
[NLP] Seq2Seq
Encoder-Decoder Model의 등장 배경 Machine Translation, QA, Speech Recognition, Image Captioning 같은 문제에서는 입력과 출력 길이가 다를 수 있다. 일반 RNN은 이러한 입력과 출력의 길이가 서로 다르거
[NLP] GRU와 LSTM
Sigmoid와 요소 단위 곱을 게이트로 사용하여 얼마나 많은 정보가 통과할지 제어한다.$$f=\\sigma\\left(\\mathbf{w}{hh}h{t-1}+\\mathbf{w}\_{xh}x_t\\right)$$Reset Gate $r_t$와 Update Gate $
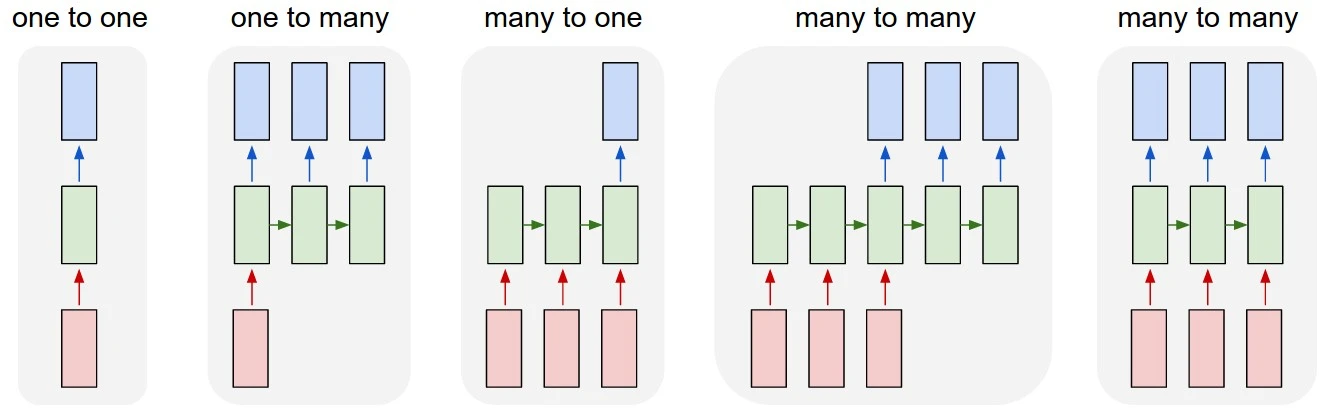
[NLP] RNN
문장의 단어를 순차적으로 처리한다. 글을 읽고 맥락을 파악하는 행위는 한 단어, 한 단어 순차적으로 보고 이해하는 것과 같다. 앞선 단어의 기록을 hidden state를 통해 기억하고 있고, 이를 현재의 예측에 활용한다. long-term dependency를 개선하
[NLP] Language Model
LM은 가장 자연스러운 단어 시퀀스를 찾아내는 모델이다. 퇴근 후 공항에 택시를 타고 갔는데, 답승 시간에 늦어서 결국 비행기를 () 앞에 순차적으로 나열된 단어들을 살펴보았을 대 ()에 들어갈 만한 그럴듯한 (likeliness) 단어는? 앞의 단어들의 hist
[NLP] Tokenization과 Embedding
Tokenization Token은 특정 문서에서 연속된 문자들을 의미 있는 인스턴스다. Tokenization은 언어 입력을 토큰과 같은 작은 단위로 나누는 과정이다. Tokenization Level 단어 수준 일반적으로 공백, 구두점을 기준으로 분리하며, 각 단어
[DL] Gradient Descent
Gradient Descent Gradient를 계산하고, Gradient가 가능한 한 작아질 때까지 parameter $\theta$를 반복적으로 조정한다. Chain Rule로 Gradient를 계산하고 기울기의 반대 방향으로 small step 이동하여 param
[DL] Optimizer Function
Optimizer NN이 Loss로부터 어떻게 학습할지 알려준다. Loss Landscape을 직접 알지는 못한다. Argument Learning rate: Optimizer의 step size Momentum: 이전 몇 단계의 개선 방향을 반영해 조금 더 큰 st
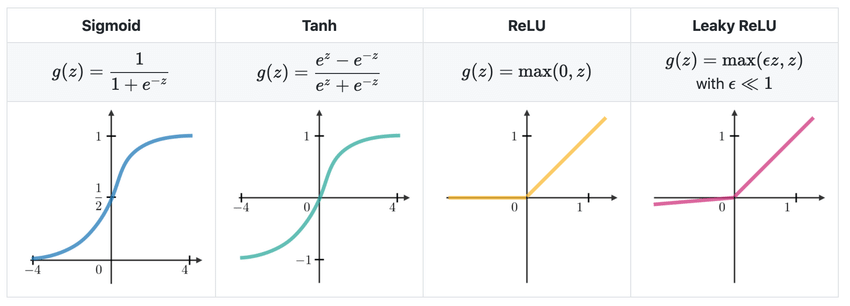
[DL] Activation Function과 Loss Function
Activation Function 각 층에서 비선형 변환(non-linear transformation)을 적용하고, 뉴런이 활성화될지 여부를 결정합니다. 활성화 함수가 없으면 신경망은 단순히 선형 회귀(linear regression) 모델을 쌓아놓은 것과 같습
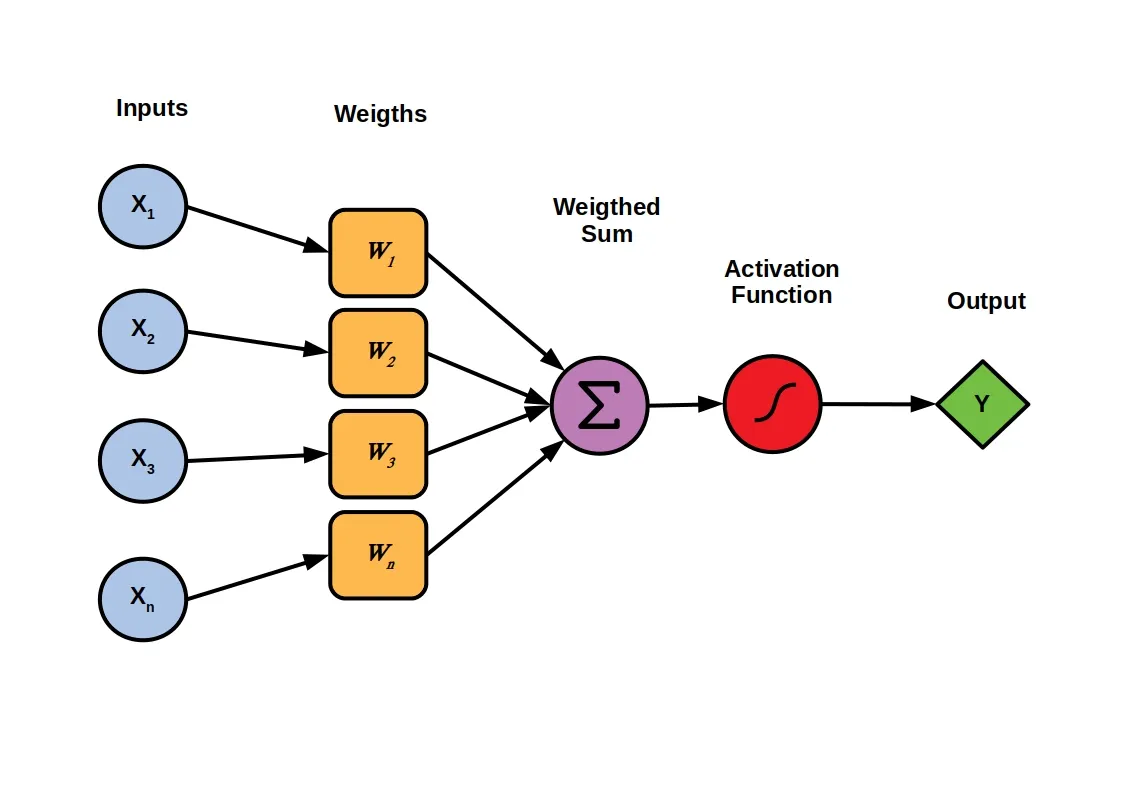
[DL] Neural Network
Neural Network와 Perceptron Neural Network는 인간의 신경 세포 구조에서 영감을 받았다. Perceptron은 Neural Network의 기본 요소로, 각 퍼셉트론은 신경 세포 하나를 나타낸다. 퍼셉트론은 벡터를 입력받아 Weighted
[ML] Regularization
모델이 과도하게 복잡해져 일반화 성능이 떨어지는 문제를 완화하기 위하여 모델의 파라미터나 구조에 인위적을오 패널티를 부과하는 기법이다. Overfitting을 방지하고, 모델 복잡도를 제어한다. LASSO (Least Absolute Shrinkage and Sele
[ML] Linear Regression
Linear Regression Feature와 연속형 결과값 사이의 관계를 설명하는 선형 방정식을 찾는 알고리즘 Input Feature Vector $\mathbf{x}=\left(x1,x2,\dots,x_n\right)$에 대응되는 결과값 $y$가 있을 때, $y
[ML] Logistic Regression
Logistic Function (=Sigmoid Function) 입력된 값에 0과 1 사이 값을 할당한다. $$ y(z)=\frac{1}{1+\exp(-z)} $$ Logistic Regression Feature 변환 Logistic Regression에서 Lo
[ML] Decision Tree
개요 Decision Tree Classifier는 트리 모양의 순차형 다이어그램을 통해 주어진 데이터를 분류한다. 데이터를 기반으로 조건을 자동 생성 및 판단하고, 이를 통해 최종 결과에 이른다. 대표적인 트리 생성 알고리즘에는 CART가 있다. 트리 분할 기본적으
[ML] SVM
개요 SVM (Support Vector Machine)은 클래스 별 데이터를 가장 잘 구분하는 최적의 Hyperplane을 찾는 알고리즘이다. 최적의 하이퍼플레인은 하이퍼플레인에 의해 양분된 두 공간 내에 있는 가장 가까운 데이터 포인트 간의 거리 (Margin)이
[ML] Naïve Bayes
개요 Naïve Bayes는 $n$개의 특성을 지닌 샘플 데이터 $\mathbf{x}$가 주어졌을 때, 이 샘플 데이터가 $K$개의 클래스 $y1, y2, \dots y_k$ 중 하나에 속할 확률을 결정한다. 즉, 각 클래스에 대해 $$ P\left(yk|\mathbf
[Docker] Docker 명령어 실습
이미지 조회 docker search 레지스트리 (Docker Hub)에서 이미지 (ubuntu)를 검색한다. 이미지 다운로드 docker pull 레지스트리 (Docker Hub)에서 이미지 (ubuntu)를 다운로드한다. 태그를 지정하지 않으면 최신 버전
[SpringBoot] JPA Transaction
개요 JPA의 변경 내용 (저장/수정/삭제)은 트랜잭션이 있을 때만 데이터베이스에 안전하게 반영된다. JPA에서는 서비스 계층에서 트랜잭션을 시작하며, Spring은 @Transactional 어노테이션을 사용해 트랜잭션을 자동으로 관리한다. JPA 트랜잭션 Comm
[SpringBoot] JPA Repository
개요 Spring Data JPA가 제공하는 인터페이스로, JPA를 더 쉽게 다루기 위한 추상화 계층이다. 개발자가 데이터베이스에 접근하는 코드 DAO를 직접 구현하지 않고도 데이터베이스를 조작할 수 있도록 하는 인터페이스 기반 프레임워크이다. 주요 메서드 조회 |
[SpringBoot] JPA (Java Persistence API)
개요 RDBMS에 데이터를 CRUD (저장/조회/수정/삭제)할 수 있도록 표준화된 Java의 ORM 프레임워크 > ✏️ ORM (Object-Relational Mapping)? > 객체 지향 프로그래밍 언어와 데이터베이스 간에 데이터를 매핑하는 기술로, 개발자는 S