
- 전체보기(35)
- 네이버커넥트_부스트캠프 AI Tech 3기(9)
- Ustage(8)
- web(6)
- 스파르타코딩클럽_웹개발 종합반 62기(6)
- 김기현의 자연어 처리 딥러닝 캠프(4)
- 선택 선호도(3)
- 코테(3)
- 프로그래머스(3)
- transformer(3)
- 기계번역(2)
- Encoder/Decoder/Generator(2)
- Seq2Seq(2)
- 멀티 헤드 어텐션(2)
- NLI(2)
- bootstrap(2)
- 중의성 해소(2)
- Attention(2)
- JavaScript(2)
- htmlcss(2)
- LSTM(1)
- klue(1)
- pororo 설치(1)
- 셀프 어텐션(1)
- attention is all you need(1)
- 의존 구조 분석(1)
- 빈번도(1)
- mongodb(1)
- 텍스트 벡터화(Text Vectorization)(1)
- Level 2(1)
- Attention Attention Is All You Need(1)
- Pseudo-Words(1)
- 전처리(Preprocessing)(1)
- 토크나이저(1)
- jquery(1)
- pororo conda(1)
- TeacherForcing(1)
- 선택 연관도(1)
- Position Embedding(1)
- mysql(1)
- 래스크 알고리즘(1)
- GRU(1)
- 그래디언트 클리핑(1)
- positional encoding(1)
- KoBART(1)
- 논문 리뷰(1)
- 품사 태깅(1)
- Flask(1)
- RNN(1)
- Level 3(1)
- pymongo(1)
- install pororo(1)
- memo(1)
- Masking(1)
- 시각화(1)
- Selectional Preference(1)
- Transformer Encoder(1)
- POST/GET(1)
- Lv.2(1)
- ViT(1)
- optimization(1)
- Patch Embedding(1)
- pororo(1)
- MLP Head(1)
- beautifulsoup(1)
- ajax(1)
- 유사 어휘(1)
pororo 설치 및 ImportError: cannot import name 'Pororo’ 에러 해결
카카오브레인 pororo, conda 가상환경에 설치하는 방법 pip install pororo를 했더니 ImportError: cannot import name 'Pororo’ 에러가 떴다. pororo git을 clone하여 직접 conda install -e
선택 선호도(Selectional Preference) 개념의 첫 논문(1997) 리뷰 읽어보기 (2022/03/15)
📝 회고 어제 읽은 [Improving the Use of Pseudo-Words for Evaluating Selectional Preferences(2010)] 논문은, 선택 선호도(Selectional Preference) 매커니즘의 evaluation 단계의
유사어휘를 활용하여 선택 선호도를 잘 평가하는 방법을 제안한 논문 리뷰 (2022/03/14)
논문: https://aclanthology.org/P10-1046.pdf노션 글: https://utopian-glove-b74.notion.site/Improving-the-Use-of-Pseudo-Words-for-Evaluating-Select
[김기현의 자연어 처리 딥러닝 캠프] 5장. 유사성과 모호성 (개념) - (2) (2022/03/14)
가정: 문장 내에 같이 등장하는 단어들은 공통 토픽을 공유한다..!중의성을 갖는 각 단어에 대해 사전(ex. 워드넷 등)을 활용해 사전에서의 의미별 설명 사이의 유사도를 구하는(ex. 겹치는 단어의 개수를 카운팅 등) 알고리즘<장점> 워드넷과 같은 잘 분류된 사전
[김기현의 자연어 처리 딥러닝 캠프] 5장. 유사성과 모호성 (개념) - (1) (2022/03/10)
“Context” → 사람은 주변 정보(= Context)를 파악하여 각 단어에 숨겨진 의미를 파악하고 이해함용어 단어 중의성 해소(WSD) : 단어가 가지는 모호성을 제거하는 과정 ⇒ 효과: 자연어 처리의 성능 높임단어불연속적인 심볼로써 이산 확률 변수로 나타냄 →
[크롤링/전처리/증강] 리서치 및 기법/용어 이해 (2022/03/08)
(1) 데이터 크롤링/전처리/증강이 관건, 확보한 데이터셋 기반으로 모델 training 실험 계획 수립하자(2)용어 Counterfactually-augmented data (: 반사실적으로 보강된 데이터)용어 Spurious Correlations (: 허위 상관관
[김기현의 자연어 처리 딥러닝 캠프] 4장. 전처리 (2022/03/08)
1 코퍼스 수집 단계 : Selenium과 BeutifulSoup의 차이 ? (https://rubber-tree.tistory.com/88)2 정제(normalization) 단계 : re.sub(pattern, new_text, text)3 문장 단위 분절
[4주차 과제] 웹개발 종합반 학습&개발일지
✅ Flask 프레임워크를 활용해서 API를 만들기✅ API를 클라이언트에 연결하기✅ 실습에서 적용해보기templates 폴더는 주로 HTML 파일이 담기는 곳static 폴더는 주로 이미지, CSS 파일 등이 담기는 곳폴더 및 파일 준비mongoDB 준비필요한 라이브
읽어볼 만한 논문 List
🤍✨🤍✨🤍arXiv (Deep Mind)강화학습 (CV)https://arxiv.org/pdf/1312.5602.pdf?source=post_page---------------------------arXiv스타일 변환 (CV)https://arx
[NLI 대회] 사용 모델 & 접근 방향에 대한 고민
1. 현재 한국어 언어모델 SOTA 모델 조사 & 트렌드 파악 KcBERT 구어체/신조어 반영 KcBERT는 2019.01-2020.06의 텍스트로, 정제 후 약 9천만개 문장으로 학습을 진행 KcELECTRA (21년 4월) (https://github.com/Be
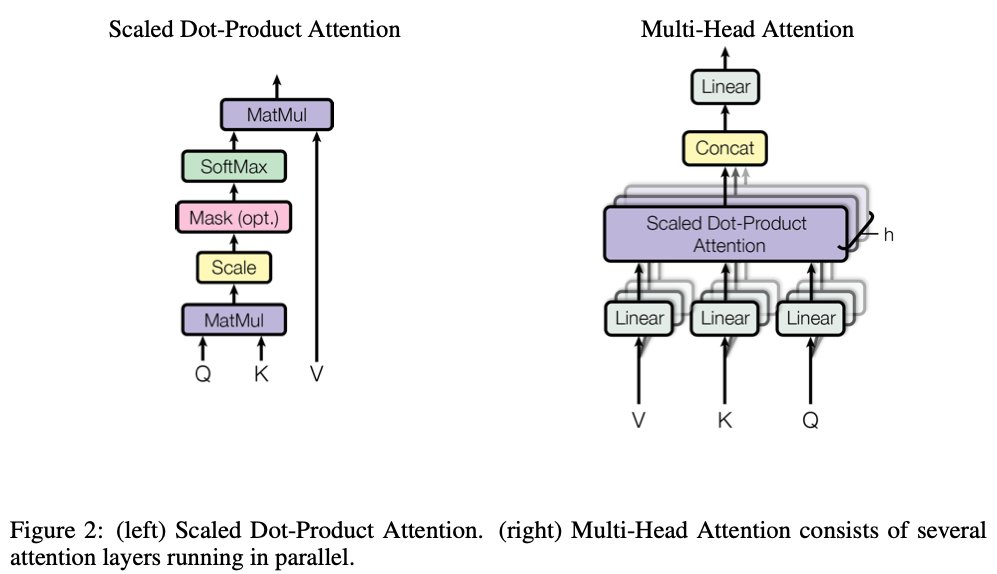
[DL Basic] Transformer - SDPA(Scaled Dop-Product Attention) & MHA(Multi-Head Attention) PyTorch 구현
1. 셀프 어텐션 (SDPA(Scaled Dop-Product Attention)) 수식의 구현 Flow [1] Query벡터와 transpose한 Key벡터의 내적 [2] Key벡터의 차원의 루트 값으로 나누어 주어 정규화
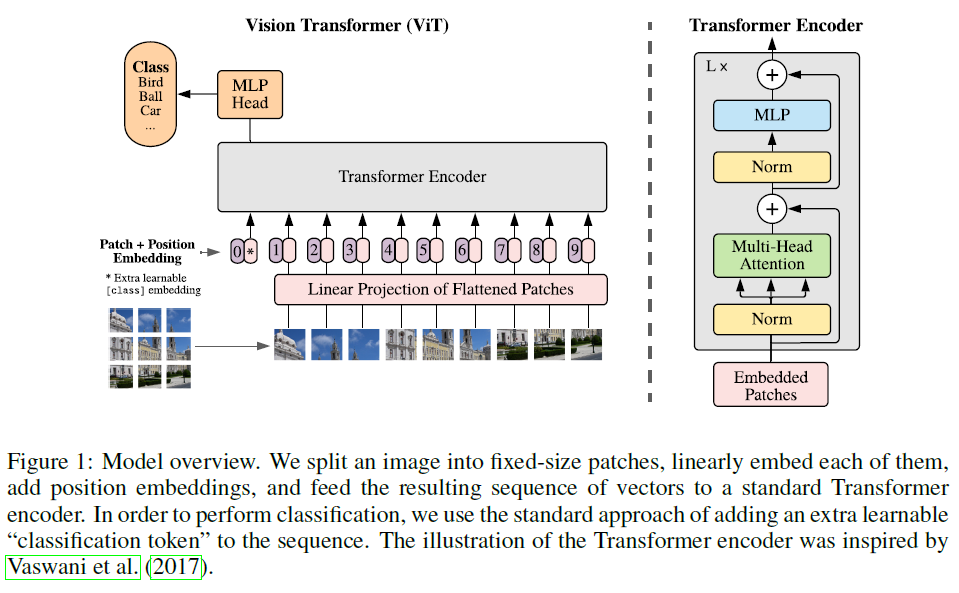
[기술 소개] Vision Transformer(ViT) - Transformer를 이미지에 적용한 연구
논문 리뷰 번역글 : https://velog.io/@changdaeoh/Vision-Transformer-ReviewPyTorch 구현 글 : https://hongl.tistory.com/235einops 라이브러리 (피어세션 공유)https&#
[NLP 트렌드 공부] 신경망 기계번역 (seq2seq, Attention, Teacher Forcing) (작성중)
1. NNMT (Neural Network Machine Translation) 2. seq2seq > 입력된 시퀀스로부터 다른 도메인의 시퀀스를 출력하는 다양한 분야에서 사용되는 모델입니다. 예를 들어 챗봇(Chatbot)과 기계 번역(Machine Translat
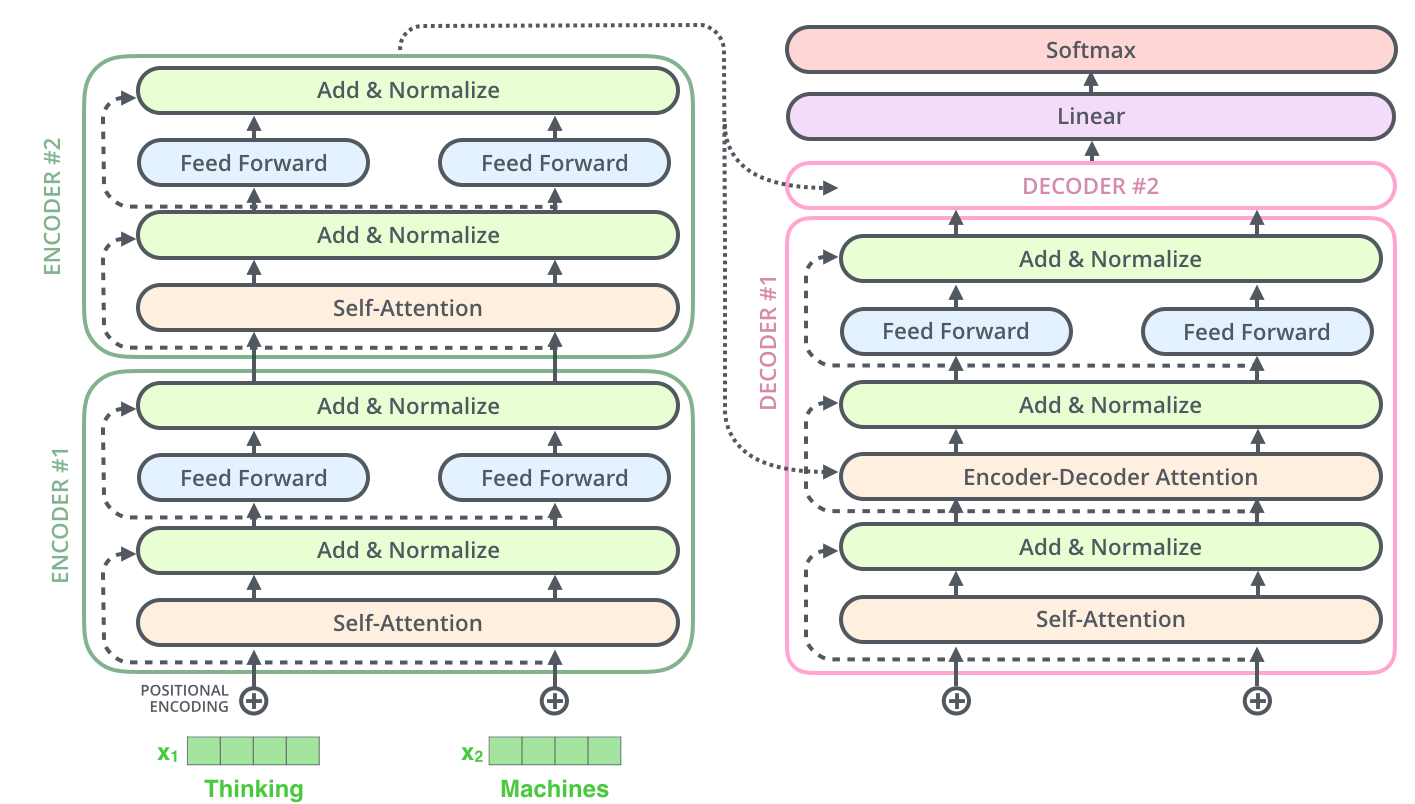
[DL Basic] Sequential Models - Transformer
시퀀셜 모델링을 어렵게 하는 문제들 Sequence는 뒤에가 잘리는 경우, 중간에 생략되는 경우, 어순이 바뀌는 경우 등이 존재 따라서 재귀적으로(recurrersive) 동작하는 RNN 계열의 경우에는, 이런 문제들을 반영해 학습하기가 어려웠음. Transform
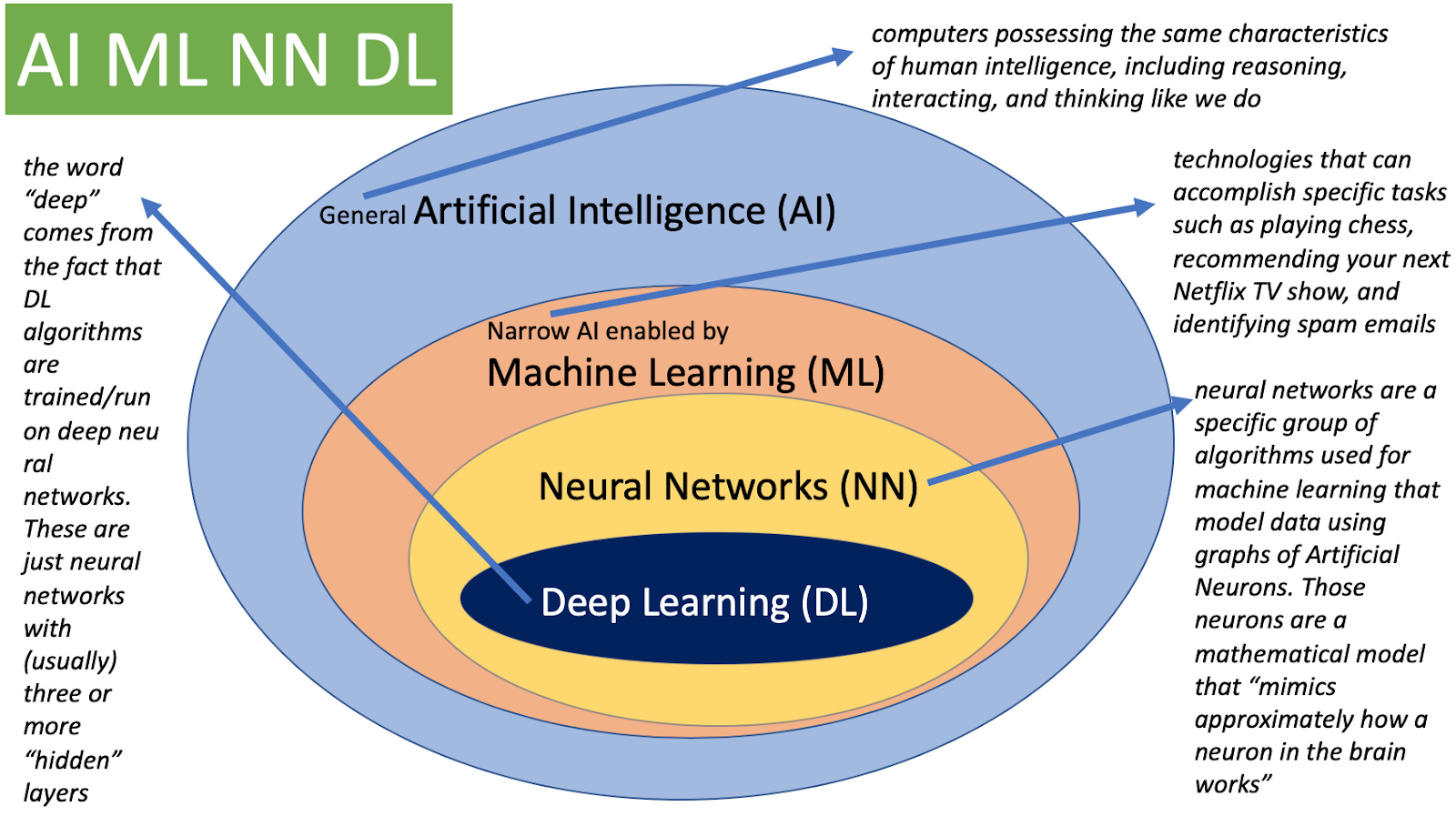
[DL Basic] 딥러닝 기본 및 최적화
Deep Learning 딥러닝의 구분 AI (인공지능) Mimic human intelligence, 사람의 지능을 모방 ML (기계학습) Data-driven approach, 데이터를 기반으로 무언가를 (기계)학습 DL (딥러닝) Neural Networks
[3주차] boostcamp 회고록 (Data viz)
피어 스터디 13. 서브워드 토크나이저(Subword Tokenizer) - 현재 통상적으로 많이 사용하고 있는 `Hugging Face`의 `WordPiece Tokenizer`(구글의 `BERT`모델)나 센텐스피스(`Sentencepiece`)(구글) 이
[손 풀기] 2월 3일 (프로그래머스 SQL Kit 복습) / 2.5 코테 응시
각 동물 col의 이름은 각각 총 몇 개인지 구하기 (이름의 개수 구하기) 중복은 제거하는 DISTINCT 사용 필수!! 조건에 해당하는 col 기준으로 group by col 하기 group by 와 having 은 세트
[2주차] boostcamp 회고록 (Pytorch)
📝 2주차 회고 PyTorch의 다양한 함수들을 직접 과제에서 nn.Module 클래스를 활용한 Custom Model 정의하고, torch.utils.data 라이브러리 및 DataLoader 함수를 활용한 Custom Dataset을 정의하며, 적용해보며 성장한
[복습/연습] 코딩테스트 고득점 Kit - 깊이/너비 우선 탐색(DFS/BFS) 시리즈 (Level 2 & Level 3)
✏️ 1. 타겟 넘버 (Level 2) ✏️ 2. 네트워크 (Level 3) ✏️ 3. 단어 변환 (Level 3) ✏️ 4. 여행 경로 (Level 3)