
- 전체보기(26)
- 수업자료(12)
- 생성형AI(7)
- rag(6)
- LLM(6)
- Computer Vision(5)
- langgraph(5)
- CNN(5)
- 수업자료_CNN(5)
- langChain(5)
- 기업교육(5)
- 강화학습(5)
- 컴퓨터비전(5)
- AI교육(4)
- LLMOps(3)
- Reinforce Learning(3)
- AI개발(3)
- streamlit(2)
- Langfuse(2)
- 파이썬(2)
- RAG평가(2)
- tensorflow기초(2)
- reinforce learing(2)
- 웹 개발(2)
- 데모(2)
- keras기초(2)
- 배포(1)
- ChatPromptTemplate(1)
- 차익거래(1)
- ClaudeDesktop(1)
- 통신(1)
- 비개발자AI교육(1)
- wireguard(1)
- 업무자동화(1)
- AI리터러시(1)
- mcp_server(1)
- 딥러닝(1)
- chatGPT(1)
- AI엔지니어링(1)
- Human(1)
- AIAgent(1)
- 네트워크(1)
- ToolCalling(1)
- AI강사(1)
- vpn(1)
- 입력설계(1)
- 자동거래(1)
- 텍스트마이닝(1)
- AI도입(1)
- 구조화출력(1)
- MCP(1)
- AdvancedRAG(1)
- LLM엔지니어링(1)
- generativeAI(1)
- 암호화폐(1)
- AI(1)
- ModelContextProtocol(1)
- middleware(1)
- 프롬프트설계(1)
- RAG시스템(1)
- HITL(1)
- tool(1)
- notion(1)
- 생성형AI교육(1)
- 머신러닝(1)
- HRD(1)
- RAGAS(1)
- 프롬프트엔지니어링(1)
- 디지털전환(1)
- VectorDB(1)
- RetrievalAugmentedGeneration(1)
- PromptTemplate(1)
- hallucination(1)
- 원격접속(1)
- mlops(1)
- 지도학습(1)
- AI기업교육(1)
- 벡터DB(1)
- 모델평가(1)
- Agentic(1)
- AI자동화(1)
- 보안(1)
- 업무혁신(1)
- mcp_client(1)
- 코인(1)
- 검색증강생성(1)
- Retrieval(1)
- 자동화(1)
- 재정거래(1)
- AI도구연결(1)
- AI실무(1)
- AI워크플로우(1)
- PromptEngineering(1)
- 김민수강사(1)
- structured(1)
- AI엔지니어(1)
- AgenticRAG(1)
- AI개발실무(1)
- AI에이전트(1)
- DNS(1)
- multi(1)

Generative AI와 Traditional Machine Learning의 차이: 문제 정의, 파이프라인, 평가 기준
생성형 AI와 기존 머신러닝의 차이는 “새 모델이 옛 모델을 대체했는가”보다 “어떤 문제를 어떻게 정의하는가”로 보는 편이 정확하다.전통적인 머신러닝 프로젝트는 보통 아래 질문으로 시작한다.생성형 AI 프로젝트는 자주 아래 질문으로 시작한다.둘 다 AI지만, 데이터 구
Prompt Engineering as Input Design: 문자열이 아니라 입력 인터페이스로 보기
프롬프트 엔지니어링을 "좋은 문장 작성법"으로 이해하면 금방 한계가 온다.LLM 애플리케이션에서 prompt는 단순 문자열이 아니다. 모델 호출 앞단의 입력 인터페이스다. 어떤 변수를 받을지, 어떤 context를 넣을지, 어떤 constraints를 강제할지, 어떤
Agent가 항상 정답은 아니다: Chain, RAG, Agent를 구분해서 선택하기
Agent를 기본 아키텍처로 두면 설계가 쉽게 과해진다. 이 접근은 위험하다. Agent는 특정 문제를 해결하는 구조이지, 모든 LLM 앱의 상위 호환이 아니다. 좋은 기준은 이것이다. 1. Chain으로 충분한 경우 정해진 입력을 받아 정해진 방식으로 출력하면
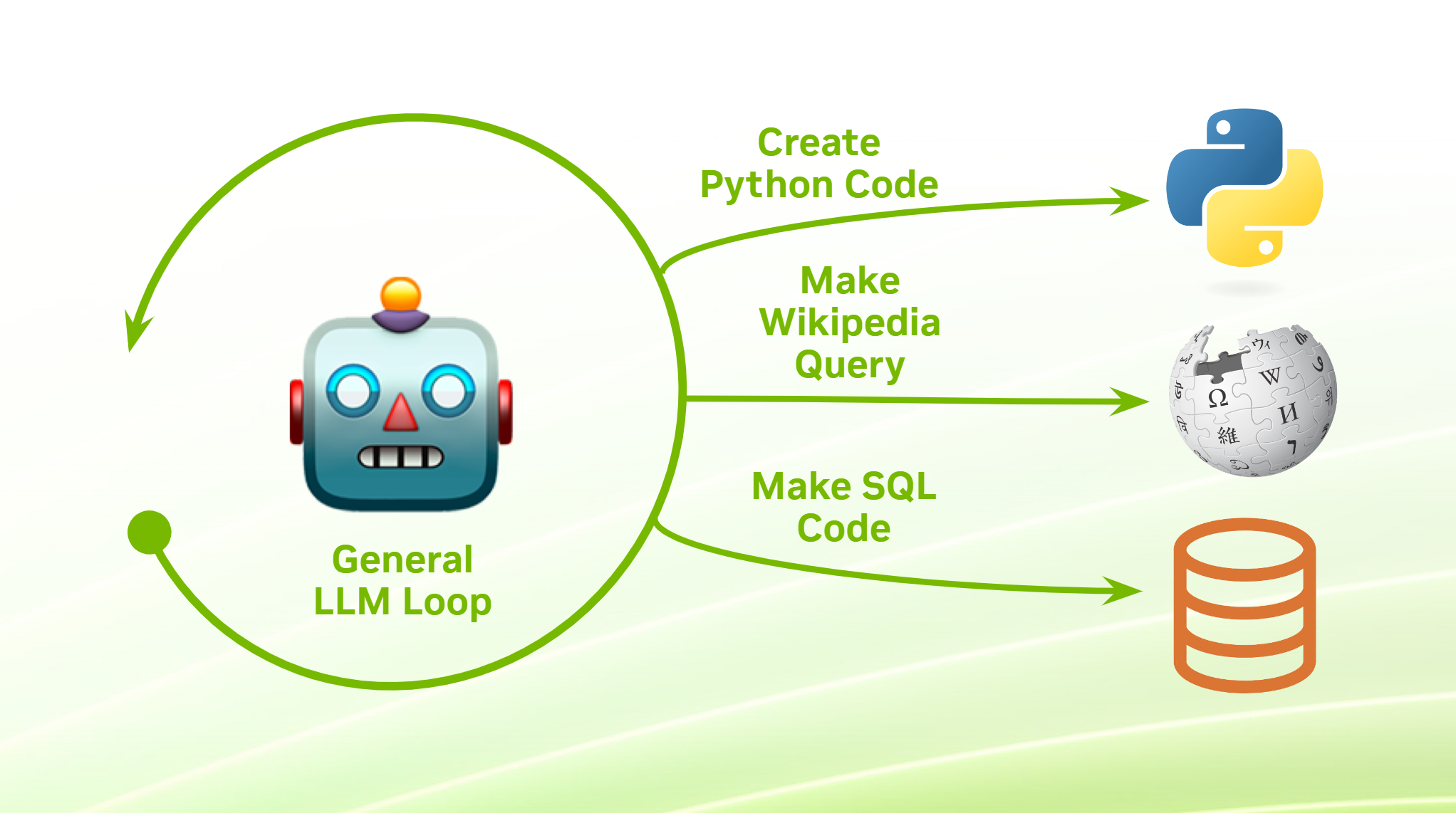
MCP 입문: Host, Client, Server, Tool을 코드 흐름으로 이해하기
MCP(Model Context Protocol)를 처음 보면 "Tool Calling이랑 뭐가 다른가?"라는 질문이 먼저 나온다.개발 관점에서는 이렇게 나누면 이해하기 쉽다.Tool Calling: 모델이 어떤 도구를 호출할지 결정하는 메커니즘MCP: AI appli
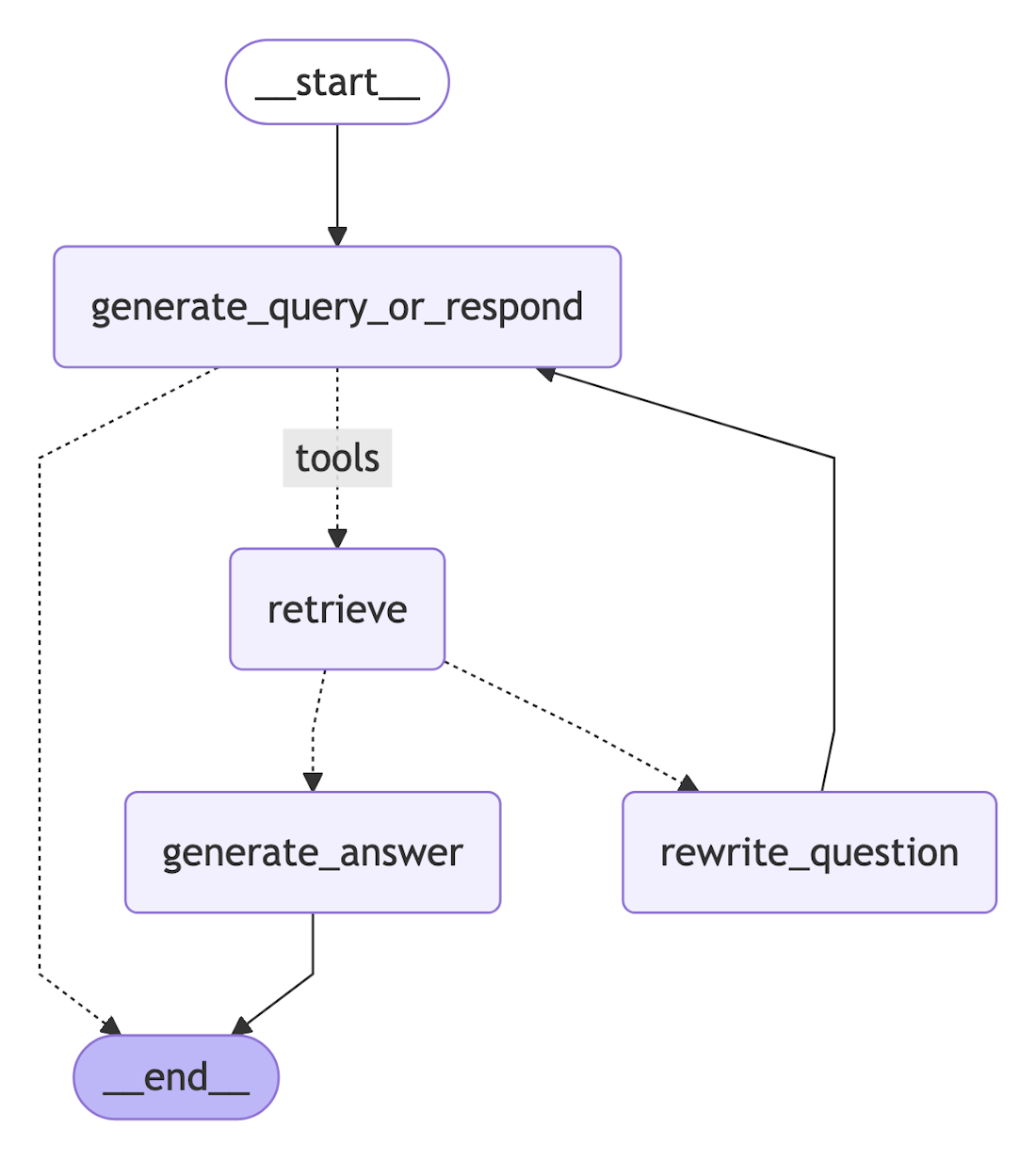
Agentic RAG vs Naive RAG: 검색을 더 많이 하는 것이 아니라 흐름을 제어하는 것
Agentic RAG를 구현할 때 가장 먼저 피해야 할 오해가 있다.부분적으로 맞을 수 있지만 충분하지 않다.Agentic RAG의 핵심은 검색 횟수가 아니라 control flow다.이 질문에 검색이 필요한가?필요하다면 어떤 지식원을 검색할 것인가?검색 결과가 충분한
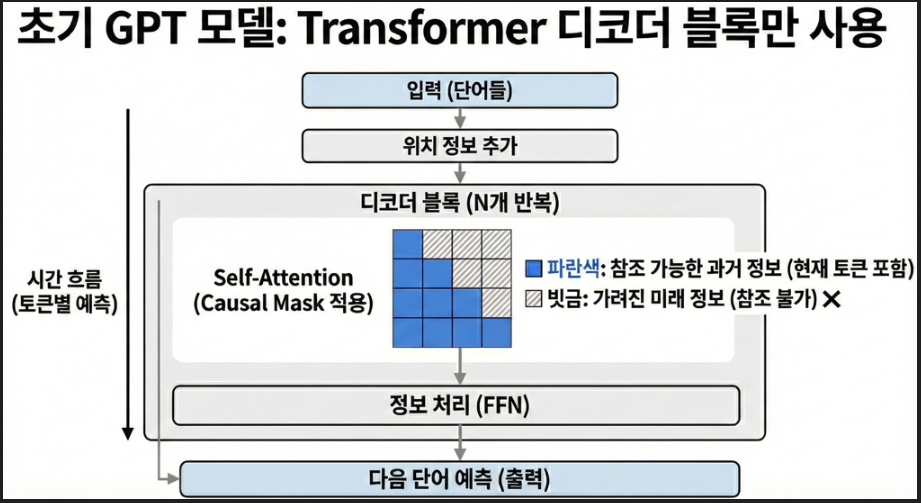
LLM Hallucination은 왜 발생하는가: 다음 토큰 예측부터 RAG 평가까지
LLM hallucination은 단순히 "모델이 거짓말을 한다"로 설명하면 부족하다. 개발 관점에서는 생성 방식, 컨텍스트 설계, 검색 품질, 평가 체계가 같이 얽힌 문제다.수업에서 이 주제를 다룰 때 가장 먼저 분리해서 설명하는 것은 다음 두 가지다.LLM은 정답
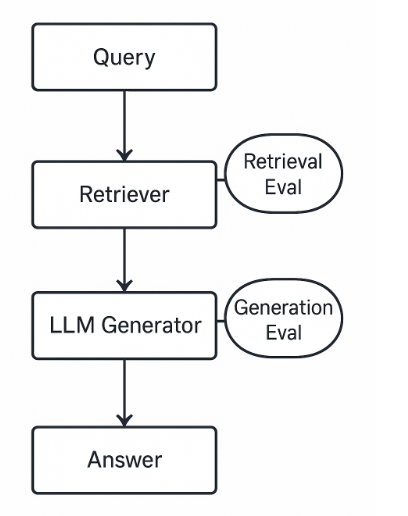
RAG가 잘 안 될 때 검색 문제와 생성 문제를 구분하는 방법
RAG가 잘 안 될 때 검색 문제와 생성 문제를 구분하는 방법 RAG 품질을 개선할 때 가장 위험한 접근은 "답변이 이상하니까 프롬프트를 고치자"로 바로 들어가는 것이다. 프롬프트가 문제일 수는 있다. 하지만 RAG는 단일 LLM 호출이 아니라 Retrieval -

영상처리 기초 - 6. OCR 프로젝트-2(학습 및 평가)
부정확하거나 일관되지 않은 라벨:라벨의 오류는 모델의 성능을 저하시킬 수 있습니다. 모델이 잘못된 라벨을 학습하면, 정확성, 정밀도, 재현율과 같은 성능 지표가 모두 감소하게 됩니다.왜곡된 라벨링: 라벨이 실제 시나리오를 제대로 대표하지 못할 경우, 모델은 새로운 데

영상처리 기초 - 4. OCR 프로젝트-1(데이터분석)
전이학습(Transfer Learning)이란?전이학습은 기존에 학습된 모델의 가중치를 새로운 문제에 활용하는 방법입니다.대규모 데이터셋에서 사전 학습된 모델을 통해 기본적인 특성(feature)을 이해하게 하고, 이를 새로운 데이터셋에 적용하여 모델 학습 시간을 줄이

영상처리 기초 - 3. 컨볼루션 신경망
완전 연결 네트워크의 문제점으로부터 시작매개변수의 폭발적인 증가공간 추론의 부족: 픽셀 사이의 근접성 개념이 완전 연결 계층(Fully-Connected Layer)에서는 손실됨동물의 시각피질의 구조에서 영감을 받아 만들어진 딥러닝 신경망 모델시각 자극이 1차 시각피질

영상처리 기초 - 2. OPENCV 이미지처리
다양한 도형을 그릴 수 있음도형을 그리는 좌표가 해당 범위를 넘어가면 이미지에 표현되지 않음cv.line()Parametersimg : 그림을 그릴 이미지 파일start : 시작 좌표end : 종료 좌표color : BGR형태의 Color (ex; (255, 0, 0)

영상처리 기초 - 1.컴퓨터비전 기초
컴퓨터 비전은 컴퓨터가 디지털 이미지를 이해하고 분석하여 의미 있는 정보를 추출하도록 하는 학문 및 기술 분야입니다.인간의 시각 시스템처럼 이미지나 비디오를 처리하고 그 안의 객체, 패턴, 또는 행동을 이해하려는 목표를 가지고 있습니다.컴퓨터 비전은 인공지능(AI)의
강화학습 기초 6 - 최신 강화학습 사례
RLHF (Reinforcement Learning with Human Feedback):사용 사례:ChatGPT (OpenAI): 인간 피드백을 활용해 언어 모델의 응답 품질 향상.InstructGPT: 사용자의 지침에 맞는 응답 생성.작동 원리:인간 평가자가 제공하
강화학습 기초 5 - DQN
강화학습(RL): 에이전트가 환경과 상호작용하며 최적의 행동을 학습하는 과정.핵심 요소:상태(State): 현재 환경의 상태.행동(Action): 에이전트가 취할 수 있는 행동.보상(Reward): 행동의 결과로 환경이 에이전트에 제공하는 피드백.정책(Policy):

가비아 DNS 설정 및 Nginx를 활용한 FastAPI 배포
가비아에 로그인한 후, DNS 관리 페이지(예: 가비아 DNS 관리)로 이동합니다.여기서 도메인에 대해 다음과 같이 DNS 레코드를 설정합니다.링크 : https://dns.gabia.com/dns/internals/total_setDNS 레코드 예시타입: A
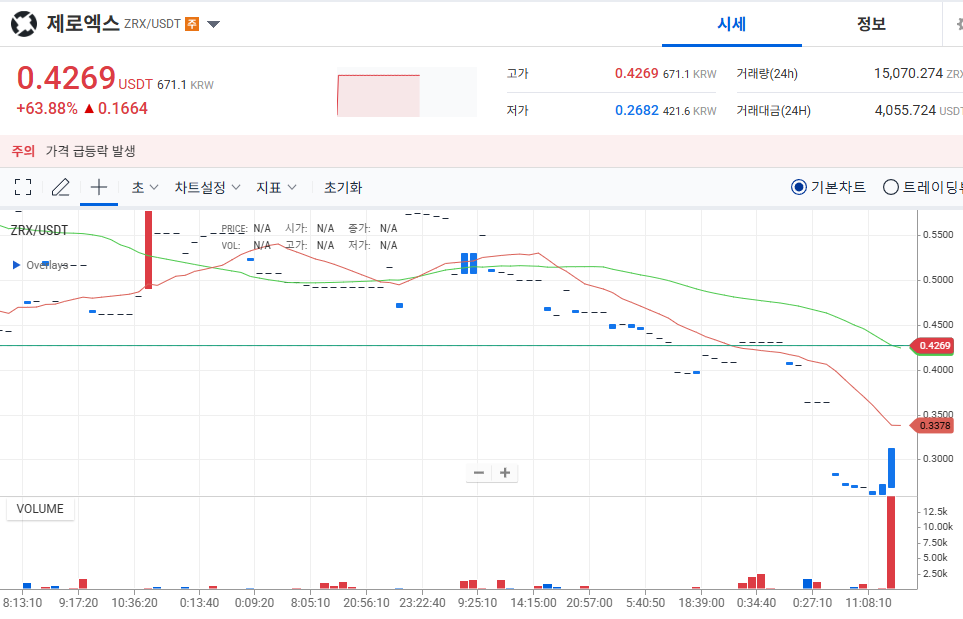
암호화폐 재정거래 프로젝트
암호화폐는 탈중앙화 화폐이기 때문에 거래소마다 가격의 차이가 있다. 따라서 거래소마다 가격이 다른 것을 이용해 가격이 싼 곳에서 구매한 뒤 비싼곳에서 사면 적은 리스크로 돈을 벌 수 있고 이것을 무위험 차익거래 혹은 재정거래라고 부른다. 돈을 입금하면 재정거래를 자동으

Tensorflow를 활용한 인공신경망 구현2
손으로 쓴 숫자들로 이루어진 이미지 데이터셋기계 학습 분야의 트레이닝 및 테스트에 널리 사용되는 데이터keras.datasets에 기본으로 포함되어 있는 데이터셋MNIST 데이터셋을 로드Train Data 중, 30%를 검증 데이터(validation data)로 사용
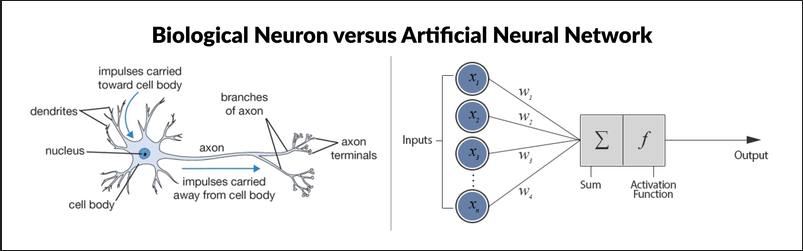
Tensorflow를 활용한 인공신경망 구현1
본 자료는 이수안 교수님(https://suanlab.com/)의 자료를 일부 수정 후 업데이트 한 자료입니다. ipynb 나 pdf 자료가 필요하신분은 연락주세요.인간 두뇌에 대한 계산적 모델을 통해 인공지능을 구현하려는 분야인간의 뇌 구조를 모방: 뉴런과
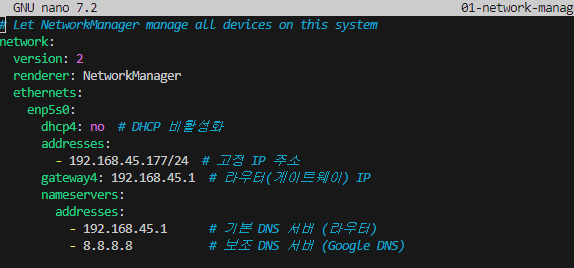
wireguard 설치 - 1
회사를 그만두고 프리랜서 개발자로 활동하며, 출장이 잦아 집이 아닌 장소에서 개발하는 일이 많아졌습니다.특히 GPU를 활용한 작업이 필요할 때가 있는데, GPU가 탑재된 노트북은 무겁고 휴대성이 떨어지기 때문에 집에 우분투(Ubuntu) 기반의 데스크톱을 구축하여 원격
강화학습 기초 4 - 큐러닝
Q-Learning은 강화학습의 대표적인 알고리즘 중 하나로, 환경과의 상호작용을 통해 최적의 정책을 학습하는 방법입니다.이미지 출처 https://www.researchgate.net/figure/Q-Learning-vs-Deep-Q-Learning_fig1