RL Basic
1.강화학습기초(1) - MDP, Bellman Equation
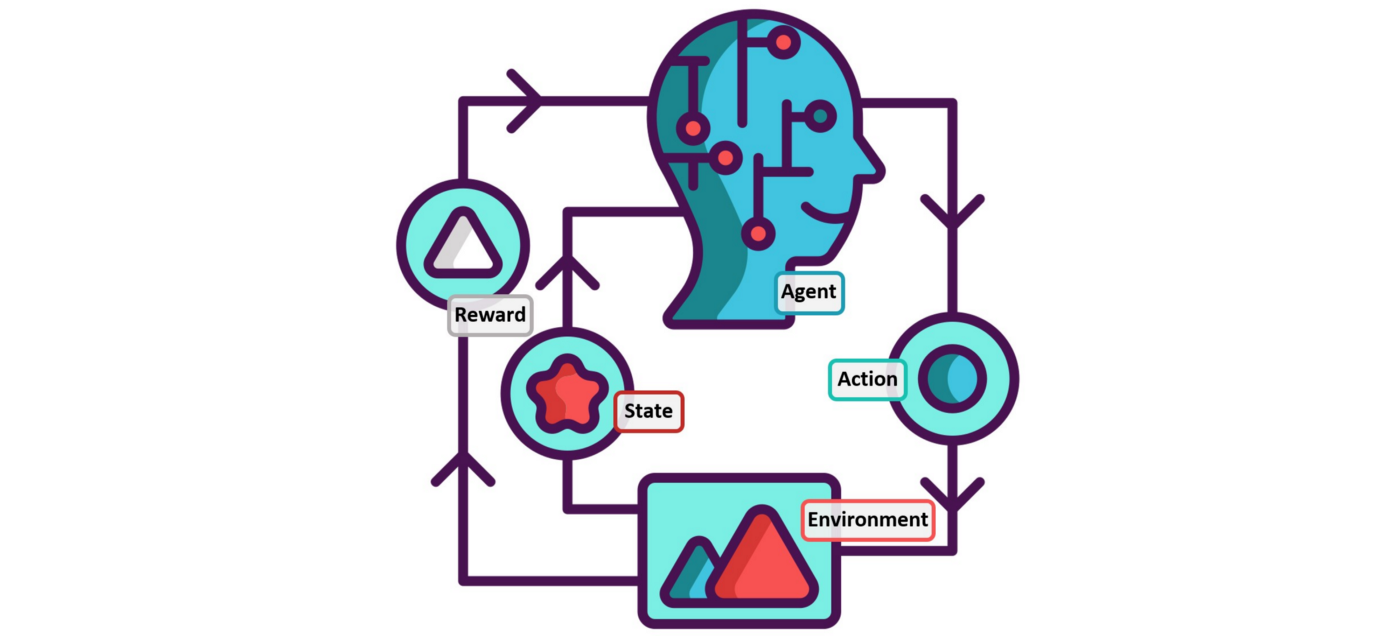
강화학습의 기본개념과 MDP 및 value function의 정의를 살펴보고, 이의 관계식에 해당하는 Bellman equation에 대해 다뤄본다.
2023년 2월 8일
2.강화학습기초(2) - Dynamic Programming
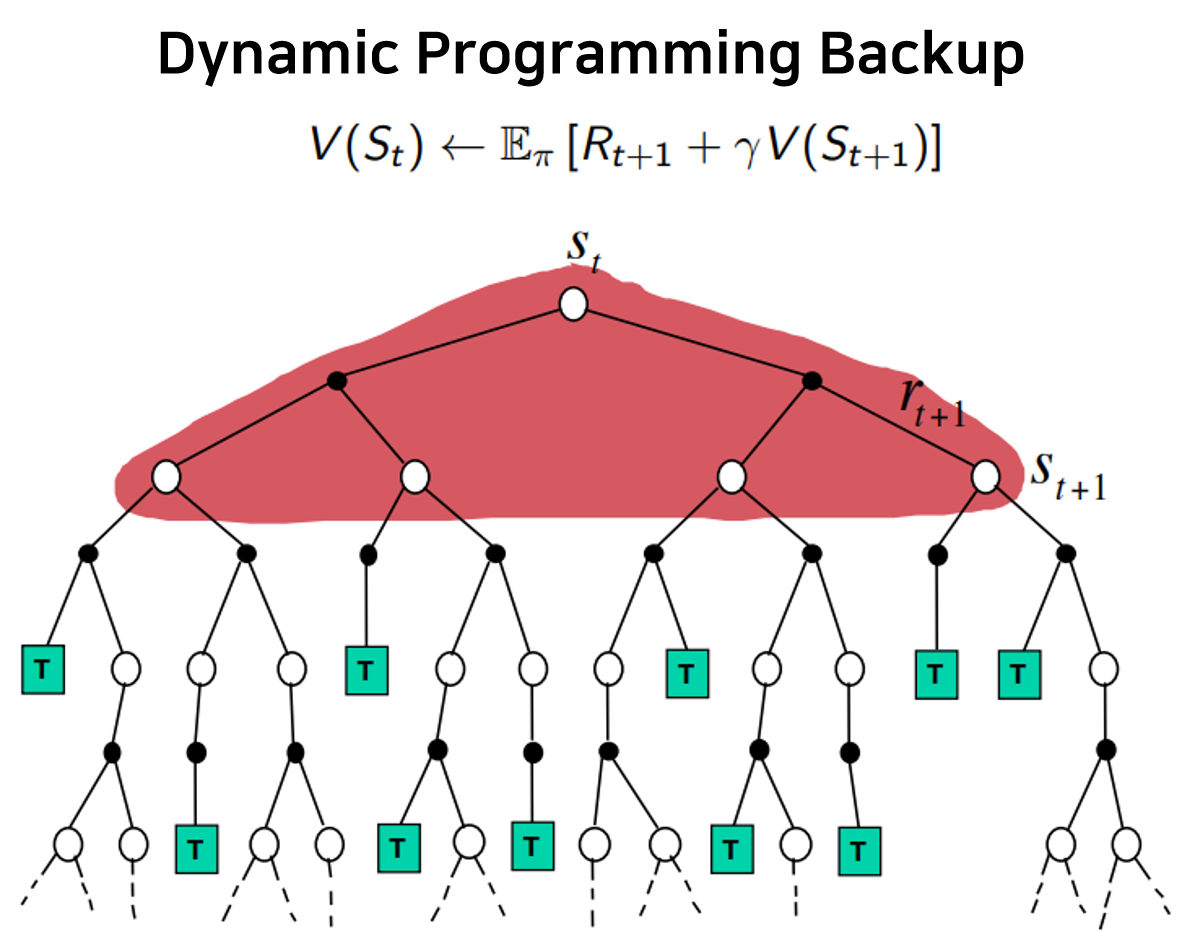
RL의 고전기법인 dynamic programming을 policy iteration과 value iteration으로 나누어 살펴본다.
2023년 2월 8일
3.강화학습기초(3) - Monte-Carlo Learning
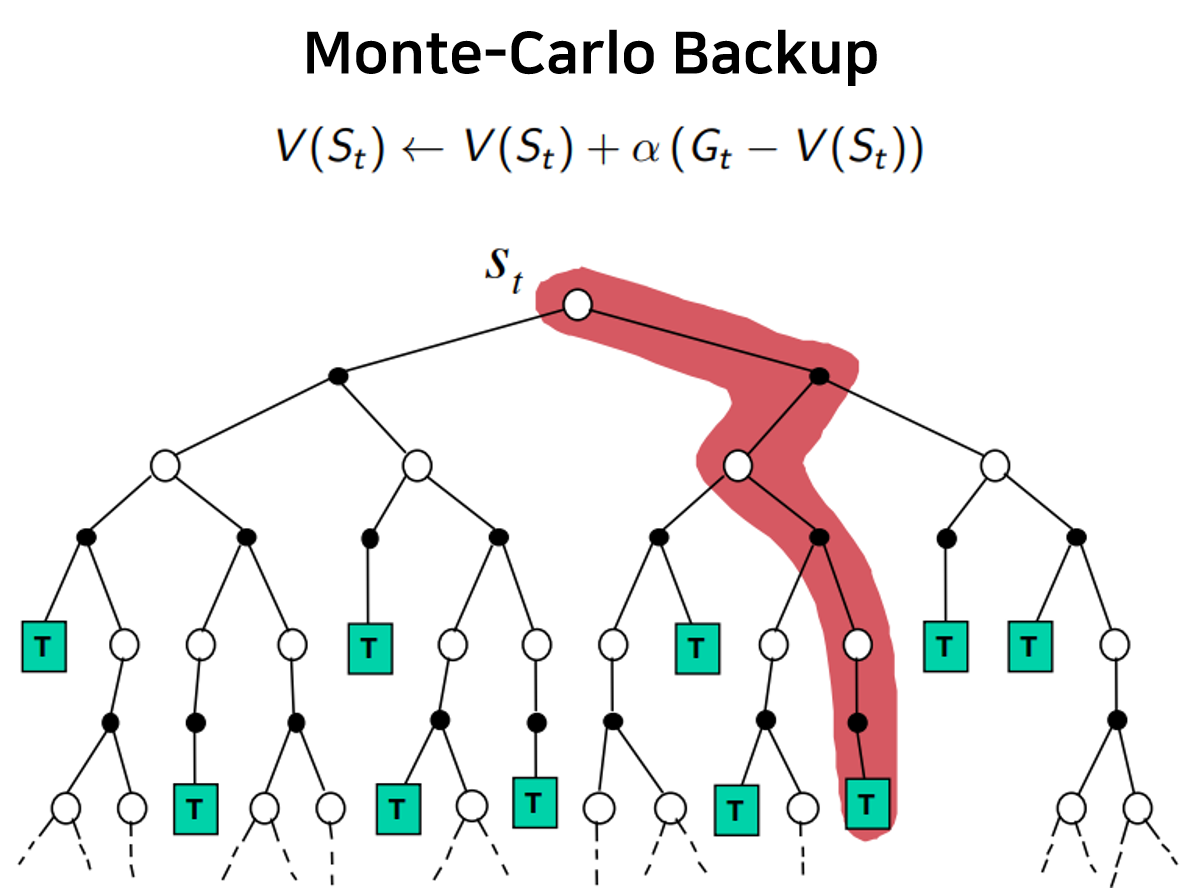
첫 번째 학습방식인 Monte-Carlo learning과 epsilon-greedy policy control의 개념을 살펴본다.
2023년 2월 8일
4.강화학습기초(4) - Temporal Difference Learning, SARSA
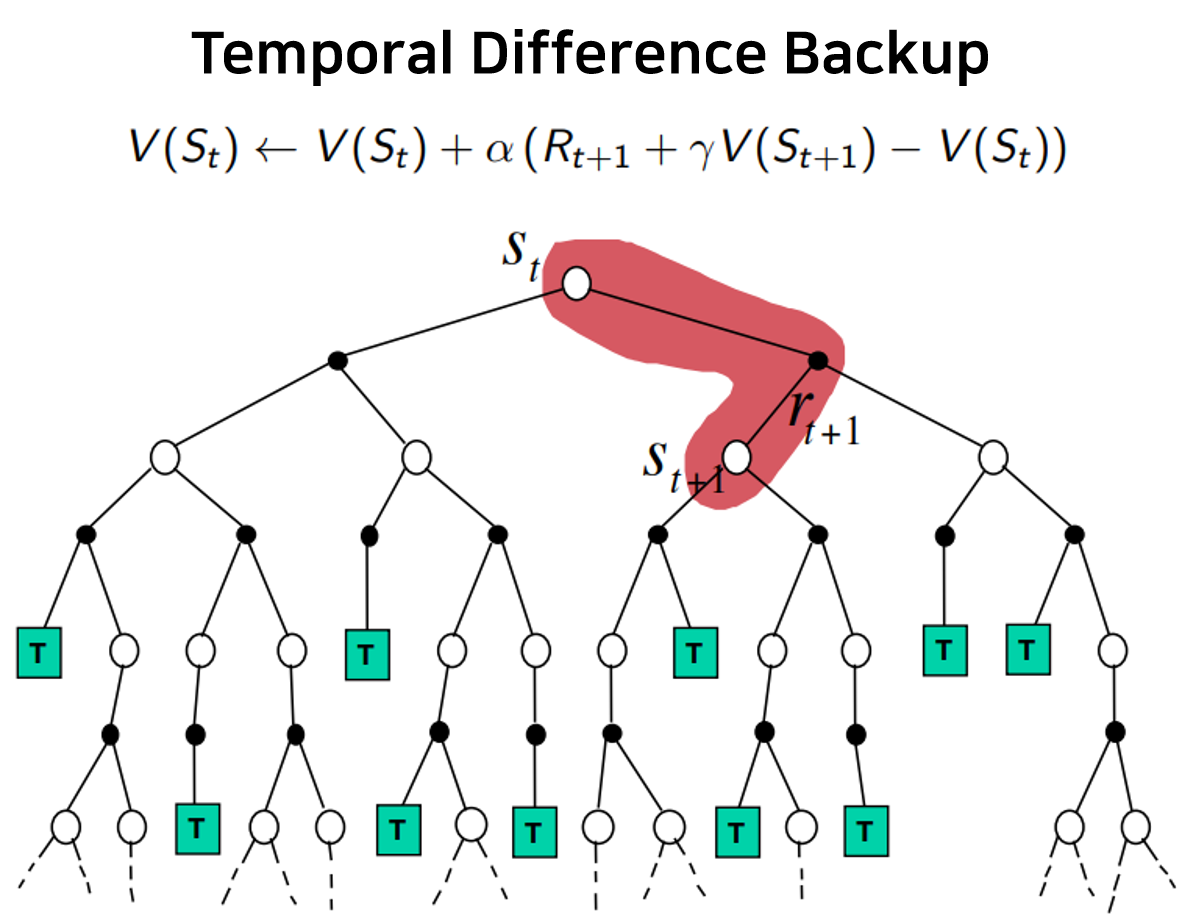
두 번째 학습방식인 temporal difference learning과 이로부터 파생된 SARSA, eligibility trace의 개념을 살펴본다.
2023년 2월 8일
5.강화학습기초(5) - Off-Policy Control, Importance Sampling, Q-Learning

Importance sampling을 적용한 off-policy MC/TD와 이를 적용하지 않은 Q-learning의 원리에 대해 살펴본다.
2023년 2월 9일
6.강화학습기초(6) - Value Function Approximation, Deep Q-Networks
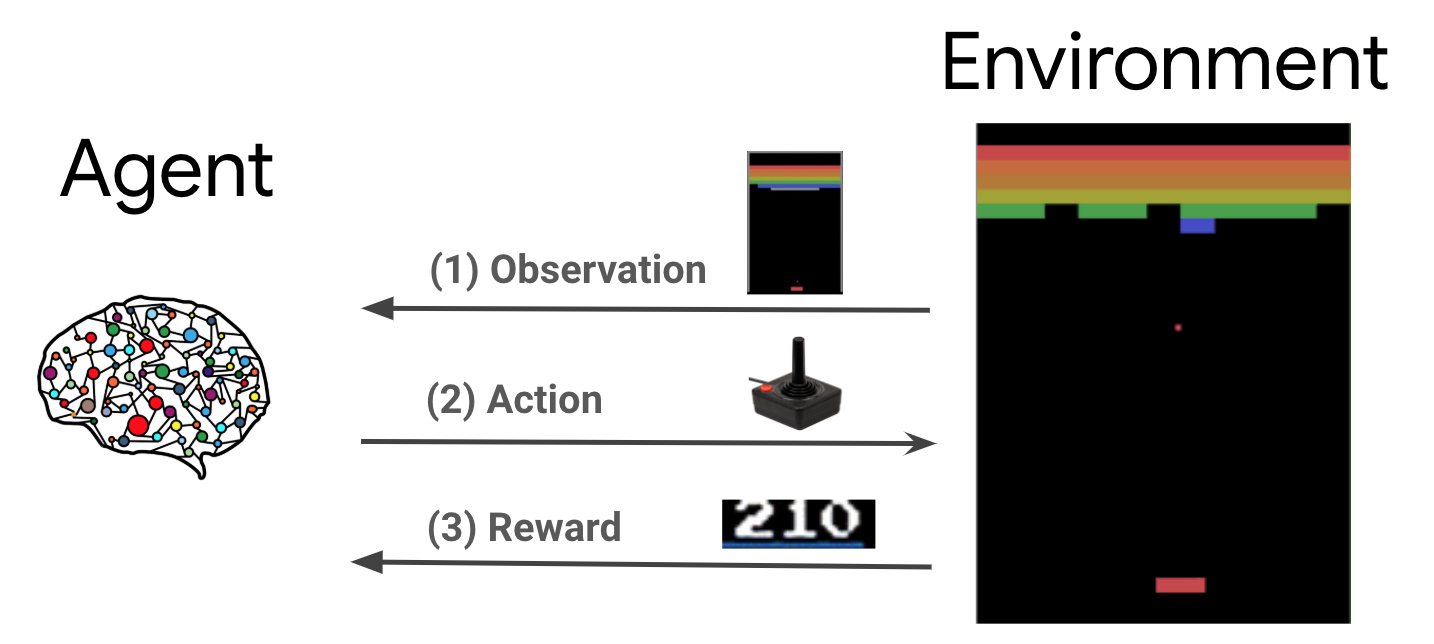
앞선 tabular RL 방식과 달리 function의 parameter만 저장하는 value function approximation의 개념과 DeepMind에서 제시한 Deep Q-Networks를 살펴본다.
2023년 2월 9일
7.강화학습기초(7) - Policy Gradient, REINFORCE, Actor-Critic
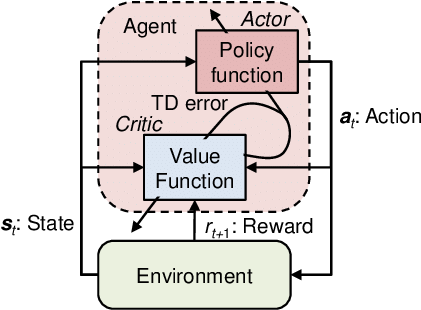
앞선 value-based 방법에 반해, policy 자체를 estimate하는 policy gradient, REINFORCE, actor-critic에 대해 살펴본다.
2023년 2월 10일
8.강화학습기초(8) - Advanced Models
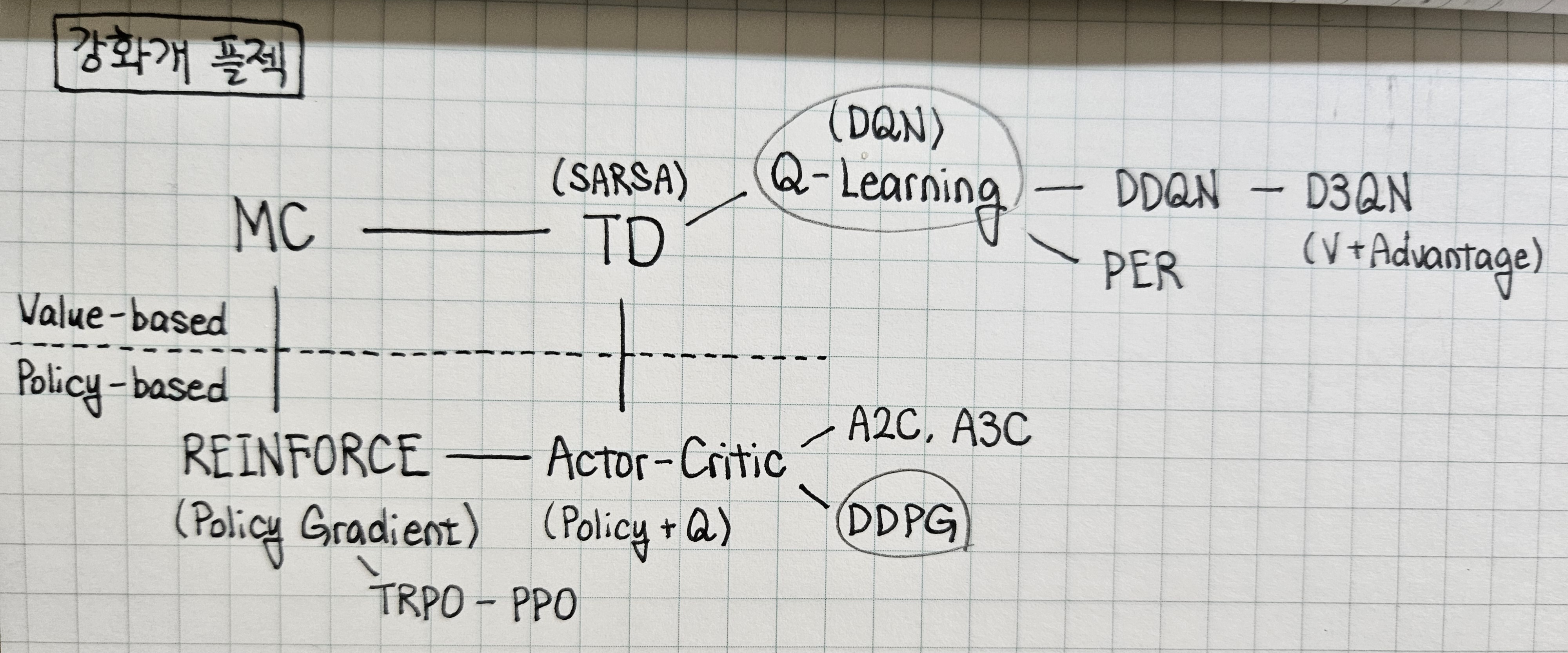
DDQN, D3QN, PER, A2C, A3C, PPO, TRPO, DDPG 등의 advanced models에 대한 내용 정리.
2023년 6월 2일