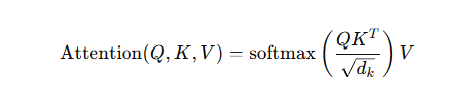- 전체보기(109)
- question(14)
- AI(5)
- 이산수학(4)
- huggingface(3)
- linux(3)
- paper-review(2)
- 모방학습(2)
- simulation(2)
- koch1.1(1)
- 시사(1)
- MoveIt2(1)
- robot(1)
- 독후감(1)
- 용어 정의(1)
- 3D Printing(1)
- chatGPT(1)
- korch1.1(1)
- smolVLM(1)
- English(1)
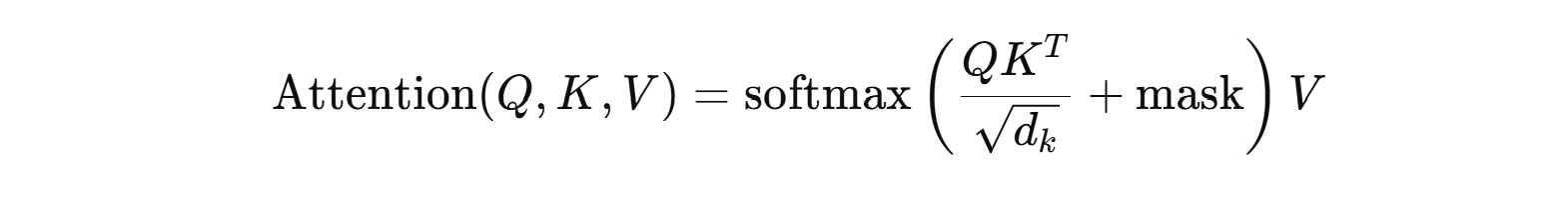
Hugging Face의 attn_implementation("eager", "sdpa", "flash_attention_2", "flash_attention_3")
이 4개는 attention의 수학 자체가 완전히 다른 것이라기보다, 같은 scaled dot-product attention을 어떤 구현체/backend로 계산하느냐의 차이에 가깝습니다. Hugging Face는 attn_implementation으로 "eager",
smolVLM Model Architecture
from transformers import AutoProcessor, AutoModelForImageTextToText import torch model_path = "HuggingFaceTB/SmolVLM2-256M-Video-Instruct" processor
Huggingface Doc
좋아. 아래처럼 카테고리 / 키워드 / 간단 설명 형태로 표로 정리해줄게.원하면 내가 다음 단계로1) 이 키워드들을 “초보자 기준”으로 다시 분류해주거나,2) 너한테 특히 중요한 것들(예: Transformers, Datasets, PEFT, Accelerate, Le
attn_implementation= sdpa vs flash_attention_2
쉽게 말하면,sdpa = PyTorch가 제공하는 공식 어텐션 API/백엔드 경로flash_attention_2 = Dao-AILab의 외부 FlashAttention-2 커스텀 구현을 직접 쓰는 방식입니다. Transformers 문서도 attn_implementat
__all__ = ["SiglipProcessor"]
“이 파일에서 밖으로 공식적으로 공개할 대상은 SiglipProcessor다.”\*\*라는 의미특히 이런 코드에서 영향이 있어:이때 \_\_all\_\_이 있으면그 목록에 들어 있는 이름들만 import 돼.예를 들면:이면했을 때 SiglipProcessor만 들어오는
__call__ vs __init__
https://huggingface.co/docs/transformers/v5.3.0/en/model_doc/siglip\_\_init\_\_ : 객체가 만들어질 때 처음 한 번 실행되는 초기화 함수\_\_call\_\_ : 이미 만들어진 객체를 함수처럼 호출

Position Controller vs Velocity Controller
정해진 자세/각도로 정확히 가서 멈추기: Position control조이스틱/키보드로 부드럽게 움직이기, 베이스 주행(모바일 로봇), 연속 추종: Velocity control접촉/힘 제어(삽입, 연마, 잡기): 보통 토크/임피던스(힘-위치 혼합) 쪽으로 확장
What dose "grounding"mean??
접지(grounding)란 인공 지능 시스템이 추상적 개념(일반적으로 자연어에서 파생됨)을 시각 데이터나 감각 입력과 같은 물리적 세계의 구체적 표현과 연결하는 능력을 의미한다.컴퓨터 비전 분야에서 이는 모델이 단순히 텍스트를 처리하는 것이 아니라 "개를 산책시키는 사
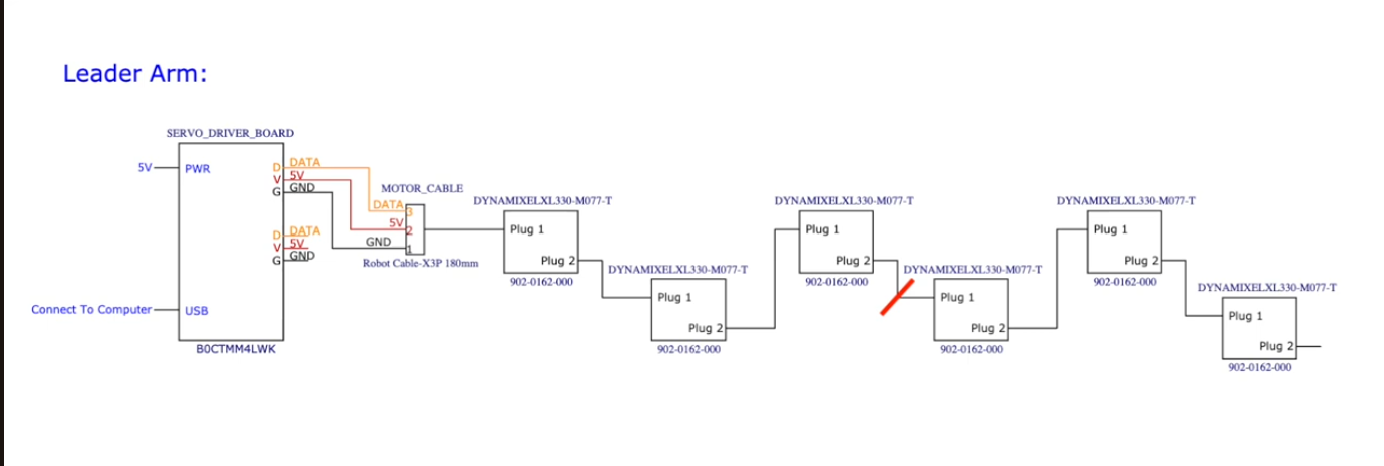
koch1.1 connect (2)
'''sudo chmod 666 /dev/ttyACM0sudo chmod 666 /dev/ttyACM1'''아두이노 서보 드라이버 보드 USB-시리얼 장치 마이크로컨트롤러(예: STM32, ESP 계열 일부) 로봇 컨트롤러를 USB로 연결했을 때 생기는 시리얼 통신 포
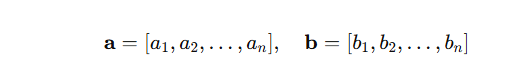
코사인 유사도 (Cosine Similarity)
해당 내용을 적게된 이유 : 몇몇 인공지능 모델을 이용해서 해당 데이터를 임베딩 벡터로 만드는데 해당 임베딩 백터간의 유사도를 계산하는 것에 대한 의문점이 생김. dot prodoct vector norm 
반복 정밀도 & 도달 범위
뜻: 같은 목표 위치로 여러 번 이동했을 때, 그 위치에 “얼마나 비슷하게” 다시 도착하느냐쉽게 말해: “매번 찍는 점이 얼마나 한곳에 모이냐”보통 표기: ±0.02 mm 같은 형태중요한 포인트:“절대적으로 정확한 위치”가 아니라 ‘재현성’이 핵심예: 목표점이 실제로는
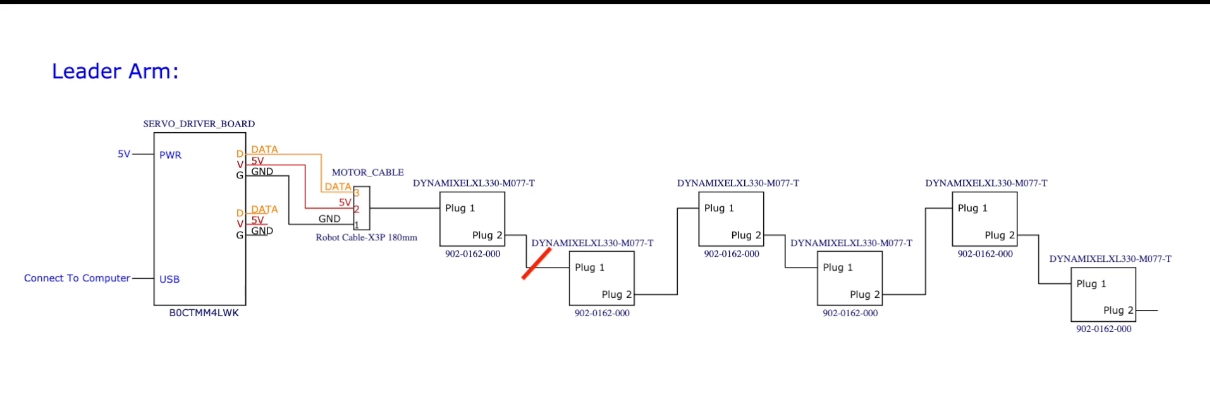
koch1.1 connect (1)
https://github.com/jess-moss/koch-v1-1?tab=readme-ov-filehttps://www.youtube.com/watch?v=U78QQ9wCdpY&list=PLo2EIpI_JMQu5zrDHe4NchRyumF2ynaUN
if you can't connect wifi
sudo apt updatesudo apt install --reinstall linux-firmwaresudo update-initramfs -usudo reboot
tmux 사용법
좋아. tmux + conda + 서버 접속 흐름을 “처음부터 끝까지” 한 번에 정리해줄게. (GPU 서버에서 학습 돌리는 상황 기준)tmux: SSH 끊겨도 작업(학습/스크립트) 계속 돌게 “터미널 세션”을 서버에 붙여두는 도구conda env: 파이썬/라이브러리 버

Transfomer 모델 구조
작성이유 : Transfomer 논문을 이해하는 과정에서 x N 이라고 있는데 이 부분에서 레이어가 인인코더와 디코더 레이어가 어떻게 훈련되어가는지 모르겠음https://github.com/hyunwoongko/transformer/tree/master
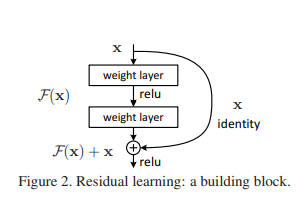
Residual Neural Network, ResNet
작성 이유 : transfomer 모델을 설명해주기 위해서 작성하는 과정에서 attention 부분이 3가지정도 있었는데 encoder - decoder attention / multi-head-self-attention /masked multi-head-attenti

Activation function
작성한 이유 : 잔차 학습 방법을 공부하면서 그레디언트 소실 문제를 막는 효과가 있다고 하는데 그전에는 시그모이드 함수의 역시도 미분하면 최댓값이 0.25이고 0도 나와서 결국 Gradiant vinishing problem이 발생해서 그것을 보완하는 것이 RELU인데