[논문리뷰] From Show to Tell: A Survey on Deep Learning-based Image Captioning(1)(Visual Encoder Part를 중심으로 )
Multimodal Deep Learning
Paper:From Show to Tell: A Survey on Deep Learning-based Image Captioning
0. Abstract
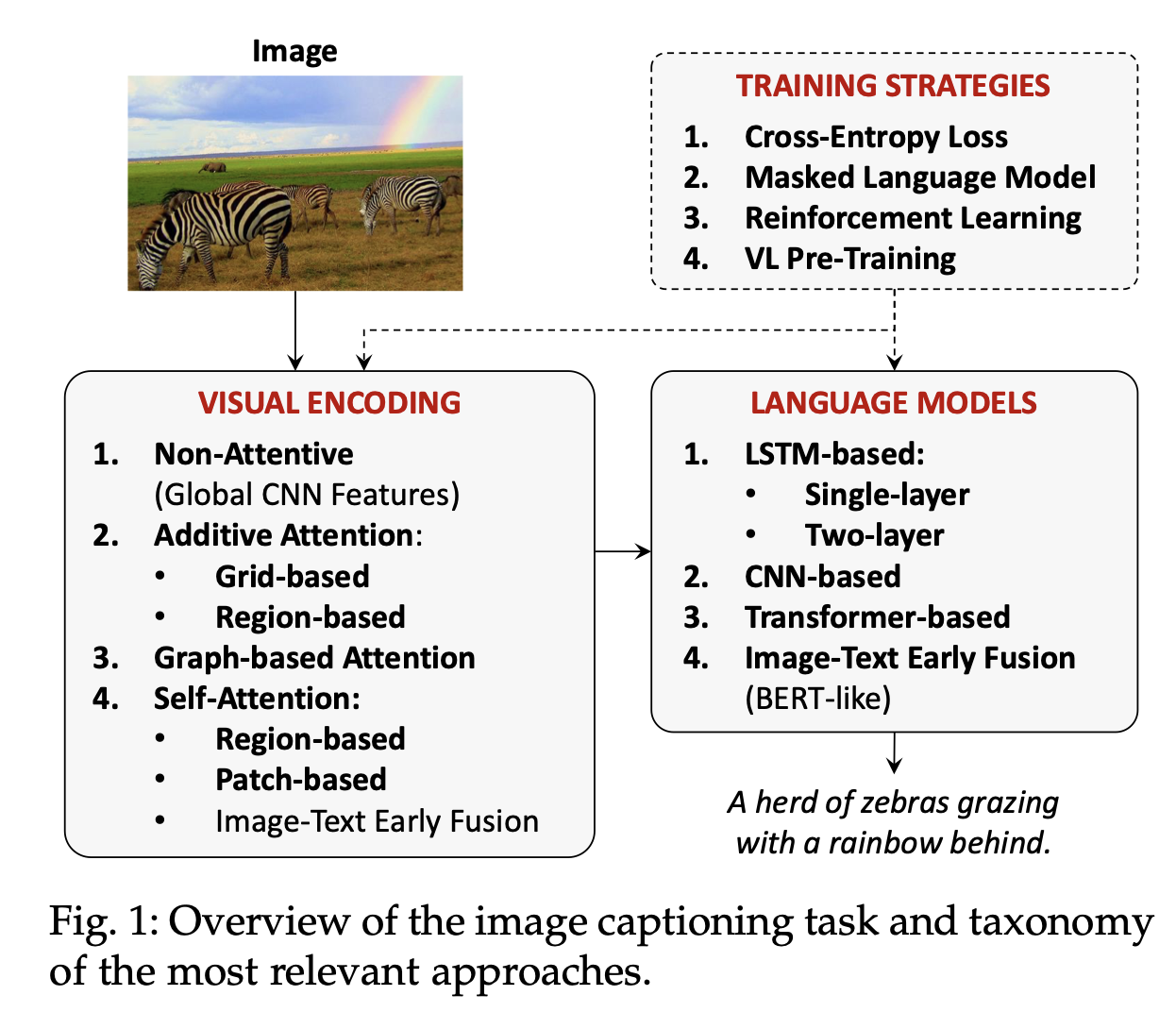
일반적으로 Image captioning model은 visual encoder와 language model로 구성됩니다.
가장 기본적으로는 CNN과 RNN(LSTM)을 사용했었으나, object regions에 대한 연구, attributes, multl-modal connections, fully-attentive approaches, 그리고 BERT같은 early-fusion 접근법 들로 인해 Image Captioning 모델도 다양해졌습니다.
본 서베이 논문은 image captioning 연구의 전반적인 개요를 다룹니다.
- visual encoding
- text generation
- training strategies
- dataset
- evaluation
- SoTA approaches
- e.t.c
최종적으로, 기존의 연구들과 Captioning 연구의 미래 방향들을 이해하는데 도움이 되길 바란다고 합니다.
1. Introduction
이미지를 받아 문법적으로, 그리고 의미적으로 타당한 문장을 반환하는 것이 Image captioning입니다.
- 최종 목표 : input image를 처리해 representation을 생성하고, visual element와 textual elements 사이의 연결을 만들어, 언어의 유창함을 유지한채, 일련의 단어들을 생성하는 것.
검색, 템플릿, manual language generation 등 초기의 접근법들은 생략.
최근 Image Captioning 방법론들은 주로 image-to-sequence problem으로 구성됩니다.
- input image를 one(multiple) feature vector로 인코딩
- visual encoder
- 초기엔 기본적인 CNN
- 이 feature vector로부터 문장을 생성
- language model
- 초기엔 기본적인 RNN(with global image descriptor)
최근에는, Transformer와 Self Attention이라는 breakthroughs와 single-stream BERT-기반 방법들과 같은 attentive approaches들에 이르기까지 attentive approaches들로 하여금 모델은 더욱 좋아졌습니다.
reinforcement Learning도 사용
마찬가지로 (사람이 만든 ground-truth)와의 비교를 위해서 Evaluation 프로토콜과 Metric도 활발히 개발되었습니다
하지만, 여전히 Image Captioning은 발전할 필요가 있습니다.
뿐만 아니라, 이미지 캡셔닝은 Object Detection이나 Classification처럼 딱 떨어지는 모델이 아니고, 개개인 연구자의 목적이나 사용하는 맥락에 맞게 다양성을 가질 수 있기 때문에 Domain-specific한 모델들과 변형모델들이 많습니다.
Flickr 등 데이터셋과 메트릭을 구축한 연구자들에 따르면, 이미지 캡션은 아래와 같은 개념을 가진다고 합니다.
- perceptual : focusing on low-level visual attributes
- non-visual : reporting implicit and contextual information
- conceptual : describing the actual visual content
(visual entities & relation)
이 때, conceptial은 이미지 캡셔닝의 목표로 여겨지기도 하는데(구체적인 정보들에 대한 캡션을 주로 알고싶으므로), 이 개념은 다양한 관점, 다양한 수준의 디테일들을 다루는 것도 포함합니다.
- including Attributeds or not
- mentioning named entities
- high-level concepts
- describing salient parts
- finer(세세한) datails
서베의 논문의 기여
- visual encoding 모델과 language model
- pre-training paradigm과 masked langauge model losses
- dataset
- domain-generic
- domain-specific
- metrics for evaluation
- comparison of the main captioning mtehods
- many variants of the task
2. Visual Encoding
input image로부터 효율적인 representation을 뽑아내는 것은 이미지 캡셔닝의 첫번째 단계입니다.
요즘에는 이런 visual encoding 문제를 아래와 같이 4개로 나눠서 바라볼 수 있습니다.
- non-attentive methods(global CNN features)
- additive attentive methods(using grdis or regions)
- graph-based methods(considering relationships between visual regions
- self-attentive methods(using region-based, patch-based, image-text early fusion)(based on Transformer)
2.1. Global CNN Features
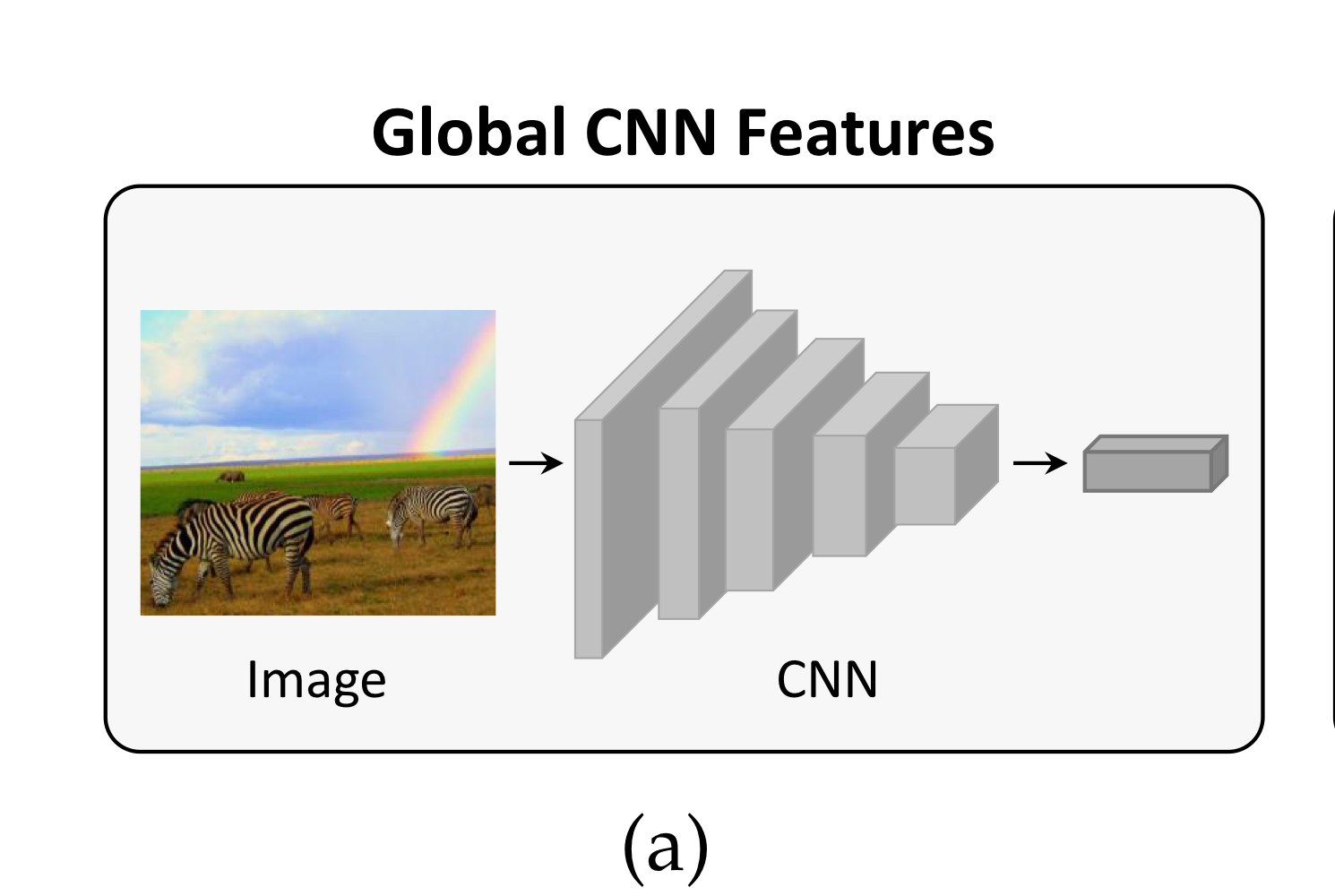
우리가 일반적으로 사용하는 CNN입니다.
CNN 모델을 이용해 input image의 feature를 뽑아낼 수 있고, 특히 top layers에 가까운 activation을 택할수록, high-level representation을 추출하게 됩니다.
그 후, 이렇게 추출한 representation은 language model의 input(혹은 condition)으로 주어집니다.
사실 이런 아이디어의 시초는 연구 "Show and Tell"에서 사용됐습니다.
즉, 이미지에서 뽑아낸 정보를 language model의 hidden state에 넣어줌으로써 이미지와 언어 간 관계를 보는 것입니다.
그 외에도 AlexNet으로 뽑아낸 정보를 language model의 input으로 넣어주거나, VGG로 뽑아낸 정보를 매 time step 마다 넣어주거나 했던 연구들이 많았습니다.
이런 초기 연구들을 토대로, Global CNN features는 다양한 image captioning model에도 쓰였습니다.
2017년에는 연구 "Self Critical Sequence Training for Image Captioning"에서 Resnet을 이용해 이미지를 인코딩했고, 특히, 이미지의 기존 차원을 유지하는 FC model을 사용했습니다.
그 외에도, training captions에 많이 포함된 단어들에 대한 확률 분포를 나타내는 high-level attributes or tags를 이미지와 같이 사용해 더 나은 language model을 만드는 방법들도 있었습니다.
이렇듯 CNN으로 global features를 뽑아 사용하는 것은 굉장히 간단하고, 잘 압축된 representation을 사용할 수 있는 장점이 있긴 했으나, 이미지의 전체적인 맥락만을 받았기 때문에 정보가 과도하게 압축되거나, 섬세하지 않은 representation을 사용하는 단점도 있었습니다.
이런 문제들은 captioning model이 구체적이고 세밀한 descriptions을 생성하지 못하도록 제한했습니다.
CNN이 이미지의 세밀한 부분이 아닌 전체적인 맥락만을 고려한다는 것은 CNN의 last layers(top laerys) 근처에 있는 activation을 사용했을 때를 일컫습니다.
2.2. Attention Over Grid of CNN Features
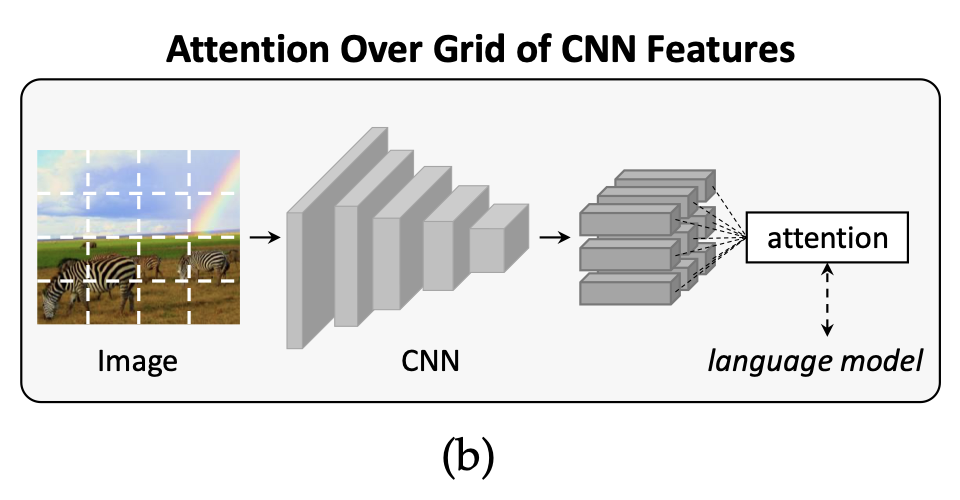
CNN 기반 방법들을 이용해 Representation을 추출하는 것에는 global features만 있는 것이 아닙니다.
위에서 언급한 CNN global features의 단점이 있었기 때문에, 추후 연구 중에는 1D global feature vectors를 2D activation maps으로 대체해 language model에 공간(spatial) 정보도 제공하려는
연구들도 있었습니다.
기계 번역에서 attention 모델이 성공하고 있던 시기였기 때문에 captioning model에도 additive attention mechanism이 쓰였고, 이로부터 "time-varying visual feature encodings이 가능해져 세밀한 representation을 생성할 수 있었습니다.
2.2.1. Definition of additive attention
Attention 관련 기법들의 기반은 weighted averaging이라 할 수 있습니다.
뭐 key와 query를 통해 얻은 attention weights(합이 1)를 value와 그대로 내적해서 나온 값을 사용하므로.
특히, additive attention은 Bahdanau attention으로 불리는, sequence alignment에 관한 연구에 처음 쓰였습니다.
(concat Attention과 additive Attention은 같은 의미로 씅딥니다)
https://velog.io/@sjinu/개념정리-Attention-Mechanism
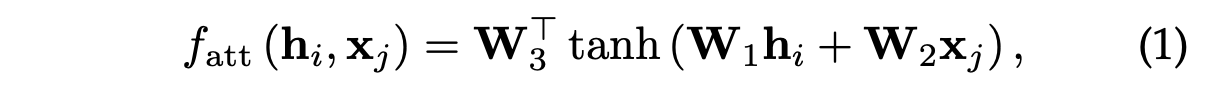
은 linear combination을 수행하는 weight vector(학습 가능한 vector) 위의 연산 결과로 얻게 되는 는 Attention Score가 됩니다.
물론 Bahdanau Attention에서는 아마 위와 같은 용어가 쓰이진 않은 걸로 기억하지만, 그냥 편의상 Attention 용어 사용
그 후, softmax를 통해 Attention weights 확률 분포를 얻고, 이로부터 인코더의 시퀀스들()이 decoder의 token 와 얼마나 연관이 있는 지에 대한 정보를 얻을 수 있습니다.
위와 같이 Attention은 기본적으로 nlp 내 encoder-decoder sequences를 다루기 위해 나왔지만, 점차 이미지 분야에도 적용돼 visual repersentation-language model간 커넥션을 다루는 데에도 널리 쓰이게 됩니다.
2.2.2. Attending convolutional activations
Additive Attention을 CNN의 2d output grid에 사용한 최초의 방법은 연구 “Show, attend and tell: Neural image caption generation with visual attention,” in ICML, 2015.입니다.
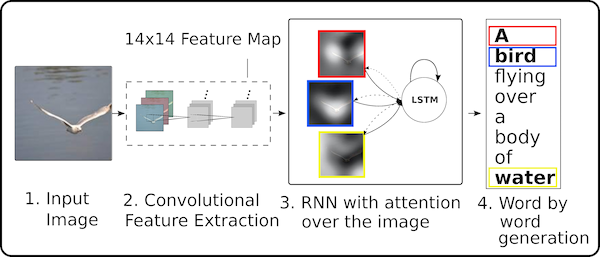
즉, 2d 이미지를 마치 1d sequence로 여기고, language model에 생성하는 문장과 attention을 계산한 최초의 연구입니다.
구체적으로는, VGG networks에서 마지막 convolution layer의 activation을 뽑아 디코더 단계의 hidden vector와 attention을 적용합니다.
마지막 convolution layer의 activation은 2d인데, 각 위치에 해당하는 activation은 모두 차원의 representation을 가지게 됩니다.
즉, time step에서 나온 디코더의 hidden state 과 각 위치에 해당하는 representation 와 dot product 등의 attention을 수행해 스코어를 뽑게 됩니다.
이렇게 수행한 attention weight를 기반으로 다음 단어를 뽑는 데 중요한 이미지의 영역을 알 수 있습니다(다음 단어를 추출하는 데에도 영향을 주고).
2.2.3. Other approaches
Review networks
- encdoer의 hidden states에서 attention을 수행하는 'review step'을 가짐
- 이 과정에서 나온 'thought vector'를 decoder의 attention 과정에 쓰임.
Multi-Level features
-
convolution activations 간의 channel-wise attention을 제안함.
-
하나의 activations이 아닌, 여러 개의 activations을 사용함(Multi-level features).
-
총체적인 정보를 파악하기 위해 여러 개의 CNNs을 사용한 다른 연구도 있음.
-
모두 이미지 단계에서 강화한 연구로, 해당 정보를 바탕으로 RNN 과정에 사용함
[51] L. Chen, H. Zhang, J. Xiao, L. Nie, J. Shao, W. Liu, and T.- S. Chua, “SCA-CNN: Spatial and Channel-wise Attention in Convolutional Networks for Image Captioning,” in CVPR, 2017.
[52] W. Jiang, L. Ma, Y.-G. Jiang, W. Liu, and T. Zhang, “Recurrent Fusion Network for Image Captioning,” in ECCV, 2018.
Exploiting human attention
- 몇몇 연구는 saliency information(사람이 보통 이미지에서 인식하는, 두드러진 곳)을 통합해 caption generation에 사용함.
- 이를 stimulus-based attention이라고도 함.
- human eye fixations을 활용해 soft-attention module의 input으로 사용한 연구도 있음.
- 즉, 인간이 시선이 머무르는 영역에 더욱 가중치를 주는 방법.
2.3. Attention Over Visual Regions
saliency를 사용하는 직관은 뇌과학쪽에서도 많이 쓰였는데, 이는 인간이 주로 이미지를 볼 때 top-down 추론 과정과 bottom-up의 시각 흐름을 통합한다는 것을 시사합니다.
- top-down path : 지식과 직관을 기반으로 sensory input을 예측
- bottom-up flow : 이전의 예측을 조정하는 시각적 자극을 제공
이 때, 이전까지 다룬 Additive attention은 top-down systems으로 생각할 수 있습니다.
다음 단어를 예측하는데 feature grid와의 attention을 사용하지만, 기하학적으로 이미지의 내용과 grid는 상관이 없기 때문.
2.3.1. Bottom-up and top-down attention
saliency based 방법들과 다르게 object detector를 활용해 bottom-up path를 정의한 연구도 있습니다.
"Bottom-up and top-down atteniton for image captioning and visual question answering", in CVPR, 2018.
이 bottom-up path는 각 단어 예측에 쓰이는 이미지 영역에 가중치를 부여하는 top-down mechanism(이전에 계속 다루던..)과 합쳐서 사용되게 됩니다.
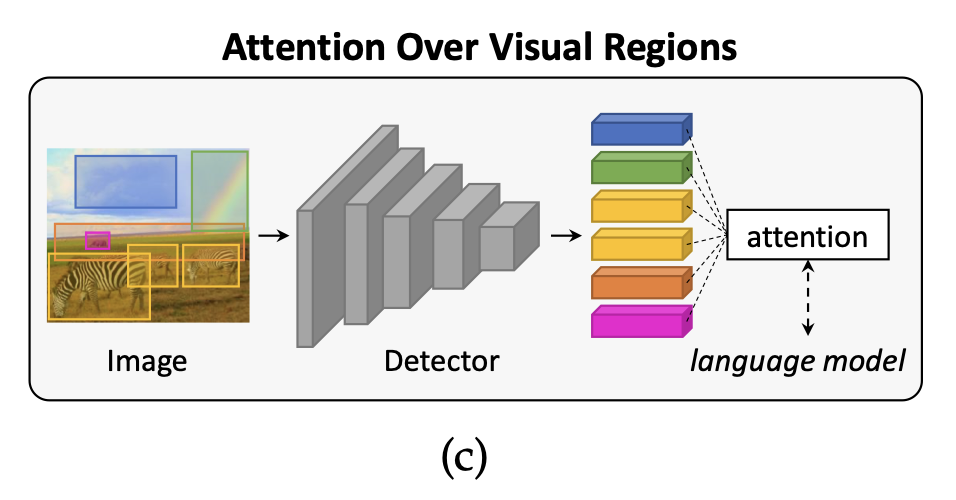
주로 Bottom-up path(object region)을 뽑아내는 데에는 Faster R-CNN계열 모델이 쓰입니다.
다만, 이런 모델들을 사용하는 데 있어서 중요한 요소는 pre-training 전략에 있습니다.
여기서 말하는 pre-training 전략이란, Visual Genome(멀티모달 데이터의 일종)에 대한 클래스와 함께 attribute classes를 예측하는 데 쓰이는 보조 학습 손실함수를 추가해 학습하는 것을 말합니다.
(Image annotation을 활용해 Visual 정보와 Language 정보를 통합 학습하는..)
이를 통해 모델은 더욱 dense하고 풍부한 detection을 예측할 수 있어서 salient object와 contextual regions을 잘 뽑아내, 더 좋은 feature representation을 제공해줍니다.
2.3.2. Other Approaches
사실 위에서 설명한 image region features를 사용하는 것은 raw visual input을 다루는 데 강점을 보였고, 그래서 image captioning 분야에서는 나름 사실상의 정석과도 같았습니다.
[62] L. Ke, W. Pei, R. Li, X. Shen, and Y.-W. Tai, “Reflective Decoding Network for Image Captioning,” in ICCV, 2019.
[63] Y. Qin, J. Du, Y. Zhang, and H. Lu, “Look Back and Predict Forward in Image Captioning,” in CVPR, 2019.
[64] L. Huang, W. Wang, Y. Xia, and J. Chen, “Adaptively Aligned Image Captioning via Adaptive Attention Time,” in NeurIPS, 2019.
[65] L. Wang, Z. Bai, Y. Zhang, and H. Lu, “Show, Recall, and Tell: Image Captioning with Recall Mechanism,” in AAAI, 2020.
그래서 몇년 간 이런 visual encoding 방법들에 대한 연구가 많았고, 여기서도 2개정도만 다루도록 하겠습니다.
Visual Policy
전형적인 visual attention은 매 step마다 single image region에 집중합니다만, Zha et al이 제안한 연구는 visual part도 sequential하게 해석하는 sub-policy networks를 제안합니다.
구체적으로는, 이전에 attend한 visual region과 같은 historical visual actions을 (LSTM으로) 인코딩해 다음 visual action을 하는데 context로서 사용합니다.
(“Context-aware visual policy network for fine-grained image captioning,” IEEE, 2019)
Geometric Transforms
Pedersoli et al은 image-specific attention을 생성하기 위해 weakly-supervised 방식으로 region proposal을 regress하는 spatial transformer를 제안했습니다.
(“Areas of Attention for Image Captioning,” in ICCV, 2017.)
2.4. Graph-based Encoding
몇몇 연구는 이미지 인코딩 능력을 강화하기 위해 image regions을 이용한 graph 모델을 구축했습니다.
즉, spatial & semantic connections을 제공함으로써 representation을 풍부하게 했습니다.
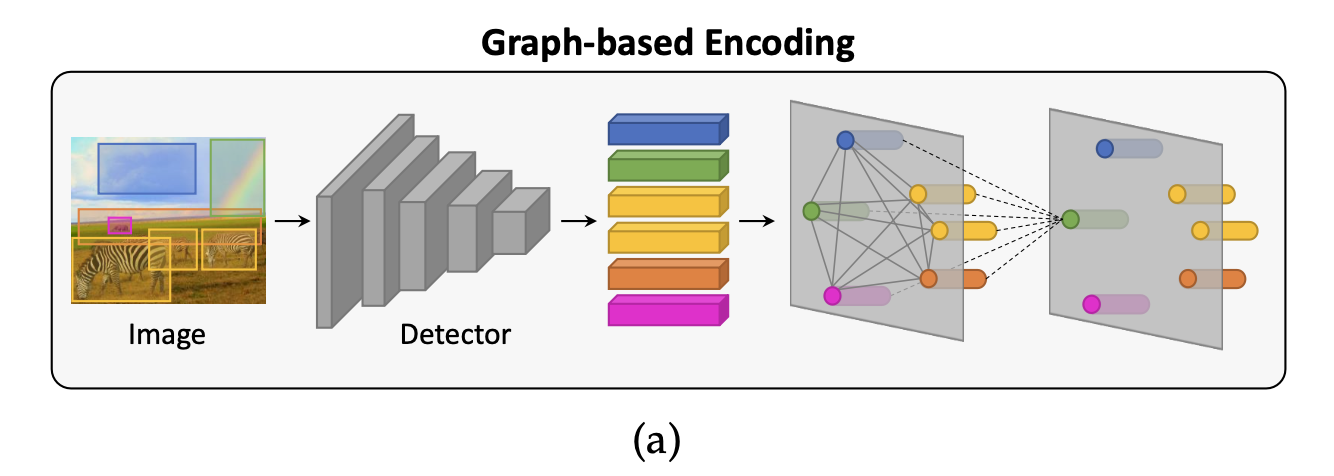
2.4.1 Spatial and semantic graphs
이미지 캡셔닝 & 그래프 관련 분야는 Graph Convolutional Networks를 제안한 Yao et al의 연구가 시초입니다.
[68] T. Yao, Y. Pan, Y. Li, and T. Mei, “Exploring Visual Relationship for Image Captioning,” in ECCV, 2018.
[69] L. Guo, J. Liu, J. Tang, J. Li, W. Luo, and H. Lu, “Aligning linguistic words and visual semantic units for image captioning,” in ACM Multimedia, 2019.
GCN을 활용해 object 간에 공간 정보와 의미 정보를 통합해 사용했습니다.
이 때, 그래프 내의 의미 관계(semantic relationships)는 위에서 잠깐 언급한 Visual Genome에 사전학습 시킨 classifier를 활용해 얻었습니다.
구체적으로 이 classifier는 object pairs 간에 관계나 action을 예측했습니다.
공간적 관계(spatial relationships)은 두 객체(바운딩 박스) 간에 geometry measures(가령, IoU, 상대거리-0과 1사이-, 각도 같은 메트릭들)를 활용해 얻었습니다.
2.4.2. Scene graphs
의미 관계를 모델링하는 데 초점을 맞춘 Yang et al의 연구도 있습니다.
해당 연구는 text에서 얻은 semantic prior를 이미지 인코딩 단계에 적용했습니다.
특히, 이렇게 얻은 representation은 scene graph에 쓰였는데, 객체 간 연결하는 그래프나, 그들 간의 속성이나, 그들 간의 관계를 기술하는 데 쓰입니다.
2.4.3. Hierearchical trees
graph-based encoding의 특별한 예시로, image를 계층적 구조로 표현하는 트리를 사용한 연구도 있습니다.
[73] T. Yao, Y. Pan, Y. Li, and T. Mei, “Hierarchy Parsing for Image Captioning,” in ICCV, 2019.
root는 전체적인 이미지를 표현하며, intermediate nodes는 image regions과 sub-regions을 표현하며, leaves는 region의 segmented objects를 표현합니다.
그래프 인코딩은 detected objects간의 관계를 활용하는 매커니즘인데, 이를 통해 인접한 노드 간 정보의 흐름(교환)을 알 수 있습니다(local manner - 인접한 객체 간 관계이므로).
특히, 이런 방식은 외부적인 의미 정보를 깔끔하게 통합시킬 수 있습니다.
하지만, 당연하게도, 이런 그래프를 손수 구축하는 것은 쉽지 않고, 그렇기 때문에 self-attention을 사용한 모델이 여러모로 성공적인 경우가 많았습니다.
2.5. Self-Attention encoding
self-attention은 nlp에서 먼저 쓰였지만, 이미지 분야에서도 쓰일 수 있습니다.
즉, 특정 input sequence(or set)에서 각 요소 간의 관계를 반복해 모델링함으로써, 더욱 정제된 representation을 얻을 수 있습니다(input의 길이나 차원이 변하지 않고).
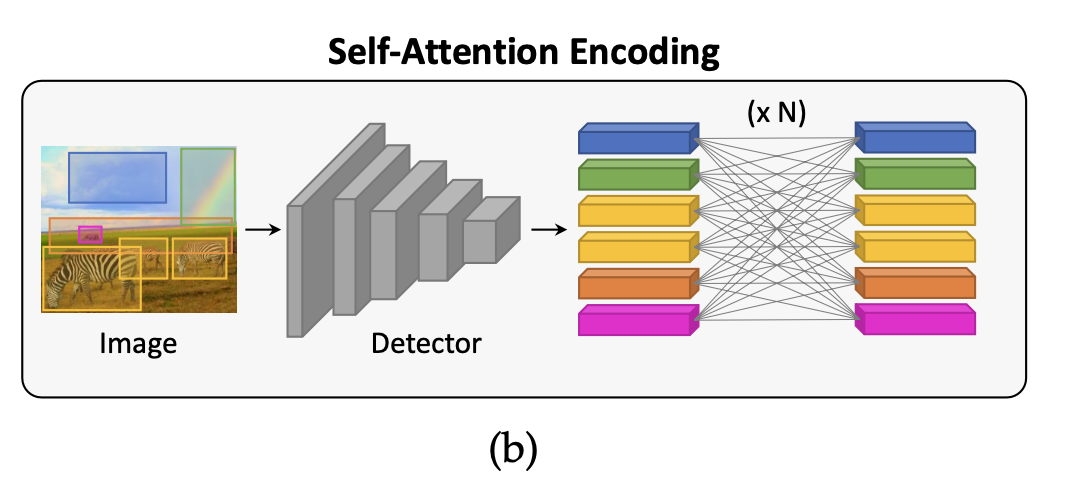
딥러닝의 모든 분야에서 Transformer의 부흥을 불러 일으킨..
2.5.1. Definition of self-attention
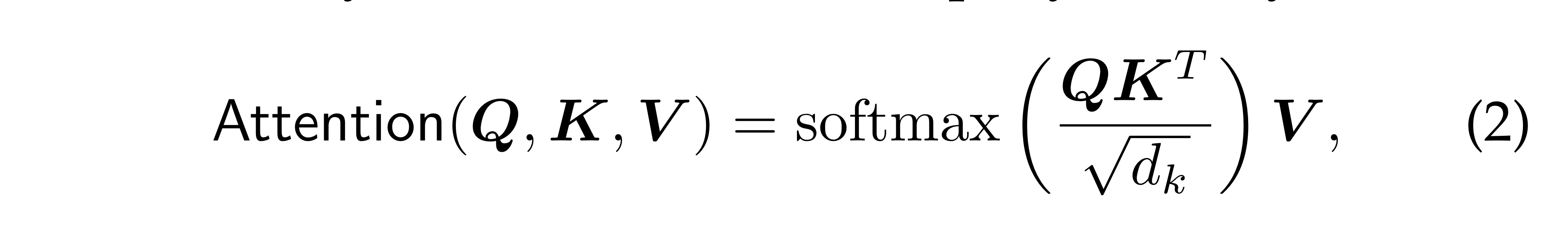
주로 위와 같은 scaled dot-product를 사용해 어텐션을 계산합니다.
Query와 Key간의 유사도를 바탕으로, Value를 가중합해 output을 계산합니다.
특히, self-attention에서는 Q,K,V가 모두 같은 input에서 얻어집니다(project matrix만 다름).
2.5.2. Early self-attention approaches
이미지 캡셔닝 분야에서 self-attention을 처음 사용한 연구는 Yang et al의 연구입니다.
X. Yang, H. Zhang, and J. Cai, “Learning to Collocate Neural Modules for Image Captioning,” in ICCV, 2019.
위의 연구는 object detector로 얻은 image features들을 self-attentive moudle을 이용해 인코딩했습니다.
즉, object regions 간 관계를 인코딩했습니다.
그 후, Li et al은 Visual Encoder로 Transformer를 사용하는 방법을 제안했는데, 아래와 같이 두 개의 인코더로 구성됩니다.
- visual encoder : region features를 인코딩
- semantic encoder : 외부의 tagger를 사용해 얻은 지식을 활용
두 인코더는 모두 self-attention과 feed-forward layers로 구성됩니다(즉, Original Transformer와 유사).
[75] X. Yang, H. Zhang, and J. Cai, “Learning to Collocate Neural Modules for Image Captioning,” in ICCV, 2019.
[76] G. Li, L. Zhu, P. Liu, and Y. Yang, “Entangled Transformer for Image Captioning,” in ICCV, 2019.
2.5.3. Variants of the self-attention operator
반면, Self-attention을 이미지 캡셔닝 태스크에 맞게 수정한 연구들도 있습니다.
Geometry-aware encoding
Herdade et al은 regions의 spatial relationships을 고려한 모델을 제안했습니다.
S. Herdade, A. Kappeler, K. Boakye, and J. Soares, “Image Cap- tioning: Transforming Objects into Words,” in NeurIPS, 2019.
특히, 객체 간 추가적인 geometric weight를 계산해 attention weight를 스케일링하는데 쓰였씁니다.
비슷하게, Guo et al은 noramlized-geometry-aware attention을 제안했는데, 객체 간 상대적인 정보를 활용합니다.
He et al은 더 나아가서 spatial graph transformer를 제안했는데, 이는 객체 간에 각기 다른 공간 관계를 고려해 Attention 과정에 활용했습니다.
가령, parent, neighbor, child 같은..
S. He, W. Liao, H. R. Tavakoli, M. Yang, B. Rosenhahn, and N. Pugeault, “Image captioning through image transformer,” in ACCV, 2020.
Attention on Attention
context에 의해 결정되는 gate를 final attended information과 같이 결합해 사용하는 모델도 있습니다.
[79] L. Huang, W. Wang, J. Chen, and X.-Y. Wei, “Attention on Attention for Image Captioning,” in ICCV, 2019.
[83] F. Liu, X. Ren, X. Wu, S. Ge, W. Fan, Y. Zou, and X. Sun, “Prophet Attention: Predicting Attention with Future Attention,” in NeurIPS, 2020.
즉, self-attention의 output과 query가 concat된 다음, information & gate vector와 같이 연산됩니다.
Encoder에서 visual features를 정제하기 위해 사용됐습니다.
X-Linear Attention
Pan et al은 attended features의 표현 능력을 강화하는 bilinear pooling techniques을 사용한 방법을 제안했습니다.
[80] Y. Pan, T. Yao, Y. Li, and T. Mei, “X-Linear Attention Networks for Image Captioning,” in CVPR, 2020.
특히, region-level의 features와 image-level features를 통합한 결과를 얻을 수 있습니다(higher-order interaction을 활용).
Bilinear pooling이 2nd-order, 저자가 제안한 X-LAN을 쌓아서 더 높은 order의 feature interaction을 추출할 수 있습니다.
단순히 dot-product로 attention하는 것을 1st-order로 볼 수 있고 멀티모달의 정보를 모두 활용하기에는 약간의 한계가 존재합니다.
(Query : Decoder(LAngauge), Key : Encoder(Image..)
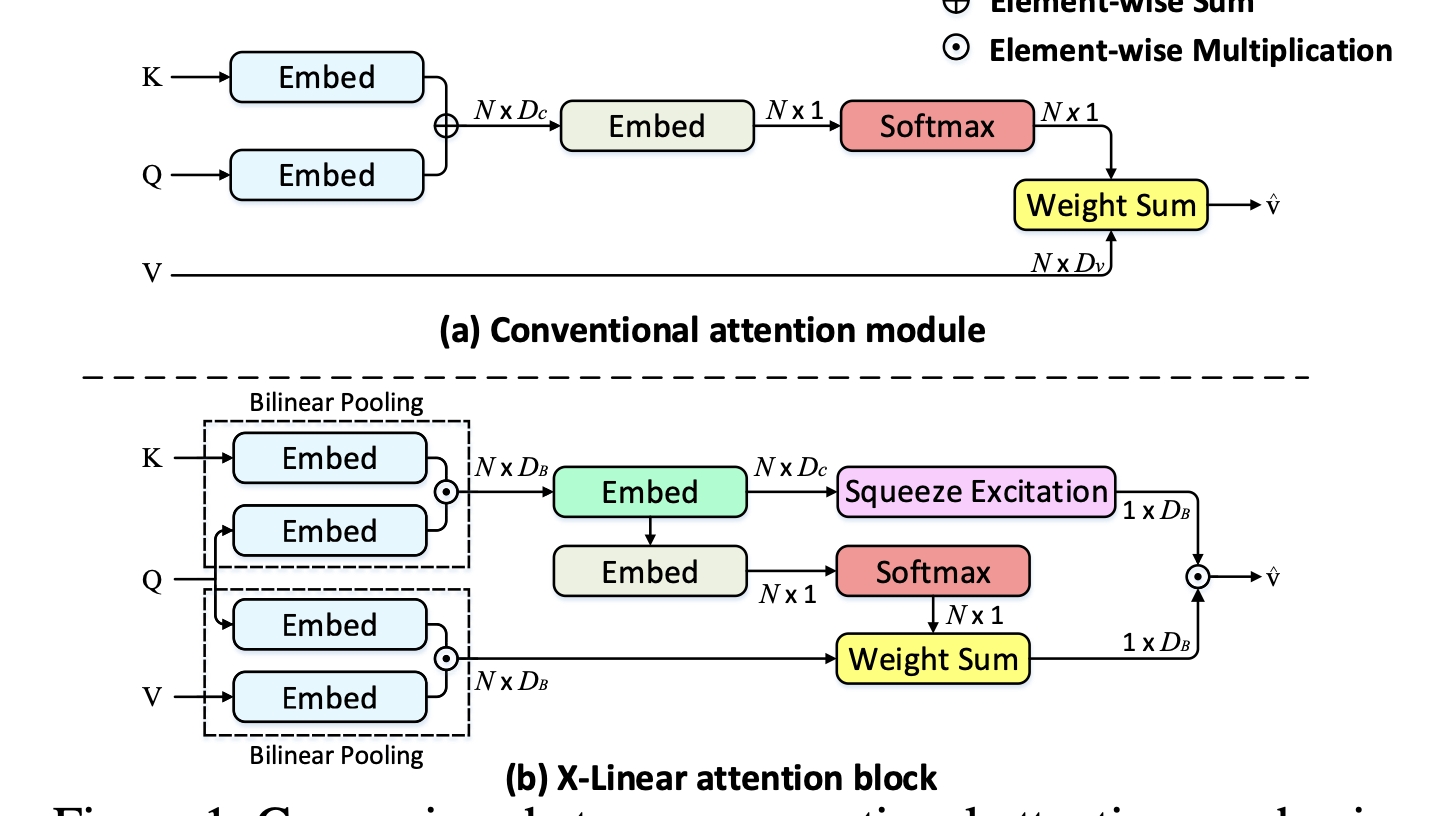
Memory-augmented Attention
특히, Transformer 기반 아키텍처 중 encoder layer에서의 attention 과정에 memory vector를 활용하는 연구도 있습니다.
특히, key와 value에 추가적인 slots을 부여해서, multi-level visual relation ships을 더욱 잘 인코딩할 수 있게 됩니다.
[81] M. Cornia, M. Stefanini, L. Baraldi, and R. Cucchiara, “Meshed-Memory Transformer for Image Captioning,” in CVPR, 2020.
[84] M. Cornia, L. Baraldi, and R. Cucchiara, “SMArT: Training Shal-low Memory-aware Transformers for Robotic Explainability,” in ICRA, 2020.
2.5.4. Other self-attention-based approaches**
그 밖에, 기존의 region-level representation을 보완해, intra-layer representation 뿐만 아니라 inter-layer Global representation을 얻는 연구도 있습니다.
J. Ji, Y. Luo, X. Sun, F. Chen, G. Luo, Y. Wu, Y. Gao, and R. Ji, “Improving Image Captioning by Leveraging Intra- and Inter- layer Global Representation in Transformer Network,” in AAAI, 2021.
대강 layer 내부의 vector 표현과, layer 간의 information을 모두 잘 활용해, adaptive하게 decoder에 도움을 주는 모델 정도.
이외에도 grid features(CNN의 global features)와 region features(R-CNN 계열의 region features)을 결합해 사용하는 모델도 있습니다.
self-attention이 각각의 module에 독립적으로 적용되고, 이들 간의 융합을 위해 지역적으로 cross-attention을 적용하게 됩니다.
Y. Luo, J. Ji, X. Sun, L. Cao, Y. Wu, F. Huang, C.-W. Lin, and R. Ji, “Dual-Level Collaborative Transformer for Image Captioning,” in AAAI, 2021.
semantic-grounded encodings를 얻기 위해 concept extractor로 추출한 visual words와 기존의 grid(or detection) features를 정렬시키는 모델도 있습니다.
F. Liu, Y. Liu, X. Ren, X. He, and X. Sun, “Aligning visual regions and textual concepts for semantic-grounded image representa- tions,” in NeurIPS, 2019.
2.5.5. Attention on grid features and patches
위에서는 모두 detections features에 attention을 적용하는 데 치중했습니다만, 최근 grid features의 역할에 대해서 재평가되고 있습니다.
예를 들어, grid features에 self-attention을 직접적으로 적용해, 기하학적 관계를 통합한다거나, convolution을 아예 사용하지 않고 Transformer에 바로 태운다거나(Vi-T)...
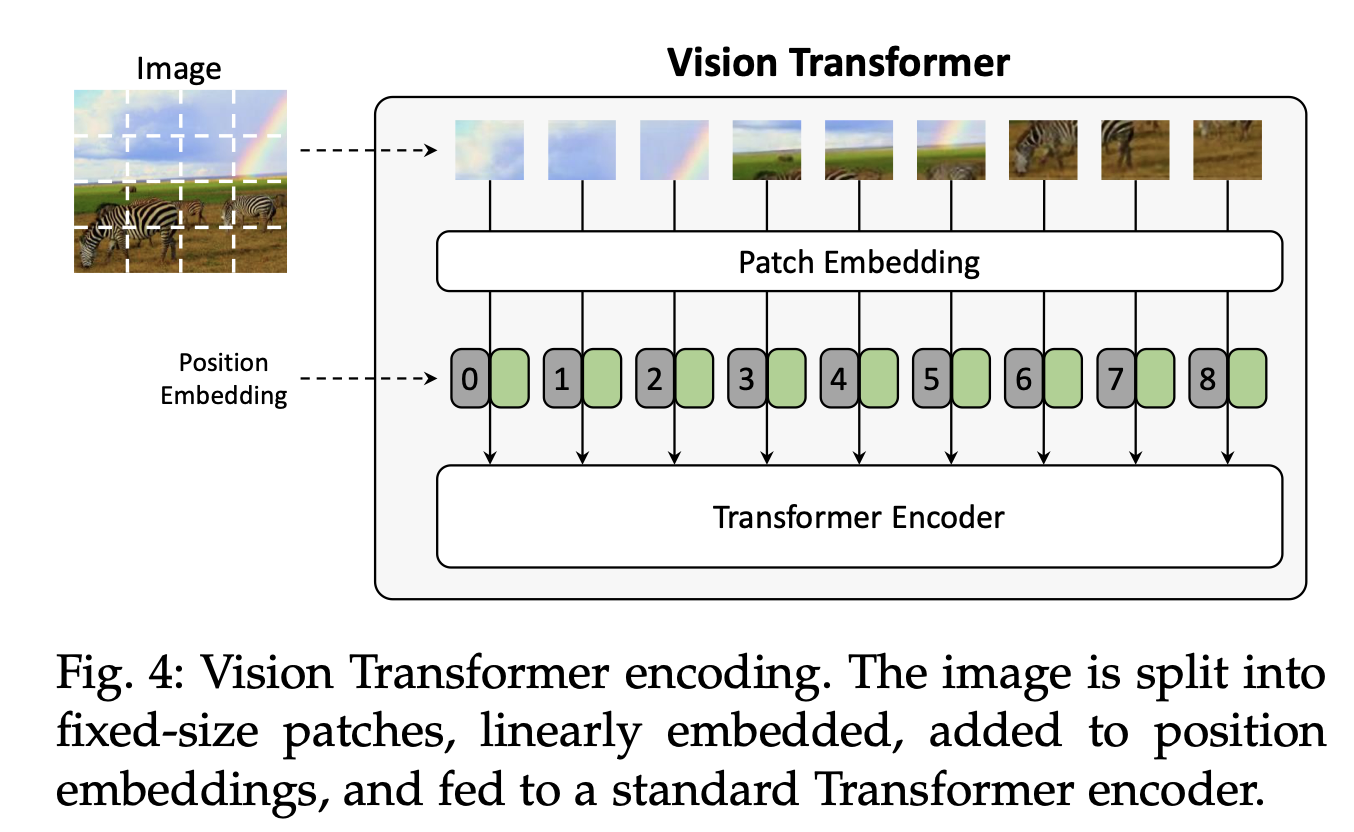
[88] H. Jiang, I. Misra, M. Rohrbach, E. Learned-Miller, and X. Chen,“In defense of grid features for visual question answering,” in CVPR, 2020.
[89] X. Zhang, X. Sun, Y. Luo, J. Ji, Y. Zhou, Y. Wu, F. Huang, and R. Ji, “RSTNet: Captioning with Adaptive Attention on Visual and Non-Visual Words,” in CVPR, 2021.
[90] A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly et al., “An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale,” ICLR, 2021.
특히, 이 사전학습된 Vi-T를 인코더와 일반적인 트랜스포머 디코더를 활용해 이미지 캡셔닝에 적용한 연구도 있었습니다.
W. Liu, S. Chen, L. Guo, X. Zhu, and J. Liu, “CPTR: Full Transformer Network for Image Captioning,” arXiv preprint arXiv:2101.10804, 2021.
특히, 같은 방법을 바탕으로 하는 CLIP 같은 연구에서 도출된 CLIP-based features는 이후에 나오는 캡셔닝 연구들에도 쓰였습니다.
[93]A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agar- wal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever, “Learning Transferable Visual Models From Natural Language Supervision,” arXiv preprint arXiv:2103.00020, 2021.
[94] Z. Wang, J. Yu, A. W. Yu, Z. Dai, Y. Tsvetkov, and Y. Cao, “SimVLM: Simple visual language model pretraining with weak supervision,” arXiv preprint arXiv:2108.10904, 2021.
[95] S. Shen, L. H. Li, H. Tan, M. Bansal, A. Rohrbach, K.-W. Chang, Z. Yao, and K. Keutzer, “How Much Can CLIP Benefit Vision- and-Language Tasks?” arXiv preprint arXiv:2107.06383, 2021.
[96] R. Mokady, A. Hertz, and A. H. Bermano, “ClipCap: CLIP Prefix for Image Captioning,”arXiv preprint arXiv:2111.09734, 2021.
[97] M. Cornia, L. Baraldi, G. Fiameni, and R. Cucchiara, “Universal Captioner: Long-Tail Vision-and-Language Model Training through Content-Style Separation,” arXiv preprint arXiv:2111.12727, 2021.
2.5.6. Early fusion and vision-language pre-training
Visual features를 self-attention함으로써 인코딩하는 방법론들 덕분에 visual-langauge pre-training model들도 널리 개발되고 있습니다.
예를 들어, 마치 DALL-E처럼 Vision tokens과 language tokens을 single stream으로 바라보고 학습하는 방법이 있습니다.
[101] L. Zhou, H. Palangi, L. Zhang, H. Hu, J. J. Corso, and J. Gao, “Unified Vision-Language Pre-Training for Image Captioning and VQA,” in AAAI, 2020.
뿐만 아니라 OSCAR라는, Image와 Language사이의 연결고리(anchor point - object tags)을 필두로 joint representation을 학습하는 BERT기반 모델도 있습니다.
특히, 해당 모델은 650만개 가량의 image-text paris를 학습하면서, 기존의 makked tokne loss 외에 'words-tags-region'의 (data) triplet을 구별하는 constrastive loss를 활용해서 학습했습니다.
후에는 VinVL 이라는, OSCAR를 활용해 더 나은 visual features를 추출할 수 있는 object detector를 도입했습니다.
[100] X. Li, X. Yin, C. Li, P. Zhang, X. Hu, L. Zhang, L. Wang, H. Hu, L. Dong, F. Wei et al., “Oscar: Object-semantics aligned pre- training for vision-language tasks,” in ECCV, 2020.
[103] P. Zhang, X. Li, X. Hu, J. Yang, L. Zhang, L. Wang, Y. Choi, and J. Gao, “VinVL: Revisiting visual representations in vision- language models,” in CVPR, 2021.
2.6. Discussion
global features와 grid features의 등장 이후로, region-based features가 사실상 SoTA를 위한 정석적인 선택으로 쓰여 왔습니다.
하지만, 잘 학습된 grid features(위의 [88])부터, self-attentive visual encoder(ViT), 그리고 large-scale multi-modal model(CLIP)까지, 어떤 모델이 이미지 캡셔닝이 좋은지에 대한 활발한 논의가 진행되고 있습니다.
즉, large-scale data에 object detector를 잘 학습하거나(위의 [103]), 아니면 detector 뿐만 아니라 end-to-end visual model을 처음부터 학습하거나(위의 [94]Sim-VLM)할 수 있습니다.
textual information을 비전-랭귀지 간에 통합하기 위해서 image-text를 시작부터 fusion해 학습하는 BERT-like 모델들도 많았습니다.
