
[논문 리뷰] π0.5: a Vision-Language-Action Model with Open-World Generalization
Paper 링크 Website 링크 Abstract 이 모델은 이질적인 다양한 작업에 대한 co-training을 통해 광범위한 일반화를 가능하게 함 π0.5 시스템은 이미지 관찰, 언어 명령, 객체 탐지 등을 결합한 hybrid multi modal example들과 공동 학습 방식을 사용함 Introduction 기존 문제점 open world...
[논문 리뷰] Octo: An Open-Source Generalist Robot Policy
Octo 논문 링크 Octo 깃허브 링크 Abstract Octo는 Open X-Embodiment에서 수집한 80만개 trajectory로 학습된 대형 transformer 기반 policy model이다. Octo는 자연어 명령이나 목표 이미지를 통해 지시를 받을
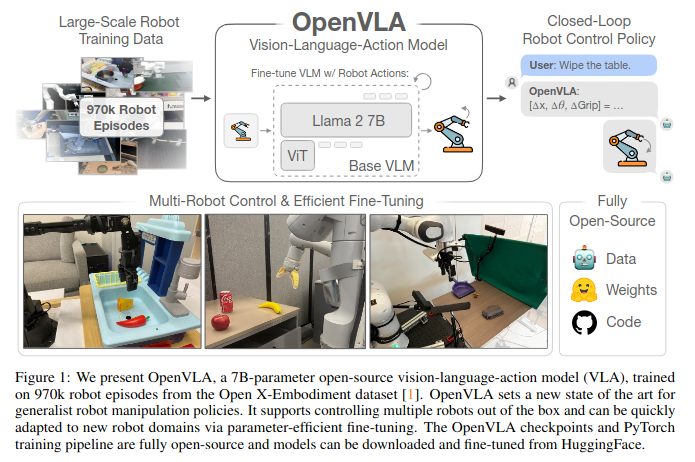
[논문 리뷰] OpenVLA: An Open-Source Vision-Language-Action Model
OpenVLA 논문 링크OpenVLA는 970,000개의 로봇 에피소드를 기반으로 학습된 7B 파라미터의 오픈 소스 비전-언어-행동 모델(VLA)이다.
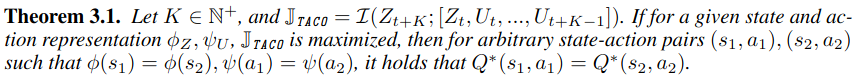
[논문 리뷰] TACO: Temporal Latent Action-Driven Contrastive Loss for Visual Reinforcement Learning
TACO 논문 링크 Introduction 배경: 픽셀 이미지만 보고도 게임이나 로봇을 잘 제어할 수 있는 알고리즘들이 많이 나왔지만 여전히 샘플 효율성이 낮다는 문제가 있다. 즉, 환경에서 너무 많은 경험(데이터)을 필요로 한다. 과거 연구들은 이 문제를 해결하려

[OCR] 5.7 진행 상황
Progress 1. PaddleOCR 적용 새로운 데이터셋들을 기존 모델인 PaddleOCR로 inference했을 때, 문자 인식을 아예 못함

[논문 리뷰] Learning robust autonomous navigation and locomotion for wheeled-legged robots
본 연구는 적응형 이동 제어, 이동성 인식 기반의 지역 내비게이션 계획, 그리고 도시 내 대규모 경로 계획을 포함하는 통합형 시스템을 소개한다.
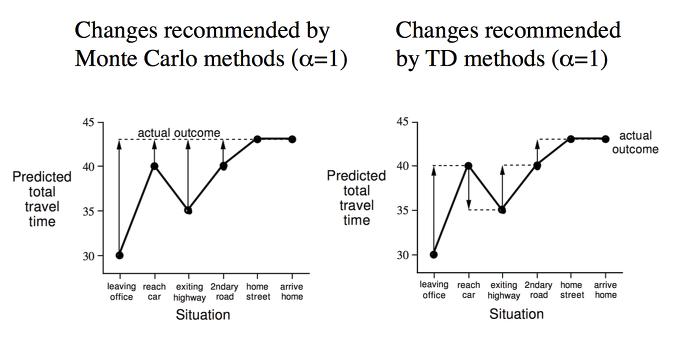
[강화학습] Ch 6. Temporal-Difference Learning
TDL에 대한 최대한 자세히 설명하였습니다. 위 내용은 "단단한 강화학습" 책을 통해서 작성되었습니다.
Isaac Sim, Isaac Lab 설치하기
Conda 설치 Conda Installation Isaac Sim이랑 Isaac Lab 설치하기 Isaac Sim, Lab Installation Isaac Sim 설치하기 Isaac Sim 설치 링크 이렇게 설치하고 나면 Isaac Sim directory는
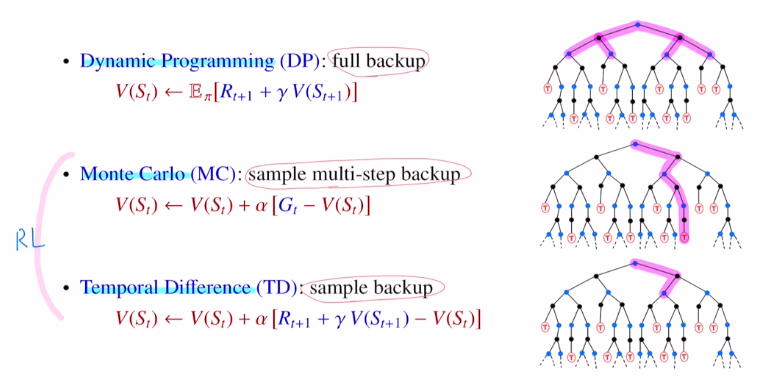
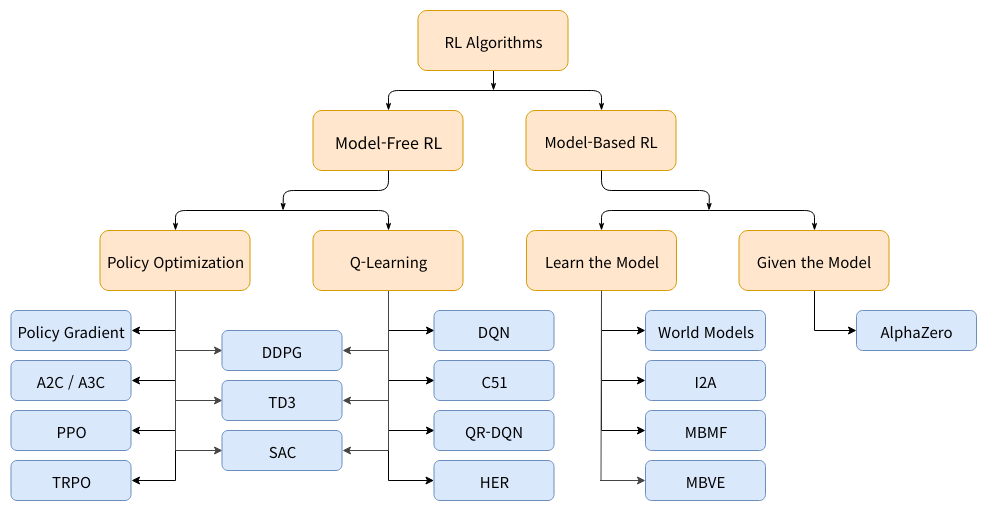
[강화 학습] RL 발전 과정 및 간단 정리
강화학습을 공부해보니 발전과정이 복잡해서 그걸 한번 간단하게 정리해보려고 한다. 각 개념에 대해서는 차차 정리를 자세하게 해보겠다.

[논문 리뷰] Policy Gradient Methods for Reinforcement Learning with Function Approximation
소개 업로드중.. Paper link 강화학습의 시초 같은 논문을 읽어보겠다. NeuralPS (NIPS)에 기재된 논문이다. Abstract Function approximation (함수 근사)는 강화학습에서 필수적이지만, value fuction을 근사하고