기본 레이어 이해하기 시리즈
Recurrent
Recurrent는 돌아가다, 회귀하다라는 뜻을 가지고 있다.
프로그래밍적으로는 자기 자신을 참고하는 재귀형 프로그래밍에 사용된다.
이름에서 말하고 있듯이 Recurrent 레이어는 입력 데이터를 참고하여 입력 데이터를 변환한다.
Recurrent 레이어를 사용하여 설계한 대표적인 네트워크가 RNN (Recurrent Neural Network)이다.
순서가 존재하는 데이터
영상, 시계열, 자연어 등의 데이터는 순차적이라는 특징을 갖고 있다. 순차적이라는 것은 순서가 존재한다는 의미이며, 이런 데이터를 시퀀스 데이터 라고 한다.
예를 들어 나는 밥을 먹었다 라는 시퀀스 데이터는 나는, 밥을, 먹었다 순으로 구성돼 있다. 물론 우리는 나는 먹었다 밥을이나 밥을 먹었다 나는처럼 어순을 바꿔 써도 이해할 수 있다.
하지만 컴퓨터에게 예시로 든 세 문장은 서로 다른 데이터로 인식된다. 한국어 자연어 처리는 이런 특징 때문에 굉장히 어려운 편에 속한다.
RNN의 기본 전제는 시퀀스 데이터의 각 요소는 서로 연관성을 가진다는 것이다. 물론 시퀀스 데이터라고 모든 요소끼리 연관이 있다는 보장은 없다. 예를 들어 [오리, 닭, 7, 1, ㄱㄴㄷ] 라는 데이터는 시퀀스 데이터이지만 각 요소끼리 아무 연관이 없다.
하지만 애초에 시퀀스 데이터를 처리하는 목적은 다음 순서에 올 요소를 예측하기 위함이므로, 딥러닝을 통해 처리하는 데이터는 순차적 연관성을 가지고 있다는 전제가 반드시 성립한다.
그렇다면 순차적 연관성을 어떻게 추출할 수 있을까?
줄을 세우자
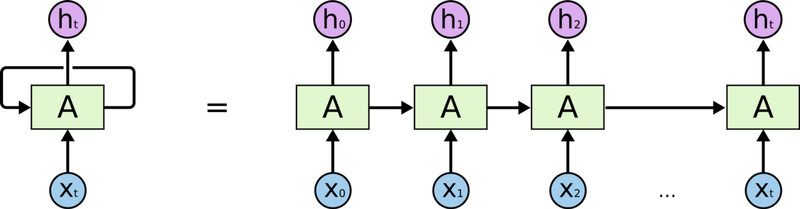
(출처: http://colah.github.io/posts/2015-08-Understanding-LSTMs/)
위 그림을 보면 직관적으로 이해할 수 있다.
먼저 을 입력받아 벡터로 변환한다. 이후 과 벡터를 다시 입력받아 새로운 벡터를 얻는다. 이런 작업을 반복하여 까지 도달하여 최종적으로 벡터 를 출력한다. 이렇게 얻은 벡터는 전체 입력 시퀀스의 벡터 표현이 된다.
여기서 벡터 를 은닉 상태 (hidden state) 또는 은닉 벡터 (hidden vector) 라고 하는데, 연산 과정이 마치 이라는 상태를 라는 상태로 갱신하는 것과 같기 때문이다. (은닉이라는 단어가 붙은 이유는 겉으로 드러나지 않아서 그렇다.)
이상의 과정을 수식으로 보면 다음과 같다.
RNN의 weight의 개수는 입력 시퀀스의 원소 개수와 상관없다는 점을 기억하자. RNN은 (입력의 차원, 출력의 차원) 모양을 갖는 딱 1개의 weight를 갖는다. 단지 해당 weight가 이전 스텝(시점)의 출력 값(hidden state)에 의존할 뿐이다.
과거에 얽매이는 RNN
그런데 이전 스텝의 출력 값을 입력으로 받는다는 것은 반대로 말해 이전 스텝을 연산하기 전까지 현재 스텝을 연산할 수 없다는 것을 의미한다. 즉, 아무리 좋은 하드웨어를 가지고 있어도 한 번에 하나씩 데이터를 처리해야 하므로 속도가 느려지게 된다.
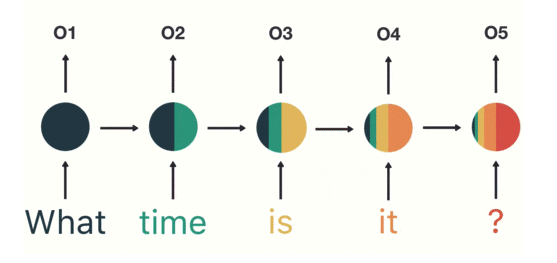
(출처: https://towardsdatascience.com/illustrated-guide-to-recurrent-neural-networks-79e5eb8049c9)
또한 고정된 weight 크기를 가지고 있어 시퀀스 길이에 따라 성능이 들쭉날쭉하게 된다. 특히 시퀀스의 뒤쪽으로 갈 수록, 긴 시퀀스를 처리할 수록 이전 데이터의 영향력이 줄어들어 소실되는 문제가 발생한다. 위 그림을 보면 what의 영향력이 뒤로 갈수록 줄어들고 있는 것을 볼 수 있다. 이를 기울기 소실 (Gradient Vanishing)이라고 한다.
RNN은 바로 이 문제 때문에 긴 시퀀스를 잘 처리하지 못한다는 단점을 가지고 있다. 이 단점 때문에 RNN을 short-term memory라고 부르는데, 이를 개선하여 나온 모델이 LSTM (Long Short Term Memory)과 GRU (Gated Recurrent Unit)이다.
범인은 시그모이드
그런데 사실 기울기 소실이 RNN만의 문제는 아니다. 기울기 소실 문제는 활성화 함수와 밀접한 연관이 있는데, 특히 주요 활성화 함수인 sigmoid 함수와 큰 관계가 있다. 시그모이드 함수의 미분값이 0~0.25이기 때문에 역전파 과정이 길어지면 계속해서 기울기가 줄어들면서 0으로 수렴하게 되는 것이다.
위에서 히든 벡터 를 구하는 과정을 보면 활성화 함수로 를 사용하는 것도 사실 기울기 소실을 방지하기 위한 것이다. 하이퍼볼릭 탄젠트 함수도 기울기 소실을 완전하게 막을 순 없지만, 이것까지 이야기하면 여러 가지 활성화 함수에 대해 다뤄야 하니 지금은 넘어가도록 하겠다.
한 번 만들어 보자
백문이 불여일견, 한 번 간단한 연습 코드를 통해 RNN의 구조와 작동 과정을 살펴보자.
import tensorflow as tf
sentence = "What time is it ?"
dic = {
"is": 0,
"it": 1,
"What": 2,
"time": 3,
"?": 4
}
print("RNN에 입력할 문장:", sentence)
sentence_tensor = tf.constant([[dic[word] for word in sentence.split()]])
print("Embedding을 위해 단어 매핑:", sentence_tensor.numpy())
print("입력 문장 데이터 형태:", sentence_tensor.shape)
embedding_layer = tf.keras.layers.Embedding(input_dim=len(dic), output_dim=100)
emb_out = embedding_layer(sentence_tensor)
print("\nEmbedding 결과:", emb_out.shape)
print("Embedding Layer의 Weight 형태:", embedding_layer.weights[0].shape)
rnn_seq_layer = \
tf.keras.layers.SimpleRNN(units=64, return_sequences=True, use_bias=False)
rnn_seq_out = rnn_seq_layer(emb_out)
print("\nRNN 결과 (모든 Step Output):", rnn_seq_out.shape)
print("RNN Layer의 Weight 형태:", rnn_seq_layer.weights[0].shape)
rnn_fin_layer = tf.keras.layers.SimpleRNN(units=64, use_bias=False)
rnn_fin_out = rnn_fin_layer(emb_out)
print("\nRNN 결과 (최종 Step Output):", rnn_fin_out.shape)
print("RNN Layer의 Weight 형태:", rnn_fin_layer.weights[0].shape)위 코드를 실행하면 다음과 같이 출력된다.
RNN에 입력할 문장: What time is it ?
Embedding을 위해 단어 매핑: [[2 3 0 1 4]]
입력 문장 데이터 형태: (1, 5)
Embedding 결과: (1, 5, 100)
Embedding Layer의 Weight 형태: (5, 100)
RNN 결과 (모든 Step Output): (1, 5, 64)
RNN Layer의 Weight 형태: (100, 64)
RNN 결과 (최종 Step Output): (1, 64)
RNN Layer의 Weight 형태: (100, 64)입력 시퀀스의 임베딩 벡터의 shape가 (1, 5, 100)이고 출력할 데이터의 shape가 (1, 5, 64)이므로 당연히 RNN 레이어의 weight 모양은 (100, 64)가 된다.

👍