
BERT를 활용한 이진 분류 실습(전처리 및 모델 학습)
전체 학습 흐름 주의할 점: .py에서 진행 argparses는 .ipynb에서 실행이 안됨 깃허브에서 풀코드 확인 가능 0. 라이브러리 불러오기 1. 데이터 설명 및 전처리 Fake News Detection: 가짜뉴스탐지 데이터셋 활용 데이터셋 구성: t
RoBERTa: A Robustly Optimized BERT Pretraining Approach
논문 링크: https://arxiv.org/pdf/1907.11692Facebook AI Research 팀에서 발표한 논문기존 BERT의 학습 방식에 대한 재검토와 여러 최적화 기법을 적용해 모델 성능을 향상시킴💡 주요 목표는 "BERT의 잠재력을 최대한
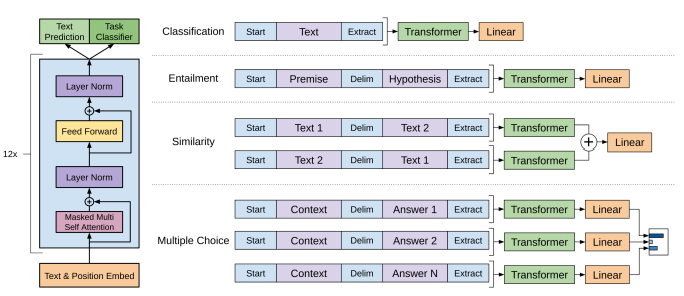
GPT-1 : Improving Language Understanding by Generative Pre-Training (2018)
GPT-1: Introduction openAI에서 GPT-1(Generative Pre-trained Transformer) 개발 자연어 이해를 향상시키이 위해 사전학습(pre-traning)과 미세 조정(fine-tuning)의 두 가지 단계 활용 Backgroun
📜Transformer: Attention is All You Need (2017)
Transformer: Introduction 자연어 처리(NLP)는 오랜 시간동안 순환신경망(RNN, LSTM)을 기반으로 발전함 이러한 모델들은 (1) 긴 문장에서 정보를 잃어버리고(Long-Term Dependency Problem), (2) 병렬 연산이 어렵다는
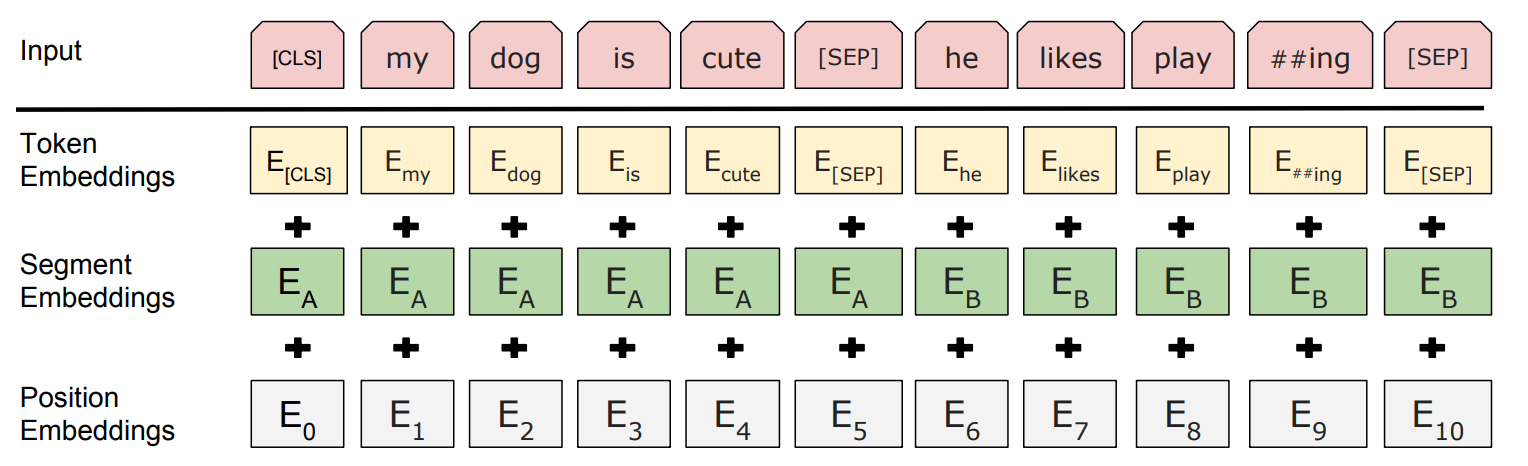
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
소개BERT(Bidirectional Encoder Representations from Transformers)구글이 2018년에 발표한 자연어 처리 모델트랜스포머 아키텍처를 기반으로 함기존 NLP 모델과 달리 BERT는 입력 텍스트를 양방향으로 이해함주요 특징양방향
분류알고리즘의 성능지표
Accuracy \- 설명: 전체 예측 중 올바르게 예측한 비율을 나타냄. \- 데이터 특성: 클래스가 균형을 이루는 데이터셋에 유용함(균형데이터)AUC(Area Under the ROC Curve)설명: ROC 곡선 아래 면적으로, 모델의 분류 성능을 전체적으
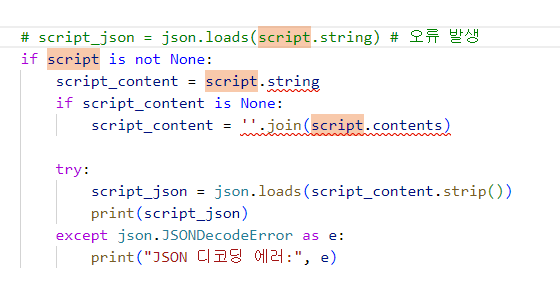
크롤링 script.string 오류 해결 방법(AttributeError: 'NoneType' object has no attribute 'string')
크롤링하면서 script를 json으로 변경하는 곳에서 아래와 같은 오류 발생함.그러나 script를 확인해보니 내용이 존재함.script에는 내용이 존재하니, 이거를 직접 string으로 변환해야 함.이렇게 변경하니 json으로 변환이 되었으며, 적재가 잘되는 것을
AutoML 정의 및 코드 적용(pycaret 사용)
AutoML AutoML(Automated Machine Learning) 자동화된 ML은 시간 소모적이고 반복적인 기계 학습 모델 개발 작업을 자동화하는 프로세스 머신러닝을 위한 고급 모델 구축을 자동화할 수 있기 때문에 데이터 과학 전문 지식과 프로그래밍 스킬이
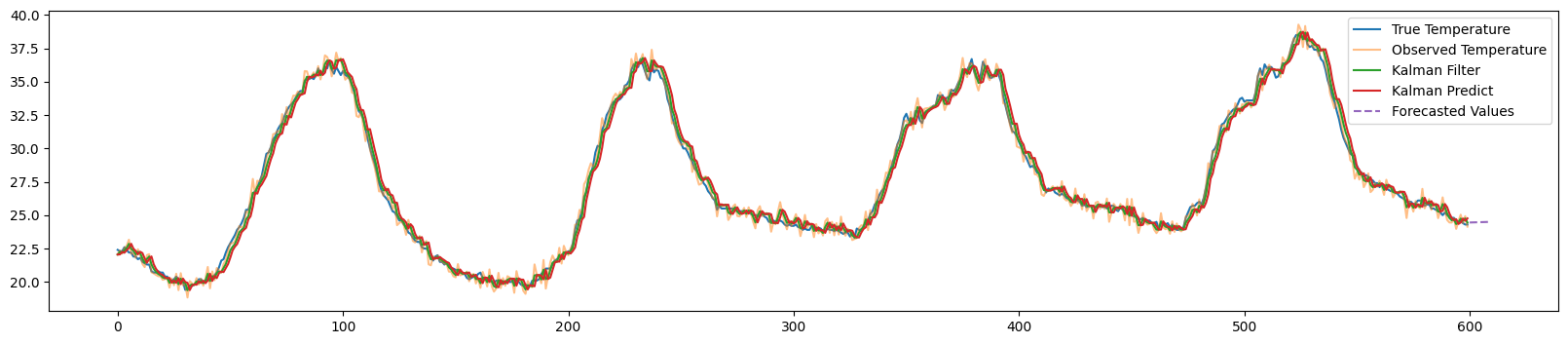
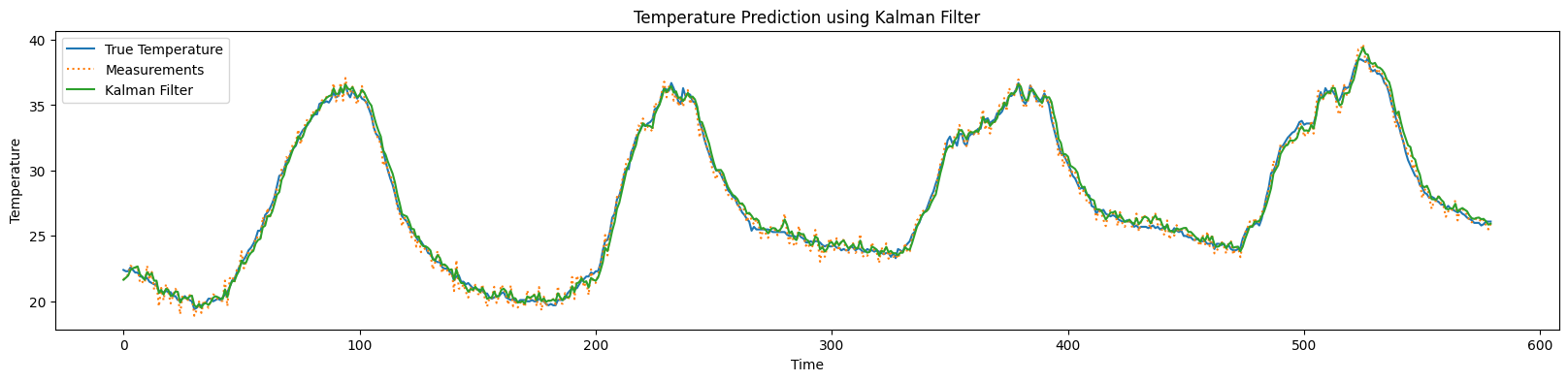
칼만필터 파이썬 코드로 구현하기(수식 사용)
칼만필터 정의 및 알고리즘 앞서 칼만필터 정의 및 알고리즘 내용을 살펴봄. 미리 칼만필터에 대해 알고 이 글을 보는 것을 추천함. 그것에 대한 수식을 패키지를 사용하지 않고 구현함. 실제 온도에 대해 칼만필터를 적용함. 1. 데이터 불러오기 참고(칼만필터 R로 구
칼만필터 파이썬 코드로 구현하기(Pykalman 패키지 사용)
칼만필터 정의 및 알고리즘앞서 칼만필터 정의 및 알고리즘 내용을 살펴봄. 미리 칼만필터에 대해 알고 이 글을 보는 것을 추천함.그것에 대한 파이썬 패키지인 Pykalman을 사용해 구현함.실제 온도에 대해 칼만필터를 적용함.transition_matrices : 상태
칼만필터(Kalman Filter)란 무엇인가? 칼만필터 정의 및 알고리즘
칼만필터 정의 > 과거와 현재의 관측값을 사용해 미래의 상태를 예측하는 수학적 알고리즘 특히, 시스템이 불확실하거나 노이즈가 많은 경우 유용함 물체의 특정 시점에서의 상태가 이전 시점의 상태와 선형적인 관계를 가지고 있는 경우 적용이 가능 이전 시간 단계의 상태와 공
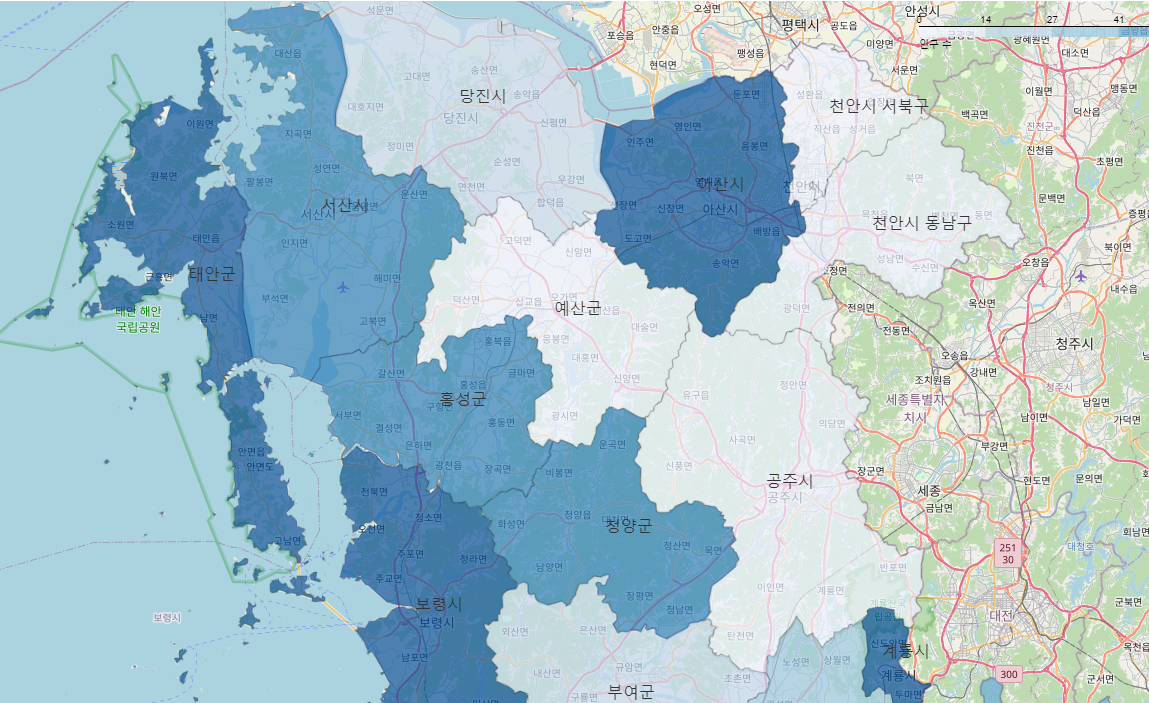
[folium 라이브러리] 지도 시각화하기, 지도에 텍스트 넣기
1. 라이브러리 불러오기 2. 지도데이터 불러오기 대한민국 최신 행정구역(SHP) 다운로드 페이지 시군구 데이터를 다운받음 위의 데이터는 좌표계가 5179라 우리가 사용하는 위경도인 4326으로 변경해줘야 함 이 데이터는 시도는 안나와서 sig_cd인 행정동코드를
흉부외과 또는 일반외과 의사 목록 출력하기-프로그래머스(SQL)
주의사항: 날짜 포맷은 예시와 동일하게 나와야합니다.다중정렬은 order by ~,~ 이렇게 사용하면 됨desc는 내림차순(생략가능, 다중에서는 안됨)asc는 오름차순
3월에 태어난 여성 회원 목록 출력하기-프로그래머스(sql)
where절 이용date에서 월만 뽑기 위해 MONTH를 이용한다.윤서연님이 전화번호가 null이기 때문에 빼줘야 한다 \-> NOT TLNO IS NULL을 이용!회원ID를 오름차순으로 정렬하기 위해 ORDER BY ~ ASC 사용DATE_OF_BIRTH를 그냥 출
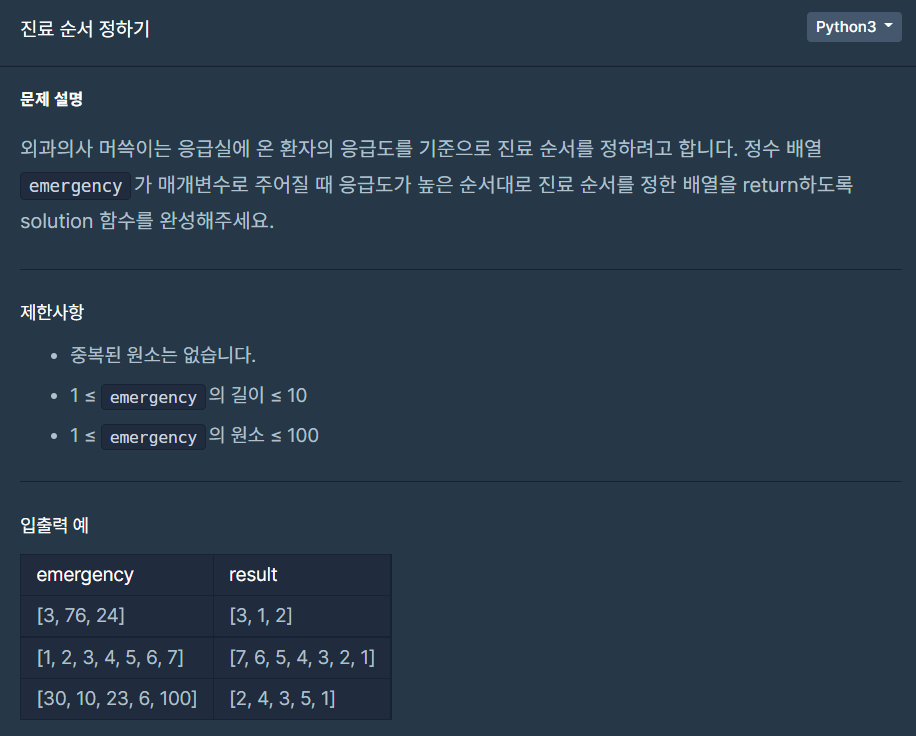
진료 순서 정하기-프로그래머스(python)
emergency를 내림차순으로 정렬해준 후 .index()를 사용해서 자리를 찾아준 후 +1을 해준다.index는 0부터 시작하기 때문딕셔너리방법도 좋은듯
숨어있는 숫자의 덧셈(2) - 프로그래머스(python)
처음엔 \[i for i in ss if i.isdigit()] 이렇게 진행했는데 그럼 숫자가 다 분리가 되었다.그래서 re메서드를 사용했다.re.split으로 알파벳을 다 공백으로 바꿔준다. \-> \['', '', '', '1', '2', '', '34', '',