
쿼리 튜닝 개요
DB 기반 시스템에서의 DB관련 성능저하의 비율은 70% 이상이다. 그만큼 DB 설계 및 쿼리 단계에서 성능을 고려하지 못하는 경우가 발생하기 쉽고, 이를 기술적으로 해결해나가는 것이 중요하다.이처럼 DB 쿼리의 성능저하 이슈를 해결하는 작업을 쿼리 튜닝이라고 한다.출
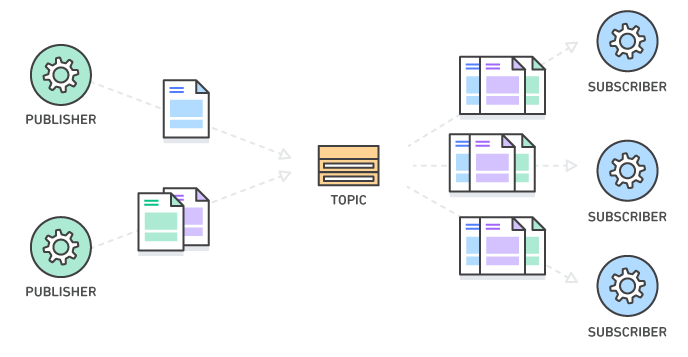
Kafka 시작하기
카프카는 이벤트 스트리밍 플랫폼으로 발생하는 이벤트에 대해 실시간으로 처리하고 이를 보장한다.카프카는 producer와 consumer가 하나의 topic을 publish/subscribe함으로써 이벤트를 발생시키고/처리하는 방식으로 구성된다. 출처 : https&#x

DI 생성해보기
Spring에서 지원하는 주요 개념인 DI(Dependency Injection)는 의존성 주입의 약어로 인스턴스를 만들지 않더라도 스프링 컨텍스트에 등록된 빈의 인스턴스를 생성해주는 것으로 잘 알려져있다.실제 DI가 어떤 식으로 구현되어 있고 동작하는지 백기선님의 J
좋은 코드를 작성하기 전에
좋은 코드를 작성하기 전에 좋은 코드가 무엇인지 알고 넘어갈 필요가 있을 것 같다.나는 클린코드라는 책을 읽으며 좋은 코드를 작성하는 법을 배우고 있다. 해당 책에서는 소프트웨어 개발 분야의 몇몇 OG들의 코멘트를 인용하여 좋은 코드를 설명하고 있다. 이를 내 나름대로
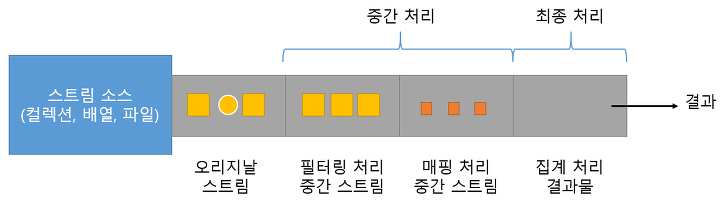
스트림
스트림이란 컬렉션의 저장 요소를 하나씩 참조하여 람다식으로 처리할 수 있도록 해주는 반복자이다. iterator와 비슷하다고 생각이 들 수도 있다. 하지만 iterator는 자체적으로 반복하지 않고 외부의 반복자가 필요하다. 반면에 스트림은 내부 반복자로 람다식으로 처
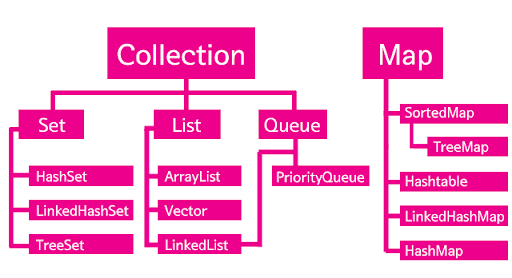
컬렉션 프레임워크
배열은 기본적으로 크기와 타입이 고정적이기 때문에 동적인 작업을 위한 자료구조로는 부적합하다. 자바에서는 이러한 배열을 문제점을 해소하기 위해 기본적인 자료구조 형태의 컬렉션 프레임워크를 지원하고 있다.컬렉션 프레임워크는 특정 객체들을 저장, 검색, 삭제 등의 작업을
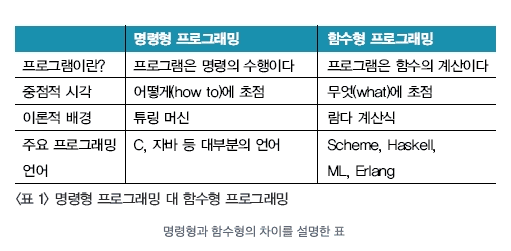
람다식
함수평 프로그래밍은 프로그래밍 패러다임의 하나로 자료를 특정 상태를 바꾸는 것이 아닌 함수를 구현하여 실행하고 결과를 얻는 방식으로 처리하는 프로그래밍 기법이다. 함수형 프로그래밍은 병렬 처리와 이벤트 지향 프로그래밍에 적합하기에 자바 8부터 지원하기 시작했다.함수형
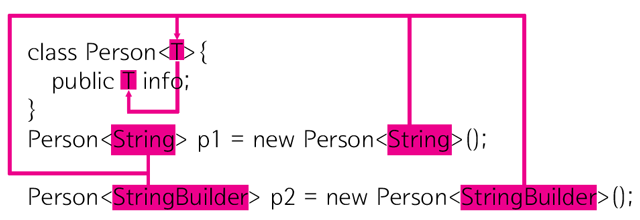
제네릭
자바에서 사용되는 다양한 컬렉션 클래스나 함수형 프로그래밍 관련 클래스들에서는 제네릭 타입으로 많은 파라미터들이 선언되어 있다. 따라서 자바를 제대로 이해하려면 제네릭에 대해서 확실히 알고 넘어가야 한다.그렇다면 제네릭을 사용하는 이유는 무엇일까? 첫 번째로 제네릭을
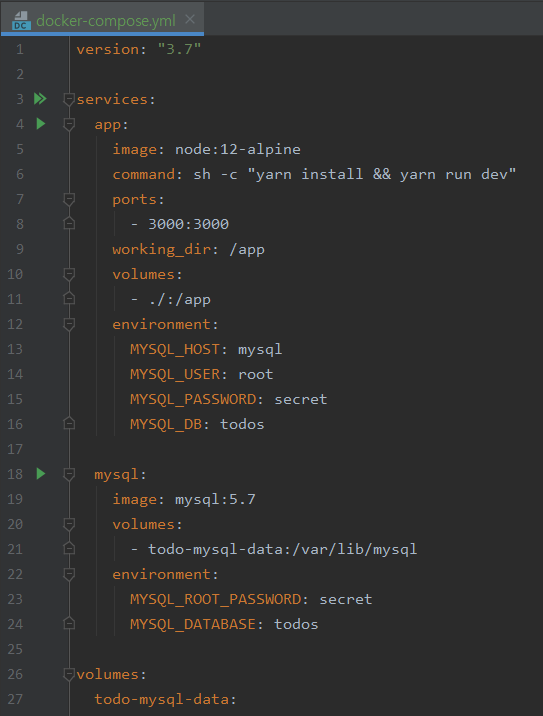
도커 컴포즈 사용하기
도커 컴포즈를 사용하면 좋은 점 도커 컴포즈는 다중 컨테이너 어플리케이션을 정의하고 공유하기 위해 개발된 기능이다. 이전에 node.js 애플리케이션과 MySQL을 각 컨테이너에 구동하기 위
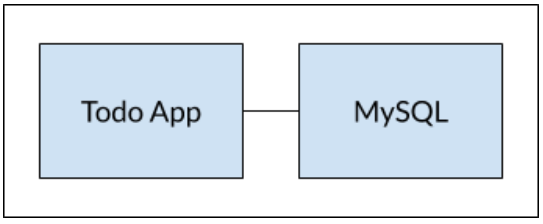
컨테이너간 통신
출처 : https://docs.docker.com/get-started웹 아키텍쳐에서는 여러 개의 애플리케이션이 구동되기도 한다. 특히 데이터베이스를 따로 구동하는 경우가 많다. 그렇다면 도커에서는 데이터베이스를 어디에서 구동할까? 하나의 컨테이너안에 nod
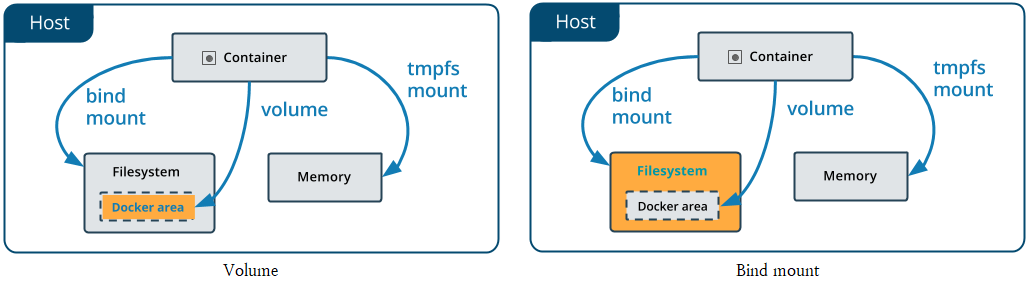
볼륨과 바인드 마운트
출처 : https://docs.docker.com/get-started도커의 컨테이너는 각각 독립적인 파일 시스템을 가지고 있다. 따라서 같은 이미지로 만든 두 개의 컨테이너는 한 쪽 컨테이너에서 작업한 내용이 다른 컨테이너에 적용되지는 않는다. 도커 공식
도커 시작하기
출처 : https://docs.docker.com/get-started/02_our_app/Node.js 예제를 활용하여 도커를 시작해보자. JavaScript에 대한 사전 지식이 없더라도 크게 문제가 없을 것이다. 우선 아래의 링크에서 도커 공식문서가 제공
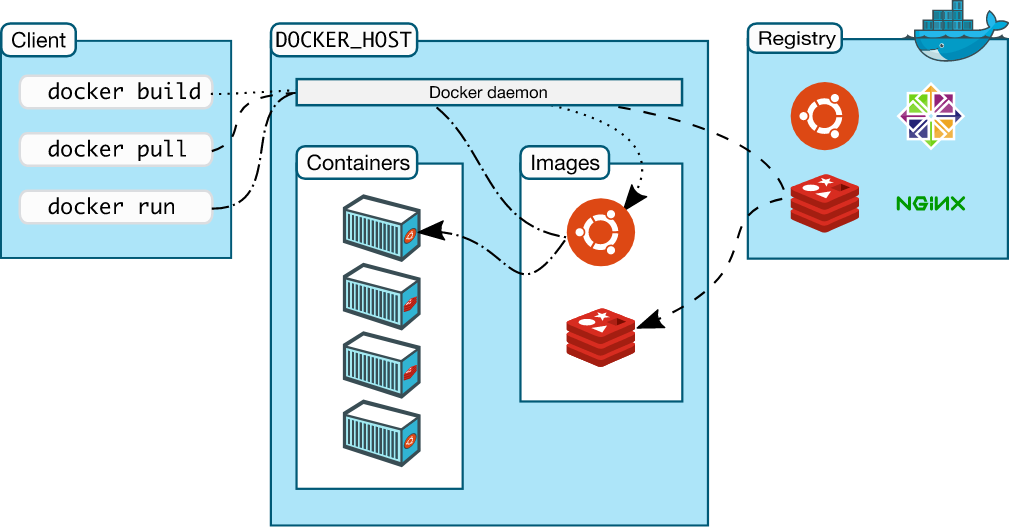
도커 개요
출처 : https://docs.docker.com/도커란 어플리케이션의 개발, 실행, 배포를 위한 개방형 플랫폼이다. 도커는 나의 어플리케이션에 독립적인 환경을 제공하여 플랫폼 독립적으로 어플리케이션을 개발할 수 있게 도와준다.그렇다면 도커를 사용해야하는 이
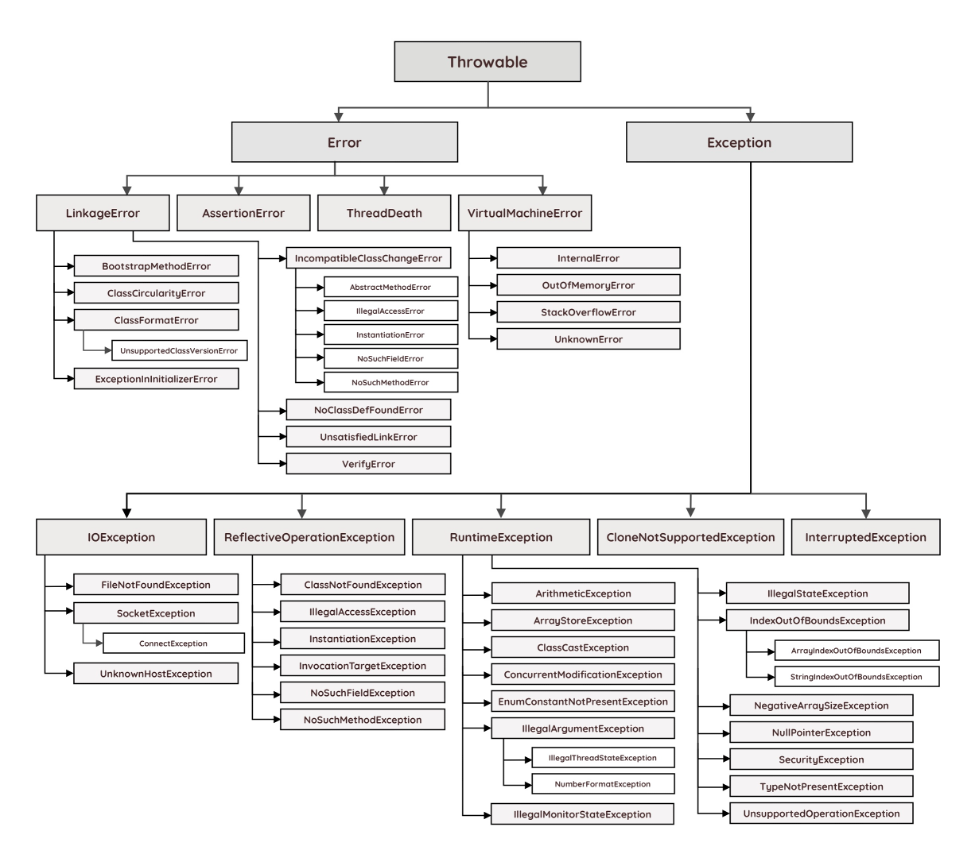
예외
예외(Exception)란 무엇일까? 사용자의 잘못된 조작이나 개발자의 잘못된 코딩으로 발생하는 프로그램 오류를 말한다. 예외가 발생하면 프로그램은 바로 종료된다. 하지만 예외 처리를 해줌으로써 프로그램이 종료되지 않고 다른 동작을 하게끔 할 수 있다.자바에서 예외는
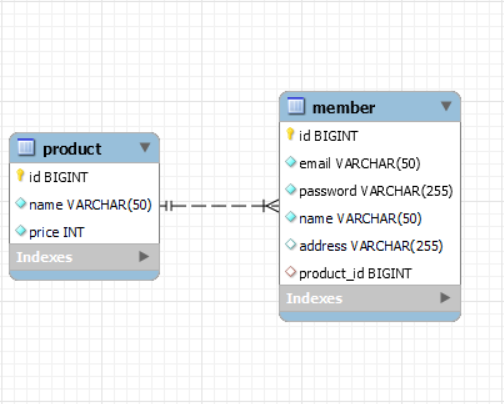
연관관계 매핑
데이터베이스에서 두 개의 테이블은 서로 연관 관계를 가지기도 한다. 예를 들어 Member table에는 Job table에서 member의 job을 참조할 job_id를 외래키로 가지게 된다. 이러한 경우에 두 테이블은 서로 연관 관계를 가진다고 한다.데이터베이스에서
엔티티 매핑
엔티티는 데이터베이스의 테이블과 매핑되는 자바 객체이다. 따라서 자바에서 테이블의 데이터를 핸들링하기 위해서는 엔티티를 잘 매핑해야한다.엔티티를 테이블과 매핑하기 위한 기본적인 문법을 살펴보자.JPA를 사용해서 테이블과 매핑할 자바 객체를 엔티티라고 한다. 이 엔티티에
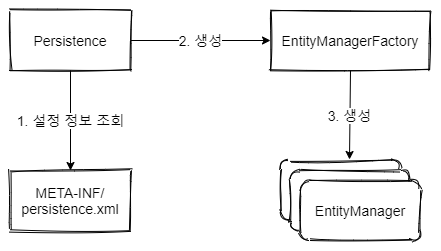
JPA 영속성
JPA를 시작하며 가장 기본적으로 사용되는 객체가 엔티티 매니저 팩토리와 엔티티 매니저이다. JPA를 기본적으로 데이터를 엔티티 단위로 받아오기 때문에 엔티티를 관리할 수 있는 수단이 필수적이다.EntityManagerFactory는 하나의 애플리케이션에 하나만 생성하

JPA 개요
JPA 등장 전부터 사용되던 JDBC나 MyBatis의 경우에는 SQL을 Java위에서 작성해서 DB에서 적절한 ResultSet을 받아오는 방식이었다. JDBC는 하나의 쿼리마다 각 컬럼을 모두 get/set 해주다보니 코드가 지저분하고 길어지게되었다. MyBatis
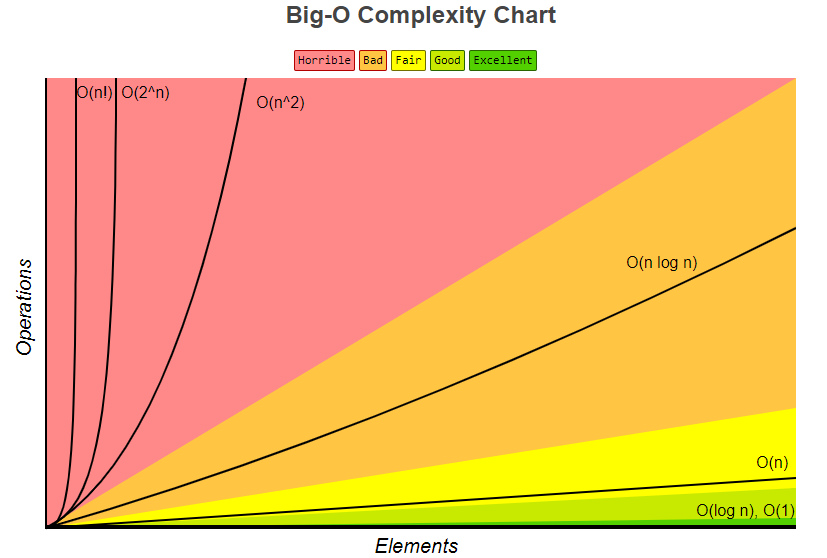
정렬 알고리즘의 시간 복잡도
프로그램들의 규모가 점차 커짐에 따라 처리하는 데이터의 양이 많아지고 있다. 이러한 경우 프로그램은 많은 데이터를 효율적으로 처리할 수 있어야 한다.데이터를 처리하는 알고리즘이 입력 데이터 n개를 n^2번 처리하여 결과 값을 출력한다고 가정해보자.입력 데이터가 100이