알고리즘&자료구조 (JS)
1.Big O Notation
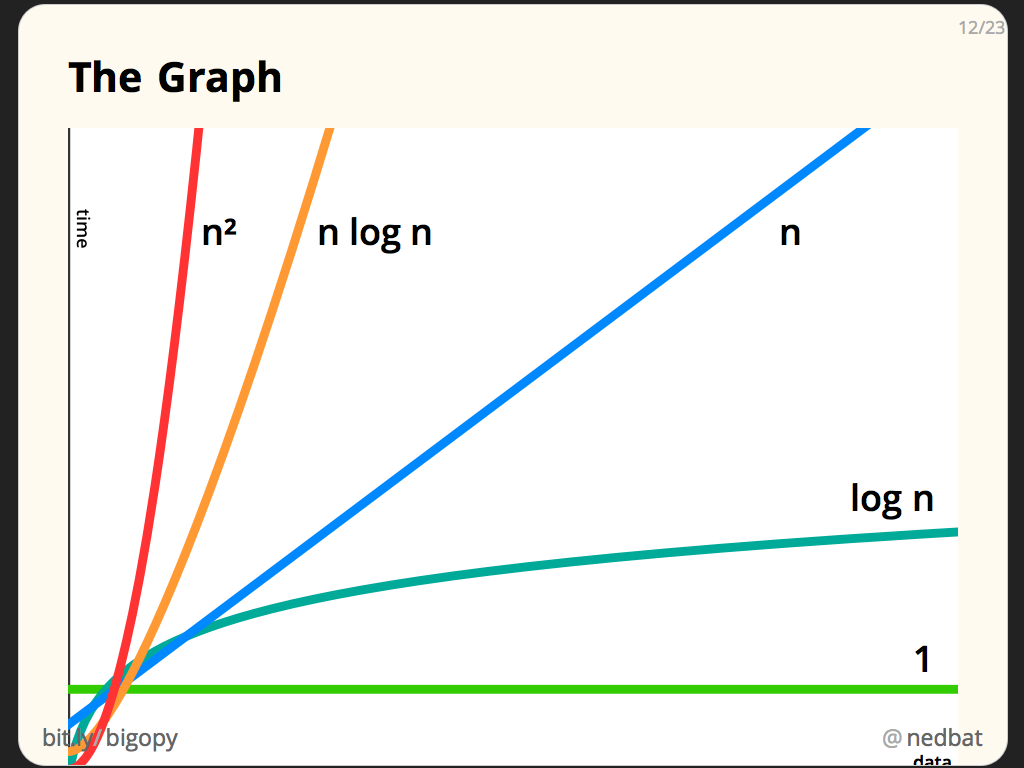
가장 많이 나오고 중요한 파트!어떤 문제에 대해 다양한 접근법이 있을 수 있는데, Big O Notation은 이 여러 접근법들을 서로 비교하여 성능을 평가할 수 있는 방법이다.코드의 성능을 빅오형식으로 분류할 수 있다.(매우 좋음/좋음/별로임/..)코드의 perfor
2.배열과 객체의 Big O

객체는 정렬이 되어 있지는 않지만 입력, 제거, 접근이 매우 빠르다.\-> 정렬이 중요하지 않을 때 객체는 좋은 선택지가 될 수 있다.Insertion, Removal, Access : O(1)Searching : O(n)Object.keys : O(n)Object.
3.문제 해결 접근법
특정 작업을 달성하기 위한 과정이나 일련의 단계를 의미한다.문제 해결을 위한 계획 수립일반적인 문제 해결 패턴 파악나만의 언어로 문제를 설명할 수 있는가?문제가 어떤 입력값을 담고 있는가?출력값은 어떤 형태여야 하는가?문제를 해결할 단서가 충분히 주어졌는가?문제에서 정
4.문제 해결 패턴
빈도수 세기, 다중 포인터, 기준점 간 이동 배열, 분할과 정복
5.재귀 (Recursion)
자기자신을 호출하는 함수를 의미한다.다양한 솔루션에 활용된다.ex. JSON.parse, JSON.stringify, document.getElementById, Object traversal반복 대신 재귀를 사용하는 게 더 깔끔할 때가 있다. 호출 스택은 자바스크립트
6.검색 알고리즘
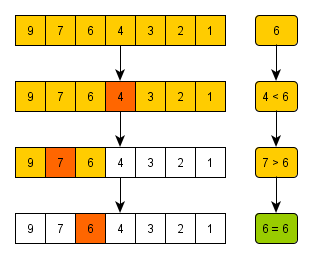
배열이나 문자열이 주어질 때, 특정 값이 있는지 확인하는 방법.크게 선형 검색과 이진 검색이 있다.모든 개별 항목을 순서대로 살펴보는 방법시간 복잡도 : O(1) 혹은 O(n)메서드 : indexOf, includes, find, findIndexindexOf는 특정
7.버블 정렬
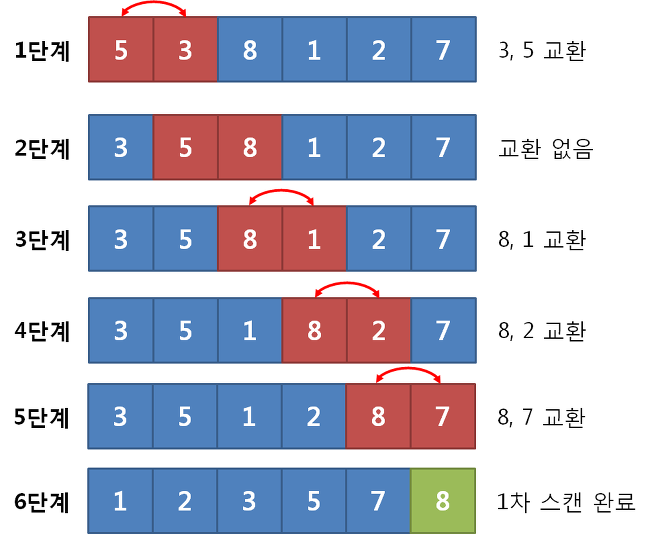
collection의 항목을 재배열하는 과정을 의미한다.ex) 배열 안의 숫자들을 오름차순/내림차순으로 정렬, 문자를 알파벳순으로 정렬, 영화 데이터를 개봉 연도순으로 정렬하는 등정렬이 프로그래밍에서 매우 흔하게 사용되기 때문이다.정렬할 수 있는 방법이 굉장히 다양하고
8.선택 정렬
선택 정렬 맨 앞의 값과 뒤의 값들을 비교해 더 작은 값이 나오면 위치를 바꾼다. 시간 복잡도 : O(n^2) 별로 좋지 않음 > 선택 정렬 과정 애니메이션으로 보기 https://visualgo.net/en/sorting?slide=4-1 최솟값을 저장할 변수 만
9.삽입 정렬
삽입 정렬 한 번에 하나의 항목을 올바른 위치에 삽입해서 배열의 정렬된 부분을 점진적으로 구축함. 시간 복잡도 : 랜덤 데이터의 경우 : O(n^2) 거꾸로 정렬된 경우가 최악의 케이스 거의 정렬된 데이터의 경우 가장 좋음 >삽입 정렬 과정 애니메이션으로 보기 ht
10.합병 정렬

합병 정렬, 퀵 정렬, 지수 정렬 매우 빠른 정렬 방법이다. 시간 복잡도를 O(n^2)에서 O(n log n)로 향상시킬 수 있다. -> 앞에서 배운 세 가지 정렬 방식보다 빠르다. 효율성이 높지만, 이해하기 어렵고 가독성이 좋지 않다. 합병 정렬 배열을 계속 반
11.퀵 정렬
퀵 정렬(Quick Sort) 특정 지점(pivot)을 기준으로 작은 값은 왼쪽으로, 큰 값은 오른쪽으로 이동시킨다. (자동으로 pivot은 올바른 위치에 놓여짐.) 단일 요소가 될 때까지 위의 과정을 재귀적으로 반복한다. Pivot Helper pivot 설정 기준
12.기수 정렬
비교 정렬 알고리즘 지금까지 살펴본 정렬들(버블 정렬, 선택 정렬, 삽입 정렬, 합병 정렬, 퀵 정렬)은 모두 비교 정렬 알고리즘에 속한다. 공통적으로 주어진 시점에서 2개의 항목을 비교한다. 평균 시간 복잡도가 O(n^2) ~ O(n log n) 이다. 더 빠른 정
13.자료구조
자료구조에 대해 왜 알아야 하는가? 다루어야 할 데이터가 점점 복잡해질수록 배열과 같은 단순한 자료구조가 아닌 고급 자료구조가 필요해질 수 있다. 가장 좋은 자료구조는 없다. 각각의 자료구조는 각자만의 특화된 재능을 갖고 있다. ex. 지도/위치를 다룰 때 -> 그래
14.단일 연결 리스트
📌 단일 연결 리스트(Single Linked List) 연결 리스트 : 인덱스 없이 다수의 데이터(노드)들로 연결. 각각의 엘리먼트를 노드라고 한다. 각각의 노드는 문자열/숫자와 같은 하나의 데이터를 저장한다. 각 노드들은 다음 노드를 가리키는 정보 역시 저장해
15.이중 연결 리스트
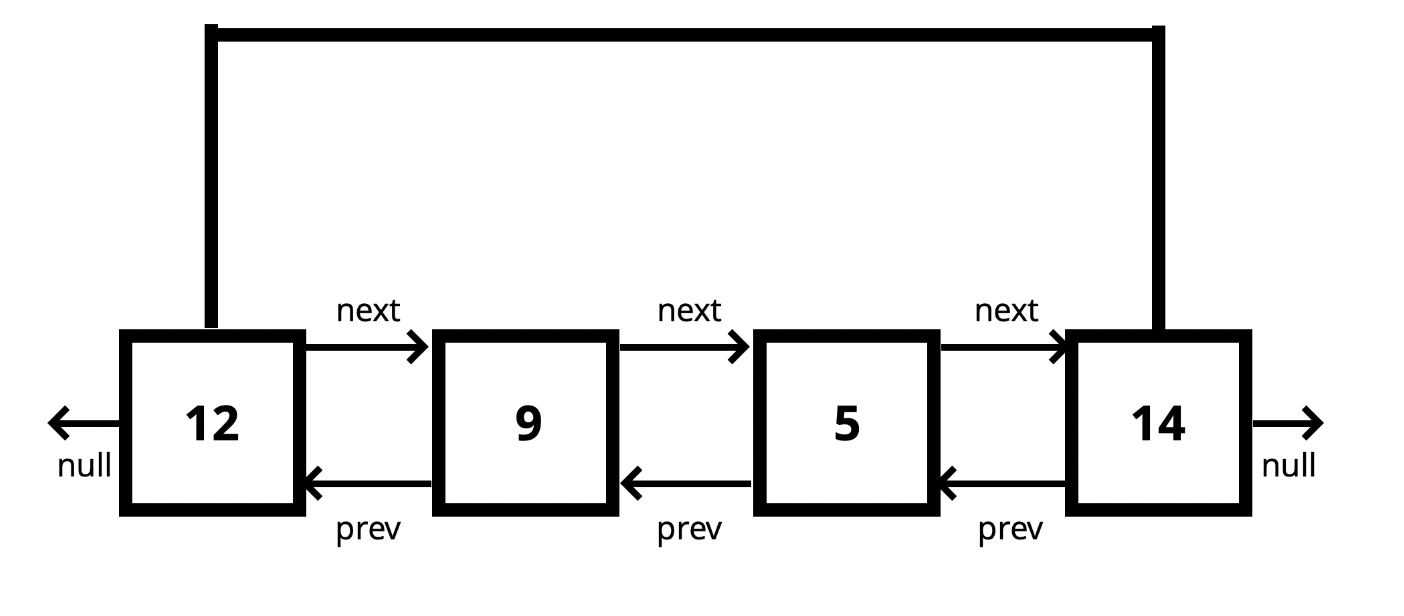
단일 연결 리스트에 앞의 노드에 대한 포인터를 추가했다고 생각하면 된다.구성 : head, tail, length, next, prev단점 : 새로운 포인터를 저장하므로 메모리가 더 많이 든다.장점 : 단일 연결 리스트에서 pop을 할 때는 head에서부터 한 방향으로
16.스택(Stacks) & 큐(Queues)
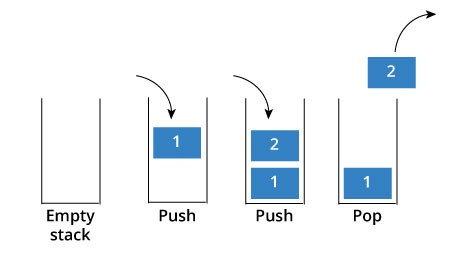
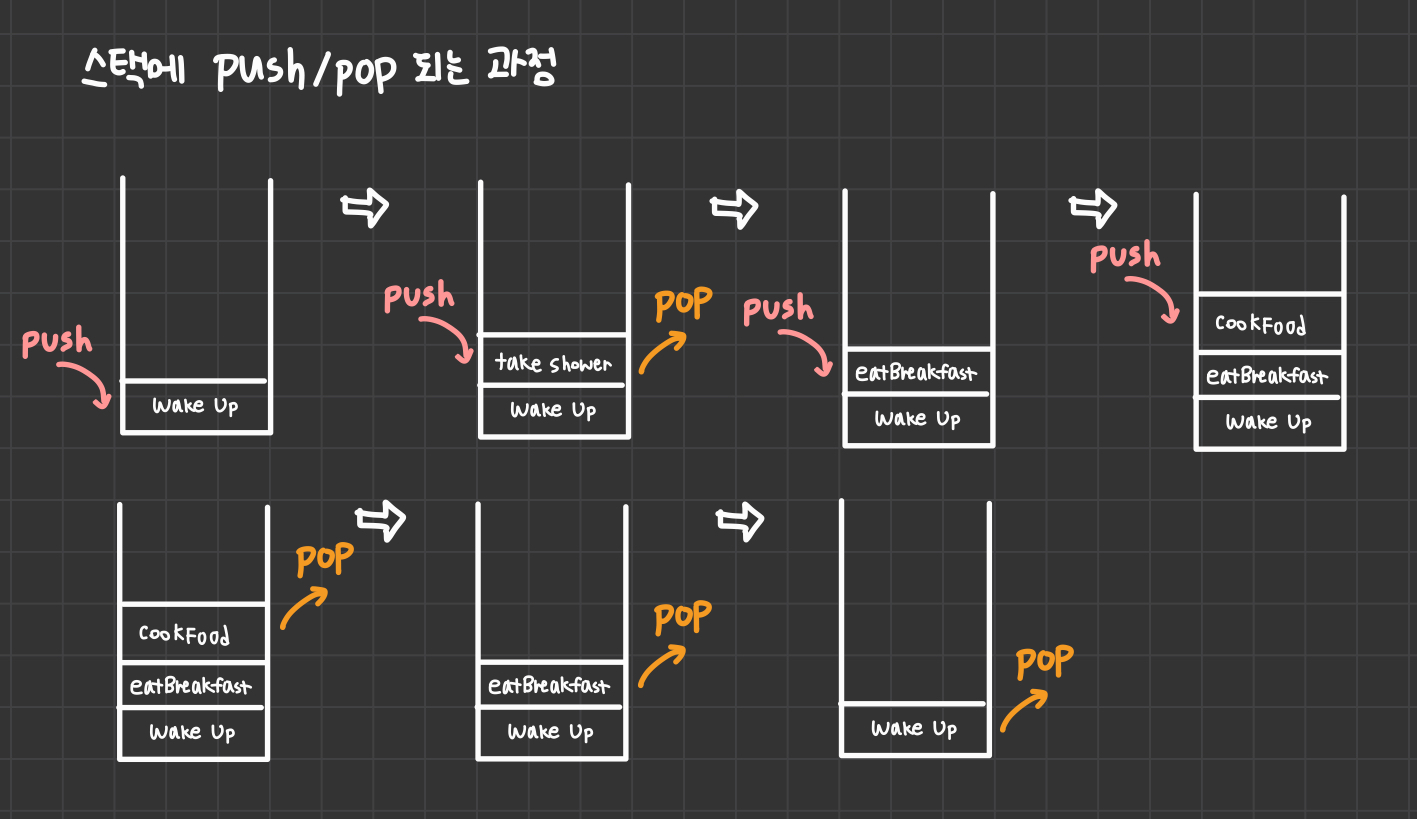
후입선출(LIFO)에 따라 데이터를 추가하고 삭제하는 자료구조.가장 마지막으로 추가된 요소가 가장 먼저 제거된다.예시: 함수 호출을 다루는 상황(호출 스택)undo/redo(포토샵에서 실행 취소, 재실행)인터넷 브라우저에 있는 방문 기록추가 : push, 삭제: pop
17.이진 탐색 트리(BST)
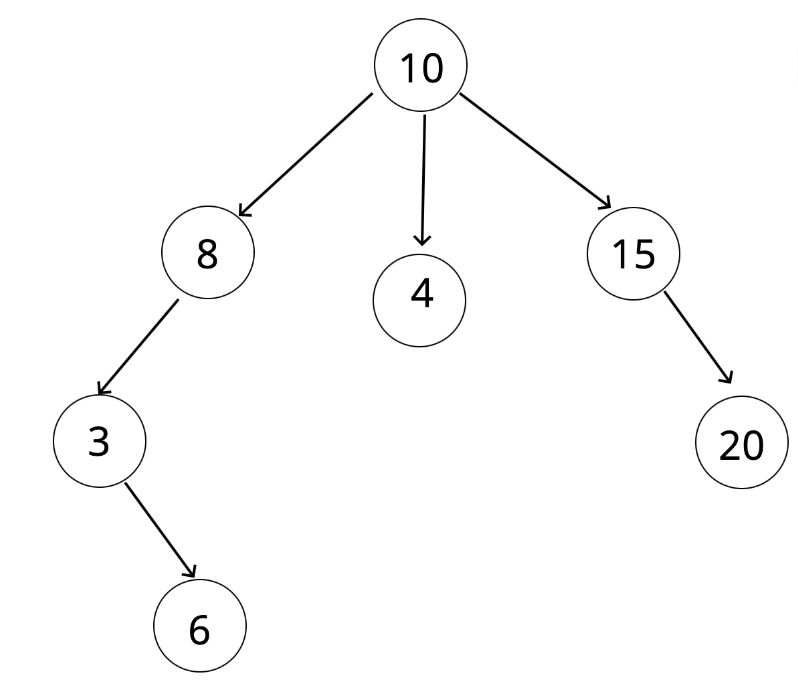
📌 Tree 노드들이 부모/자식 관계로 이루어진 자료구조 앞에서 배운 리스트들은 선형구조(Linear) 이지만, 트리는 비선형구조(nonlinear)이다. 용어 Root : 트리 꼭대기에 있는 노드 Child : 다른 노드와 연결되어 루트로부터 멀어지는 노드 P
18.트리 순회(BFS, DFS)
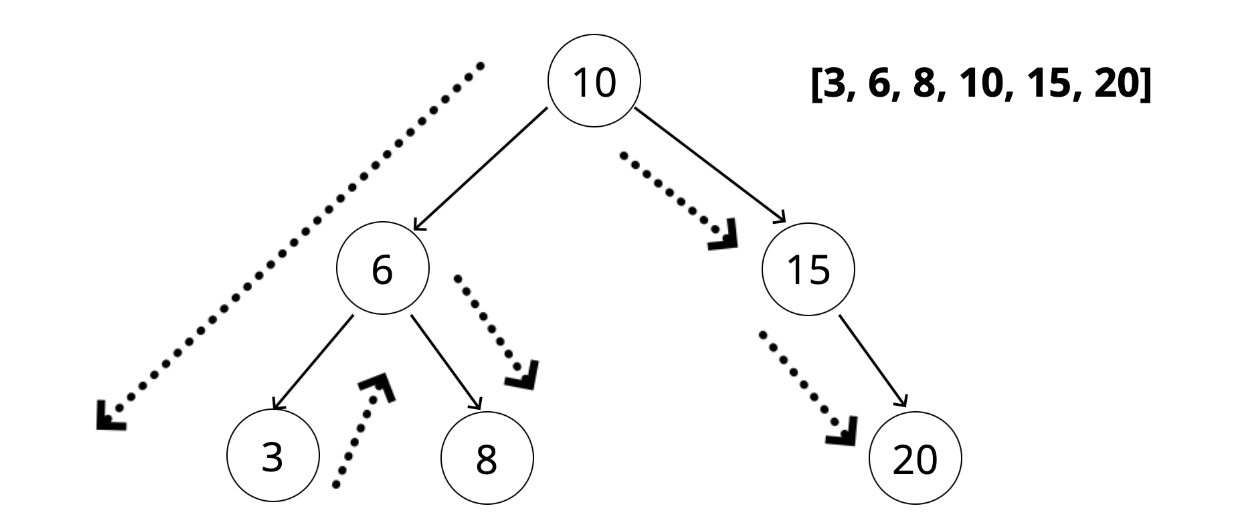
트리 순회 (Tree Traversal) 연결 리스트를 순회하는 방법은 선형 접근법 한 가지만 존재하지만, 트리 순회에는 다양한 접근법이 있다. 가장 널리 쓰이는 두 가지 접근법이 있다. 1. BFS(Breadth First Search) : 너비 우선 탐색 자식
19.이진 힙(Binary Heaps)
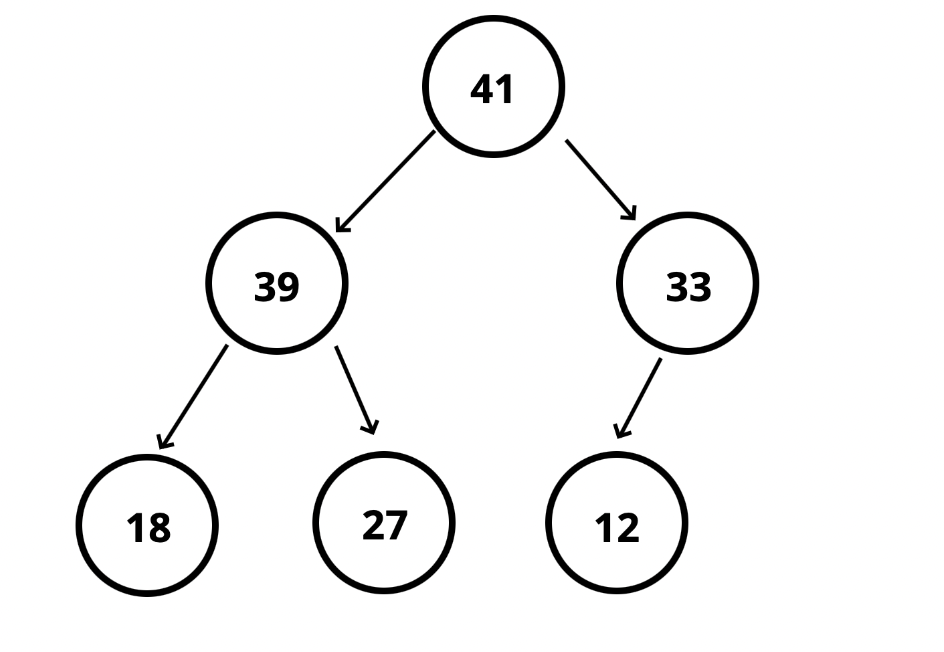
## 📌 Binary Heaps : 이진 탐색 트리(`BST`)와 유사하지만 다른 규칙이 있다. - `Max Binary Heap` : 부모 노드들이 항상 자식 노드들 보다 크다. - `Min Binary Heap` : 부모 노드들이 항상 자식 노드들 보다 작다.
20.우선순위 큐(Priority Queue)
📌 Priority Queue 각 요소가 그에 해당하는 우선순위를 가지는 데이터 구조. 더 높은 우선순위를 가진 요소가 더 낮은 우선순위를 가진 요소보다 먼저 처리된다. 구현 방법 1. 배열을 이용해 구현. 리스트를 전부 순회하면서 우선순위가 높은 것을 찾아야 하
21.해시 테이블(Hash Table)
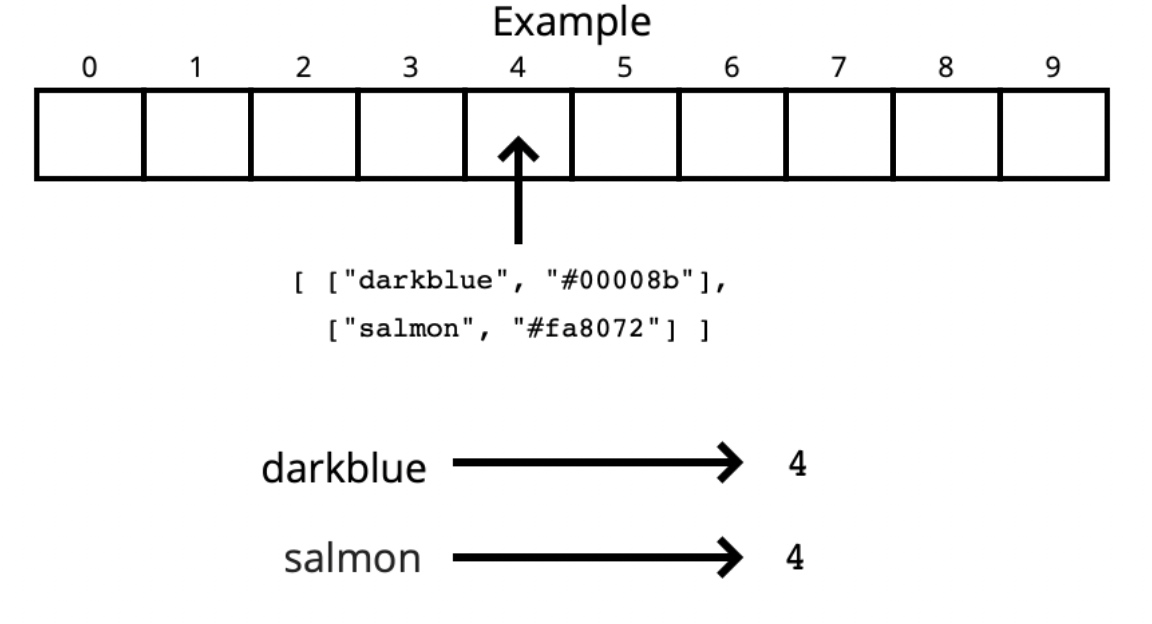
해시 테이블은 데이터를 key-value 쌍으로 묶은 자료구조를 말한다.거의 대부분의 언어에 해시 테이블 기능이 있으며, 자주 사용되는 자료 구조이다.JS 에서는 object 와 Map이 해시 테이블에 해당한다.Python 에서는 Dictionary가 해시 테이블에 해
22.그래프(Graphs)
그래프는 노드나 노드들의 연결을 모은 것이다.Nodes + Connections기본적으로 모든 SNS에서 사용된다. 사용자 추천 엔진등을 만들때 사용.트리는 그래프의 일종이다.소셜 네트워킹지도/위치파일 시스템 최적화 (위키피디아 문서 구조)등등vertex : 노드edg
23.그래프 순회(BFS,DFS)
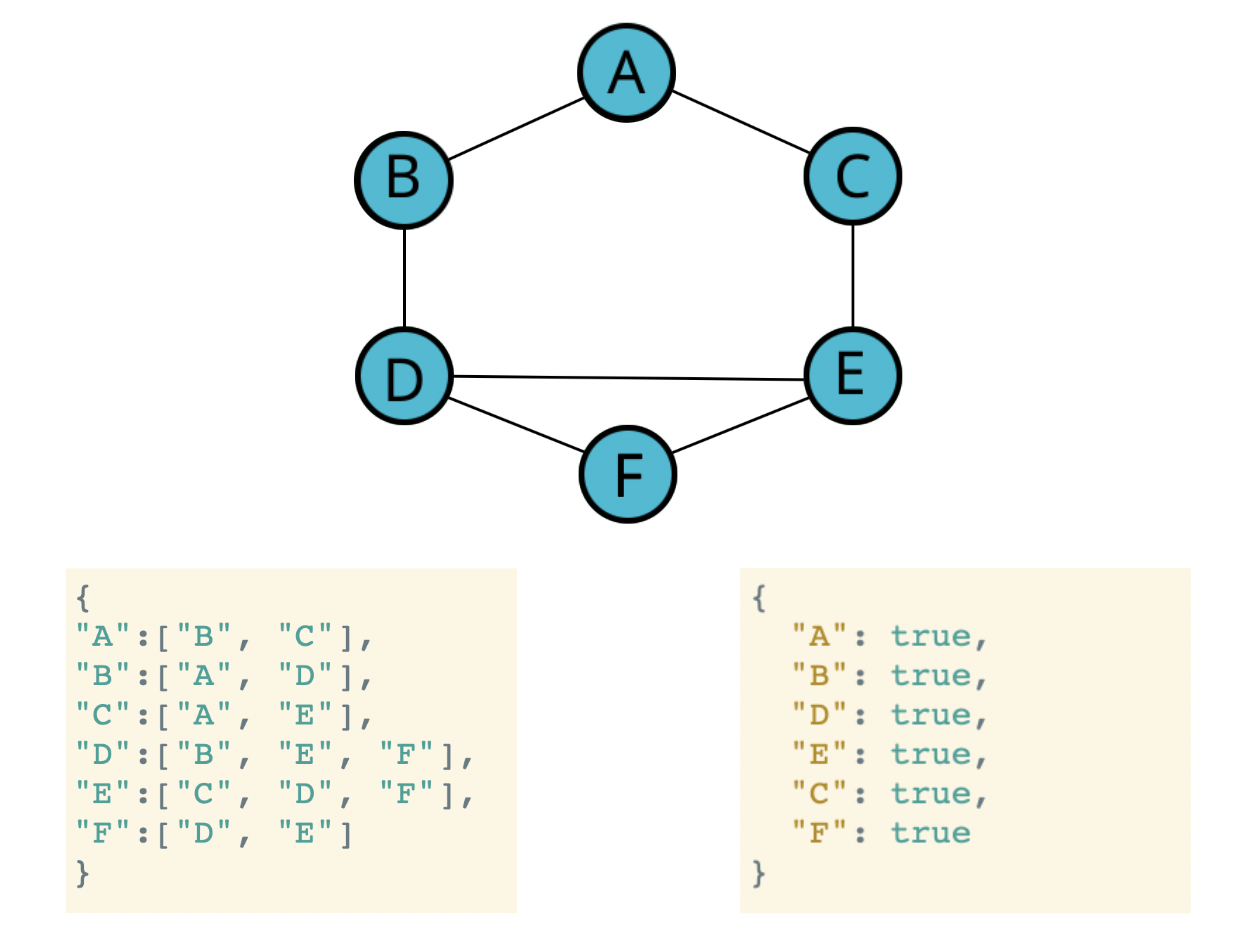
트리와는 다르게 그래프를 순회할때는 시작점을 정해주어야 한다.(그래프에는 루트가 없기 때문.)그래프에서는 깊이라는 개념이 모호한데, 인접점의 인접점을 따라 길이 막힐때까지 가는 것을 의미한다.1\. 각 vertex의 인접점을 해시 테이블에 담아둔다. 2\. 시작점을 정
24.다익스트라 알고리즘(Dijkstra's Algorithm)
📌 다익스트라 알고리즘(Dijkstra's Algorithm) 다익스트라 최단 경로 알고리즘의 줄임말 가장 유명하고 널리 사용되는 알고리즘 중 하나이다. 그래프에 대해 작동한다. 코딩을 할 때 우선순위 큐를 사용한다. 우선순위 큐 대신 이진 힙을 사용하면 더 빠르다
25.동적 프로그래밍(DP)
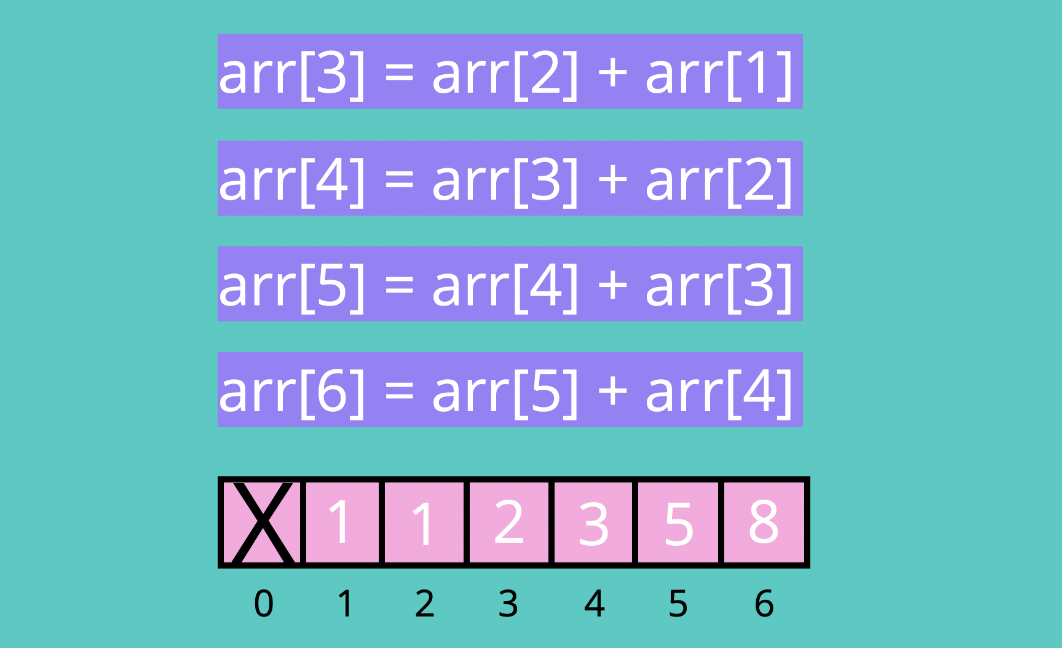
📌 동적 프로그래밍(Dynamic Programming, DP) 복잡한 문제를 더 간단한 하위 문제의 모음으로 쪼개서 푸는 것 >### 동적 프로그래밍을 효율적으로 사용할 수 있는 문제 조건 1. 반복되는 하위 문제 : 동적 프로그래밍을 쓰기 위해서는 그 문제에 중
26.자바스크립트로 보는 큐
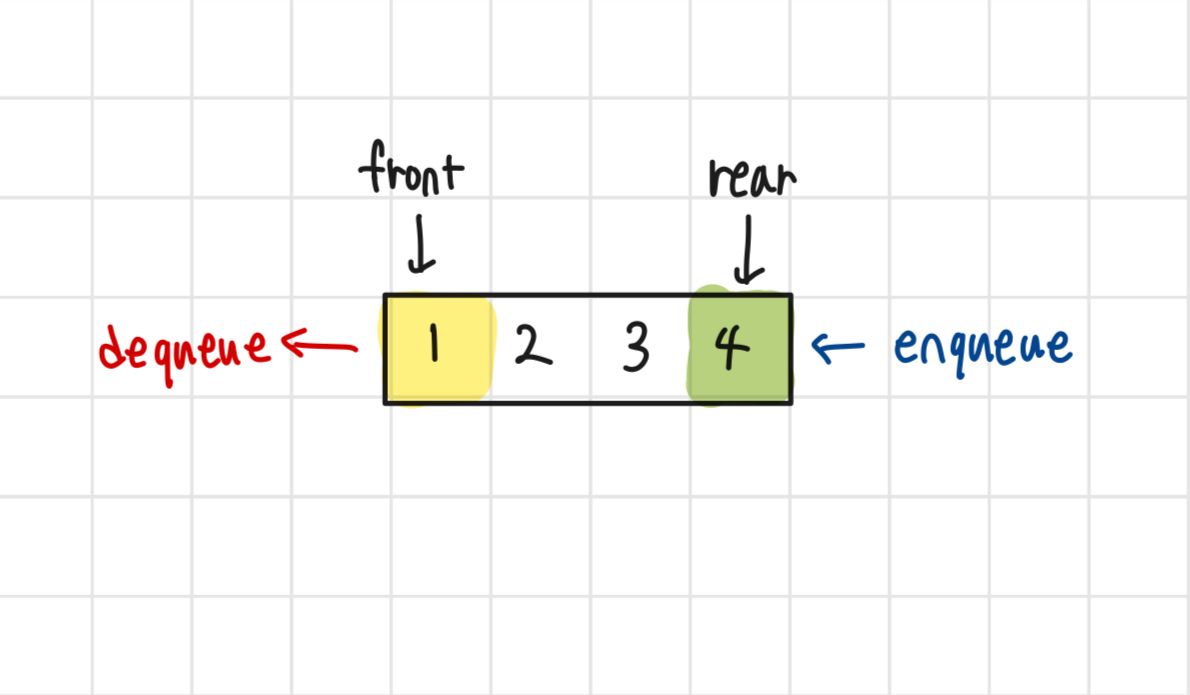
큐는 선입선출(FIFO)의 규칙을 가지는 자료구조이다.즉, 가장 먼저 넣은 것이 가장 먼저 나오는 구조이다. (일반적으로 매장에서 물건을 팔 때 가장 오래전에 들어온 물건을 먼저 파는 것과 동일하다고 생각하면 된다.)가장 먼저 들어온 것을 먼저 처리해야 할 때BFS 탐
27.자바스크립트로 보는 덱
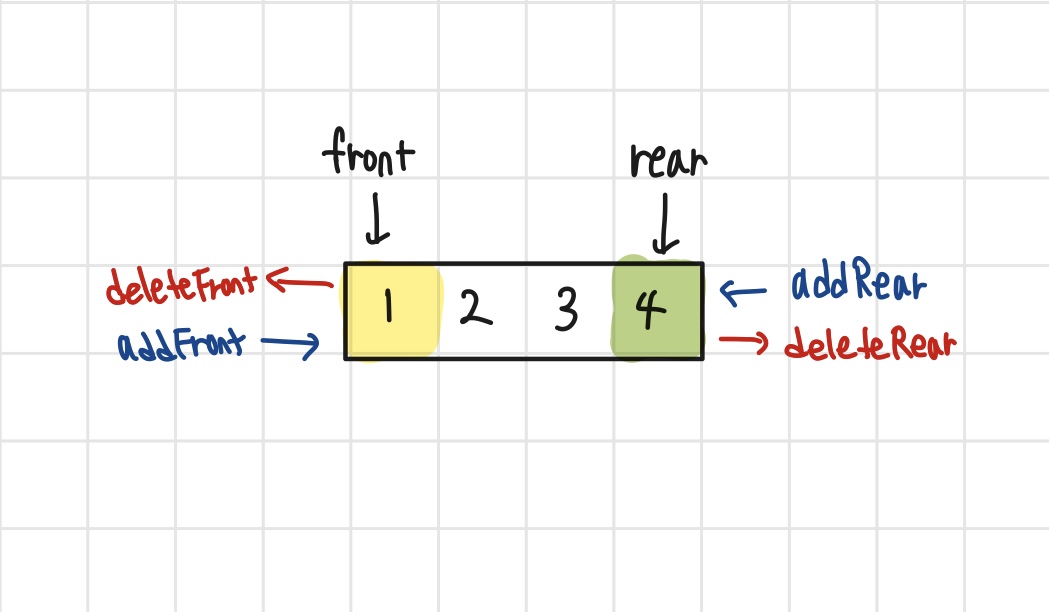
덱(Deque)는 어떤 자료구조인가? 스택,큐와 유사한데 양쪽에서 데이터를 추가하고 삭제할 수 있는 자료구조이다. Double-Ended Queue의 줄임말이다.(Deque) 필요한 프로퍼티는 큐와 동일하고, 앞에 요소를 추가하는 메서드와 뒤에 요소를 삭제하는 메서드가
28.자바스크립트로 보는 힙과 우선순위 큐
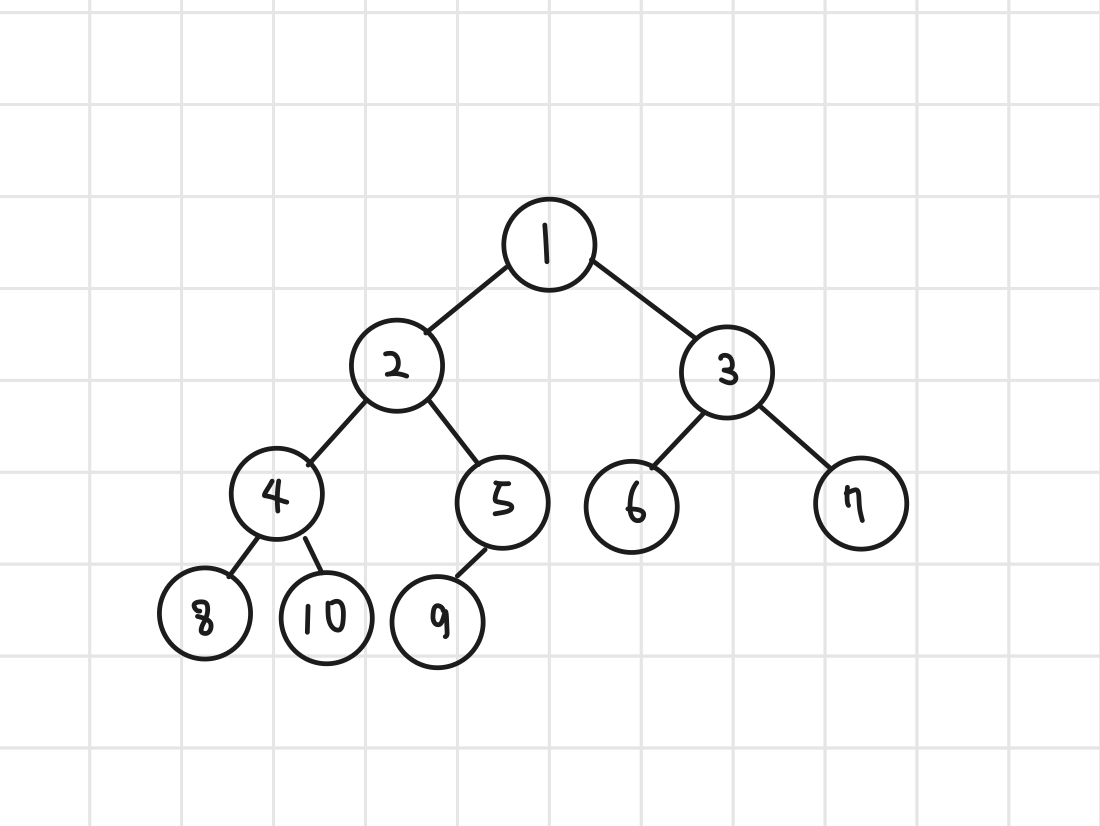
우선순위 비교가 필요한 경우 다익스트라 (최단 거리) 작업 스케줄링 / 우선 처리 모든 비용이 동일하다면 BFS를 사용하면 된다. 백준 최대 힙 실버 2 https://www.acmicpc.net/problem/11279 백준 카드 합치기 골드 4 일단 모든
29.자바스크립트로 보는 이분 탐색
이분 탐색은 어떤 알고리즘인가? 이분 탐색은 리스트에서 특정 값이 존재하는지 찾을 때 쓰는 알고리즘이다. 데이터가 정렬되어 있어야 한다. 일반적으로 배열을 모두 순회하며 값을 찾으려면 O(N)의 시간복잡도를 가지지만 이분 탐색은 탐색 범위가 절반씩 줄어드므로 O(log
30.자바스크립트로 보는 투 포인터
투 포인터란? 투 포인터는 배열에서 2개의 포인터를 조건에 따라 이동시키며 원하는 값을 찾는 알고리즘이다. 보통 left, right로 불리는 두 가지의 포인터를 가진다. 매번 하나씩 포인터를 이동시키기 때문에 배열을 1번 순회하는 것과 같으므로 시간 복잡도는 O(N)
31.자바스크립트로 보는 DFS
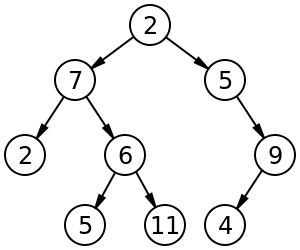
DFS는 depth-first-search의 줄임말로 그래프에서 깊이를 우선적으로 탐색하는 알고리즘이다.이때 그래프는 정점(node)와 간선(edge)으로 구성된 자료구조로, 정점이 목적지라면 간선은 목적지를 잇는 경로를 의미한다.깊이를 우선적으로 탐색한다는 것은 한
32.자바스크립트로 보는 BFS
BFS는 어떤 알고리즘인가? BFS는 breadth-first-search의 줄임말로, 그래프에서 너비를 우선으로 탐색하는 알고리즘이다. DFS는 한 경로를 끝까지 파고 들어가지만, BFS는 현재 위치에서 가까운 요소들을 우선적으로 탐색한다. BFS는 어떤 상황에 쓰
33.자바스크립트로 보는 완전 탐색
완전 탐색이란? 완전 탐색은 가능한 모든 경우의 수를 전부 탐색하여 정답을 찾는 기법이다. 이름 그대로 하나도 빠짐없이 모든 경우를 확인한다는 뜻이다. 다른 최적화 기법을 사용하지 않더라도 반드시 정답을 찾을 수 있다는 장점이 있지만, 경우의 수가 많아질수록 시간이
34.자바스크립트로 보는 그리디/탐욕법
그리디(탐욕법)이란? 매 순간 가장 좋아보이는 선택을 하는 알고리즘이다. 현재 상황에서 최선인 선택을 반복하여 결과적으로 최적 해를 구하기 위한 전략이다. 그리디는 언제 사용하는가? 그리디는 아래 두 가지 속성을 만족할 때에만 사용할 수 있다. 1. 그리디 선택 속
35.자바스크립트로 보는 DP/동적 계획법
DP는 큰 문제를 작은 문제로 쪼개고 그 결과를 저장해서 중복 계산을 없애는 알고리즘이다.큰 문제의 최적해가 작은 문제들의 최적해로 구성된다.예: n번째 피보나치 -> n-1, n-2의 결과로 결정됨같은 작은 문제가 계속 반복됨예 : f(3)은 여러 경로에서 계속 호출
36.자바스크립트로 보는 다익스트라
현재까지 가장 가까운 정점을 하나씩 확정해가며 시작점에서 모든 정점까지의 최단 거리를 구하는 알고리즘그래프에서 한 출발점 → 모든 정점까지 최단 거리를 구해야 할 때가중치가 음수가 아니고 가중치가 서로 다를 때가중치가 음수가 아니어야 하는 이유다익스트라는 가장 가까운