
- 전체보기(30)
- 휴학(10)
- kusitms(9)
- 서비스기획(8)
- 데이터분석(7)
- IT학회(6)
- 서비스(6)
- 대외학회(6)
- IT(6)
- PM(6)
- 추천시스템(5)
- 밋업프로젝트(4)
- MSDataSchool(4)
- AI(4)
- 큐시즘(4)
- 머신러닝(4)
- Microsoft(4)
- PO(4)
- 자기계발(4)
- 대외활동(4)
- 밋업(4)
- 부트캠프(4)
- data(3)
- collaborativefiltering(2)
- Bias Model(2)
- 큐시즘학술(2)
- 데이터사이언스(2)
- 기획(2)
- 사이드프로젝트(2)
- 회고(2)
- 협업필터링(2)
- 유사도(2)
- 알고리즘(2)
- 개발일지(2)
- 모각작(2)
- Collaborative Filtering(1)
- similarity(1)
- 행렬분해(1)
- python(1)
- MachineLearning(1)
- 서비스 기획(1)
- UIUX(1)
- 과적합방지(1)
- LatentFactorModel(1)
- Bias(1)
- @Temporal(1)
- 벨로그(1)
- 추천알고리즘(1)
- SVD(1)
- CS(1)
- datascience(1)
- RatingPrediction(1)
- 잠재요인모델(1)
- cloud(1)
- Recommender System(1)
- 생산성(1)
- Content based Filtering(1)
- 유아이볼(1)
- JVM(1)
- 코사인유사도(1)
- TemporalDynamics(1)
- 지원(1)
- 인공지능(1)
- 컴파일(1)
- RcSy(1)
- 공모전 수상(1)
- 디어셈블,(1)
- Personalizati(1)
- CloudComputing(1)
- aws(1)
- Java(1)
- 자바(1)
- movielens(1)
- 디컴파일(1)
- 프로그래밍기초(1)
- latentfactor(1)
- 정규화(1)
- 자바동작원리(1)
- jdk(1)
- RecommendationSystem(1)
- IoT(1)
- OT(1)
- algorithm(1)
- RecommenderSystem(1)
- ALS(1)
- 리텐션(1)
- 몰입(1)
- XAI(1)
- MatrixFactorization(1)
- 런칭(1)
- L2Regularization(1)
- 피어슨상관계수(1)
- 대학생(1)
- 컴퓨터공학(1)
- uibowl(1)
- TIL(1)
- PM회고(1)
- ALS알고리즘(1)
- 지원동기(1)
- 개인화추천(1)
- Azure(1)
- GA4(1)
- 개인화(1)
- Regularization(1)
- 모각코(1)
- 공모전(1)
- velog(1)

[추천 시스템] User-free Model
Memory-bsed (Similarity based)가중 평균 구해서상호이력을 직접 활용Model based다 기억하는 게 아니라이력을 저차원 표현으로 압축해서, 압축된 걸 활용해서 예측하는 것Item Matrix와 User Matrix로 표현을 압축한 다음에, 벡터
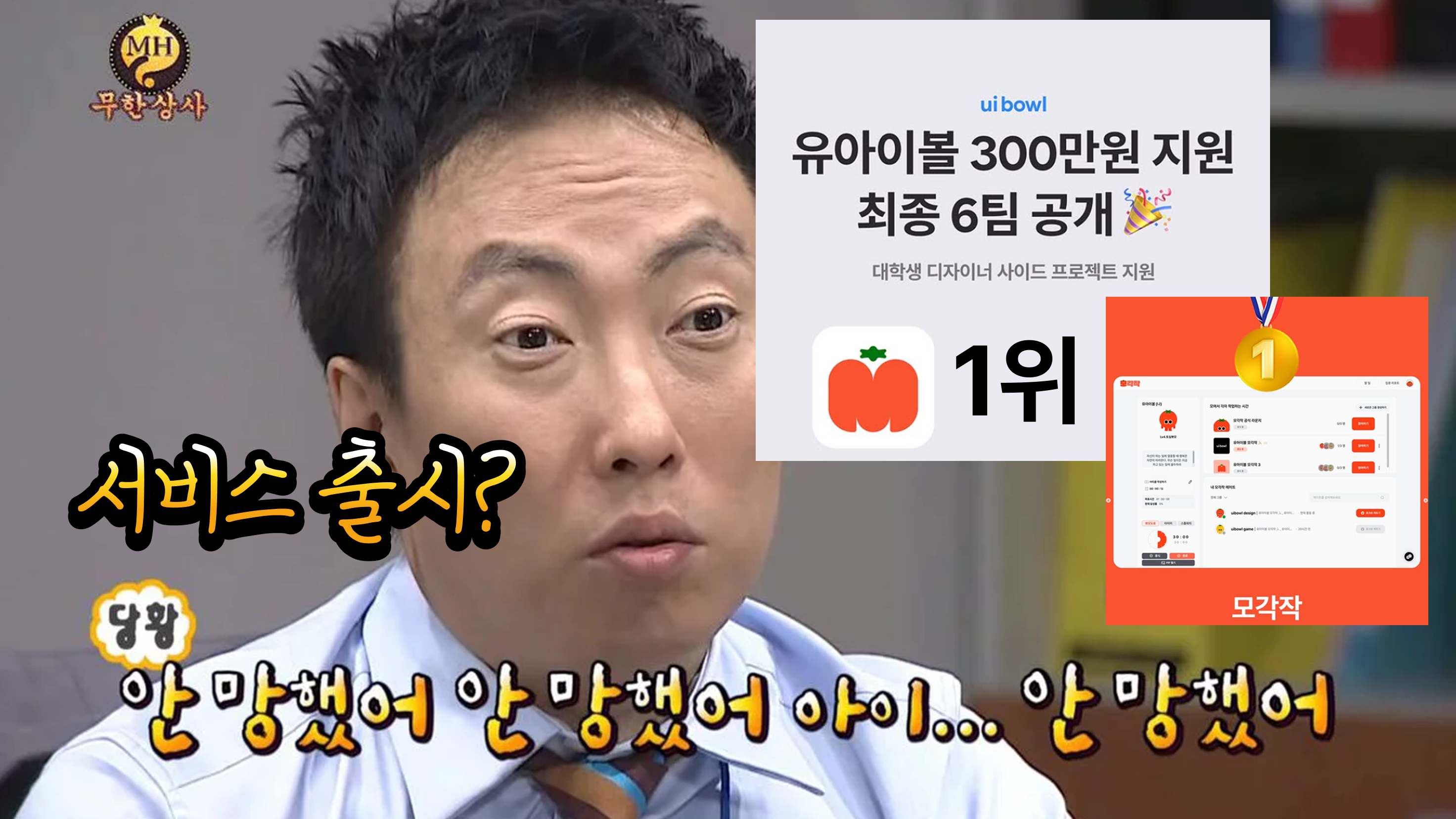
🏠 출시부터가 진짜다.. 이탈률과의 싸움부터 uibowl 공모전 1위 수상까지
혼자 공부하는 게 집중이 안 된다면? 사이드 프로젝트로 시작한 서비스 "모각작".. 출시 후 3달 동안 이탈률과의 싸움부터 uibowl 공모전 1위 수상까지

[추천 시스템] 시간 정보를 반영한 Temporal Bias & Latent Factor 모델
안녕하세요! 오늘은 추천 시스템에서 '시간'이라는 요소가 별점 예측에 어떤 영향을 미치는지, 그리고 이를 지난 "별점 예측(Rating Prediction) 모델"을 이해한 것에서, 어떻게 반영할 수 있을지 정리해 보려 합니다. 1. 별점에 미치는 ‘시간’의 영향

[추천 시스템] 별점 예측(Rating Prediction) 모델 이해하기
추천시스템에서 별점을 예측하는 방법은 크게 두 가지로 나뉩니다. 유사도 기반 CF부터 모델 기반 CF(MF)까지!

[추천 시스템] MovieLens-32M 데이터를 활용한 유사 영화 추천기 구현 (Jaccard, Cosine, Pearson)
안녕하세요! 오늘은 추천 시스템의 기초이면서 가장 강력한 방법 중 하나인 유사도 기반 추천(Similarity-based Recommendation)을 구현해 보겠습니다. MovieLens-32M 대용량 데이터셋을 활용하여 태그, 사용자 시청 기록, 별점 패턴에 따라

1-1. 자바의 시작과 개요
1.컴퓨터 프로그래밍 언어의 이해 2. 자바의 핵심, 플랫폼 독립성 3. JVM(Java Virtual Machine)

🏠 혼자 작업하면 딴짓하는 나를 위해 직접 만들었습니다: '모각작' 런칭 기록
집중이 잘 안 될 때, 혼자 작업할 때의 막막함을 덜어주는 온라인 몰입 도구 '모각작'이 정식 런칭되었습니다. 카메라 공유나 랭킹의 부담 없이도 함께 작업하는 감각을 유지하기 위해 어떤 고민을 했는지에 대한 기록을 담았습니다.

[추천시스템] 유사도 측정 알고리즘 3종 세트 (Jaccard, Cosine, Pearson)
이번 수업에서는 추천할 때 어떤 아이템들이 서로 유사한지를 계산하는 방법론들을 배웠다. 그 중 지난 시간에 모델을 분류 및 정리했었는데, 그중에서 모델의 학습 유무에 따른 분류를 했을 때, 학습된 인공지능이 추천하는 (model-based Approach)가 아니고,

[추천시스템] Recommender System 개요
추천시스템을 처음 접했던 건 고3..빅데이터나 AI가 지금만큼은 아니지만 막 화두되고 있던 시기이쪽으로 입시를 하기로 맘먹고, 관련 도서를 뒤적거리다가원래 광고나 마케팅에도 관심이 있어서 자연스럽게 추천시스템이 끌렸다. 한창 넷플릭스의 추천 알고리즘이 떠올랐을 때라 넷

[한국대학생IT경영학회 큐시즘] 31기 지원 과정 (지원서와 면접 꿀팁)
지난번 글에서는 왜 Why 큐시즘에 지원했는지를 이야기했다면, 이번에는 어떻게 How 지원했는지, 즉 지원서 작성 과정과 면접 후기를 공유하려고 한다. 예비 큐밀리들에게 큰 도움이 됐으면 하는 마음으로...👉 지난번 글 보러 가기https://velog.i

[한국대학생IT경영학회 큐시즘] 31기 지원 이야기 (큐시즘이란? 운영진과 일반 학회원 차이?)
너무 길어져서, 내 지원서 내용은 다른 패이지에서 더 자세히 다루겠음2025년은 내 첫 휴학 도전기다! 나는 휴학에 꽤 많은 의미를 뒀다..! 장장 3살 때 어린이집을 다닌 이후 대학교까지, 늘 학교라는 일반적인 흐름 속에서 살아오다가, 처음으로 내가 선택해서 내 시간

[모각작, 모여서 각자 작업하는 시간] 8~9주차 - 전시회와 데모데이, 가설을 증명하고 마침표를 찍다
Intro, 여정을 마무리하며 8주차, 전시회 회고 : 가설을 증명하다 번외, 마케팅 전략 : '참여하는' 콘텐츠 9주차, 데모데이 회고 : 경쟁과 고립 사이, '지속 가능한 몰입'을 제안하다 Outro, 비하인드 > 🖐️글을 읽기 전에 잠깐. 모각작(Mogakj

[모각작, 모여서 각자 작업하는 시간] 3~7주차 - UT 및 인터뷰에서 발견한 인사이트, 그리고 최종 QA까지
앞선 1~2주차를 통해 어느정도 서비스의 틀을 만들었다면, 3~7주차는 그 안을 견고하게 채우는 시간이었다! 사실상 8주차는 서비스 전시, 9주차는 서비스 발표여서 7주차까지 개발을 거의 완료해야 했다. 7주라는 짧은 시간 동안 막연하던 아이디어가 웹 서비스로 따-란
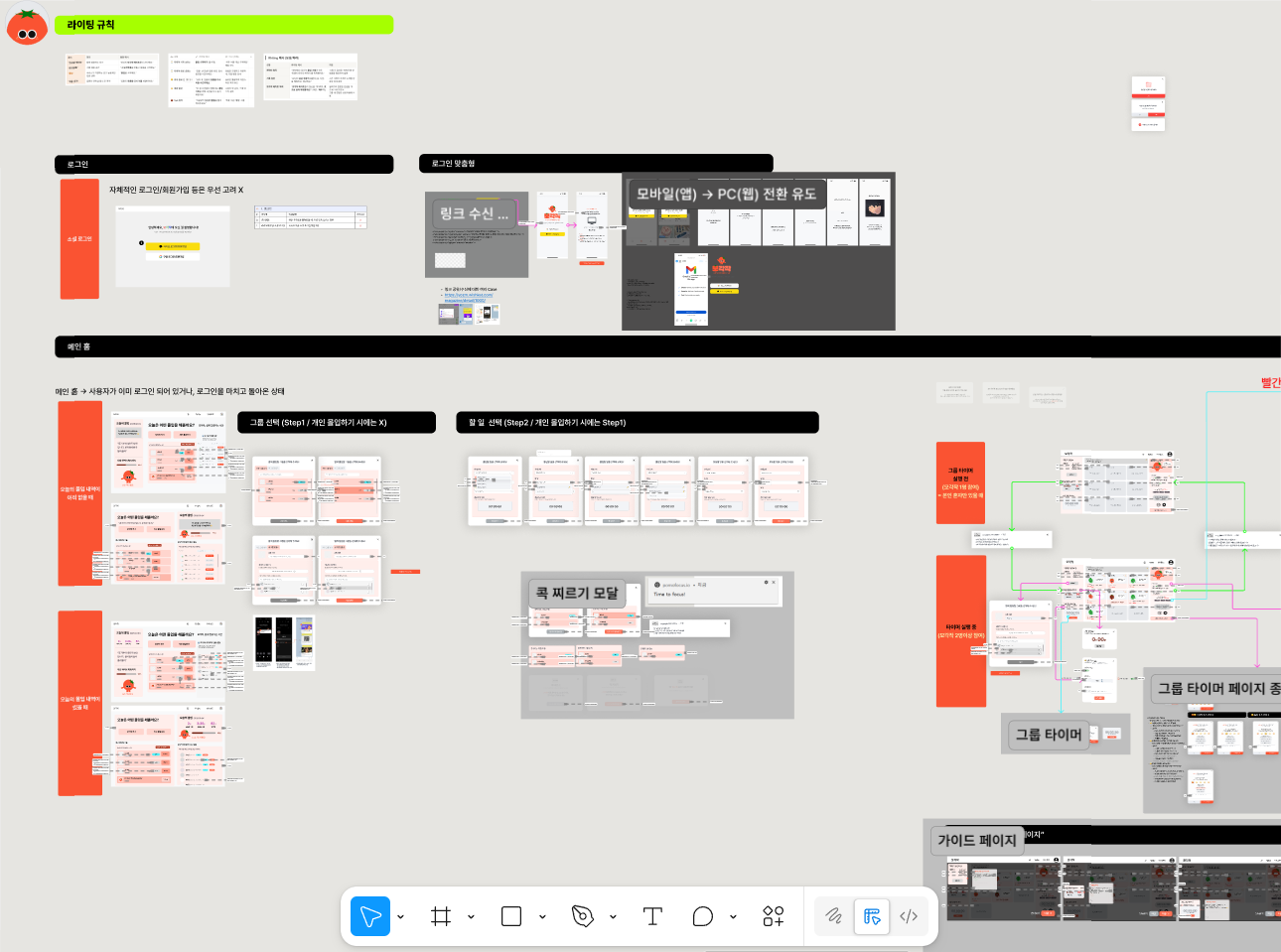
[모각작, 모여서 각자 작업하는 시간] 1~2주차 - 협업방식 및 MVP 설정
0️⃣ 프롤로그: 두 번째 밋업, 그리고 새로운 도전 1️⃣ 1주차 : 협업 방식 및 MVP 구체화 2️⃣ 2주차 : 와프 작성 및 상세 기능 지난 글에서 'Sparkup' 발제 및 팀빌딩 과정을 다뤘다면, 이번에는 본격적인 프로젝트 진행 과정을 이야기해 보려 한다

[모각작, 모여서 각자 작업하는 시간] 아이디어 발제 과정 - "어떻게 집중시키지?" (화면 블러에서 타이머까지)
지금부터는 본격적으로 '모각작' 프로젝트의 기획 과정을 소개해 보려고 한다! > ** Intro, '모각작'은 어떻게 시작되었나? (밋업 프로젝트의 시작) WARM-UP, 문제 정의와 데이터 기반의 아이디어 도출 CHECK-UP, 현실의 벽과 Pivot 스토리 SPA

DP900 공부 (1) - 데이터 기본
정형 데이터대부분 표 형식 스키마반정형 데이터일반적 형식 : Json (서로 다른 정보를 유용하게 담기에 좋음)비정형 데이터NLP, ML등 사용관계형 데이터베이스(RDB)앤터티를 참조할 수 있음따라서, 정규화될 수 있음. (중복된 데이터 제거)비관계형 데이터베이스(No
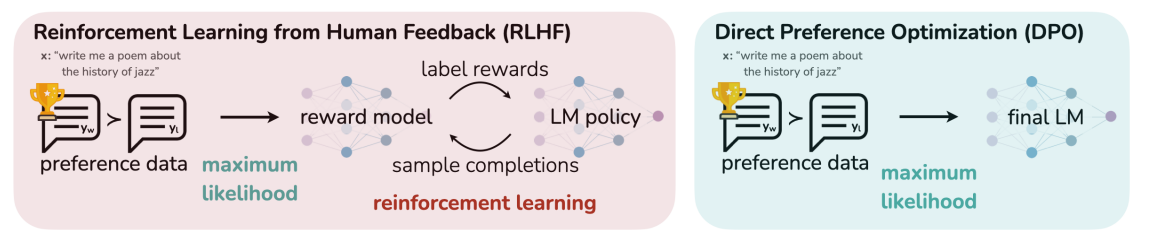
DPO : A Differential and Pointwise Control Approach to Reinforcement Learning
2023.05https://arxiv.org/abs/2305.18290RM와 RL 없이 LLM policy model만을 학습하여, 사람의 선호도를 반영한 문장을 생성하도록 LLM을 직접적으로 최적화 하는 알고리즘본 논문은 대규모 언어 모델(LM)의 동작을 제

에겐/테토 챗봇 만들기 (feat. SFT, QLoRA, DPO)
교내 학회에서 방학동안 논문 리뷰와 함께, 간단한 toy project를 한다. 주제를 고민하던 중, 벨로그 상단에 있던 에겐/테토 개발자 유형 테스트를 만드신 내용을 보고 영감 받았다. https://velog.io/@wkddudgk4869/출시-하루만에-트래픽-16

[한국대학생IT경영학회 큐시즘] 31기의 첫 시작..OT..!
큐시즘 후기를 벨로그에도 남기면 좋을 것 같아, 블로그 내용을 이동시켰다\~~블로그 내용https://blog.naver.com/sbyeori큐시즘에 합격 통보가 1월 20일쯤에 나왔던 것 같다그 이후로, LT, 리쿠르팅, 경총 회식 등등을 거치고 드디어 첫
LLaMA 논문 리뷰
https://arxiv.org/abs/2302.13971LLaMA는 비교적 가벼운 모델, 오픈 소스 데이터만 사용한 모델LLaMA-13B는 대부분의 벤치마크에서 GPT-3(175B)보다 뛰어난 성능LLaMA-65B는 Chinchilla-70B 및 PaLM-5