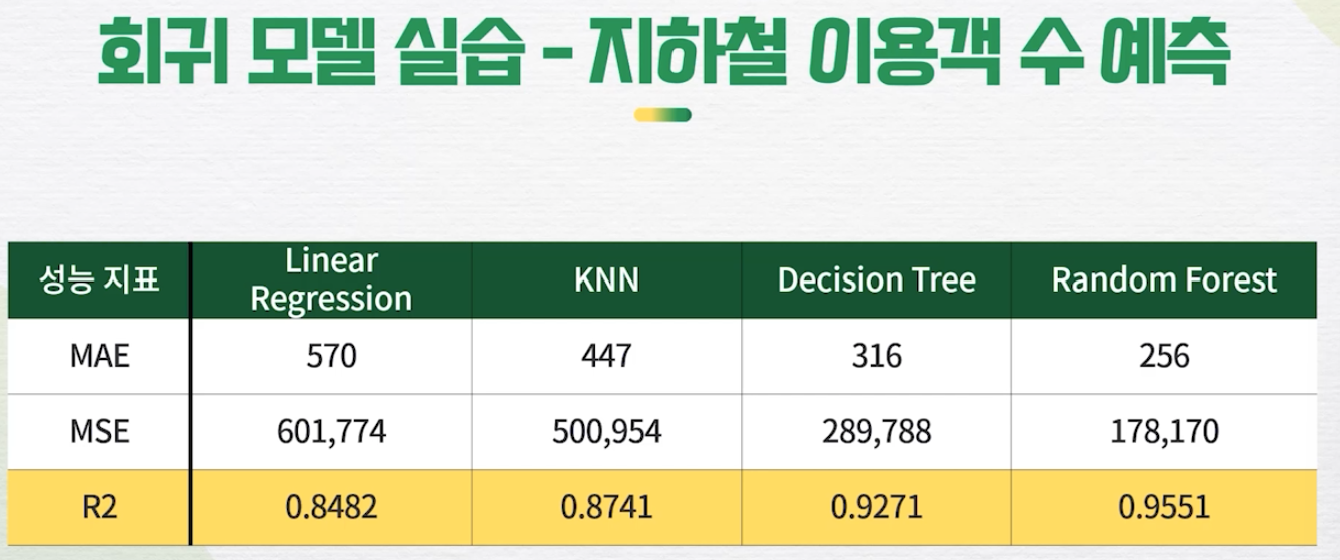
회귀 모델다중선형회귀K-최근접 이웃의사결정나무랜덤포레스트회귀 모델 실습 결과Random Forest 가 우세분류 모델로지스틱회귀K-최근접 이웃의사결정나무랜덤포레스트분류 모델 실습 결과Accuracy 기준으로 Random Forest가 우세
23.[이론편]딥러닝 동작원리 Basic - 딥러닝 동작 원리
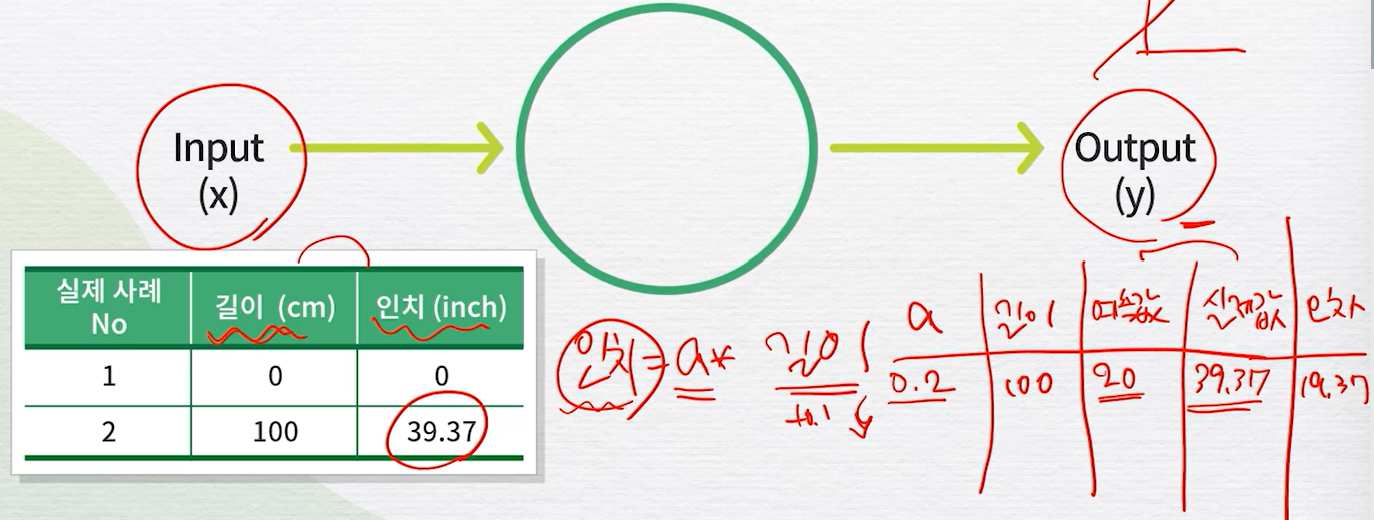
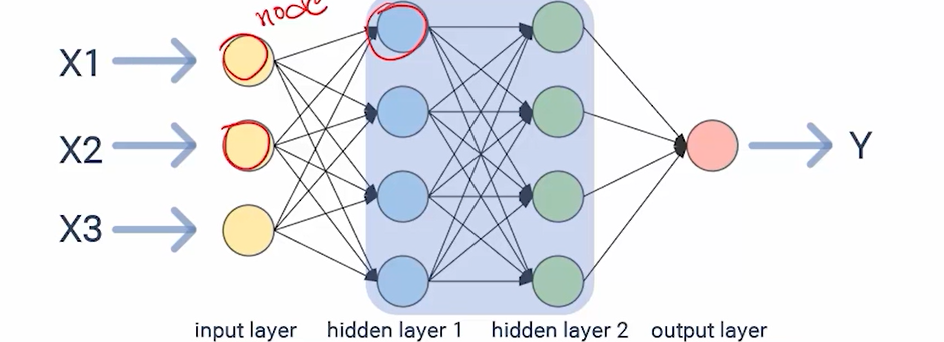
추후에 추가 학습 필요함, 키포인트만 익힐것딥러닝의 동작 원리딥러닝의 구조뇌의 정보처리방식을 모사한 인공신경망과 유사하게 여러 층으로 깊이있게 구성하여 학습을 진행인공신경망의 regressor인공신경망의 classifier학습률을 적용하여 특정 데이터에 크게 움직이지않
24.[이론편]딥러닝 동작원리 Basic - 딥러닝의 구조 및 학습 방법
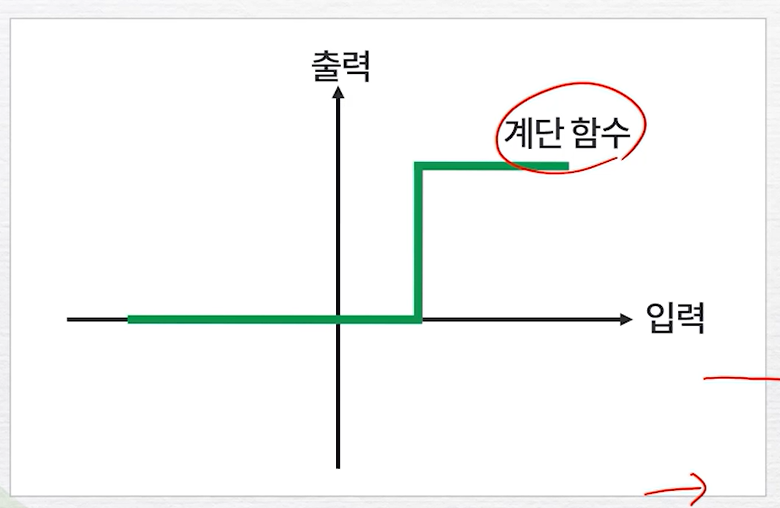
딥러닝의 구조뉴런동작원리전기 입력을 받아 또 다른 전기신호를 발생시킴입력이 누적되어 어떤 수준으로 커진 경우에만 출력이 발생함DNN인공뉴런 = 노드입력의 합이 어떤 조건(활성화 함수)이 되야만 출력을 냄딥러닝 학습방법딥러닝 모델의 매개변수(weight, bias)를 무
25.[실습편]AICE 연습사례(회귀)_음원 흥행 가능성 예측(딥러닝+머신러닝) - 문제 정의 및 데이터 수집

문제정의목적음원투자자는 투자리스크를 최소화 하여 투자 효율을 극대화 하고 싶어한다.목표AI로 흥행이 가능한 음원을 예측해보자.데이터 수집무슨 데이터를 수집하는가?음원 메타 데이터음원사이트 및 음원차트를 통해 입수 가능한 데이터예) 순위, 가수명, 장르..음원 자체 데이
26.[실습편]AICE 연습사례(회귀)_음원 흥행 가능성 예측(딥러닝+머신러닝) - 데이터 분석 및 전처리 1
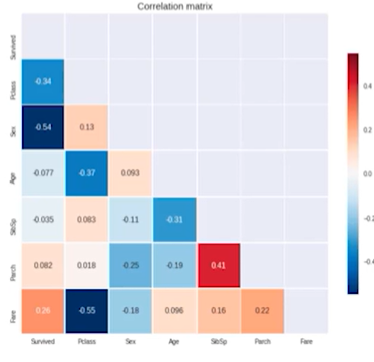
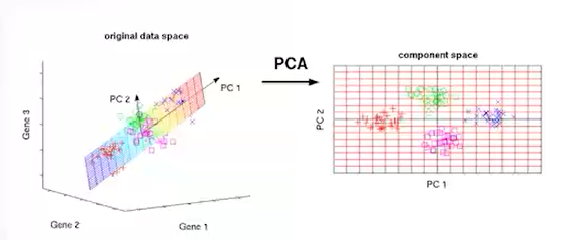
포인트 위주 정리데이터 분석시각화 분석 도구Feature 간 상관관계 분석Heat mapFeature 자체 분석Box plot통계 분석 도구데이터 가공스케일링Min-Max Scaling(normalization)모든 데이터를 0~1 사이로 맞추기Standard Scal
27.[실습편]AICE 연습사례(회귀)_음원 흥행 가능성 예측(딥러닝+머신러닝) - 데이터 분석 및 전처리 2

이전 학습 내용 핵심 데이터 분석 -> 데이터 가공 흐름변수 의미 파악타켓변수 지정타켓변수와 상관관계 파악상관관계 높은 독립변수를 가공결측치, 이상치 처리스케일링이후 학습기초정보탐색흐름1\. 타겟변수 확인회귀, 분류 모델 확인 \- 어떻게? \-
28.[실습편]AICE 연습사례(회귀)_음원 흥행 가능성 예측(딥러닝+머신러닝) - AI 모델링
AI 과제 유형별 성능평가 지표0에 가까울수록 성능 좋음MSE오차의 제곱 평균MAE오차의 절대값의 평균1에 가까울수록 성능 좋음R2독립변수가 종속변수를 얼마나 잘 설명하는지AI 대표 모델(회귀)Linear RegressionDecision TreeRandom Fores
29.[실습편]AICE 연습사례(분류)_중공업 수주 여부 예측(딥러닝) - 문제정의 및 데이터 수집
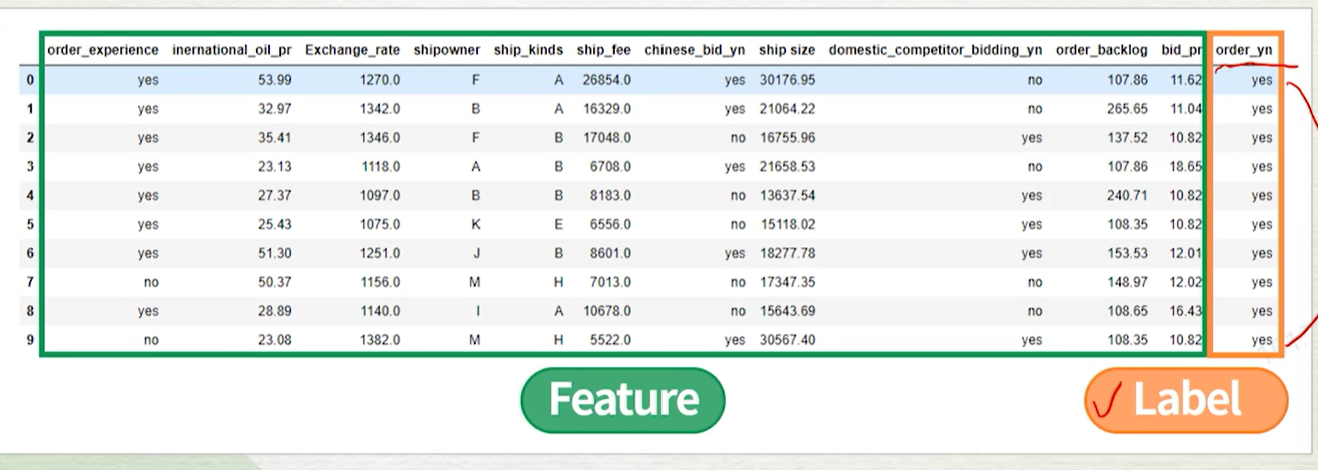
선박 수주 여부 예측하기과제유형이진분류 과제문제정의수주시 유용한 지표가 무엇인지, 수주가 가능한지 예측하는 AI 분류 모델을 만들자데이터 수집데이터 소개타겟변수order_yn범주, 수치형 데이터 파악
30.[실습편]AICE 연습사례(분류)_중공업 수주 여부 예측(딥러닝) - 데이터 분석 및 전처리(1) 핵심개념
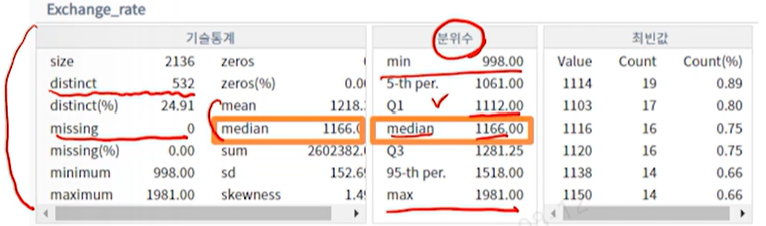
AI모델링 흐름1\. 데이터 분석수치형 데이터, 범주형 데이터, 수치형 범주형 데이터 확인수치형 데이터distinct 확인(많으면 수치형)범주형 데이터distinct 확인(적으면 범주형)한쪽에 많이 치우쳐있으면 데이터 부족을 의심결측치 확인이상치 확인EDA탐색적 데이터
31.[실습편]AICE 연습사례(분류)_중공업 수주 여부 예측(딥러닝) - 데이터 분석 및 전처리(2) 실습

핵심 포인트 위주 정리결측치는 도메인 지식 기반으로 처리해당 ship_pee는 결측치 처리를 median으로 하는것이 적절함 하지만 강의에서는 평균으로 함
32.[실습편]AICE 연습사례(분류)_중공업 수주 여부 예측(딥러닝) - AI 모델링 및 적용(1) 핵심개념
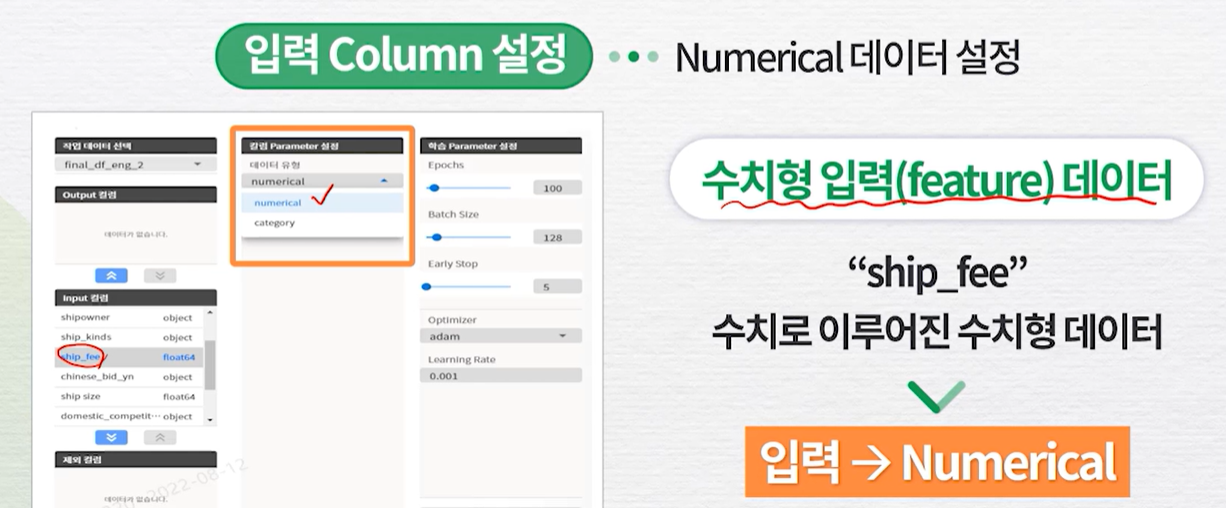
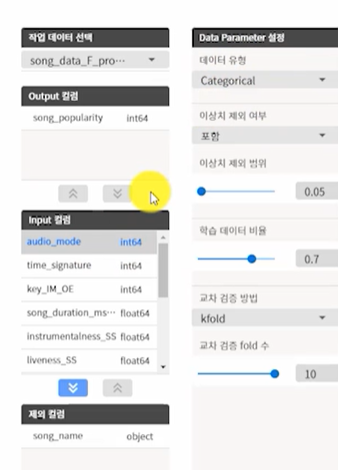
AI 모델링 및 적용1\. 데이터 분리Train60%Test20%Valid20%2\. Model 구조 파라미터 설정1\. 입력 Column 설정2\. 라벨 Column 설정타겟변수가 범주형이므로 분류이진분류면 Sigmoid 다중분류면 Softmax히든 레이어 설정처음은
33.AICE 베이직 자주 볼거
데이터량에 따른 적절한 정도Epochs< 100020~501000~1000050~10010000 <10~50Batch size< 10008~321000~1000032~12810000 <128~512학습률< 10000.0001~0.0011000
34.[실습편]AICE 연습사례(분류)_중공업 수주 여부 예측(딥러닝) - AI 모델링 및 적용(2) 실습
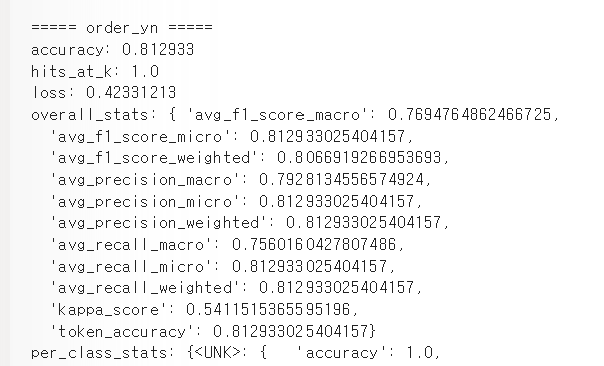
포인트 위주로 정리학습파라미터 설정초기FC레이어 수 : 1FC레이어 크기 : 64Epochs : 20Batch Size : 128Early Stop : 5드롭아웃 : 0 (과적합확인후 0.2~0.3)설정Optimizer : adamLearning rate : 0.001
35.[실습편]AICE 연습사례(분류)_항공사 고객만족 예측(딥러닝) - 문제 정의 및 데이터 수집
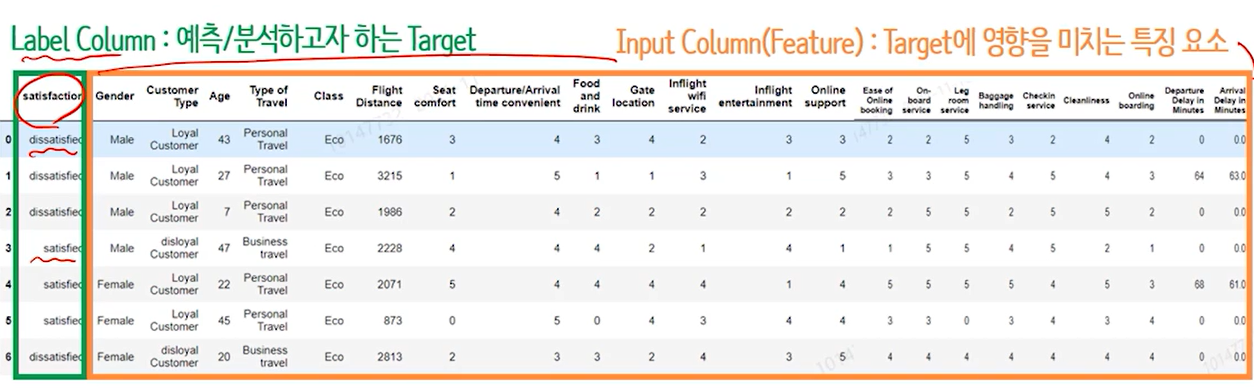
문제 정의다음 사례에서는 여러가지 요소들을 분석하여 고객의 만족 여부를 예측 할 수 있는 AI분류 모델을 만들고자 함데이터 수집항공사\_s_data.csv항공사\_data데이터 샘플독립변수, 타겟변수 지정데이터 타입 확인(범주형, 수치형, 수치형 범주형)
36.[실습편]AICE 연습사례(분류)_항공사 고객만족 예측(딥러닝) - 데이터 분석 및 전처리(1) 핵심개념
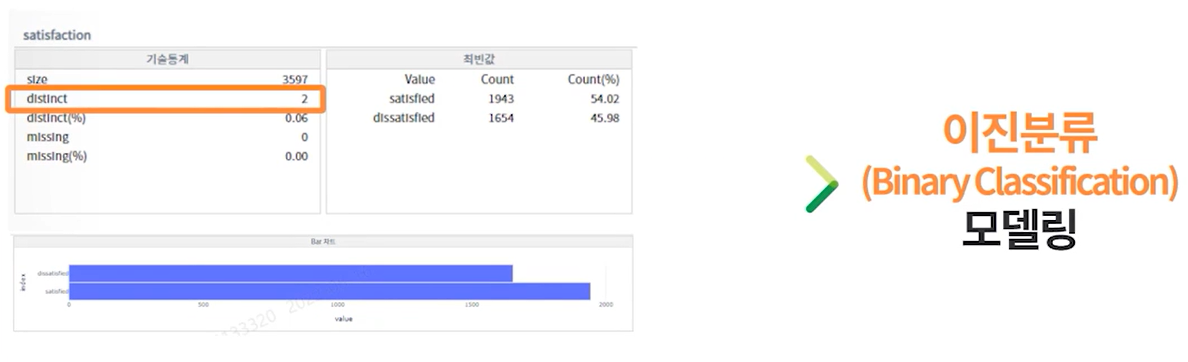
Label 칼럼 분석Label 칼럼(타겟변수)가 범주형 데이터 이므로 만들어야할 모델은 분류 모델임을 알 수 있고 satisfied/dissatisfied 2개의 Class로 구성되므로 분류 모델중 이진분류모델을 만들어야함을 할 수있음Input 칼럼 : 카테고리형 데이
37.[실습편]AICE 연습사례(분류)_항공사 고객만족 예측(딥러닝) - 데이터 분석 및 전처리(2) 실습
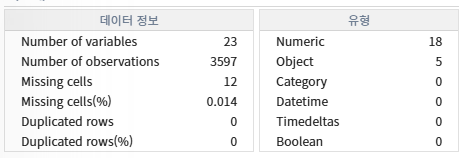
실습 중 핵심 포인트만 작성1\. 기초정보분석확인할거데이터 타입 확인(수치형, 범주형)결측치 컬럼 확인전체적인 데이터 정보들2\. 상관관계분석확인할거히트맵을 통해 히트맵과 상관관계가 높은 컬럼확인(실제로는 0에 가까운 컬럼은 삭제하지만 실습에서는 확인만 함)해당 사진에
38.[실습편]AICE 연습사례(분류)_항공사 고객만족 예측(딥러닝) - AI 모델링 및 적용(1) 핵심개념
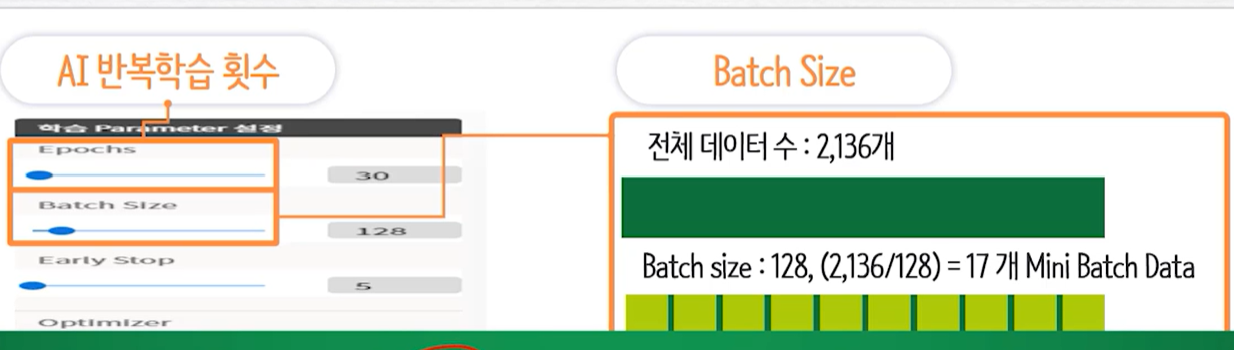
학습데이터/평가데이터 분리Train Data60% , 70%Vaild Data20%, 30%Test Data20%, 10%Apochs과 Batch Size과적합 방지Valid 오차율은 높아지는데 Train 오차율 낮아짐 -> 일반화 XLearning RateRecall
39.[실습편]AICE 연습사례(분류)_항공사 고객만족 예측(딥러닝) - AI 모델링 및 적용(2) 실습
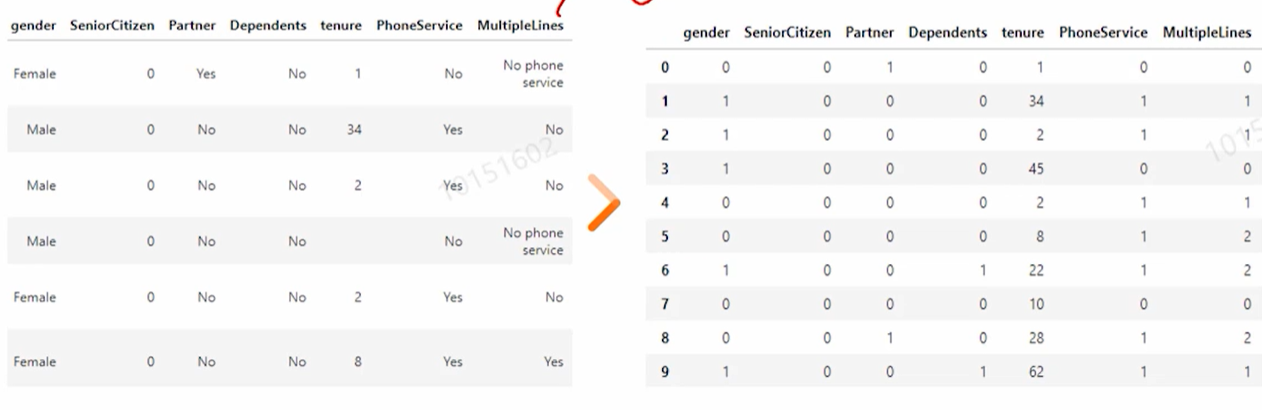
시뮬레이션 예시에 따라 가공 처리가 정해짐(예시가 처리안해있으면 처리생략)ㅇ수치형 범주형 데이터이지만 수치형으로 모델링 학습해당 컬럼들은 수치형 범주형이지만 수치형이라고 두고 모델을 학습 \- 해도되는이유: 해당 컬럼은 수치형 범주형이지만 1,2,3,4,5의 의미
40.[실습편]AICE 연습사례(회귀)_미세먼지 수치 예측(딥러닝) - 문제 정의 및 데이터 수집
문제정의목적건강에 해로운 미세먼지로부터 우리를 보호하자.목표미세먼지의 농도를 미리 예측하는 AI 모델을 만들어 고객에게 미세먼지 예측 정보를 제공하자.데이터 수집원본 데이터 소개데이터 유형수치형이진형범주형문자형데이터 정의
41.[실습편]AICE 연습사례(회귀)_미세먼지 수치 예측(딥러닝) - 데이터 분석 및 전처리(1) 핵심개념
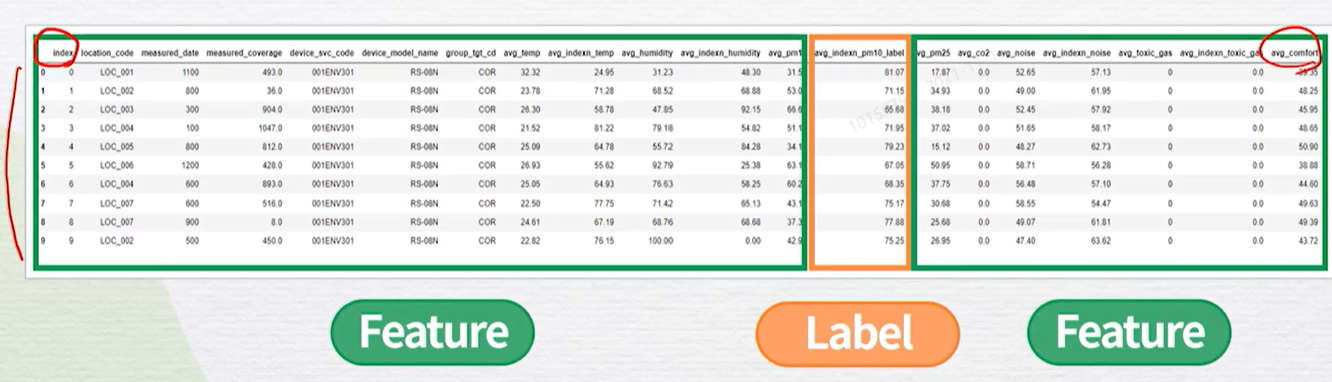
데이터분석데이터 상관관계 분석데이터 전처리컴퓨터가 인식/학습 할 수 있도록 하는 데이터 가공(수정) 과정인코딩결측치 처리스케일링(정규화)이상치 처리데이터 전처리를 하는 이유distinct가 높은 컬럼 삭제인덱스는 삭제해도 무방
42.[실습편]AICE 연습사례(회귀)_미세먼지 수치 예측(딥러닝) - 데이터 분석 및 전처리(2) 실습
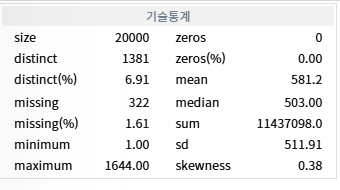
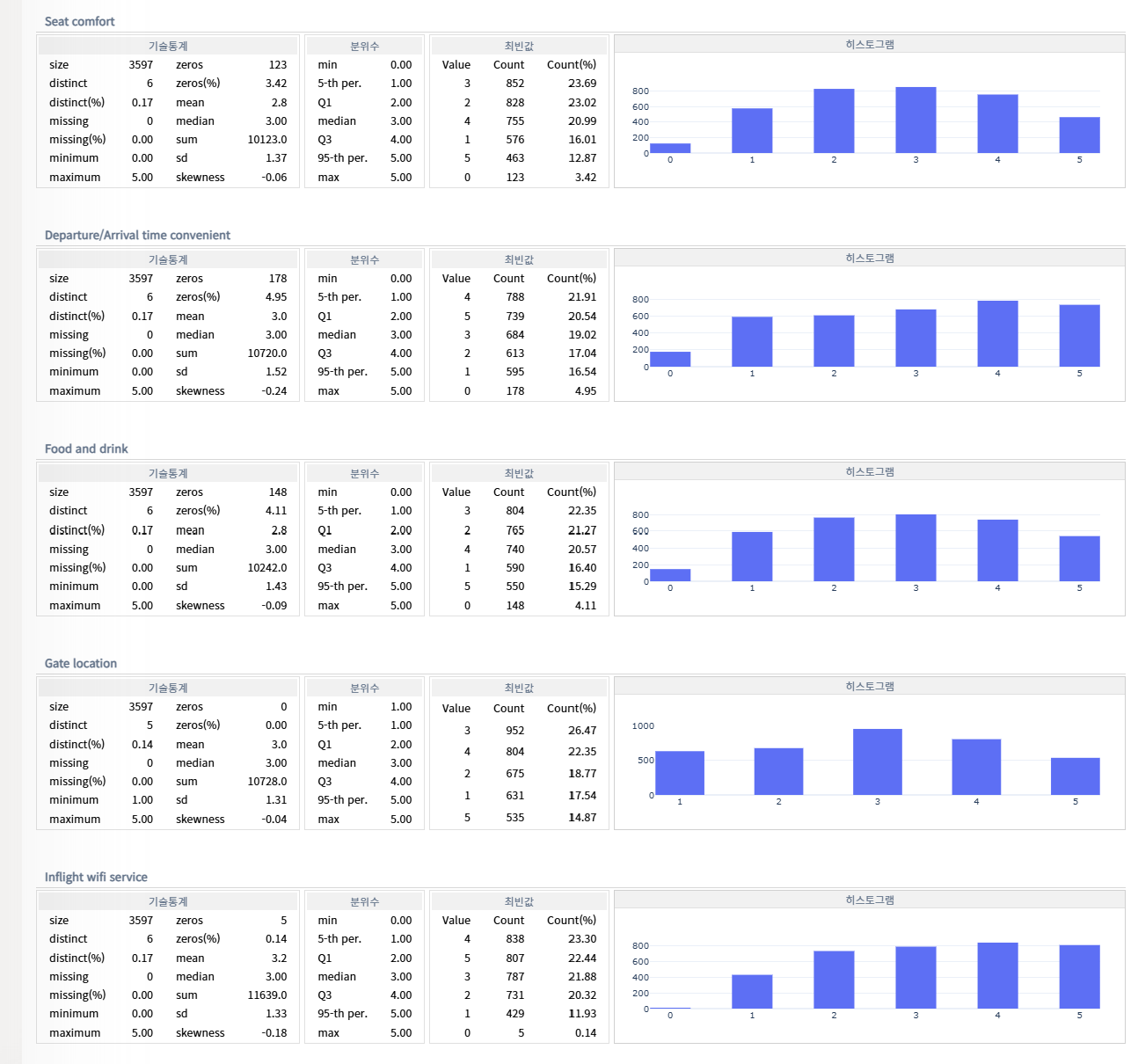
핵심 포인트 위주로 정리sd 는 표준편차(평균에서 얼마나 퍼져있는지)50% 에 있는 값 median25% 에 있는 값 Q175% 에 있는 값 Q35% 에 있는 값 5-th per95% 에 있는 값 95-th per결측치 처리강사: 히스토그램이 평평하므로 최빈값으로 채움
43.[실습편]AICE 연습사례(회귀)_미세먼지 수치 예측(딥러닝) - AI 모델링 및 적용(1) 핵심 개념
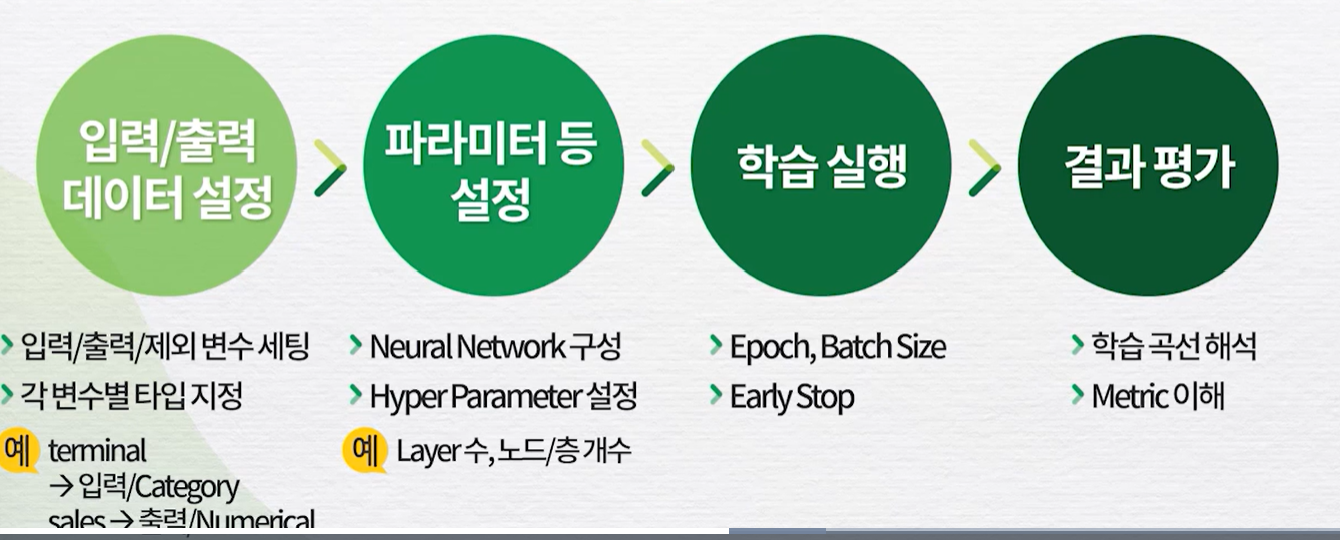
AI 모델링 및 적용 프로세스딥러닝의 입/출력딥러닝 구조
44.[실습편]AICE 연습사례(회귀)_미세먼지 수치 예측(딥러닝) - AI 모델링 및 적용(2) 실습1
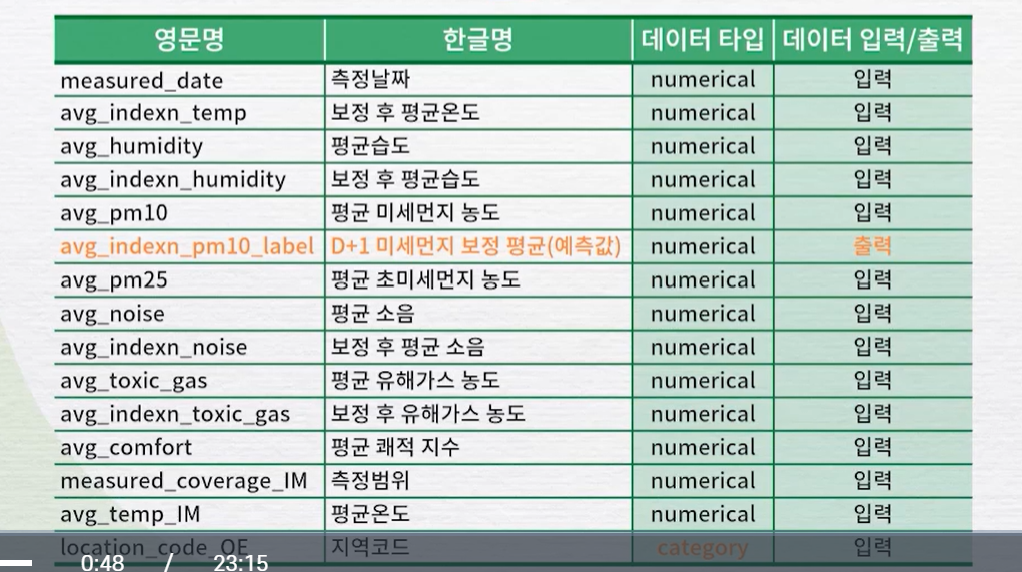
딥러닝에서 수치예측딥러닝에서 수치예측을 할때는 Relu가 적절sigmoid, softmax는 분류tanh는 일반적으로 안쓰임, 특이한 상황에서 Relu 대신 사용1\. 데이터 입출력 설정입력 데이터 처리 방식 설정스케일 문제히스토그램 만 봤을 때 해당컬럼에 문제가 있는
45.[실습편]AICE 연습사례(회귀)_미세먼지 수치 예측(딥러닝) - AI 모델링 및 적용(3) 실습2
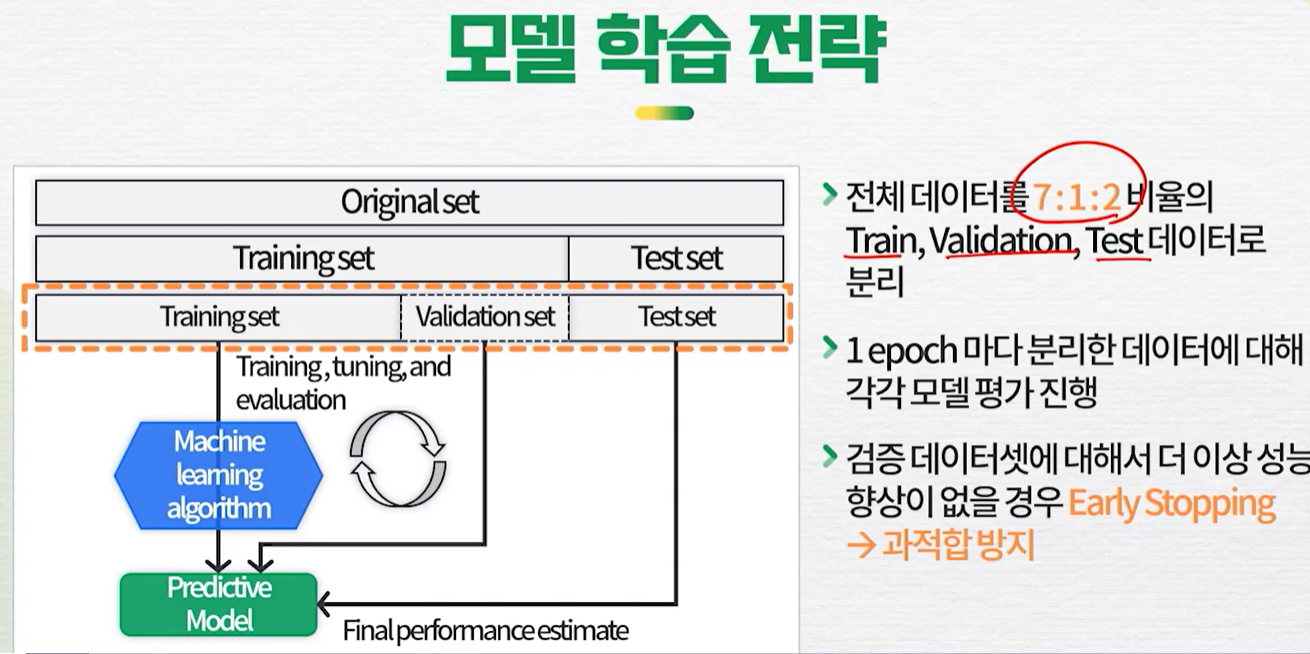
모델 학습 전략Validation는 파라미터 튜닝, 성능 평가에 사용학습결과강의 모델내 모델동일하게 파라미터를 설정했는데 더 점수가 낮게 나오는걸 확인 가능데이터셋 차이로 판단됨train, validation, test의 학습 횟수(이터레이션)Q8딥러닝에서 과적합 판단