
- 전체보기(27)
- mysql(6)
- aws(6)
- sql(3)
- 인덱스(3)
- fp(3)
- typescript(3)
- cloudfront(3)
- 성능(3)
- MySQL8(3)
- CDN(2)
- effect-ts(1)
- LomBok(1)
- FM(1)
- dynamic route(1)
- AWS CLI(1)
- S3(1)
- hammerspoon(1)
- lambda edge(1)
- mac(1)
- Window Function(1)
- rag(1)
- Cache(1)
- Namespace(1)
- lock(1)
- Index(1)
- React(1)
- AWS CloudFront(1)
- performance_schema(1)
- ecs(1)
- class(1)
- domain(1)
- entity(1)
- Effect(1)
- Lambda@Edge(1)
- apaceh bench(1)
- chatbot(1)
- OpenAI(1)
- Statistics(1)
- window(1)
- Enum(1)
- AI(1)
- cloudfront function(1)
- dynamic(1)
- getter(1)
- elastic search(1)
- dynamodb(1)
- shortcut(1)
- next.js(1)
- ssg(1)
- Elastic Beanstalk(1)
- .env(1)
- Embedding(1)
- Elastic Container Service(1)
- sys(1)
- EB(1)
- productivity(1)
- benchmark(1)
- nextjs(1)
- param(1)
- brandedType(1)
- LLM(1)
Typescript에서 Namespace의 활용 (with BrandedType, FP)
Typescript에서 BrandedType과 Namespace를 활용해봅니다.
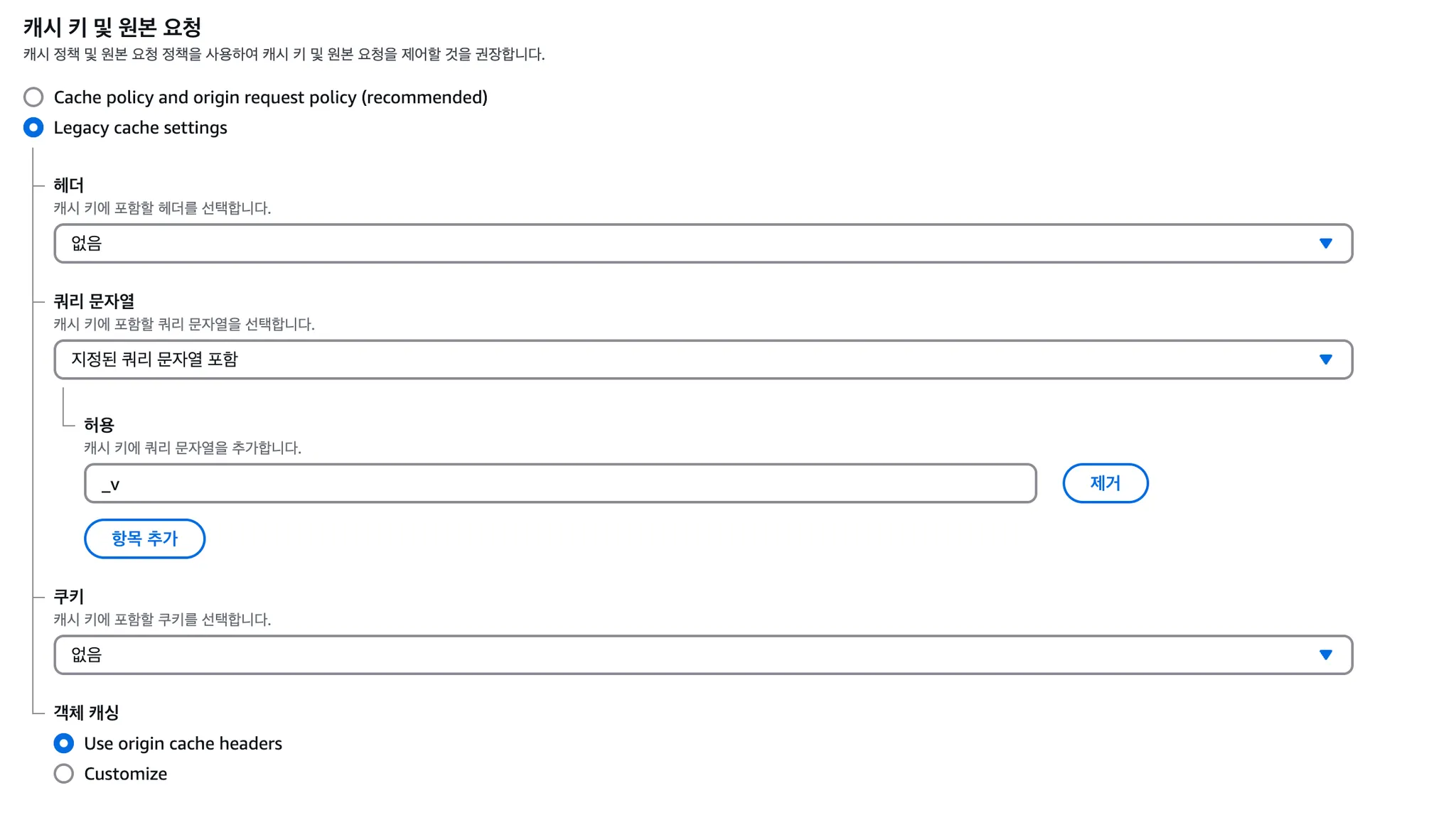


MySQL 쿼리 성능 최적화 - 1
자료구조 B+Tree 쿼리 성능을 최적화하기 위해서는 B+Tree 자료구조를 이해하는 것이 시작입니다. (a, b, c) 컬럼으로 구성된 인덱스가 있을 때 a, b 정렬은 인덱스를 타고 a, c 정렬은 못타고... 이런식으로 외우는건 큰 도움이 되지 않습니다. mysql(innodb)의 테이블과 인덱스 데이터는 모두 트리 구조로 저장됩니다. 하나의 테이...
MYSQL8. 인덱스 적용
조인은 아니지만 조인과 같이 사용하는 준조인서브쿼리를 조인으로 바꾼다.다른 최적화도 사용할 수 있다. 전체 semijoin 플래그 외에는 비활성화 시키는 variable이 없다. In 서브쿼리를 exists로 바꿔서 실행시켜서 각 로우에 대해 handler_read_
Elastic search. 기본 정리
TextAnalyzer로 토큰화하여 풀텍스트 검색 가능index 필드 false로 두면 토큰화 하지 않아서 검색 불가능집계나 정렬이 필요하면 fileddata:true 로 하거나 field로 keyword 사용Keyword풀텍스트 검색 불가능Analyzer 대신 Nor
MYSQL. Performance_schema, Sys
모든엔진은 performance_schema 엔진 사용디스크에 테이블의 구조만 저정하며 모든 데이터 메모리에 저장함바이너리 로그에 기록되지 않아서 레플리카 서버로 복제되지 않음수집할 유저(host, user) 설정수집할 스키마, 테이블, 트리거 설정이벤트 종류별 설정수
MYSQL. Handler API와 Status
InnnoDB와 같은 스토리지 엔진은 Handler API를 구현한다.MYSQL은 모든 쿼리에서 handler Api를 이용해서 실제 데이터 작업을 처리한다.이 때 상태변수에 이러한 작업 처리 횟수를 기록해 놓는다.Handler_read_first인덱스 처음 값을 읽은
AWS. DynamoDB와 기본키, 인덱스
DynamoDB에는 기본키에 추가로 두 종류의 인덱스가 있다글로벌 보조 인덱스(GSI)로컬 보조 인덱스(LSI)기본키는 파티션키와 추가로 정렬키를 가질 수 있다.AWS에서 DynamoDB는 물리적으로 여러 파티션에 데이터를 나눠서 저장한다.저장될 파티션의 위치를 정하는
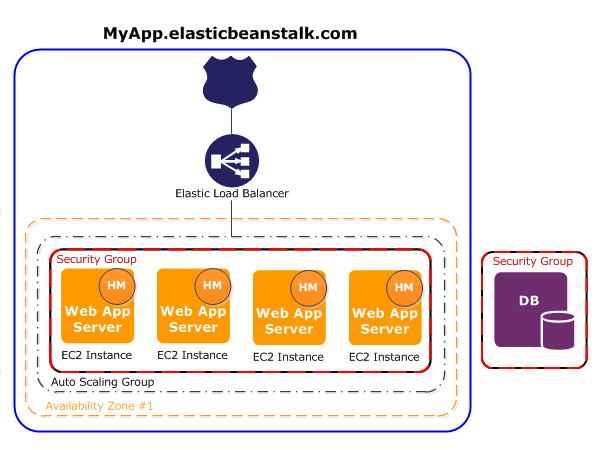
AWS Elastic Beanstalk(EB) 기본 정리
소스(or도커이미지) + 기본설정\-> 배포, 로드밸런싱, 오토스케일링, 모니터링 ...제목 설명만 있는 껍데기어플리케이션에 종속되며 하나의 어플리케이션에 여러개 생성 가능 (ex] dev, release, production)소스부터 설정까지 여기에 다 있음이름 잘