
📊 Object Detection?
Object detection(객체 검출)은 입력 영상이 주어질 때, 영상 내에 존재하는 모든 카테고리에 대해서 classification(분류)과 localization(지역화)를 수행하는 작업.
📚 위키백과
객체 탐지(客體探知, object detection)는 컴퓨터 비전과 이미지 처리와 관련된 컴퓨터 기술로서, 디지털 이미지와 비디오로 특정한 계열의 시맨틱 객체 인스턴스(예: 인간, 건물, 자동차)를 감지하는 일을 다룬다. 잘 연구된 객체 탐지 분야로는 얼굴 검출, 보행자 검출이 포함된다. 객체 탐지는 영상 복구, 비디오 감시를 포함한 수많은 컴퓨터 비전 분야에 응용되고 있다.
- 사진 및 영상에서 물체를 구분해주는 작업을 하는 것!
🔍 분류 ?? 지역화 ?? 그게뭐지
🐱 classification(분류)
- 영상에 있는 물체의 Class를 알아내는 문제

🐱 localization(지역화)
- 영상에 있는 물체의 위치를 찾는 문제

🧐 용어정리
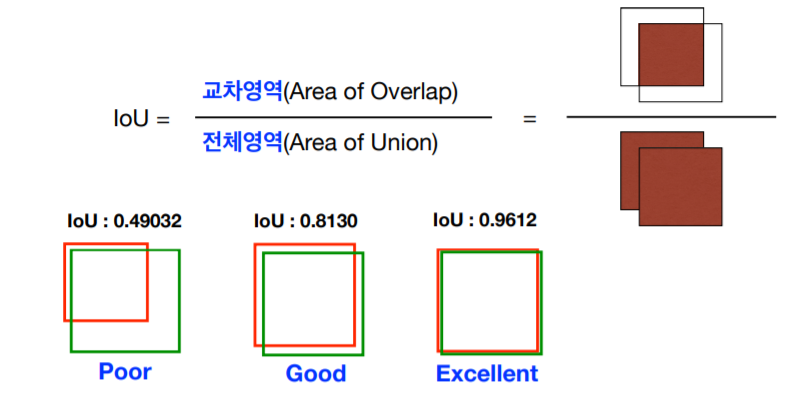
1. IoU (Intersection over Union)
2. TP, FP, FN, TN
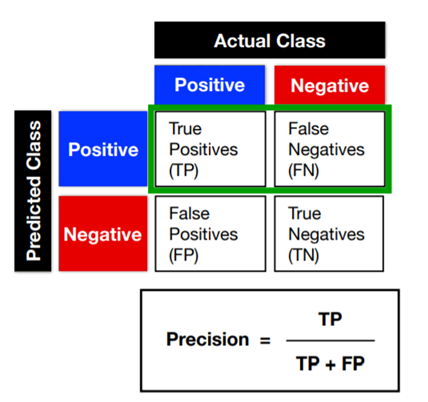
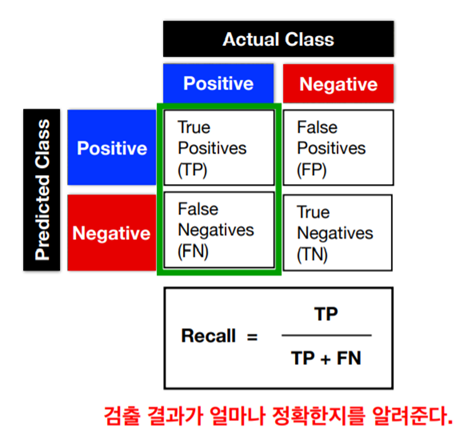
True Positive(TP) : 실제 True인 정답을 True라고 예측 (정답)
False Positive(FP) : 실제 False인 정답을 True라고 예측 (오답)
False Negative(FN) : 실제 True인 정답을 False라고 예측 (오답)
True Negative(TN) : 실제 False인 정답을 False라고 예측 (정답)
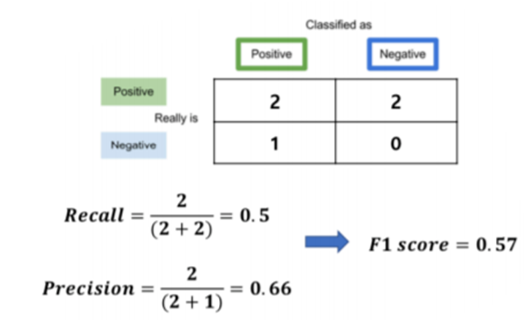
3. Precision
4. Accuracy
5. F1 Score
Precision과 Recall의 조화평균.
두 Score를 모두 고려할 수 있는 Score
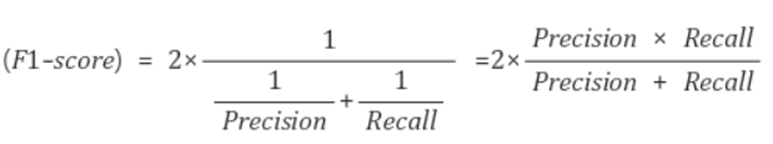

👓 Detection Methods
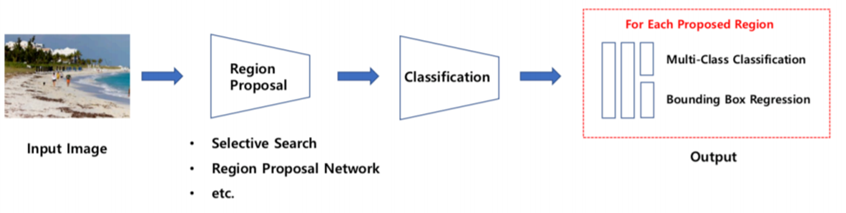
2 Stage Detection
- Region Proposal 수행 후, Classification, Regression 수행
R-CNN, SPPNet, fast R-CNN, faster R-CNN
상대적으로 느린 속도와 높은 정확도
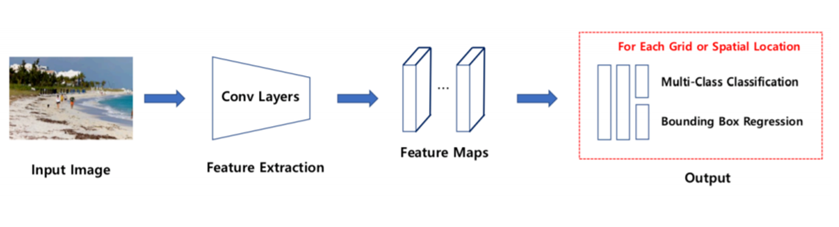
1 Stage Detection
- Region Proposal, Classification, Regression을 동시에 수행
YOLO series, SSD
상대적으로 빠른 속도와 낮은 정확도
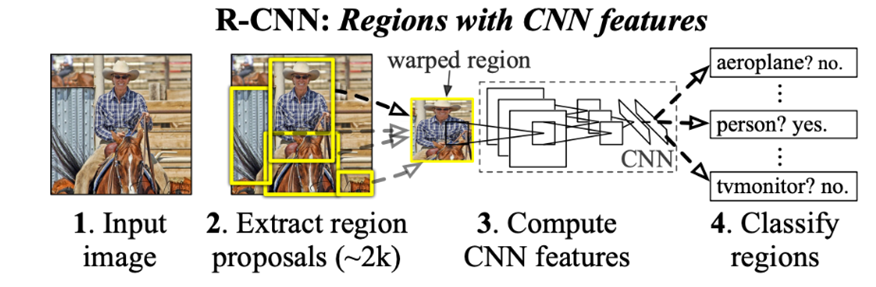
🎓 R-CNN

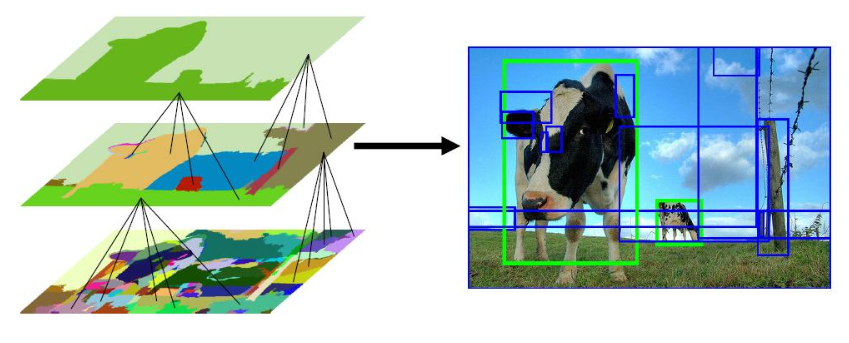
- Selective Search
선택적 탐색(Selective Search)은 Object Detect를 수행하기 위한 영역 제안(Region Proposal) 알고리즘 중 하나.
선택적 탐색은 색, 질감, 크기, 모양에 의존하여 유사한 영역 찾는데, 이를 계층으로 수행하여 그룹화한다.
- 영상의 각 픽셀에서 Handmade-Feature들을 추출
- 이웃한 픽셀한 유사도가 특정 Threshold 이상이면 같은 Region으로 취급
- 다음 알고리즘을 이용해 이웃한 Region들을 병합해 나감
- 최종적으로 L에 포함된 모든 Region이 Proposal 대상이 됨.

- Loop 횟수에 따른 Region들의 모습
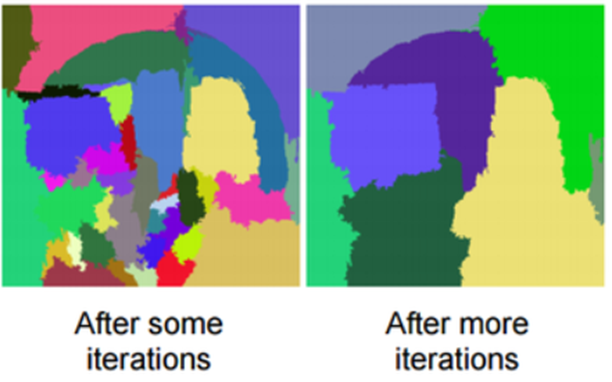
- Selective Search로 뽑은 Region들을 일정 크기로 Resize함.
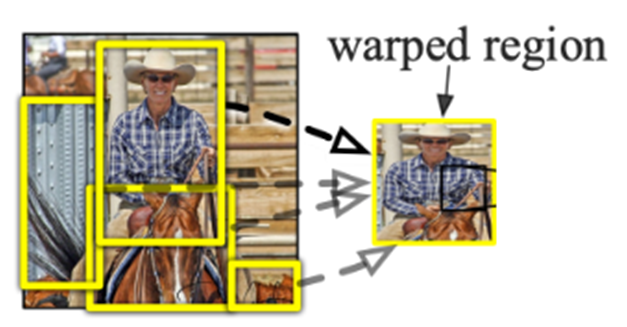
-Selective Search로 뽑은 Region들을 각각 일정 크기로 Resize한 뒤 CNN에 넣음
-CNN에서 추출된 Feature들을 각 클래스마다 정의된 이진분류 SVM에 넣어 가장 Score가 높은 Class를 선택
-Non-Maximum Suppression : IoU가 일정 Threshold(약 0.5) 이상이고 같은 Class면 같은 객체로 취급.
-SVM Score가 가장 높은 객체만 남기고 모두 제거

-Bounding Box Regression : Selective Search가 제안한 영역은 부정확하므로,
정확한 Box 위치를 맞춰줘야 함.
- 분류에 사용했던 CNN Feature들을 대상으로 Linear Regression 사용
- Bounding Box Regression으로 정확해진 영역을 대상으로 다시 Classification하고 이걸 다시 Bounding Box Regression하는 것을 반복할 필요는 없다.(의외로 성능 향상에 큰 도움 안 됨.)

Bounding Box Regression

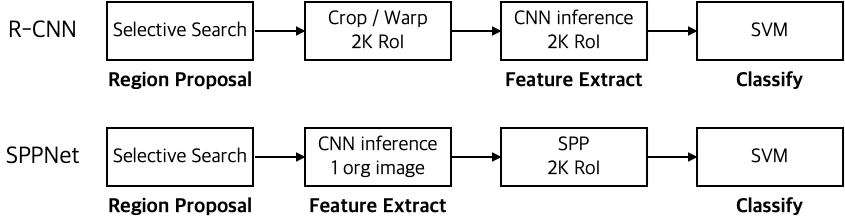
🎓 SPPNet
- 기본 뼈대는 R-CNN과 동일(R-CNN 시리즈는 저자들이 모두 FAIR 소속)
- SS로 찾아내는 Region들은 2000~3000개
- region들을 하나하나 모두 Resize해서 CNN에 입력하는 것은 비효율적
기본 뼈대
-Region Proposer : Selective Search
-Feature Extractor : CNN
-Classifier : Class-wise binary SVM
-Bounding Box Regression : Linear Regressor
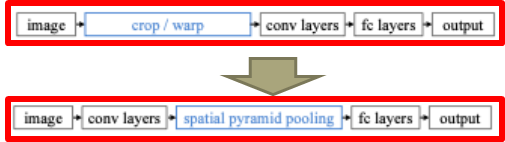
- 전체 이미지를 CNN에 한번 통과시킨 Feature Map에서 Region 위치에 있는 Feature들을 사용하면, CNN을 2000~3000번 돌릴 것을 1번만 돌려도 가능.
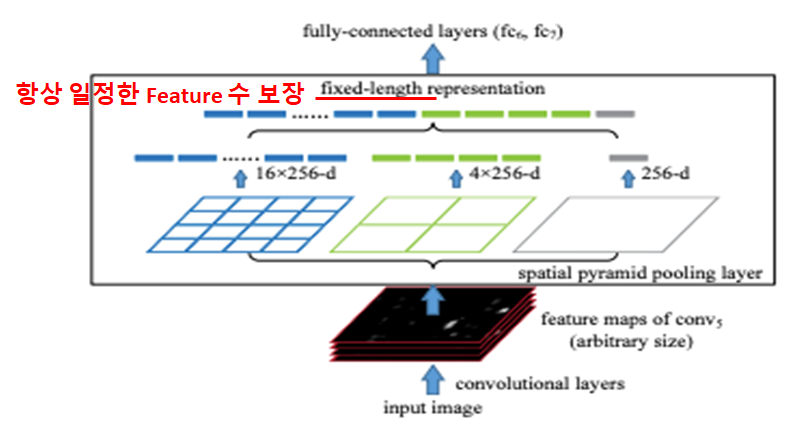
- 문제는 Feature Map의 크기, 즉 Feature의 숫자가 일정하지 않아 이것을 해결하는 것이 Spatial Pyramid Pooling.
- Region을 4x4, 2x2, 1x1 Grid로 나눠서 Max-Pooling.
- Max-Pooling한 값들(16 + 4 + 1 = 21)을 Feature로 사용.
- 사진과 달리 논문에서는 6x6, 3x3, 2x2, 1x1의 Grid 사용(총 50개).
개선점
1. 2000~3000번에 달하는 CNN 실행횟수를 1번으로 단축
2. 입력크기에 상관없이 일정한 Feature 개수를 보장하는 SPP기법 제안
한계점
1. 여전히 Region Proposal은 Selective Search, Feature Extraction은 CNN, Classification은 binary SVM을 사용하는 등 여러 단계가 필요.
2. CNN Fine-Tuning, SVM Training, Bounding Box Regressor Training 등을 각각 따로 학습시켜야 해서 구현과 학습이 비효율적이고 복잡.
🎓 Fast R-CNN
- Region Proposer : Selective Search
- Feature Extractor : CNN
- Classifier : NN with Multi-Label Softmax
- Box Regression : Linear Regressor
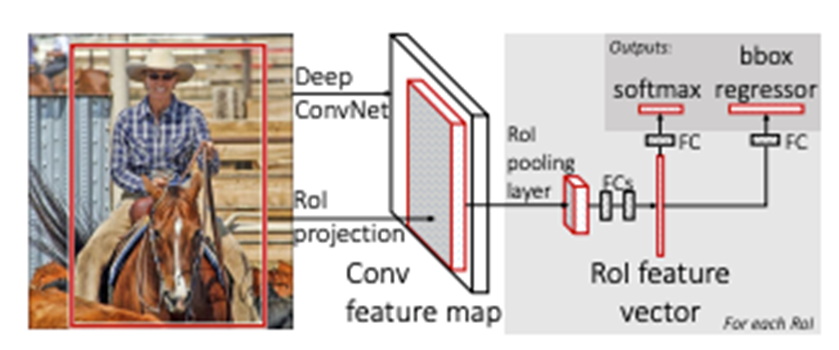
- 최초의 End-to-End 학습을 가능케 한 모델.
- 분류기로 더 이상 SVM을 사용하지 않기 때문에 Classifier, Bounding Box Regressor와 함께 Feature Extractor까지 한꺼번에 학습 가능.
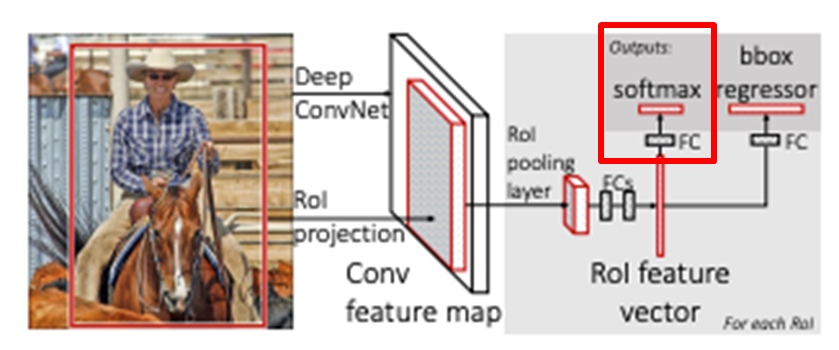
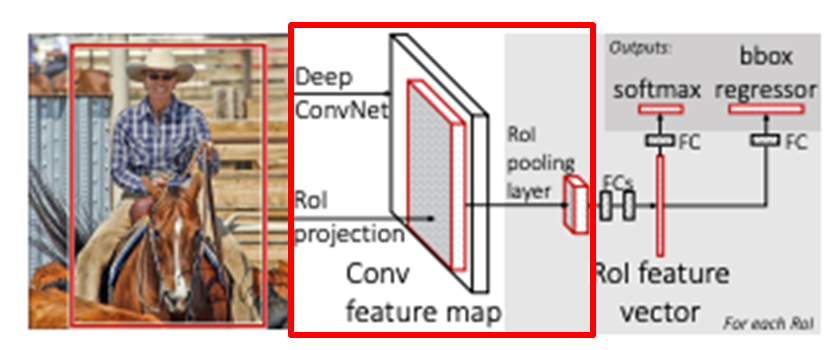
- 최초에 영상 전체를 CNN에 통과시킨 뒤, Region에 대입되는 영역을 구하는 부분까지는 SPPNet과 동일.
- SPP(Spatial Pyramid Pooling ) 대신 RoI Pooling 사용.
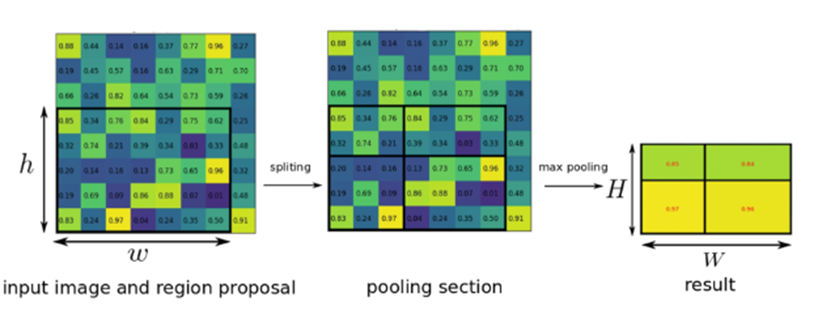
- RoI Pooling : Spatial Pyramid Pooling 의 1 Stage Version
- 4x4, 2x2, 1x1등 여러 배율의 Grid를 사용하는 대신 그냥 한 개만 사용
- 논문에서는 7x7 배율 사용
- Pyramid 기법 자체는 영상처리에서 Scale Invariance를 확보하기 위해 사용되어 온 오래된 기법.
- 여러 Stage의 Pyramid를 사용하지 않아도 Deep CNN이 자체적으로 Scale Invariance를 학습할 수 있기 때문에 복잡한 SPP 대신RoI Pooling을 사용하는 것.
- SS로 Region 추출.
- 전체 영상을 CNN에 한 번 통과시켜 Feature Map 추출.
- Feature에서 Region에 해당하는 영역을 RoI Pooling해서 49개의 Feature 추출.
- 49개의 Feature들은 FC Layer를 거쳐 차원조절 된 뒤 Classifier와 Bounding Box Regressor로 입력.
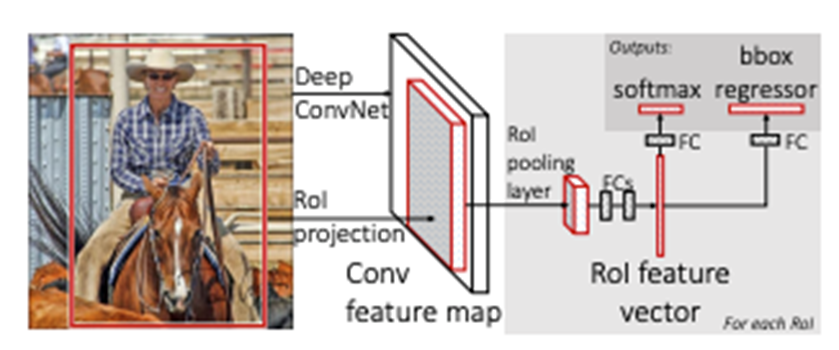
Classifier와 Bounding Box Regressor를 학습시키는 방법은 두 가지 존재.
- 번갈아 가며(R-CNN, SPPNet 방식)
- 한꺼번에
- 한꺼번에 시킬 때가 확실히 더 좋은 성능을 내는데, Classification과 BB Regression이 서로 완전히 독립적인 Task가 아님.
- 즉 번갈아 가며 Bias하게 Optimize하는 것 보다, 한꺼번에 Optimize하는 것이 더 좋은 특징들을 추출할 수 있도록 도움.


- 그렇다면 어떻게 동시에 학습시키는가?
=> Multi Task Loss를 정의
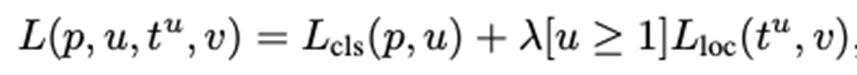

Fast R-CNN 정리
개선점
1. SVM Classifier을 제거하여 End-to-End로 학습가능.
2. 위 개선점에서 오는 자연스러운 성능향상
3. Neural Net 자체의 Scale Invariance를 이용하는 RoI Pooling을 사용하기 때문에 SPP보다 덜 복잡.
한계점
1. 여전히 Region Proposal에 SS를 사용하기 때문에 2000~3000번의 Classification이 필요.
2. 따라서 진정한 Neural Net Only Method는 아님
출처 및 참조 :

정확도와 재현률은 다른 것 아닌가요?
Accuracy = TP+TN/(TP+FP+FN+TN)
Recall (Sensitivity) = TP/(TP+FN)