
회사가 죽었슴다 ㅡㅡ;
작년부터 이럴거라고 어느정도 예상은 했지만, 인생에 뼈아픈 순간은 언제나 예상을 벗어 나서 찾아오는 것 같다. 11월 급여가 밀리고, 12월을 무급으로 일하면서도 순진하게 회사에서 하는 말을 믿은 내 잘못이 일단 제일 크고, 나쁜 사람은 결국 나쁜 사람이다. 변하지 않
[혼공머신]6주차_mission
미션 기본미션 Q1) 어떤 인공 신경망의 입력 특성이 100개 이고 밀집층에 있는 뉴런 개수가 10개일 때 필요한 모델 파라미터의 개수는 몇 개 인가요? A) 3. 1,010개 ( 100개의 뉴런과 10개의 밀집층 뉴런이 모두 연결되고 출력층의 뉴런마다 하나의 이 있다) Q2) 케라스의 Dense 클래스를 사용해 신경망의 출력층을 만들려고 합니다. 이...
[혼공머신]5주차_mission
초기화: K개의 클러스터를 대표할 중심점을 무작위로 선택한다.할당 : 각 데이터 샘플들을 가장 가까운 중심점에 할당한다. 보통 유클리드 거리같은 거리 측정 방법을 이용하여 가까움을 측정한다.중심점 업데이트 : 클러스터에 속한 데이터 샘플들의 평균위치 값으로 새로운 데이
[혼공머신]5주차(chapter 06)
군집 알고리즘(Clustering Algorithm)은 비지도학습의 대표적인 예로써 서로 비슷한 특성 값을 갖는 데이터 샘플들을 특정한 그룹으로 분류하는 과정을 이야기한다. 300장의 과일 사진이 있을 때, 각 사진이 가지고 있는 픽셀 데이터 값을 기준으로 비슷한 그룹
[혼공머신]4주차_mission
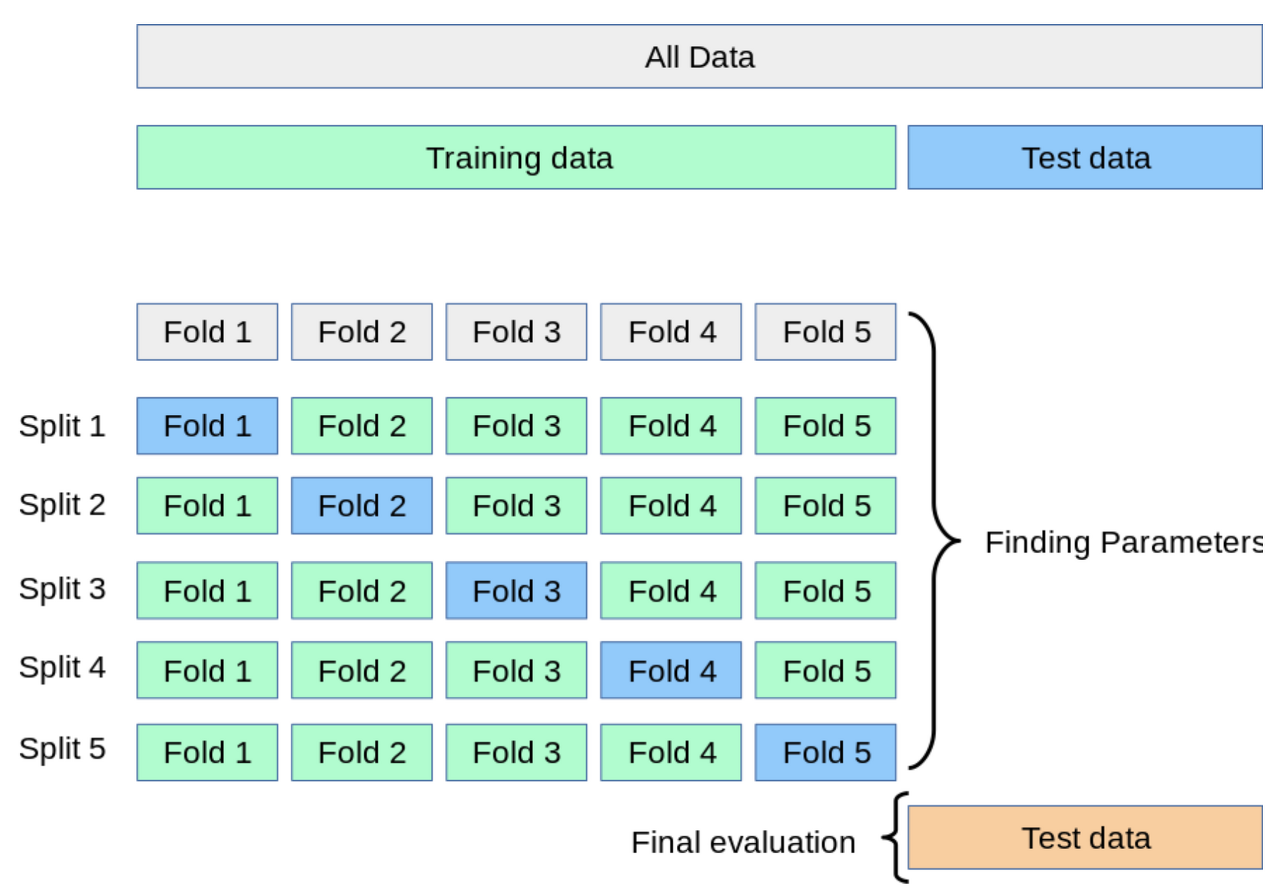
전체 데이터 셋을 Training Data Set와 Test Data Set로 나눈다.Training Data Set을 K개의 Fold로 나눈다.첫번째 Fold를 Validation Set으로 사용하고, 나머지 Fold를 Training Set으로 사용해 훈련하고 평가
[혼공머신]4주차(chapter 05)
5장 01. 결정트리 정의 결정트리(Decision Tree)란 분류와 회귀의 문제를 모두 다룰 수있는 지도 학습 모델이다. 말 그대로 아래 그림과 같은 트리 구조를 이용하여 데이터를 학습하고 최적화 한다. 학습 데이터의 샘플들이 최상위의 루트 노드(root node)
[수학] 미분
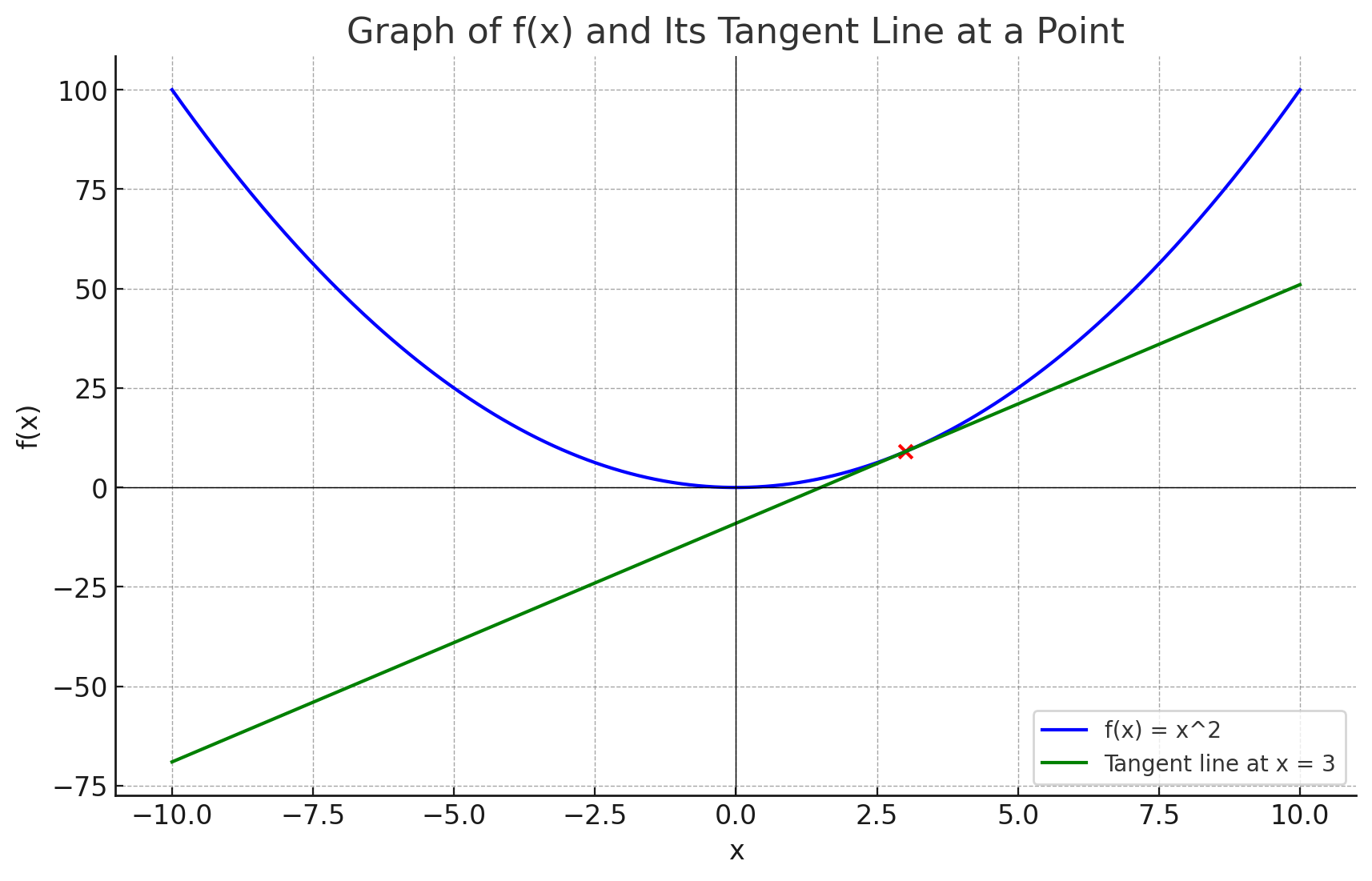
미분(Derivative)이란 어떤 함수의 특정 지점에서의 순간적인 변화율을 이야기 한다. 함수$f(x)$가 어떤 실수 $x$에 대한 변화를 나타낸다고 할 때 $f(x)$의 미분이란 x가 아주 조금 변했을때, $f(x)$가 얼마나 변하는지를 나타내는 것이 미분이다. 쉽
[수학] 미분에 대해 정리하려다가
미분 나는 수학을 잘 모른다. 수학을 좋아했던 기억은 있다. 초등학교 입학도 전 학습지에서 수도 없이 따라 써야만 했던 한글과 한자등과 다르게, 숫자만 적으면 빠르게 끝나서 좋아했었다. 음, 중학교 때 어떤 경험에 의해 나는 수포자의 길로 들어섰고 심지어 수능시험에도
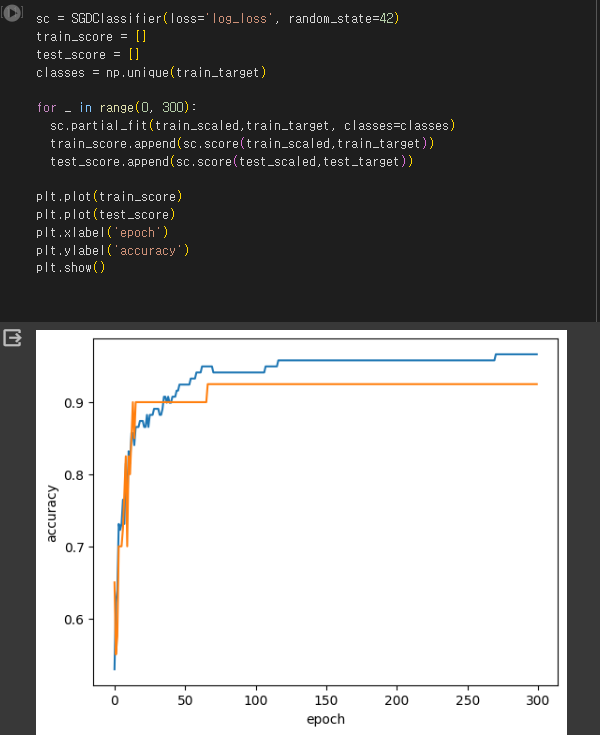
[혼공머신]3주차(chapter 04)
4장 로지스틱 회귀 정의 로지스틱 회귀(Logistic Regression)란 사건의 발생 가능 성을 예측하는 데 사용되는 확률모델로써, 일반적인 회귀분석과 마찬가지로 입력된 데이터(독립변수) 간의 관계를 이용해서 값(종속변수)을 예측하는 방법이다. 선형회귀와
[수학] 로그
로그(log:logarithm)란 지수(Power)를 다른 방법으로 표현한것이다. 예를 들어 $2^4 = 16$ 라는 방정식이 있을 때 $2$는 밑, $4$를 지수, 16을 값이라고 읽고 "2를 4번 제곱하면 16이라는 값이 나온다" 라고 설명할 수 있을 것이다. 이
[혼공머신]2주차_mission
미션 모델 파라미터란? 개념 머신러닝, 특히 딥러닝에서 주어진 데이터를 학습할때 작동하는 모델 내부의 변수를 의미한다. 데이터의 종류, 패턴에 따라 추가하거나 조정되며 최적화를 진행하게 된다. 파라미터의 수, 그리고 값에 설정은 모델의 학습 능력을 결정하는 중요한 요
[혼공머신]2주차(chapter 03)
3장 회귀 (regression) 정의 회귀라는 단어는 프랜시스 골턴이라는 사람이 유전학을 연구하던 도중 아버지의 키에 따라 아들의 키가 결정되는 경향이 있지만 세대가 지나면서 키가 작은 아버지의 아들은 물론 키가 작지만 아버지보다는 커지고, 키가 큰 아버지의 아
[혼공머신]1주차_extra(chapter 02-2)
K-최근접 이웃 모델로 길이, 무게 데이터로 이웃을 판단할때 두 특성간의 스케일 차이로 인해 올바른 예측이 불가능하다. 이 모델은 그래프상 기준 위치의 값과 가까운 데이터들의 많음이 어떠냐에 따라 정답을 예측하는데 무게의 기준값의 범위가 0 - 1,000g, 길이의 경
[수학] 표준편차
자료의 값들이 얼마나 흩어져 있는지를 하나의 수치로 나타내는 방법. "Standard Deviation" 약어로는 SD 또는 StDev라고 쓴다. 관찰값들이 얼마나 떨어져있는지 수치로 나타내는 방법이다. 이것을 산포도라고 한다. 간단하게 생각해보면 어떤 데이터의 집단이
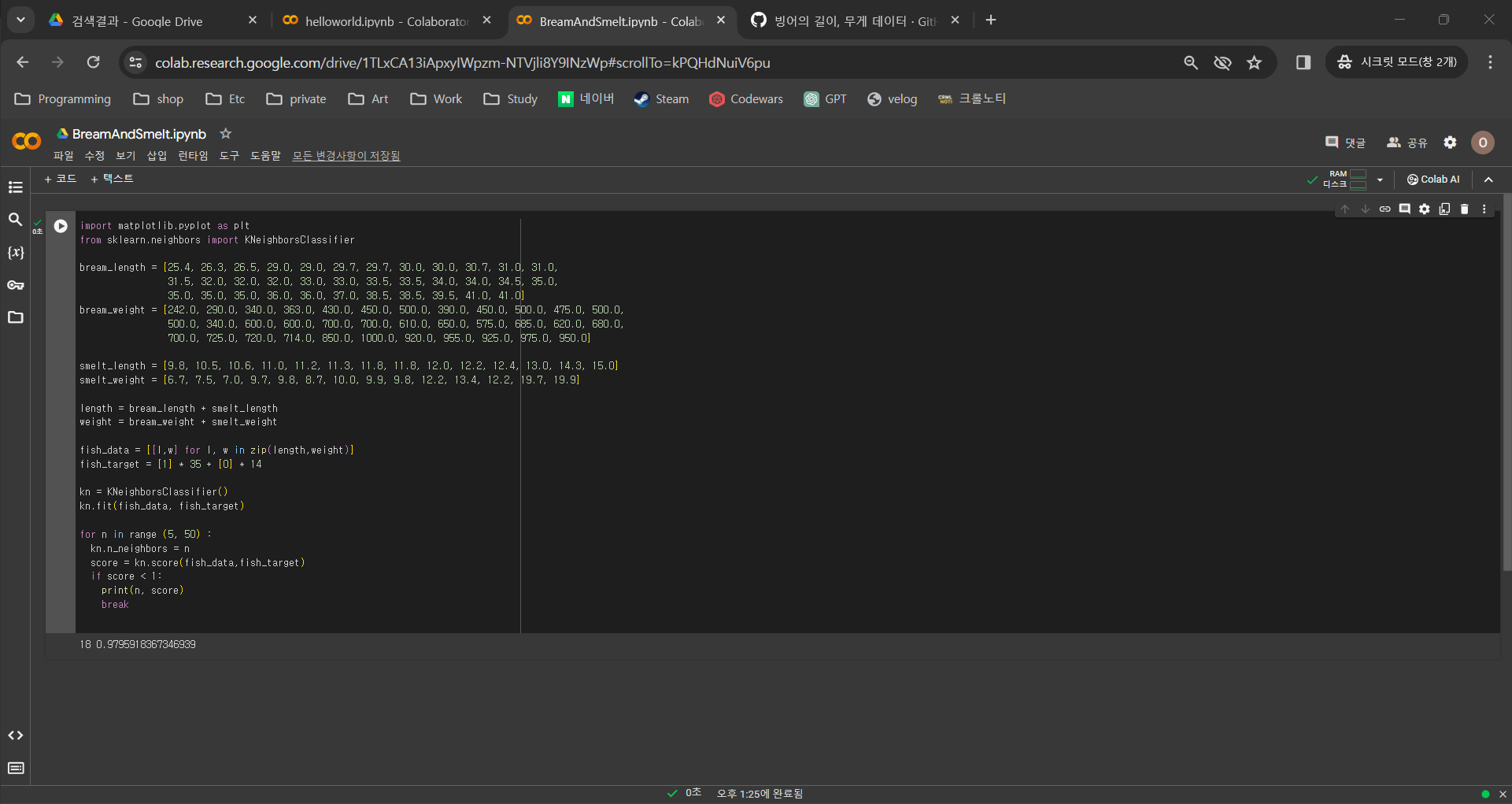
[혼공머신]1주차(chapter 01~02)
"인간처럼 학습하고 추론할 수 있는 컴퓨터 시스템을 만드는 기술"실직적인 역사는 80년정도 되었으며, 사실상 전자식 컴퓨터의 역사와 발을 맞추어 왔다고 생각해도 별 문제는 없을것 같다.컴퓨팅 성능의 한계, 전문가 시스템 붐의 거품 붕괴라는 이유로두번의 겨울을 겪었지만,