
[네트워크] 응용 계층 - HTTP 응용
HTTP의 stateless한 특성을 보완하기 위한 수단서버에서 생성되어 클라이언트 측에 저장되는 <이름, 값> 형태의 데이터이외에도 만료기간 같은 추가적인 속성값도 가질 수 있음클라이언트는 서버로부터 받은 쿠키를 주로 브라우저에 저장추후 같은 서버에 요청을 보낼
[네트워크] 응용 계층 - HTTP의 기초
호스트의 IP 주소는 언제든지 바뀔 수 있음 -> "도메인 네임" 사용의 이유도메인 네임과 그에 대응하는 IP 주소는 "네임 서버"에서 관리네임서버 == DNS 서버호스트는 네임 서버에 "특정한 도메인 네임을 가진 호스트의 IP 주소"를 질의함으로써 패킷을 주고받고자
[DB] RDBMS의 기본
테이블 내의 특정 레코드를 식별할 수 있는 필드의 집합은 "키"라고 함레코드의 식별뿐만 아니라 테이블 간의 참조에도 사용테이블의 레코드를 식별할 수 있는 하나 이상의 필드를 "키"라고 함테이블의 접근 속도를 높이기 위해서도 사용됨후보키테이블의 한 레코드를 식별하기 위한
[DB] DB의 큰 그림
DB : 원하는 기능을 동작시키기 위해 마땅히 저장해야 하는 정보의 집합DBMS : DB 관리 시스템DBMS는 사용자와 직접 상호작용하기보다는 사용자(개발자)가 만든 프로그램과 상호작용응용 프로그램들 입장에서 DBMS는 마치 서버와 같음쿼리 : 사용자와 응용 프로그램이
[네트워크] 전송 계층 - TCP와 UDP
TCP와 UDP의 목적과 특징 포트를 통한 프로세스 식별 패킷의 최종 송수신 대상은 호스트가 아니라, 호스트가 실행하는 프로세스 호스트가 실행하는 프로세스 식별 : 포트 PORT 번호를 통해 식별 네트워크 패킷을 주고 받는 프로세스에는 포트 번호가 할당됨 IP주소와 포
[네트워크] 네트워크 계층 - IP
네트워크 계층 물리 계층, 데이터 링크 계층 이후의 네트워크 계층 LAN을 넘어서 다른 네트워크와 통신을 주고 받기 위한 기술 네트워크 계층의 핵심 프로토콜 IP IP의 목적과 특징 IP의 목적 주소 지정 단편화 IP의 특징 신뢰할 수 없는 통신 비연결
Javascript와 Python의 filter 함수
Javascript 공부를 하면서 filter 함수를 사용해 to-do-list를 구현했다.Python에서 사용했던 filter 함수와 왜 다른 형태일까?JS에선 filter가 배열의 메서드로 구현. 즉, 배열 객체에 직접 붙어서 동작map, reduce와 같은 함수도
[네트워크] 네트워크 계층
LAN을 넘어서는 네트워크 계층 네트워크 계층에서는 IP 주소를 이용해 송수신지 대상을 지정하고, 다른 네트워크에 이르는 경로를 결정하는 라우팅을 통해 다른 네트워크와 통신 데이터 링크 계층의 한계 물리 계층과 데이터 링크 계층만으로는 LAN을 넘어서 통신하기 어려움
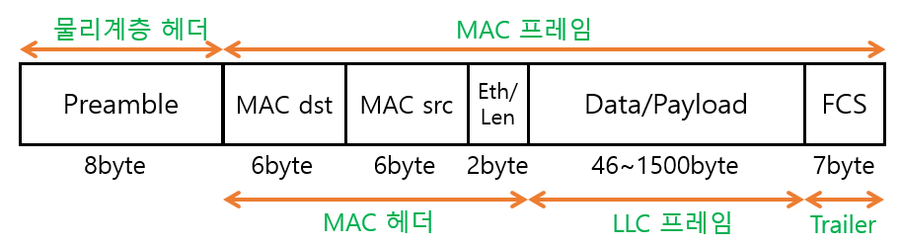
[네트워크] 물리 계층과 데이터 링크 계층
이더넷은 다양한 통신 매체의 규격들과 송수신되는 프레임의 형태, 프레임을 주고받는 방법 등이 정의된 네트워크 기술물리 계층과 데이터 링크 계층은 서로 밀접하게 연관되어 있음. 왜냐? 두 계층은 '이더넷'이라는 공통된 기술을 사용하기 때문오늘날의 유선 LAN 환경은 대부

[네트워크] 컴퓨터 네트워크 시작하기
부트캠프 마지막 프로젝트로 웹소켓 프로토콜을 이용해 실시간 메세징 기능을 구현했다. 강의를 통해 기능 구현은 완성했지만 프로토콜, 더 나아가 네트워크에 대한 지식이 부족함을 느꼈다. "혼자 공부하는 네트워크"라는 책을 공부하고 정리하면서 네트워크에 대한 이해도를 높이고

[이코테] 이진탐색
순차탐색 순차탐색Seqiential Search란 리스트 안에 있는 특정한 데이터를 찾기 위해 앞에서부터 데이터를 하나씩 차례대로 확인하는 방법 순차탐색은 데이터 정렬 여부와 상관없이 하나씩 확인해야 하므로, 데이터의 개수가 N개일 때, 최악의 시간복잡도는 $O(N)
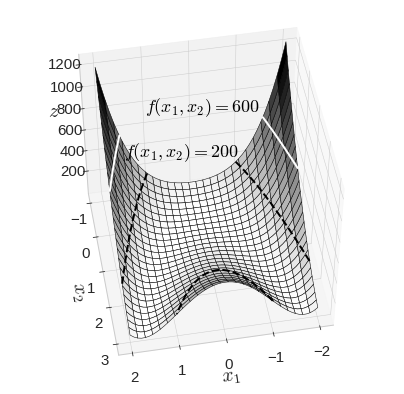
[기초수학] 3장. 다변수함수와 벡터함수 : 입력과 출력이 여러 개..
책의 내용을 정리하다보니, 쉽게 설명한 부분에서 정확하지 않은 부분이 있을 수 있습니다.스칼라 : 크기만을 가지는 값, 숫자 하나로 표현되는 값 ex)재산, 온도의 크기벡터 : 크기와 방향을 모두 가지는 값, 숫자 여러 개인 값, 벡터는 기본적으로 열벡터 ex) 속도
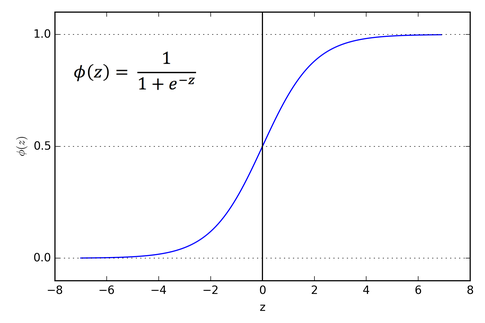
[기초수학] 2장. 함수 : 세상의 모든 것을 입력과 출력으로 바라보기
자연수 : 자연수란 사물을 셀 때나 순서를 매길 때 사용하는 수정수 : 자연수에 0과 음수를 더한 것유리수 : 유리수는 분자, 분모로 정수를 갖는 분수로 나타낼 수 있는 수무리수 : ratio가 없는 수, 즉 비율로 표현되지 않는 수를 의미 ex) $\\pi$실수 :
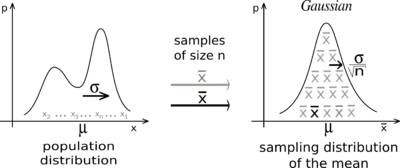
[이렇게 쉬운 통계학] 5장 표본을 이용하여 모집단의 특징 추정하기
추측통계학을 이루는 두 기둥 "추정"과 "가설검정"무엇을 추정하냐? 모집단의 평균, 분산, 비율(시청률과 비슷함)추정의 순서는 "모집단의 평균을 추정하는 방법"만 알면 모두 비슷함정규분포, $t$분포, $\\chi^2$분포 사용함.중심극한정리 : 모집단의 평균을 추정하
[ML] 적절한 스케일링 방법
우선, 표준화와 정규화를 통칭하여 '스케일링'이라고 표현함데이터 컬럼별로 분포를 뽑아서 분포에 맞는 스케일링을 적용하려고 하는데 어떤 분포에 어떤 스케일링이 효과적일까?일반적으로 스케일링은 개별 feature내에서 데이터들이 skew되었거나, 서로 다른 feature들

[이렇게 쉬운 통계학] 4장 정규분포 체감하기
정규분포의 첫걸음은 히스토그램 만들기대략적인 순서는 1\. 데이터 : 공공기관 데이터, 회사 등의 매출 데이터 2\. 도수분포표 : 원시 데이터를 이용하여 최댓값,최솟값(범위) / 그래프 폭(계급)과 빈도 등을 통해 도수분포표 완성 3\. 히스토그램 : 도수분포표
[이코테] 정렬
정렬 알고리즘 개요 정렬Sorting이란 데이터를 특정한 기준에 따라서 순서대로 나열하는 것 선택정렬 가장 작은 데이터를 선택해 맨 앞에 있는 데이터와 바꾸고, 그 다음 작은 데이터를 선택해 앞에서 두 번째 데이터와 바꾸는 과정을 반복 매번 가장 작은 데이터를 선택한
[기초수학] 1장. 머신러닝과 선형회귀
머신러닝이란? 작업&평가를 반복하면서 결과를 개선하는 것 위와 같은 두 2차원 어레이 2개가 있다고 한다면 좌표평면 상에 다음과 같이 나타낼 수 있음 좌표평면 상의 점들과 가장 '친한' 선을 그리고자 한다면, 누군가는 여러번의 시도를 통해 그릴 수 있고 매우
[이렇게 쉬운 통계학] 3장 평균과 분산 이해하기
모든 데이터를 나열하여 데이터의 특징을 파악할 수 없음따라서, 데이터 전체의 특징을 단 하나의 데이터로 나타낼 수 있음. 이를 '대푯값'이라고 함대푯값에는 '평균', '중앙값', '최빈값'이 있음평균의 아킬레스건 '특잇값Outlier'평균은 데이터 전체의 중심에 위치하