한화시스템 BEYOND SW 캠프_20기
1.한화시스템 BEYOND SW 캠프 20기 시작
내일이면 드디어 부트캠프 시작일이다. 긴장도 되고 약간 설레기도 한다.부트캠프를 시작하면서, 앞으로 부트캠프에서 배운것들과 느낀점들을 블로그로 정리할려고 한다.블로그는 거의 작성해본적이 없어 많이 부족할 수 있지만, 꾸준히 작성하여 실력을 늘려가고!\[] 싶다.부트캠프
2.한화 SW 캠프 1일차 개념정리
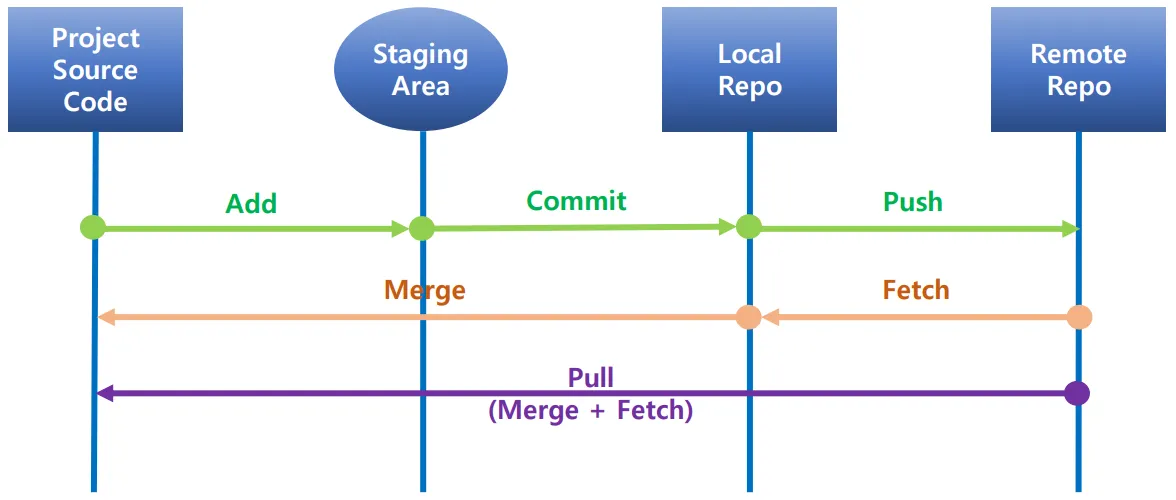
파일의 변경 이력을 관리하고 협업을 효율적으로 지원하는 도구브랜치: 개발의 다양한 단계나 기능을 분리하여 관리할 수 있다. 이를 통해 여러 기능을 동시에 개발하고 통합하는 것이 용이하다.협업: 여러 개발자가 동일한 프로젝트에서 병렬로 작업할 수 있게 지원한다.Proj
3.한화 SW 캠프 2일차 개념정리
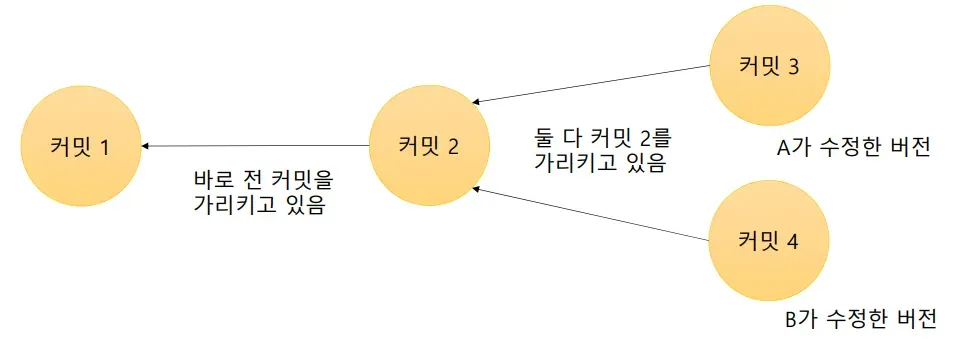
특정 기준에서 줄기를 나누어 작업할 수 있는 기능을 브랜치라고 하며 브랜치를 만들지 않고 A, B가둘 다 커밋 2을 기준으로 커밋을 만들려고 한다면 오류가 나게 된다.Git이 제공하는 기본적인 브랜치. 첫 번째 커밋을 하면 자동으로 master라는 이름의 브랜치가 커밋
4.GitHub 협업 연습
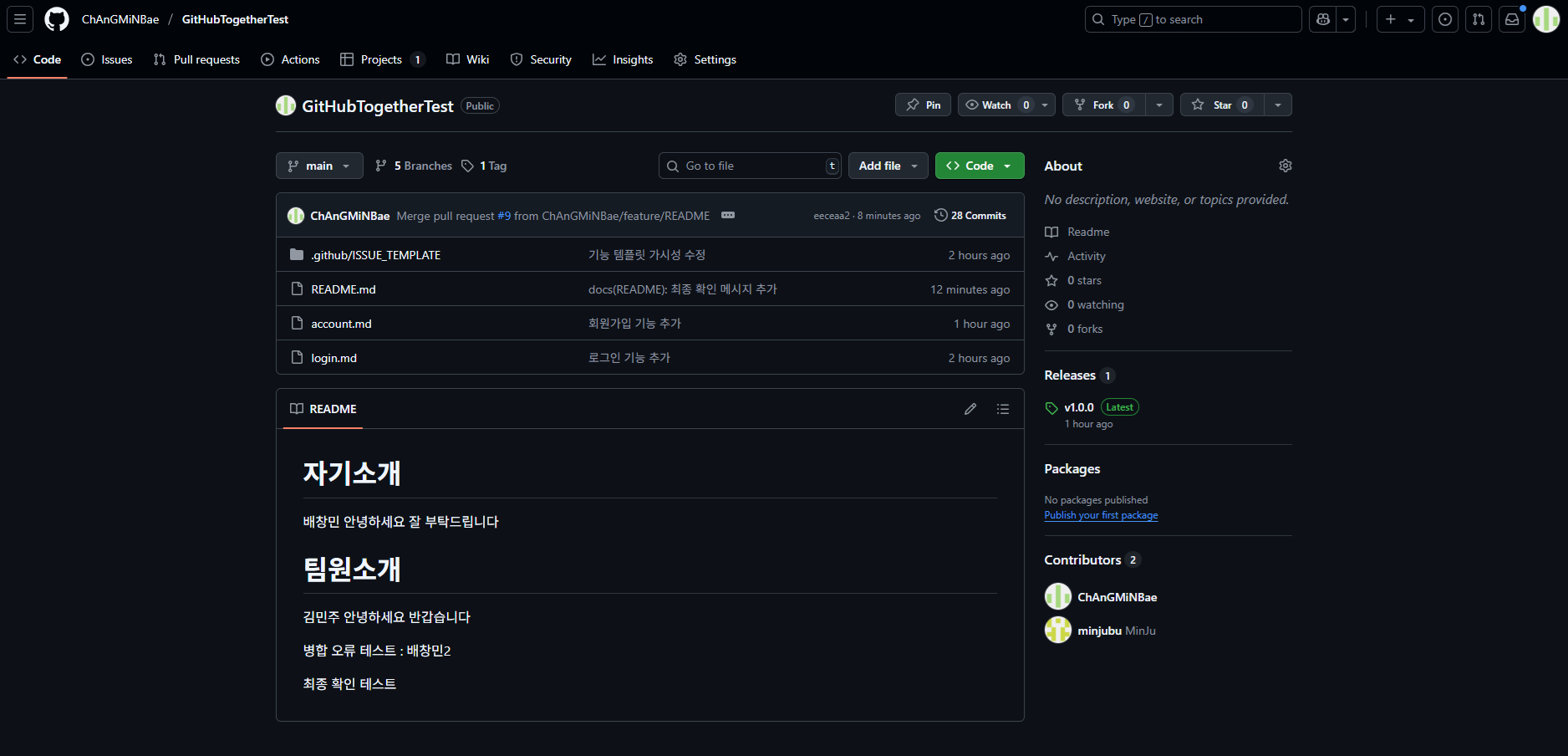
오늘은 저장소 생성 → 팀원 초대 → 협업 규칙 적용까지 GitHub의 기본 협업 흐름을 실제로 따라 해 보았다. 간단한 실습이었지만, 프로젝트를 진행할 때 필수로 쓰이는 기능들을 손에 익히기에 충분했다.Repository 생성: 새 저장소를 만들고 프로젝트 기본 구조
5.BEYOND SW 캠프 20기 1주차

혼자 준비하면서 기본기를 다지기는 했지만, 실제 협업 경험이나 체계적인 학습 과정이 부족하다고 느꼈다. 그러던 중 한화시스템에서 운영하는 BEYOND SW CAMP를 알게 되었고, 커리큘럼과 프로젝트 중심 학습이 매력적으로 다가왔다. 단순한 기술 학습을 넘어서 개발자로
6.[SW공학] 소프트웨어 개발 프로세스

(컴퓨터) 프로그램: 컴퓨터 명령어가 나열된 원시 코드(source code)소프트웨어: 컴퓨터에서 실행되는 모든 종류의 프로그램을 포함하는 넓은 개념이다. 하드웨어와 대조되는 개념으로, 물리적 장치가 아닌 데이터와 프로그램의 집합을 의미한다.시스템 소프트웨어 (Sys
7.[SW공학] 요구사항

정의: 사용자가 시스템에서 기대하는 기능, 서비스, 조건을 명시한 것. 프로젝트의 기초이자 개발 지침 역할.목적프로젝트 목표와 범위 명확화이해관계자 간 의사소통 원활화종류기능적 요구사항: 시스템이 수행해야 하는 기능 (예: 로그인, 결제)비기능적 요구사항: 시스템이 어
8.[SW공학] UML

UML(Unified Modeling Language) 1. 모델링과 UML 개요 모델링(Modeling) 현실 세계를 단순화해 표현하는 기법. 소프트웨어 개발 프로세스의 요구사항 분석 → 설계 → 구현 단계에서 주로 사용된다. UML (Unified Mo
9.[DB] DataBase

Data: 관찰의 결과로 나타난 실제 값예) 에베레스트의 높이: 8848mInformation: 데이터에 의미를 부여한 것예) 에베레스트는 세계에서 가장 높은 산이다.정의: 여러 응용 시스템이 공용할 수 있도록 논리적으로 연관된 데이터를 모아 중복을 최소화해 구조적으로
10.[DB] SQL 기초 (1)

테이블에서 원하는 데이터를 조회할 때 사용결과 집합을 정렬할 때 사용조건을 설정해 원하는 레코드만 조회중복 제거두 개 이상의 테이블을 연결그룹별 집계쿼리 안에서 또 다른 쿼리 사용
11.[DB]SQL 기초(2)

UNION : 중복 제거 후 결합UNION ALL : 중복 제거 없이 모두 결합INTERSECT : 공통된 레코드만 (MySQL은 기본 미지원 → INNER JOIN 또는 IN 활용)MINUS : 첫 SELECT - 두 번째 SELECT (MySQL 미지원 → LEFT
12.[DB] SQL 기초(3)

코드/길이ASCII(str), CHAR(n)BIT_LENGTH(str), CHAR_LENGTH(str), LENGTH(str)결합CONCAT(a,b,...), CONCAT_WS(delim, a,b,...)검색/위치ELT(pos, ...), FIELD(str, ...),
13.[DB] SQL 기초(4)

서버에 일련의 SQL을 저장해 반복 작업 자동화·네트워크 왕복 감소.변수/조건/반복/예외처리 지원. 권한 분리·보안에 유리.IN: 호출 시 전달 → 내부에서 사용OUT: 프로시저가 값을 반환 → @user_var로 받기INOUT: 전달받은 값을 수정해 다시 반환DELI
14.BEYOND SW 캠프 20기 2주차

2주차 회고록 1. 2주차를 시작하며 1주차가 맛보기 였다면, 2주차는 주요 개념을 익히며 제대로된 공부를 시작하는 주였다. 배울때마다 헷갈리는 개념(UML)과 손으로 익혀야 하는 기술(SQL), 그리고 시험(PCCE), 팀 결성, 스프링 예습 등등 할 일이 많았고
15.[DB] DB 모델링(1)

큰 다리는 설계도가 필수: 현실을 단순·정확하게 표현해야 구현 가능효과: 의사소통, 시뮬레이션, 문제해결, 핵심파악, 교육·훈련, 연구·개발 모두에 유용모델링 3요소단순화: 목적에 맞는 것만 선택추상화: 공통 형식으로 묶어 표현명확화: 애매함 제거, 누구나 이해 가능하
16.[DB] DB 모델링 (2)

정의: 요구분석에서 핵심 엔터티/주요 속성/엔터티 간 관계를 도출해 상위 수준 ERD로 표현. 데이터의 범위·구조를 빠르게 파악하기 위한 단계.& 목적: 사용자·개발자·모델러 등 이해관계자가 같은 그림을 보도록 데이터를 간결하게 표현; 대규모 프로젝트의 큰 틀, 이후
17.[DB] 도서 대여 시스템 : 업무 규칙을 고려한 개발

도서 대여 시스템은 사용자가 도서를 대여하고 반납하는 기능을 제공하는 시스템이다. 또한, 대여 기록 관리, 벌금 부과 및 납부 처리 등의 기능을 포함한다.사용자는 관리자(admin)와 일반 사용자(user)로 구분된다.사용자 계정을 생성하고, 이메일을 통한 인증을 수행
18.[Linux] 리눅스 기본(1)

아이콘/창/버튼 등 그래픽으로 조작 (Windows, macOS, GNOME/KDE).직관적·학습 곡선 낮음.명령어로 조작 (Windows CMD/PowerShell, macOS/Linux 터미널, Git, Python REPL).자동화/스크립팅/원격관리에 강력.사용자
19.BEYOND SW 캠프 20기 3주차

3주차는 DB 모델링과 리눅스 기본을 본격적으로 손에 붙이는 주였다. 여기에 스프링 예습과 일일 코딩 문제, 그리고 기반 기술 프로젝트(야구 통합 커뮤니티) 진행까지 바쁜 한주였다.모델링 핵심 재정리목적에 맞게 단순화/추상화/명확화무결성(엔터티/참조/도메인/업무)과 정
20.[Linux] 쉘 설정·스크립트 & MariaDB(설치·원격접속·복제)

~/.bashrc : 인터랙티브 셸(일반 터미널) 설정~/.bash_profile : 로그인 셸 설정VirtualBox 네트워크: NAT → 브리지IP 확인 & 방화벽복제 계정 권한binlog 위치 확인(메모!)서버 설정 파일 수정(고유 server-id) → 재시작M
21.[Java] 변수

리터럴: 변하지 않는 “값 자체”.상수는 값을 담는 메모리 공간(식별자), 리터럴은 그 공간에 들어가는 “고정 값”.숫자: 정수±정수=정수, 정수±실수=실수문자: 내부적으로 정수(유니코드)로 계산 가능System.out.println('a' + 1); // 98문자열:
22.[Java] 연산자 · 메소드와 API

연산자(operator): 계산에 쓰는 기호(+, -, …)피연산자(operand): 연산되는 데이터(값/변수)우선순위: 단항 > 산술(\*/%) > 산술(+ -) > 비교 > 논리 AND(&&) > 논리 OR(||) > 대입(=)괄호 ()가 최고 우선순위.단락 평가:
23.BEYOND SW 캠프 20기 4주차

이번 주는 리눅스 셸 설정/스크립트와 MariaDB(원격·복제)를 간단히 훑고, 자바 기초(리터럴/변수/연산자/메소드·API)를 학습했다. 주중엔 프로젝트(야구 통합 커뮤니티) 발표를 무사히 마치며 마무리까지 진행했다.초기화 파일: ~/.bashrc(인터랙티브), ~/
24.BEYOND SW 캠프 20기 8월 회고록

벌써 한화 SW 캠프에 참여한 지 한 달이 다 되어간다. 프로젝트를 진행하니 정말 시간이 훅훅 지나간다.이번 월간 회고록은 마침 프로젝트도 끝난 김에, 프로젝트 중심으로 정리해본다.유형: DB 기반 프로젝트팀명: 한화 데몬 헌터스인원: 5명분위기: 처음엔 어색했지만,
25.[Java] 제어문

조건식의 결과(boolean)에 따라 코드 실행 흐름을 제어.종류: if, if-else, if-else if, switch예제 (짝수 판단)예제 (학점 분기 – 개선형)정수/문자/문자열만 비교(실수·논리 X), 동등 비교만 가능(대소 비교 X).break를 넣지 않으
26.[Java] 배열

같은 자료형 값들의 연속 메모리 묶음.new 로 heap에 생성, 길이는 고정, 0부터 인덱스로 접근.변수 난립 방지, 반복문과 찰떡. 합계/검색/집계에 유리.정수: 0, 실수: 0.0, 논리: false, 문자: '\\u0000', 참조: nullarr == null
27.[Java] 클래스와 객체

서로 다른 타입의 필드+메소드를 묶어 만든 사용자 정의 자료형.객체(인스턴스)는 클래스 설계도로부터 new로 생성.변수명 난립, 메소드 인자 과다, 서로 다른 타입을 한 번에 반환 불가.필드 직접 접근 시 유효성 통제 불가, 변경 전파 큼(결합도 ↑).필드 privat
28.[Java] 상속 · 다형성

부모 클래스의 필드/메소드를 자식이 물려받아 사용(생성자는 상속 X).단일 상속만 지원.부모의 타입도 상속되어 다형성의 토대가 됨.메소드명/리턴타입/매개변수(타입·개수·순서) 모두 동일private·final 메소드는 불가접근 제어자는 같거나 더 넓게예외는 같거나 더
29.[Java] 자주 쓰는 API

모든 클래스의 최상위 부모.주요 메소드는 하위 클래스에서 오버라이딩해서 의미 있게 사용.동일성(==) vs 동등성(equals) 구분.재정의 시 규약: 반사성/대칭성/추이성/일관성/null과 비교 시 false.구현 팁(간단형):equals가 true면 hashCode
30.BEYOND SW 캠프 20기 5주차

지난주와 마찬가지로 이번주도 자바 기초를 제어문 → 배열 → 객체지향(클래스/상속/다형성) → 필수 API 순으로 한 번에 묶어 복습·정리했다. 또 외부 공모전 제 15회 이루다 프로젝트 준비를 새로 시작했다.if/switch: switch의 문자열/enum 분기, f
31.[Java] 예외 처리 & 입출력(IO)

오류(Error): 시스템 수준의 치명적 문제 → 코드로 복구 불가 (예: JVM 오류, 하드웨어 문제)예외(Exception): 예상 가능한 비정상 상황 → 코드로 처리 가능사용자 경험 보호(비정상 종료 방지), 안정성↑ / 신뢰성↑원인·위치 파악 쉬워 디버깅 효율↑
32.[Java] 제네릭스 & 컬렉션

“타입을 일반화”하여 하나의 클래스/메소드로 다양한 타입을 안전하게 다룸.타입 안정성(컴파일 타임 체크) + 중복 코드 제거.<?> : 모든 타입 허용<? extends T> : T 또는 하위 타입만<? super T> : T 또는 상위 타입만기억법:
33.[Java] Map · enum · 람다

Map: 키(Key) - 값(Value) 쌍 저장. 키 중복 X, 값 중복 O.대표 구현체: HashMap, Hashtable, TreeMap.해시 테이블 기반 → 검색/조회 빠름.키 중복 시 덮어씀, 값 중복 가능.(String, String) 전용 해시 테이블.환경
34.[Java] Stream & Thread

컬렉션/배열의 요소를 선언형으로 순회·가공·축약하는 API (Java 8+).내부 반복자 기반 → 병렬 처리 용이.for/iterator 대비 코드 간결, 조합 가능, 병렬 스트림으로 성능 향상 여지.원본 불변(읽기 전용)1회성(필요 시 재생성)지연 연산(최종 연산 전
35.[Java] SOLID 원칙

유지보수성: 수정이 쉬운가확장성: 기존 코드 변경 없이 기능 추가 가능한가응집도: 모듈이 한 가지 일에 집중하는가결합도: 모듈 간 의존이 낮은가유연성: 요구 변화에 잘 적응하는가한 클래스는 하나의 책임만 가져야 한다. (변경 이유는 단 하나) 위반 적용체크리스트변경 이
36.[Java] JUnit

핵심: JUnit은 자바 단위 테스트 표준 프레임워크.초기 버그를 빠르게 잡고, TDD(테스트 주도 개발)를 실천하는 데 필수 도구정의: 자바용 단위 테스트 프레임워크. Kent Beck & Erich Gamma 개발.목적: 작은 단위(메서드/컴포넌트)별로 독립 테스트
37.BEYOND SW 캠프 20기 6주차

이번 주는 자바 심화 내용을 예외처리\\&IO → 제네릭스&컬렉션 → Enum&람다 → 스트림&스레드 → SOLID → JUnit까지 한 번에 훑었다. 팀 단위로는 피우다 프로젝트 신청서를 작성하고 기본 UI 뼈대를 잡기 시작했다. 공모전 대비로 스프링 스터디(김영한
38.[자료구조]복잡도&List/Stack/Queue/Deque

장점구현 간단, 인덱스 접근 O(1), 메모리 연속 → 순차 접근 빠름단점크기 고정, 중간 삽입/삭제 O(n), 크기 여유분에 따른 메모리 낭비앞에서부터 차례로 비교시간 복잡도: 최선 O(1) / 최악 O(n)장점: 구현 매우 단순, 정렬 불필요단점: 데이터가 클수록
39.[자료구조] 트리·힙·그래프

계층형 자료구조 — 노드가 부모-자식 관계를 이룸이진 트리: 각 노드 최대 2자식BST(이진 탐색 트리): 왼쪽 < 루트 < 오른쪽레드-블랙 트리: 색(RED/BLACK)로 균형 유지규칙 요약: 루트=BLACK, RED의 자식은 모두 BLACK, 모든 경로의
40.[알고리즘] Sort

용어 한 줄 요약제자리 정렬: 추가 메모리 거의 없음(스택/소량의 보조 배열 제외).안정 정렬: 동일 키의 상대적 순서가 유지됨(예: 정렬 후에도 같은 값끼리 입력 순서 그대로).Dual-Pivot QuickSort 사용연속 메모리 + 빠른 스왑 → 제자리로 매우 효율
41.[알고리즘] DFS/BFS

좌표 (x, y) 를 2차원 배열에 담을 때는 보통 map\[y]\[x] 로 접근한다.최단거리/단계적 탐색은 BFS, 모든 경로/조합·백트래킹은 DFS가 자연스럽다.가로(x) 증가: → 오른쪽세로(y) 증가: ↑ 위쪽가로(col) 증가: → 오른쪽세로(row) 증가:
42.[알고리즘] Greedy

한 순간 최선(탐욕) 선택이 전체 최적해로 이어진다고 가정하고 푸는 방법.성립 조건:탐욕 선택 속성(현 시점 최선이 전체 최선으로 확장 가능)최적 부분 구조(부분 문제의 최적해로 전체 최적해 구성)동전 거스름: 큰 동전부터(단, 한국 화폐처럼 특정 체계에서만 성립)회의
43.BEYOND SW 캠프 20기 7주차

수업이 본격적으로 알고리즘 파트에 들어왔다. 초반엔 익숙한 개념도 있었지만, 뒤로 갈수록 난이도가 확 올라간다. 한 주 동안 자료구조(복잡도/리스트/스택/큐/덱 → 트리/힙/그래프)와 알고리즘(정렬 → DFS/BFS → 그리디)를 쭉 훑었고, 팀에서는 피우다 프로젝트
44.BEYOND SW 캠프 20기 9월 회고록

9월은 넓게 배운 걸 연결하는 연습의 달이었다.개념은 쌓였는데 손은 더뎠고, 그래서 더 많이 느꼈다. 아는 것과 풀어내는 것 사이엔 여전히 거리가 있다. 그 간격을 메우는 게 이번 달의 목표였던것 같다.수업: 자료구조/알고리즘 풀코스 — 복잡도·리스트·스택/큐/덱 →
45.[Spring] JDBC

jdbc-config.properties로드 & 연결설정을 분리하면 오타/중복/유지보수 비용을 줄일 수 있습니다.반드시 사용 후 반납중복되는 연결/반납 코드는 템플릿 유틸로 공통화실무/과제에서는 try-with-resources가 더 깔끔합니다.장점속도: 한 번 파싱/
46.[Spring] Servlet LifeCycle

Servlet = Server + AppletJava로 작성된 서버 측 동적 웹 컴포넌트. 클라이언트 요청을 받아 처리하고 응답을 생성. 톰캣 같은 Servlet 컨테이너가 생명주기를 관리.2.5 (Java EE 5): @WebServlet 등 애노테이션 설정 도입3.
47.[Spring] Servlet Method

브라우저는 요청/응답을 바이트 스트림으로 주고받고, 서버(Tomcat)가 이를 파싱해 Servlet의 service() → doGet/doPost()를 호출.HTML <form method="get|post"> 의 method에 따라 컨테이너가 doGet() 또는
48.[Spring] Session & Cookie

목표: HTTP의 무상태(stateless) 한계를 보완하는 Cookie(클라이언트 저장) · Session(서버 저장) 를 빠르게 정리무연결/무상태: 요청-응답 후 연결 종료, 상태(로그인/장바구니 등) 유지 불가→ 클라이언트에 저장(Cookie) 또는 서버에 저장(
49.[Spring] Filter & Wrapper

목표: 공통 로직(인코딩/보안/로깅 등)을 Filter로, 요청/응답 객체를 변형해야 하면 Wrapper로.javax.servlet.Filter 구현 클래스.요청/응답을 서블릿 전·후로 가로채서 가공(보안, 인코딩, 로깅, 압축, 리소스 접근 제어 등).여러 개를 체인
50.[Spring] IoC Container

IoC (제어의 역전)객체 생성/초기화/의존성 연결 등의 제어를 애플리케이션이 아닌 프레임워크가 맡는 패턴. 스프링은 이 IoC를 통해 빈(객체)을 자동 관리한다. IoC 컨테이너IoC를 구현한 프레임워크. 스프링에선 ApplicationContext(=고급 컨테이너)
51.추석 연휴 회고

긴 연휴 동안 김영한 스프링 MVC 강의를 예습과 복습을 겸하여서 들었다. 서블릿에서 시작해 JSP와 MVC, 프론트 컨트롤러, 스프링 MVC 구조까지 한 흐름으로 연결해 보았다.DriverManager로 드라이버 로딩과 연결 생성한다.Connection에서 State
52.BEYOND SW 캠프 20기 8주차

8주차는 웹 백엔드 기초를 체계적으로 정리했다. JDBC로 시작해 서블릿과 HTTP 흐름, 세션과 쿠키, 필터와 래퍼, 마지막으로 스프링 IoC 컨테이너까지 학습 범위를 확장했다. 개념을 연결해 동작 흐름을 이해하는 데 집중했다.또한, 준비하고 있는 공모전 예선에서 다
53.[Spring] DI

스프링 컨테이너가 의존 관계를 자동 연결해 객체 간 결합도를 낮추는 핵심 메커니즘정의: 객체가 사용할 의존 객체를 직접 생성하지 않고, 컨테이너가 주입한다.효과: 구체 클래스 의존을 줄여 유지보수성·테스트 용이성·확장성 향상.포인트: 필드는 상위 타입(인터페이스/추상)
54.[Spring] DI Annotation

의존성 주입(DI) 은 객체 생성·연결 제어를 컨테이너가 담당해 결합도를 낮춘다. 스프링에선 ApplicationContext 가 빈을 찾아 주입한다. 주입 방식필드 주입: 간단하지만 테스트/불변성에 약함.생성자 주입(권장): 의존성 보장, 불변성 확보, 테스트 용이.
55.[Spring] Bean

공통 예제: Product(추상), Beverage, Bread, ShoppingCartShoppingCart는 내부에 List<Product>를 보유하고 addItem()으로 담는 구조. singleton은 메모리 절감 및 공유에 유리, prototype은 독립
56.[Spring] AOP

관점 지향 프로그래밍으로 중복되는 공통 로직을 분리하고, 메소드 실행 전·후·예외 시점에 주입해 코드 중복을 줄이는 기술Aspect: 횡단 관심사(로깅, 트랜잭션 등)의 묶음Advice: 적용 시점별 실행 로직(Before/After/Around 등)Join point
57.[Spring] Request Mapping
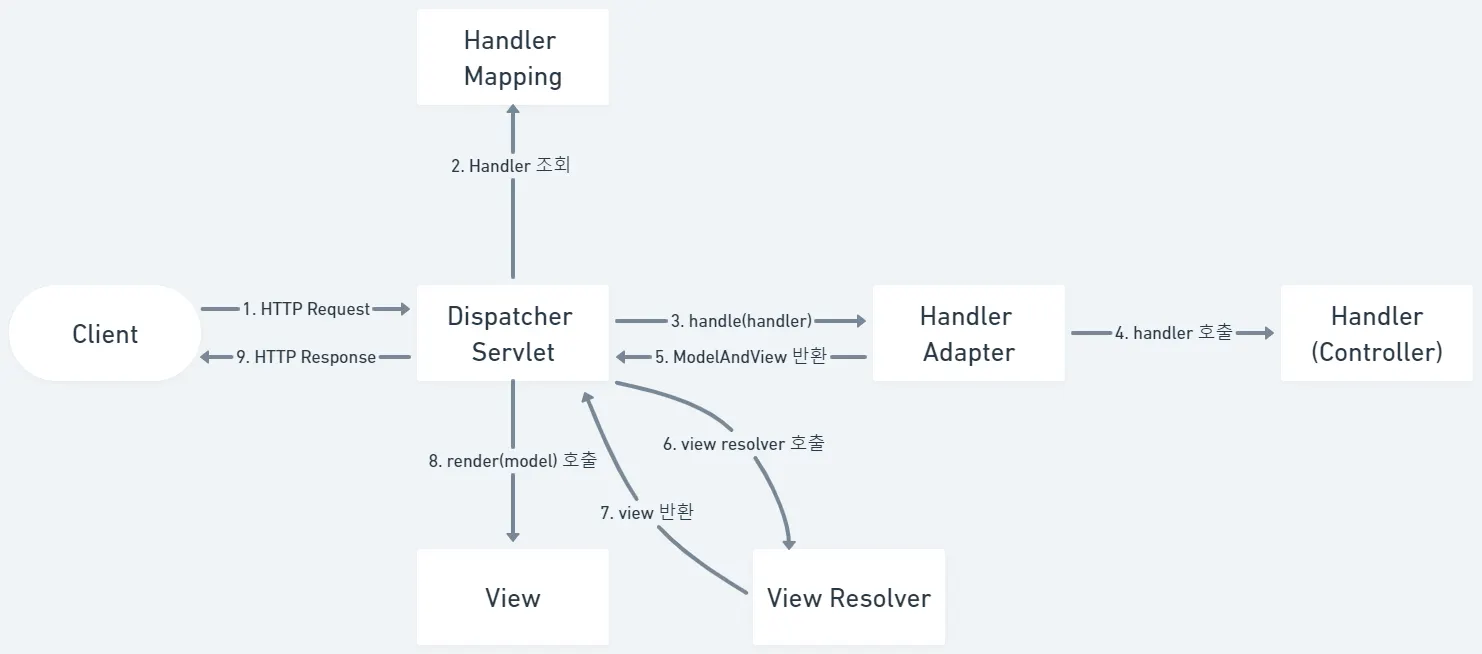
Spring Web MVC는 요청 → 컨트롤러 → 서비스/DAO → 모델 → 뷰 흐름을 표준화하고, DI 컨테이너가 레이어 간 의존을 관리해 유연한 웹 애플리케이션을 구성한다.Controller: 요청 수신, 파라미터 가공, 서비스 호출, Model 구성 후 뷰로 전달
58.[Spring] Handler Method

요청을 컨트롤러 메서드로 보낼 때, 메서드 시그니처에 선언한 타입/어노테이션에 따라 스프링이 알맞은 값을 자동 주입한다.포인트서블릿 API에 종속되지 않는 요청 추상화.간단 파라미터 읽기와 모델 조합에 적합.여러 파라미터 한 번에포인트기본값 미지정 + 누락 시 400
59.[Spring] View Resolver

요청을 처리한 컨트롤러가 논리 뷰 이름을 반환하면 DispatcherServlet → ViewResolver → View 순서로 화면 렌더링이 진행된다. 스프링은 전략 패턴으로 다양한 뷰 리졸버를 제공한다.InternalResourceViewResolverJSP/서블릿
60.[Spring] Exception Handler

스프링 MVC는 컨트롤러에서 발생한 예외를 DispatcherServlet → HandlerExceptionResolver 체인으로 위임해 처리한다. 상황에 맞는 전략을 선택해 화면 응답, 상태 코드 지정, 전역 처리를 구현할 수 있다.여러 Resolver가 함께 등록
61.[Spring] Interceptor

스프링 인터셉터는 컨트롤러 앞뒤의 공통 로직을 끼워 넣는 장치다. URL 패턴별로 적용할 수 있고, 스프링 빈 주입이 가능해 필터보다 애플리케이션 레벨의 협업이 쉽다.역할: 요청을 가로채 전처리, 후처리, 완료 콜백 수행장점URL 패턴 매핑 가능스프링 컨텍스트 접근(D
62.[Spring] MyBatis Configuration

역할: DB 접속/트랜잭션/데이터소스 환경을 담는 객체생성트랜잭션 매니저JdbcTransactionFactory: 코드로 commit/rollback 제어(권장)ManagedTransactionFactory: 컨테이너가 관리(자동 커밋)DataSourcePooledDa
63.[Spring] MyBatis Dynamic Query

DAO 다중 호출, 배치 없이 XML 태그/Provider API로 SQL을 동적 생성.자주 쓰는 XML 태그: if, choose(when, otherwise), trim(where, set), foreach, bind.자바 기반 동적 쿼리: @SelectProvid
64.BEYOND SW 캠프 20기 9주차

이번 주는 스프링 웹 애플리케이션의 기반을 전반적으로 다졌다. DI와 빈 관리, AOP를 정리하고 스프링 MVC의 요청 매핑과 핸들러 메서드, 뷰 리졸버, 예외 처리, 인터셉터까지 흐름을 연결했다. 데이터 접근에서는 MyBatis 설정과 동적 쿼리를 실습했다.피우다 프
65.[Spring] Spring MyBatis

mybatis-spring 문서자동 구성실행 시 매퍼 스캔, SqlSessionFactory, SqlSessionTemplate을 자동 등록장점설정 최소화, 의존성 관리 일원화핵심 설정connection-timeout 커넥션 획득 대기 시간idle-timeout 유
66.[Spring] Persistence Context

엔터티 저장·조회·수정·삭제를 담당하는 진입점스레드 세이프 아님 → 스레드 공유 금지웹 애플리케이션에서는 보통 요청 단위(request scope)로 사용EntityManager 생성 팩토리스레드 세이프 → 애플리케이션 전역 싱글톤으로 1개 운영생성 비용이 크므로 재사
67.[Spring] Mapping

ddl-auto 옵션:create(매번 생성) / update(스키마 변경만 반영) / validate(검증만) / create-drop(종료 시 삭제)JPA 관리 대상 클래스 선언기본 생성자 필수, final/enum/interface/inner class 불가같은
68.[Spring] Association Mapping

CamelCaseToUnderscoresNamingStrategy: myFieldName → my_field_name 으로 물리 이름 변환ddl-auto: 운영 DB에는 none 권장(마이그레이션 도구 사용)주의: 의존성의 DB 드라이버와 driver-class-nam
69.[Spring] JPQL

JPA를 엔티티 중심으로 사용하면서, 복잡한 조회·집계·조인을 DB 벤더에 독립적으로 작성하게 해 주는 객체지향 쿼리 언어. EntityManager가 JPQL → SQL로 변환해 DB에 항상 질의(find()와 달리 1차 캐시 우선 조회 X).키워드: SELECT /
70.[Spring] Native Query

ORM을 쓰면서도 DB 고유 SQL을 그대로 활용하고 싶을 때 쓰는 게 Native query. 복잡한 집계/힌트/특정 함수 등 JPQL로 표현 어려운 쿼리를 그대로 사용하되, 영속성 컨텍스트 연동(엔티티 매핑 시) 이점은 그대로 챙길 수 있음.resultClass가
71.[Spring] 스프링 데이터 JPA

Spring Data JPA로 JPA를 더 간단하게. Repository 인터페이스와 쿼리 메소드만으로 CRUD, 정렬, 페이징, 동적 조회까지 한 번에!Spring에서 JPA 사용을 편리하게 해 주는 Spring Data 모듈.Repository + 쿼리 메소드로 J
72.BEYOND SW 캠프 20기 10주차
이번 주는 데이터 접근 전반을 묶어서 정리했다. MyBatis 설정과 XML/애너테이션 기반 동적 쿼리, JPA의 영속성 컨텍스트와 매핑, 연관관계 매핑, JPQL, 네이티브 쿼리, 스프링 데이터 JPA까지 범위를 넓혔다. 백엔드 팀(ADHD)은 ERD를 마무리했고,
73.[Spring] REST API

한 번에 보는 REST → JSON → 응답 타입 → ResponseEntity → Validation → HATEOAS → SwaggerREpresentational State Transfer: HTTP 위에서 리소스 지향으로 상태를 주고받는 아키텍처 스타일.URL로
74.[Spring] CQRS

CQRS(Command Query Responsibility Segregation)는 쓰기(Command)와 읽기(Query)의 책임을 분리해 각각을 독립적으로 최적화·확장하는 아키텍처 스타일이다. 대규모 트래픽에서 읽기 사이드의 확장과 캐싱, 읽기 전용 모델 운영이
75.[Spring] Spring Security
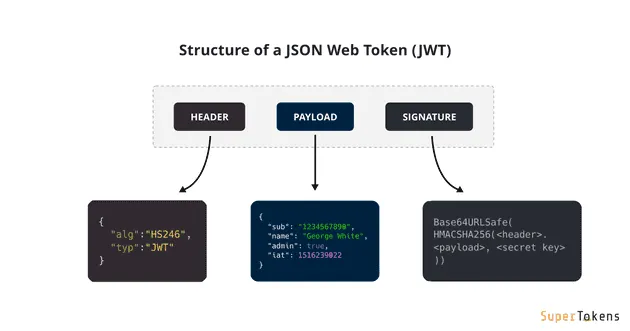
스프링 기반 애플리케이션의 인증(Authentication)과 인가(Authorization)를 담당하는 보안 프레임워크. 강력한 확장성으로 요구사항에 맞춰 쉽게 커스터마이징할 수 있다.스프링 하위 프레임워크로 인증/인가를 표준 방식으로 제공모든 요청을 필터 체인으로
76.[Spring] HTTP 실시간 통신

HTTP는 기본적으로 상태를 기억하지 않는 Stateless 프로토콜이다. 로그인 유지나 사용자 컨텍스트는 세션/쿠키 같은 별도 메커니즘이 필요하다. 실시간성은 HTTP 단독으로 한계가 있어, Polling·Long-Polling·SSE·WebSocket·STOMP 등
77.[Spring] MSA

큰 애플리케이션을 여러 개의 작은 서비스로 나누어, 독립적으로 개발·배포·운영할 수 있게 만드는 아키텍처 스타일각 서비스는 고유한 기능을 담당하며, 서로 API로 통신하면서 전체 시스템을 구성한다.주요 장점은 다음과 같다.서비스별 독립 배포필요한 서비스만 선택적 확장장
78.[Spring] Spring Cloud

Spring Cloud는 마이크로서비스 아키텍처(MSA)를 구축할 때 필요한서비스 디스커버리, 로드 밸런싱, 설정 관리, 게이트웨이 등을 제공하는 Spring 기반 확장 모음이다.그중 Eureka는 서비스 등록/발견(Discovery)을 담당하는 핵심 컴포넌트다.Net
79.[Spring] Service Instance 간의 통신

MSA에서는 서비스가 독립적이기 때문에“어디서 인증을 하고, 각 서비스는 무엇을 믿을 것인가”를 먼저 정하는 게 중요하다.각 모듈(서비스)이 클라이언트가 보낸 JWT 토큰을 직접 검증하고, 그 결과로 SecurityContext를 구성하는 방식이다.장점방어 심층(Def
80.[Spring] Config Server, Actuator, 내결함성

MSA 애플리케이션을 잘 설계하려면“서비스를 잘게 나누는 것”보다“운영·배포·장애·설정·관찰까지 한 흐름으로 관리하는 것”이 더 중요하다.통신 표준화서비스 간 통신을 REST API로 통일Swagger / OpenAPI 로 스펙 문서화 → 협업·유지보수 용이자원 중심
81.BEYOND SW 캠프 20기 12주차

백엔드 프로젝트랑 공모전을 동시에 진행하다 보니 시간이 많이 부족했다. 그러다 보니 주간 회고록도 제때 정리를 못 하고 뒤늦게 쓰게 됐다. 그래도 저번 주는 수업에서는 Spring Security와 MSA를 집중적으로 다뤘고, 실습은 거의 전부 실제 백엔드 프로젝트에
82.BEYOND SW 캠프 20기 10월 회고록

10월은 백엔드 프로젝트를 새 팀과 시작하고, 공모전 중간발표까지 준비하느라 시간이 훅 지나갔다. 프로젝트와 공모전을 병행하다 보니 일정 압박이 컸지만, 한 달을 돌아보니 그래도 뼈대와 필수 기능들을 꽉 채워 달린 느낌이다.유형: Spring 기반 백엔드 프로젝트(MS
83.HTML

HTML은 웹 페이지 구조와 콘텐츠를 정의하는 표준 마크업 언어. 브라우저가 해석해 화면에 그린다. 기본 골격<!DOCTYPE html>: HTML5 선언, head: 메타데이터, body: 실제 콘텐츠. 작성 시 주의: 태그는 소문자 권장, 여는 태그는 닫아주기
84.CSS-(1)

역할: 문서(HTML)의 표현(레이아웃·색·폰트·애니메이션 등)을 정의적용 방식: 인라인(style="") / 내부(<style>) / 외부(.css 링크)우선순위: 출처 → !important → 명시도(ID > class/속성/의사클래스 > 태그/의사요소) →
85.CSS-(2)

background-color : 배경색background-image : 이미지 배경(url(...))background-repeat : repeat | no-repeat | repeat-x | repeat-ybackground-position : left/top/ce
86.BEYOND SW 캠프 20기 13주차

백엔드 프로젝트가 끝나서 잠깐 숨 돌리나 싶었는데, 곧바로 그 결과물을 바탕으로 프론트엔드 프로젝트를 시작했다. 쉬는 시간은 거의 없었다. 초반부터 피그마로 화면을 잡아야 했는데 익숙하지 않아서 시간이 꽤 걸렸다. 또한, 이번 주 일요일에 SQlD 시험이 있어서 공부를
87.[JavaScript] 자바스크립트 - (1)

변수 · 연산자 · 객체 리터럴 · 함수자바스크립트(ES6 기준)는 7개의 데이터 타입을 제공하며, 크게 원시 타입과 객체 타입으로 나뉜다 원시 타입(primitive)numberstringbooleanundefinednullsymbol (ES6)객체 타입(object
88.[JavaScript] 자바스크립트 - (2)

스코프·생성자·프로토타입·strict mode·배열전역(global): 코드의 가장 바깥 영역→ 전역 스코프, 전역 변수는 어디서나 참조 가능지역(local): 함수 몸체 내부→ 지역 스코프, 해당 함수와 하위 함수에서만 유효 var는 함수 몸체만 지역 스코프로 인정→
89.[JavaScript] 자바스크립트 - (3)

global, Number, Math, Date, RegExp, String전역 객체(global/window)에 붙어 있는 빌트인 전역 값들이다. Infinity양·음의 무한대를 나타내는 숫자 값NaN숫자가 아님(Not a Number)Number('abc'), 10
90.[JavaScript] 자바스크립트 - 클래스

class 기본 문법 · 상속 · static핵심 정리:class Student { ... } 로 클래스를 선언new Student() 를 호출하면 인스턴스가 생성되고 constructor 가 자동 실행클래스 몸체에 정의한 메서드는 기본적으로 프로토타입 메서드→ Stu
91.[JavaScript] 자바스크립트 - ES6 문법

화살표 함수 · 스프레드 문법 · 구조 분해 할당ES6에서 도입된 화살표 함수는 function 키워드 대신 => 를 써서 함수를 더 간단하게 표현하는 문법이다. 항상 익명 함수로 정의되고, 본문이 짧은 함수에서 특히 유용하다. 객체를 바로 반환할 때는 소괄호로 감싸야
92.[JavaScript] DOM

렌더링 흐름 · 노드 선택 · 어트리뷰트 · 스타일 조작파싱(parsing)HTML/CSS/JS 같은 텍스트를 읽어 토큰으로 쪼개고문법 구조에 맞게 파스 트리(parse tree) 를 만든 뒤이를 바탕으로 중간 코드(바이트코드 등)를 생성해 실행하는 과정렌더링(rend
93.[JavaScript] Event

이벤트 핸들러 · 이벤트 객체 · 전파 · 위임 · 폼 이벤트브라우저는 클릭, 키보드 입력, 마우스 이동 같은 동작을 감지해서 이벤트 객체를 만들고, 등록해 둔 이벤트 핸들러(콜백 함수) 를 호출한다.이 핸들러를 브라우저에 넘겨두는 과정을 이벤트 핸들러 등록이라고 부른
94.[JavaScript] Async

동기 vs 비동기 · 콜백 · Promise · async/await · fetch · axios · 이벤트 루프이전 코드가 끝난 다음에야 다음 코드가 실행됨한 작업이 오래 걸리면 그동안 다음 코드가 멈춰서 기다리는 상태오래 걸리는 작업을 백그라운드에 맡겨두고, 다음
95.[Vue] 개요

Vue는 사용자 인터페이스(UI)와 싱글 페이지 애플리케이션(SPA) 개발을 위해 설계된 오픈 소스 JavaScript 프레임워크다.컴포넌트 기반 아키텍처를 제공해, 화면을 작은 독립 컴포넌트 단위로 쪼개서 조합하는 방식으로 개발하게 한다.2014년 Evan You가
96.[Vue] 기본 문법

CDN 으로 Vue를 불러와서 Composition API 중심으로 쓰는 기본 문법을 정리한 글이다.(앱 생성 → 상태 관리 → 템플릿 → v-if / v-for → v-model → watch → 라이프사이클 순서)Vue 앱은 createApp() 호출로 시작한다.s
97.[Vue] Props/Emit/Slot/Provide/Inject

Vite + SFC + 컴포넌트 패턴 한 번에 훑기Vite는 Vue 3 공식 권장 개발 환경이다.개발 서버 속도가 매우 빠른 번들러 겸 빌드 도구개발 시:변경된 파일만 ESBuild로 바로 변환브라우저의 ES 모듈 기능 활용 → 전체 번들 없이 동작빌드 시:Rollup
98.[Vue] Router

SPA에서 URL로 페이지를 다루는 방법Vue Router는 Vue 공식 라우팅 라이브러리다.하나의 HTML 안에서 URL만 바꾸면서 화면(컴포넌트)을 교체실제로는 페이지 전체 새로고침 없이 동작결국 URL → 컴포넌트 매핑 테이블을 만드는 것SPA에서 단순히 v-if
99.BEYOND SW 캠프 20기 14주차

본격적으로 Vue를 배우기 시작하면서 프론트엔드 프로젝트도 드디어 본 궤도에 올라가기 시작했다.이전에 백엔드만 붙들고 있을 때와는 달리, 이제는 내가 만든 API들을 실제 화면에서 호출하고, 버튼을 눌렀을 때 데이터가 오가도록 만드는 작업을 하다 보니 확실히 눈에 보이
100.[Vue] Axios/CORS(CRUD 연동)

브라우저 내장 fetch 만으로도 통신은 가능하지만, 실제 서비스에서는 Axios를 거의 기본처럼 쓴다.이유:에러 처리 구조가 더 명확하다 (try/catch 로 한 번에 처리)응답을 기본적으로 JSON 으로 파싱해 준다요청·응답 인터셉터로 공통 로직을 한 곳에 모을
101.[Vue] Pinia(인증 API 연동)

Vue 3 + Pinia + Spring Security(JWT) 조합으로 인증을 구현할 때 핵심 정리컴포넌트가 많아질수록 다음 문제가 터진다.부모 → 자식으로 props를 계속 내려야 하고자식 → 부모로 emit을 계속 올려야 하고중간 단계 컴포넌트가 많아지면“이 상
102.[Vue] Composable 구조화

Composition API를 제대로 쓰려면 Composable과 Pinia를 어떻게 나눌지부터 감이 잡혀야 한다.Composable = 재사용 가능한 Composition API 함수Vue 3에서 setup() 안에 마구 섞여 있던 로직을 역할별로 분리해 별도 함수로
103.[Vue] 테스트

테스트를 도입하는 목적은 단순하다.리팩토링을 해도 기존 기능이 깨지지 않도록 방어UI와 비즈니스 로직을 분리한 구조(Composable, Pinia)가 제대로 작동하는지 검증컴포넌트 / Composable / Store 각각이 자기 책임만 제대로 수행하는지 확인결국 목
104.[Docker] 도커(Docker) 개요

도커(Docker)는 리눅스의 프로세스 격리 기술을 이용해애플리케이션을 컨테이너(container) 라는 단위로 실행하고 관리하는 오픈 소스 플랫폼이다.한 줄 요약→ “애플리케이션과 그 실행 환경 전체를 하나의 컨테이너로 묶어, 어디서나 똑같이 실행되게 해주는 기술”도
105.[Docker] 도커 사용하기

로컬에서 도커를 다루면서 가장 많이 쓰는 기본 명령들을 정리한 내용.도커 허브(Docker Hub)에 저장된 이미지를 가져오거나(push 포함) 하려면 먼저 로그인해야 한다.터미널에서 실행 후 Docker Hub 계정의 username 과 password 를 입력한 번
106.[Docker] 도커 기본 명령어

도커를 쓸 때 자주 쓰는 기본 CLI 명령어를 한 번에 보기 좋게 정리.도커 명령은 기본적으로 다음 형태를 따른다.예:도커에서 명령어 사용법이 헷갈릴 때는 help 로 바로 확인할 수 있다.상위 명령어 목록과 간단 설명을 보여준다옵션, 사용 예시 등을 상세히 확인할 수
107.[Docker] 도커 이미지 만들기

스프링부트 같은 애플리케이션을 컨테이너로 띄우려면 결국 이미지 → 컨테이너 흐름으로 가야 한다.여기서는 Docker 이미지 개념부터 Dockerfile, 빌드, 실행, Docker Hub 푸시까지 한 번에 정리한다.모든 컨테이너는 이미지를 바탕으로 실행된다.이때 이미지
108.[Docker] Docker Compose

멀티 컨테이너 환경을 한 번에 올리고 내릴 때 사용하는 게 Docker Compose다.여기서는 개념 → docker-compose.yml 구조 → 자주 쓰는 명령 → 네트워크까지 정리한다.실제 서비스는 보통웹 서버DB캐시백엔드 API같은 여러 컴포넌트가 함께 돌아간다
109.[Docker] Volume & Container Modification

도커로 서비스 운영하다 보면 데이터를 어떻게 보존할지, 그리고 컨테이너를 어떻게 커스텀 이미지로 남길지가 핵심 포인트가 된다.여기서는 두 가지를 정리한다.Docker Volume: 데이터 영속성, 공유Container Modification(컨테이너 개조): 컨테이너
110.BEYOND SW 캠프 20기 15주차

이번 주는 정말 길고 길었던 백엔드, 프론트엔드 프로젝트가 완전히 마무리된 주였다.몇 주 동안 API 설계하고, 인증 붙이고, 알림 기능 만들고, Vue로 화면까지 구현하느라 정신없이 달려왔는데, 드디어 끝났다는 말을 할 수 있게 됐다.특히 프론트엔드는 시간이 항상 부
111.BEYOND SW 캠프 20기 11월 회고록

11월은 ADHD Ad Hell 백엔드 프로젝트를 기반으로 한 프론트엔드 프로젝트에 올인한 한 달이었다.그동안 포스트맨으로만 확인하던 API들을 실제 화면 위에 올리고, 로그인부터 알림까지 전체 흐름을 Vue로 구현하는 데 집중했다.일정은 여전히 빠듯했고, 날씨도 갑자
112.[Docker] Logging & Monitoring

Spring Boot 애플리케이션을 실제로 운영하려면 단순 로그 출력만으로는 부족하다.로그를 모아서 검색하고, 성능과 장애 상황을 시계열로 추적하고, 대시보드로 한눈에 보고 싶다.그 역할을 나눠서 담당하는 것이 바로 ELK(로그), Prometheus + Grafana
113.[Docker] Message Broker

서비스가 많아지고 MSA 구조로 가면, 서비스끼리 직접 REST로만 붙어 있는 구조는 한계가 금방 온다.이때 사이에서 메시지를 받아 저장해두고, 필요한 서비스가 꺼내 가서 처리하도록 중개해 주는 게 메시지 브로커다.이 글에서는 메시지 브로커 개념부터 RabbitMQ v
114.[Kubernetes] Kubernetes 기초

쿠버네티스는 컨테이너가 많아지는 순간부터 거의 필수처럼 등장하는 도구다.아래 내용은 “도커는 알겠는데, 쿠버네티스는 뭐가 다른지, 구조가 어떻게 생겼는지”를 빠르게 정리한 요약본이다.쿠버네티스(Kubernetes, K8s)컨테이너의 배포, 스케일링, 장애 복구, 롤링
115.[Kubernetes] Ingress & 배포전략

Ingress는 쿠버네티스 클러스터 외부 → 내부 서비스로 들어오는 HTTP/HTTPS 트래픽을 제어하는 API 객체여러 서비스 앞에 서서 단일 진입점(Entry Point) 역할을 한다도메인, 경로, TLS 설정 등을 한 곳에서 관리할 수 있어 복잡한 네트워크 구성을
116.[Kubernetes] Volume (PV, PVC)

쿠버네티스에서 스토리지는 크게 두 축으로 나뉜다.Pod 라이프사이클에 묶인 일시적인 Volume클러스터 단위로 관리되는 PersistentVolume / PersistentVolumeClaim이 둘이 어떻게 다른지, 그리고 실제 예제까지 한 번에 정리.쿠버네티스에서 V
117.[Kubernetes] ConfigMap & Secret

쿠버네티스에서 애플리케이션 설정을 다룰 때 자주 사용하는 리소스가 ConfigMap과 Secret이다.둘 다 설정값을 저장하지만, 용도와 보안 수준이 다르다.키–값 형태로 데이터를 저장Pod에환경 변수로 주입하거나파일 형태로 마운트해서 사용애플리케이션 설정을 클러스터
118.[Kubernetes] Health Check(Liveness/Readiness Probe)

쿠버네티스는 컨테이너가 정말 살아 있는지, 그리고 외부 요청을 받아도 되는 상태인지 자동으로 체크할 수 있는 기능을 제공한다.핵심은 두 가지 프로브다.Liveness Probe: 컨테이너가 살아 있는가Readiness Probe: 트래픽을 받을 준비가 되었는가컨테이너가
119.[Kubernetes] Pod 자원 제한과 HPA 기반 자동 스케일링

쿠버네티스에서 리소스 설정과 자동 스케일링(HPA)는 운영 안정성과 직결되는 핵심 개념이다.아래 내용은 실습 예제를 기준으로 정리한 정리본이다.Kubernetes에서 컨테이너마다 다음 두 가지 리소스를 설정할 수 있다.requestsPod가 스케줄링될 때 최소로 보장받
120.[Kubernetes] Job & Cron Job

쿠버네티스에서 Job / CronJob은 “끝나는 작업”을 안전하게 돌리기 위한 리소스다.Deployment: 계속 떠 있는 서버 프로세스 관리Job: 한 번 실행하고 끝나는 작업CronJob: 일정 주기로 반복 실행되는 JobJob은 지정한 작업이 성공할 때까지(re
121.[Kubernetes] StatefulSet + Headless Service

StatefulSet은 상태를 가진 애플리케이션을 위한 Pod 운영 방식이다.특징은 크게 네 가지로 정리할 수 있다.Pod 이름이 고정된다Pod마다 자기만의 PVC(영구 스토리지)를 가진다생성·삭제 순서가 보장된다 (0번부터 차례대로)각 Pod에 변하지 않는 DNS 이
122.[Kubernetes] Terraform

테라폼(Terraform)은 인프라스트럭처를 코드로 관리하는 IaC(Infrastructure as Code) 도구다.AWS, Azure, GCP, Kubernetes 같은 인프라를 선언적 구성 파일(HCL) 로 정의하고,그 코드에 맞춰 실제 리소스를 생성·변경·삭제해
123.[Kubernetes] Terraform을 통한 k8s 클러스터 배포

Terraform 설치 과정은 공식 문서를 따라가면 충분하다고 보고, 여기서는 Kubernetes 환경에서 Terraform을 어떻게 구성하고 쓰는지에 집중해서 정리한다.보통 프로젝트 구조는 이렇게 나눈다.같은 식으로 기존 리소스를 지우고 Terraform으로 올리는
124.BEYOND SW 캠프 20기 16주차

이번 주는 새로운 팀원이 정해지고, 숨 돌릴 틈도 없이 바로 데브옵스 프로젝트에 돌입한 한 주였다.백엔드와 프론트엔드 프로젝트가 끝난 지 얼마 되지도 않았지만, 곧바로 인프라와 배포 관점에서 서비스를 다시 바라봐야 했다.이번 데브옵스 프로젝트의 주제는 이전에 구상했던
125.[Jenkins] Jenkins 기본 개념

젠킨스(Jenkins)는 CI(지속적 통합) / CD(지속적 배포) 파이프라인을 자동화하는 오픈 소스 자동화 서버다.VCS(Git/SVN 등)와 연동해 코드 변경 감지 → 빌드 → 테스트 → 배포 흐름을 자동으로 실행한다.핵심 아이디어는 단순하다.사람이 반복하던 작업(
126.[Jenkins] Jenkins를 이용한 CI/CD Pipeline 구축

Logon Type: Run service as LocalSystem 선택기본 포트 8080 대신 18080 사용Jenkins는 Java 기반이라 JDK 위에서 구동됨설치된 JDK 경로를 찾아 선택브라우저에서 http://localhost:18080 접속안내된
127.[Jenkins] Jenkins pipeline 확장

Jenkins 파이프라인에 테스트 단계를 추가해 코드 변경 시 자동으로 테스트를 실행하고, 결과를 Jenkins UI에서 확인 가능하게 구성한다.stage('Run Tests')를 Source Build 다음에 추가Unix/Windows 환경을 분기해 Gradle 테스
128.[Jenkins] ArgoCD

ArgoCD는 Kubernetes 애플리케이션을 GitOps 방식으로 배포·운영하는 오픈소스 도구다.Git 저장소에 선언적으로 정의된 매니페스트(Desired State)를 기준으로, Kubernetes 클러스터의 실제 상태(Actual State)를 자동으로 감지하고
129.[Jenkins] ArgoCD를 통한 k8s 클러스터 배포 자동화

목표는 아래 흐름을 한 번에 연결하는 것Jenkins가 소스 변경을 감지해 빌드/테스트 수행Docker 이미지를 빌드하고 Docker Hub에 태그(빌드 번호/최신)로 pushK8S 매니페스트(manifests) 레포의 이미지 태그를 새 버전으로 업데이트 후 pushA
130.BEYOND SW 캠프 20기 17주차

이번 주를 끝으로 DevOps 프로젝트를 마무리했고, 이제는 최종 프로젝트만 남게 되었다.백엔드와 프론트엔드에 이어 DevOps까지 쉬지 않고 달려온 만큼 체력적으로도, 정신적으로도 꽤 벅찼던 한 주였다.특히 이번 DevOps 프로젝트에서는 커뮤니티 기능, 알림 기능에
131.BEYOND SW 캠프 20기 17주차

17주차 회고록 1) 17주차를 시작하며 이번 주를 끝으로 DevOps 프로젝트를 마무리했고, 이제는 최종 프로젝트만 남게 되었다. 백엔드와 프론트엔드에 이어 DevOps까지 쉬지 않고 달려온 만큼 체력적으로도, 정신적으로도 꽤 벅찼던 한 주였다. 특히 이번 De
132.BEYOND SW 캠프 20기 18주차

이번 주부터 본격적으로 최종 프로젝트 기간에 돌입했다.DevOps 프로젝트를 마무리하고 잠깐 숨을 돌릴 수 있을까 기대했지만, 현실적으로는 곧바로 최종 프로젝트 주제를 정하는 데 대부분의 시간을 쏟아야 했다.확실히 최종 프로젝트는 단순 과제가 아니라 앞으로 포트폴리오에
133.BEYOND SW 캠프 20기 19주차

이번 주는 거의 온전히 최종 프로젝트 기획에만 시간을 쏟아부은 한 주였다.요구사항을 어떻게 정리할지, 어떤 흐름으로 서비스가 돌아가야 할지,어떤 기능을 어디까지 포함할지 정리하다 보니 손대야 할 부분이 끝없이 나오는 느낌이었다.하루 종일 회의하고, 문서를 열어두고, 화