
ML - 15. 자연어 처리 NLP (Natural Language Processing)
install Kkma ['한국어 분석을 시작합니다', '재미있어요 ~'] ['한국어', '분석'] [('한국어', 'NNG'), ('분석', 'NNG'), ('을', 'JKO'), ('시작하', 'VV'), ('ㅂ니다', 'EFN'), ('재미있', 'VA'), ('어요', 'EFN'), ('~', 'SO')] Hannanum ['...
ML - 14. mini project _ CREDIT CARD FRAUD DETECTION
프로젝트 소개 주제 : 신용카드 부정 사용자 검출 데이터 : https://www.kaggle.com/MLG-ULB/CREDITCARDFRAUD 개념 신용카드와 같은 금융데이터들은 구하기가 어려움 금융 데이터들의 데이터는 또한 다루기 쉽지 않음 그러나 지능화
ML - 13. GBM - Gradient Boosting Machine
이번에 사용한 데이터 : HAR_datasetGBM - Gradient Boosting Machine부스팅 알고리즘은 여러 개의 약한 학습기(week learner)를 순차적으로 학습-예측하면서 잘못 예측한 데이터에 가중치를 부여해서 오류를 개선해가는 방식GBM은 가중
ML - 12. kNN (k Nearest Neighber)
새로운 데이터가 있을 때, 기존 데이터의 그룹 중 어떤 그룹에 속하는지 분류하는 문제k는 몇 번째 가까운 데이터까지 볼 것인가를 정하는 수치 즉, 쉽게 말해 새로운 데이터(검은점)이 빨강-파랑 중 어디로 분류 되는지 정하는 것더 간단히 말해, K값을 설정하고, 그 값에
ML - 11. 앙상블기법_Boosting Algorithm (기초)
앙상블기법 앙상블은 전통적으로 Voting, Boosting, Bagging, 스태깅 으로 나뉨 보팅과 배깅은여러개의 분류기가 투표를 통해 최종 예측 결과를 결정하는 방식이다 둘의 차이점은 보팅은 각각 다른 분류기, 배깅은 같은 분류기를 사용 대표적인 Bagging
[EDA] mini project 12 _ 세계 테러 분석
데이터 불러오기모든 컬럼 확인컬럼\_데이터 확인보기 좋게 컬럼명 변경사용할 컬럼으로 변경비어 있는 데이터 확인 : isnull().sum()데이터 타입 확인연간 테러 발생 건수 테러발생 상위 10개국사상자 상위 10개국지역별 테러 특성 확인연도별 테러 양상 분석연도별
SQL - mini test _ 세계 테러 분석
https://www.kaggle.com/datasets/START-UMD/gtd문제 1. csv 파일에 저장된 세계 테러 데이터를 하나의 테이블에 저장하세요. globalterrorismmdb_0718.csv - https://www.kaggle.
ML - 10. 앙상블 기법 - H AR, Human Activity Recognition - 센서를 활용한 행동인식 실험
앙상블 ? 📌 앙상블 기법의 voting 전체 데이터 셋에서 각기 다른 알고리즘을 돌리는 것 아는 것 다 돌려보고 다수결에 의해서 최종결정 하겠다 📌 bagging 기법 bootstrapping : 중복을 허용해 샘플링 함 랜덤하게 샘플링된 데이터에 각각의 알고리즘을 붙여서 결과를 받아들임 📌 결정 방법에서의
ML - 9. Precision(정밀도) and Recall(재현율)
Precision(정밀도) and Recall(재현율) 1) 데이터 가져오기 2) 맛 등급 설정 3) 데이터 분리 4) 로지스틱 회귀 Train Acc : 0.7429286126611506 Test Acc : 0.7446153846153846 5) classification report 6) confusion matrix array( ...
ML - 8. (분류)Logistic Regression - PIMA 인디언 당뇨병 예측
Logistic Regression을 쓰는 이유 : 💡분류기 역할 즉, linear regression (선형회귀)을 분류에 적용한 것이 Logistic Regression (로지스틱 회귀)이다. LR 이론 악성 종양을 찾는다고 가정하자. linear regression (선형회귀)에 적용한다면 0과 1밖에 없어서 수 많은 데이터를 분류하기가 어려 ...
ML - 7. Cost Function & Gradient Descent _ 보스턴 집값 예측(분석)
1. Cost Function 최소값 지점 찾기 1.236842105263158 지점 데이터 = 모델 에러는 '0' 데이터 != 모델 에러가 '증가'  데이터를 기반으로 하는 문제 해결 방법 문제 분석 > 학습 시킴(데이터 계속 유입됨) > 데이터를 베이스로 하기 때문에, 알고리즘 구현 & 서비스 런칭 부분만 코딩으로 해결 모델 스스로
ML - 5. Model Evaluation _ 함수 & box plot
기초 수학 개념 회귀 모델 내가 가지고 있는 데이터를 직선으로 만들어 두고, 각 값들을 예측하는 것 (회귀 모델 예측 결과) : 연속된 변수값 분류 모델 구분이 명확함 몇개의 종류에서 값을 찾아내는 것 (iris, 와인 프로젝트) 이진 분류 0 과 1 맞다, 아니다 전체 데이터 에서 실제 1의 값을 가진 데이터 TP = 실제 1인데 1로 맞춘 ...
ML - 4. Decision tree, Pipeline, 하이퍼파라미터 튜닝 - 와인 분석
1. 와인데이터 분석 1_데이터 읽어오기 2_컬럼조사 Index(['fixed acidity', 'volatile acidity', 'citric acid', 'residual sugar', 'chlorides', 'free sulfur dioxide', 'total sulfur dioxide', 'density', 'pH'...
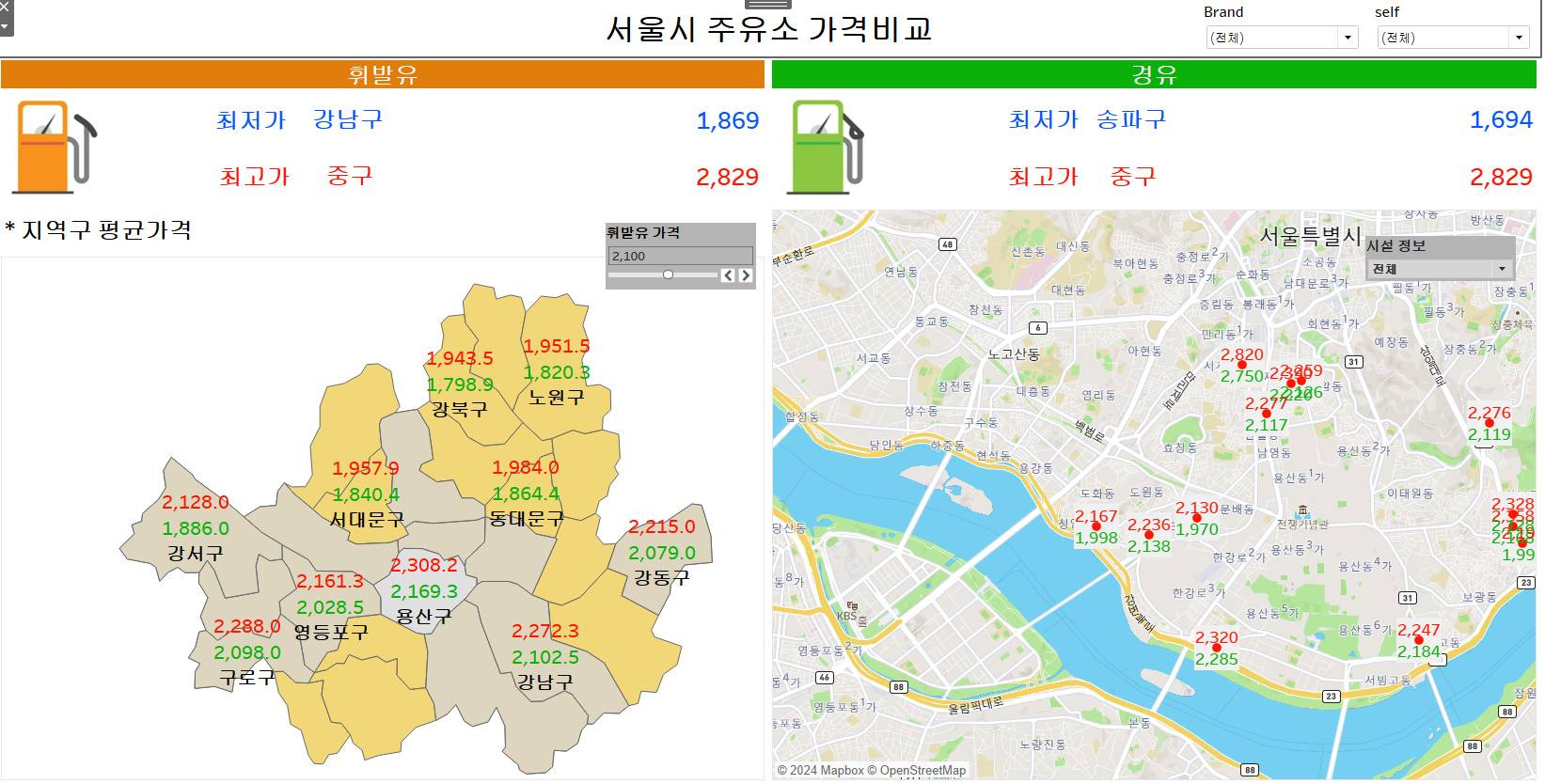
Tableau - (과제2) 주유소 평균 가격
d1. 지역별 평균 가격 1_self (계산 필드) 2_휘발유 가격 매개변수 계산된 필드 3_완성 조금 다르지만 일단 완성.. 
Tableau - (과제1) 이디야 스타벅스 매장 간 거리 _ 답안 추가
1. 기본 설정 세팅 1_매장간 거리 MAKEPOINT는 위도와 경도로 구성된 공간 개체를 반환해줌 DISTANCE는 (시작, 끝, 단위)로 이뤄져 있음 2_이디야 매장수 COUNTD() 사용 3_Meters Away (매개변수) 4_거리 설정  fit ~ transform (문자 -> 숫자 array(['a', 'b', 'c'], dtype=object) array([0, 1, 2, 0, 1]) 2) fit+transform array([0, 1, 2, 0, 1])
ML - 2. Titanic 생존 분석 _ titanic disaster kaggle
1. 데이터 정리 생존상황 확인 2) 성별 3) 경제력 crosstab : 2번째 컬럼을 구분지어 주고, 인덱스에 1번째 컬럼을 담아 줌 margins=True : 합계 4) 등급/성별 _FacetG
ML - 1. Iris의 품종 분류
iris 데이터 불러오기 모듈 insatall (1) 데이터 불러오기 sklearn 에 올라와 있는 데이터 이용 (2) 데이터 타입 확인 각각의 데이터 확인 ![](https://velog.velcdn.com/images/jaam_mini/post/33