
[기초] DataBase
데이터베이스(Database, DB)는 여러 사람이 공유할 목적으로 체계화하여 통합, 관리하는 데이터의 집합입니다. 단순히 데이터를 저장하는 것을 넘어, 효율적으로 관리하고 필요할 때 신속하게 접근할 수 있도록 지원하는 정보 저장소입니다. 핵심 기능체계적 저장: 데이
[기초] GitHub
형상 관리(Configuration Management) 또는 버전 관리(Version Control)는 소프트웨어 개발 과정에서 소스 코드와 관련 파일들의 변경 사항을 체계적으로 추적하고 관리하는 시스템입니다. 형상 관리 시스템은 다음과 같은 핵심 기능을 제공합니다:
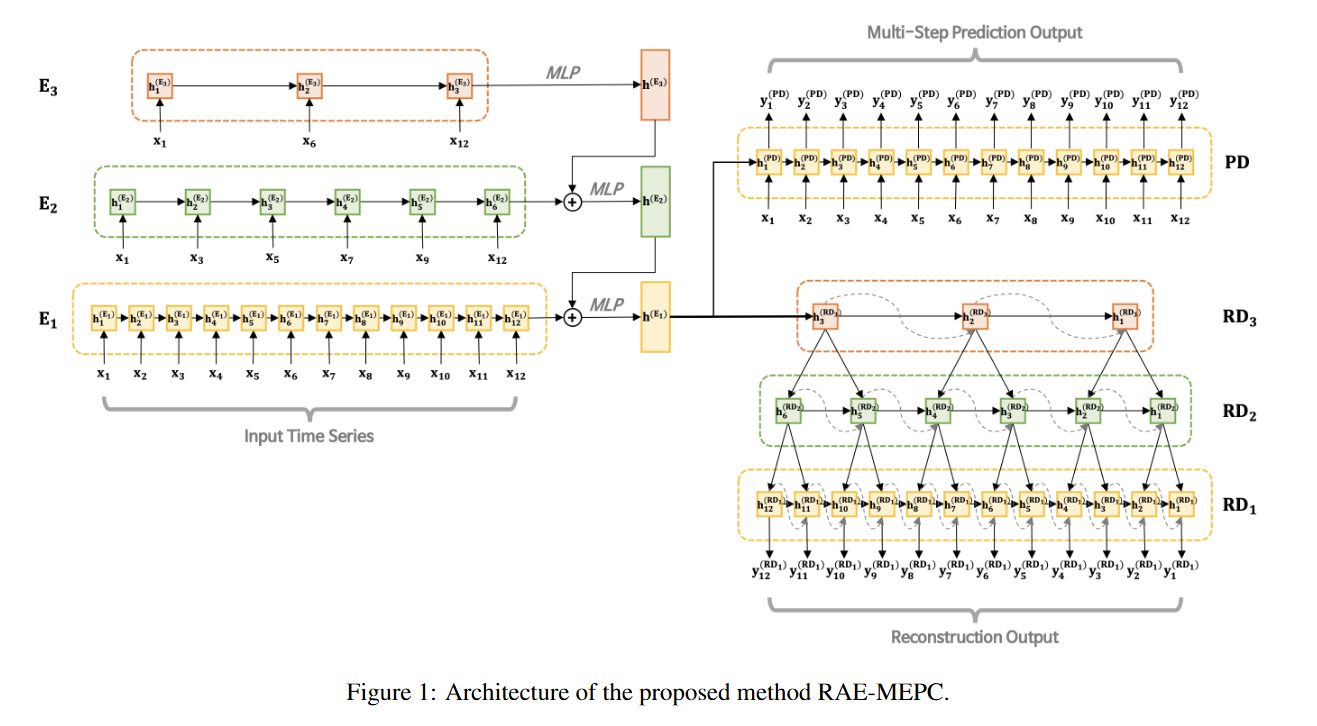
[논문 분석] 이상치 탐지 : RAE-MEPC
논문 제목 : Recurrent Auto-Encoder with Multi-Resolution Ensemble and Predictive Coding for Multivariate Time-Series Anomaly Detection실세계 애플리케이션에서는 대규모 다변
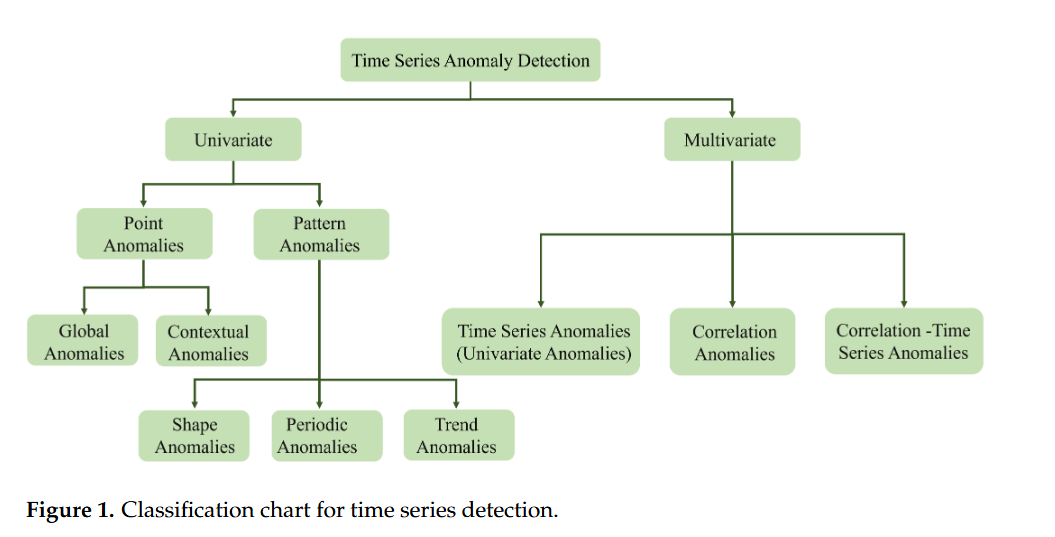
[논문 분석] 이상치 탐지 : MCA-VAE
산업 자동화와 IoT 기술의 급속한 발전으로 공장 환경에서는 대규모 다차원 시계열 데이터가 지속적으로 생성되고 있다. 이러한 환경에서 이상 탐지는 설비 고장, 생산 중단, 비용 손실을 방지하기 위한 핵심 기술로 자리 잡았다. 따라서 이상 탐지 알고리즘은 높은 정확도뿐
[Python] 메모리/속도 최적화 방법
데이터 사이언스 작업에서 메모리와 속도 최적화는 대용량 데이터 처리의 핵심입니다. Python의 Pandas와 NumPy를 중심으로 한 데이터 처리 라이브러리들은 편의성이 뛰어나지만, 최적화 없이 사용하면 메모리 부족이나 처리 속도 저하 문제가 발생할 수 있습니다.
@LRU_CACHE
functools.lru_cache는 Python에서 한 줄의 데코레이터만으로 반복 계산을 제거할 수 있기 때문에, 성능 개선을 목적으로 자주 선택되는 비교적 쉽게 적용할 수 있는 최적화 수단이다. 하지만 실제 실무에서는 단순히 "빠르게 만든다"는 이유만으로 적용했다가
[기초] CNN-LSTM, LSTM-AE
1. LSTM AutoEncoder LSTM Autoencoder와 시퀀스 입력–출력 구조 1. 시퀀스 모델에서의 입력–출력 구조 순환 신경망(RNN) 및 LSTM 계열 모델은 입력과 출력이 시간 축을 따라 어떻게 대응되는가에 따라 여러 구조로 구분된다. 이러한

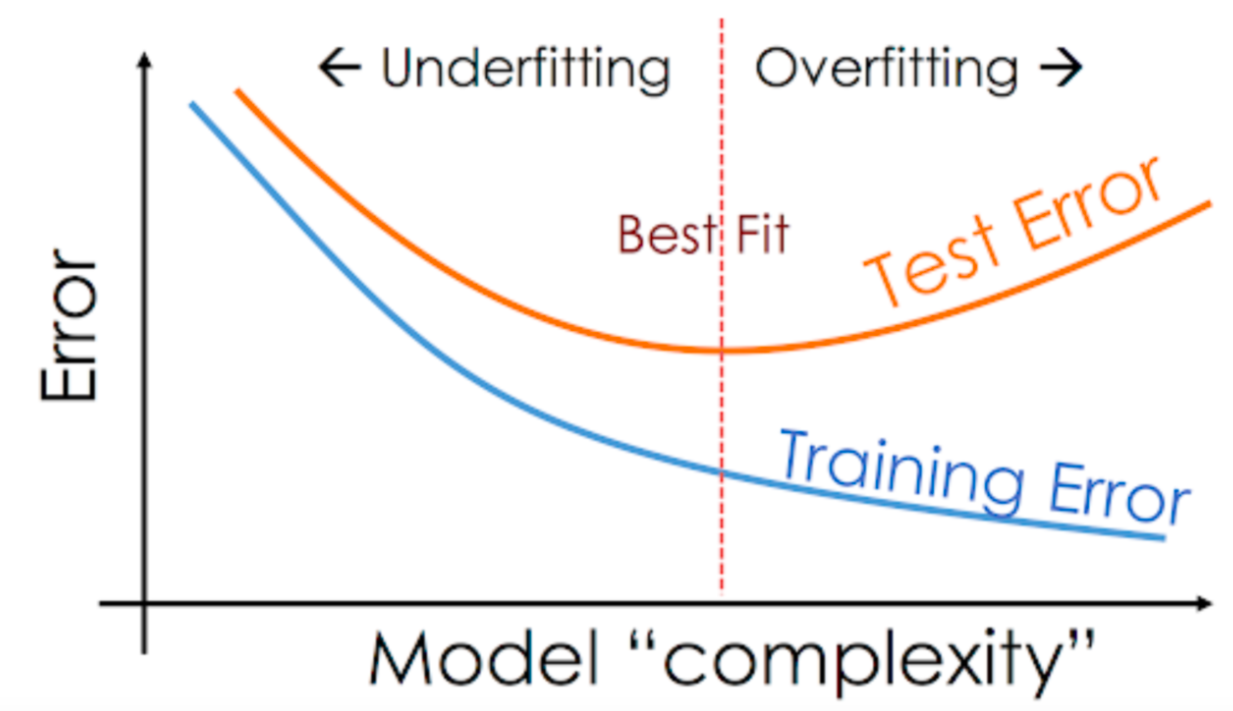
[기초] 딥러닝 학습
오버피팅(overfitting)이란, 학습된 모델이 훈련 데이터(training data) 에는 매우 높은 성능을 보이지만, 학습에 사용되지 않은 시험 데이터(test data) 나 실제 환경의 새로운 데이터에 대해서는 성능이 급격히 저하되는 현상을 의미한다. 이는 모
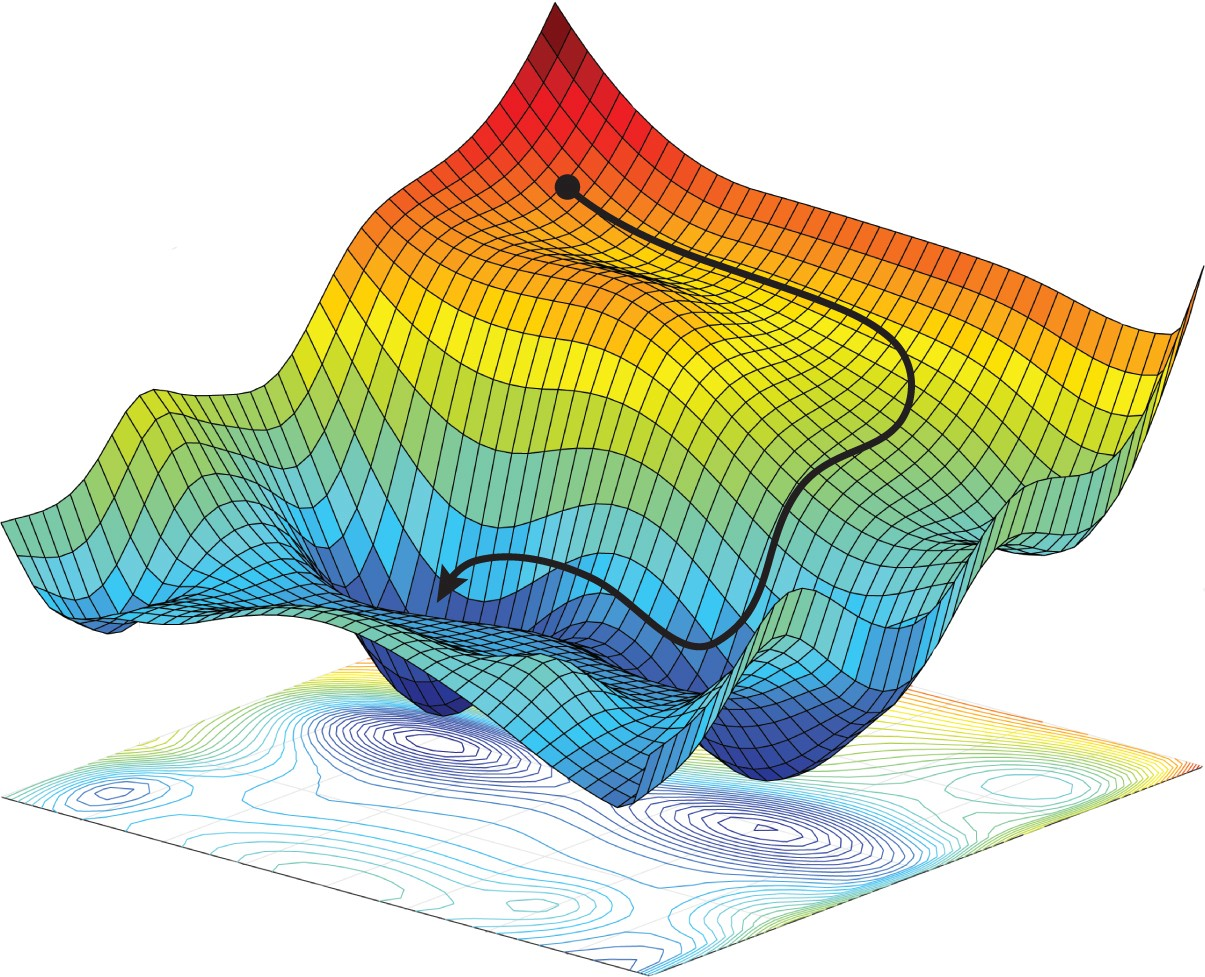
[기초] 딥러닝 최적화와 초기화
딥러닝 모델은 다음과 같은 최적화 문제로 정의된다.$$\\theta^\* = \\arg\\min\\theta ; \\mathbb{E}{(x,y)\\sim \\mathcal{D}} \\left L(f(x;\\theta), y) \\right$$여기서:( $$\\theta
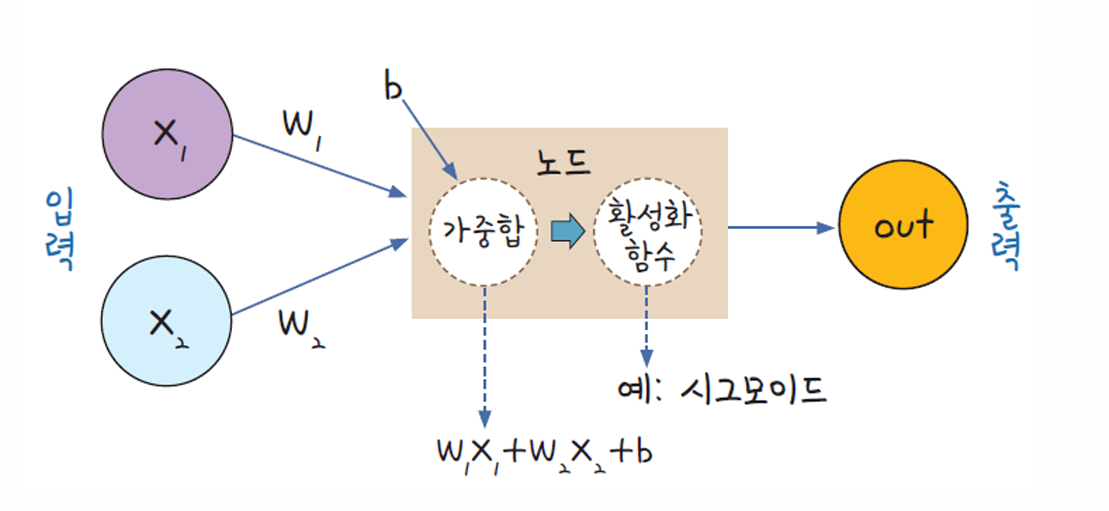
[기초] 퍼셉트론과 다층 퍼셉트론 + 순전파 역전파
인공지능 연구의 핵심 목표 중 하나는 인간의 사고 과정을 수학적·계산적으로 모사하는 것이다. 이러한 시도의 출발점은 뉴런(neuron) 이라는 생물학적 개념에 있다. 인간의 뇌는 수많은 뉴런이 서로 연결되어 정보를 전달하고 처리함으로써 복잡한 판단을 수행한다. 인공 신
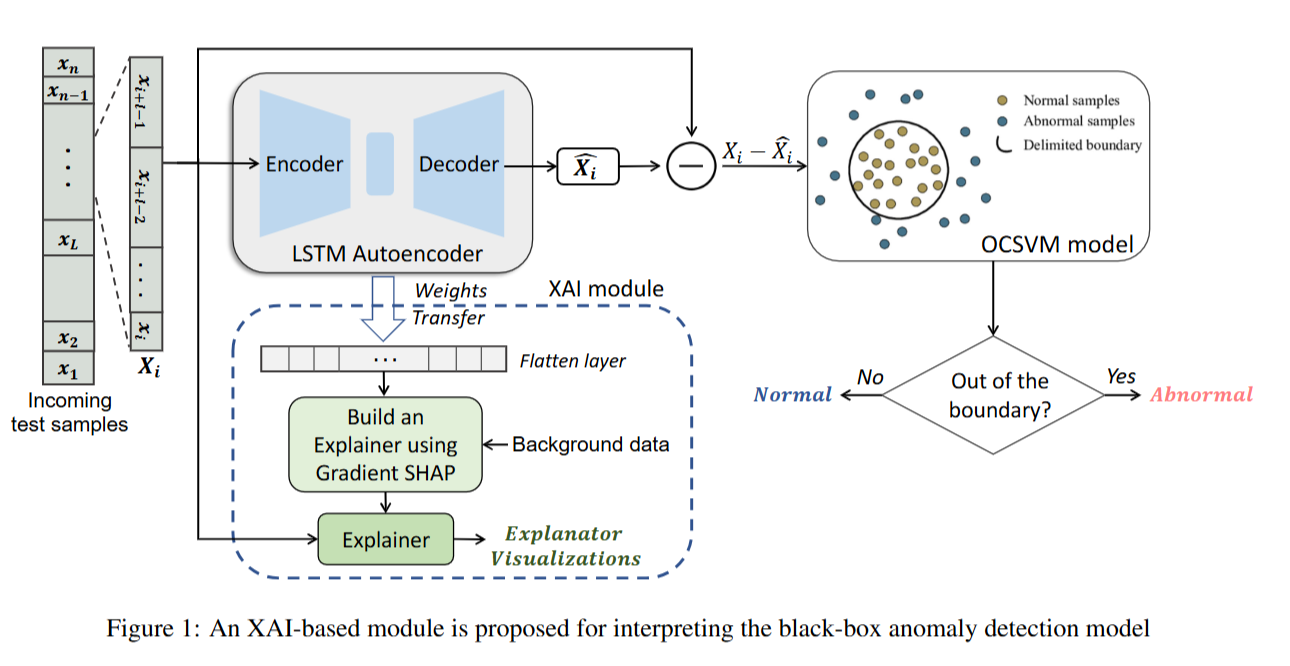
EXPLAINABLE ANOMALY DETECTION FOR INDUSTRIAL
본 연구의 목적은 산업 제어 시스템(ICS)의 사이버 보안 강화를 위해 높은 탐지 성능과 해석 가능성을 동시에 갖춘 이상 탐지(Anomaly Detection, AD) 방법론을 제안하는 것이다.이를 위해 LSTM 오토인코더(Autoencoder) 와 단일 클래스 서포트
[기초] 머신러닝 모델 평가 지표
핵심 질문예측값이 실제값과 얼마나 가까운가?→ 오차(error)의 크기를 어떻게 정의하고 측정할 것인가회귀 모델은 연속적인 값을 예측한다.따라서 평가의 핵심은 예측값 (\\hat{y}) 와 실제값 (y) 사이의 차이를어떤 방식으로 집계하느냐에 있다.가장 직관적인 오차
[기초] 시계열 예측 모델 - RNN 이후의 시계열 모델들
RNN / LSTM / GRU는순서를 순차적으로 처리한다는 명확한 장점을 가졌지만, 그만큼 명확한 한계도 있었다.병렬화가 어렵다시퀀스가 길어질수록 비효율적이다이 문제를 해결하려는 방향에서다음과 같은 시계열 모델들이 등장한다.시간 축 위에서 패턴을 “국소적으로” 훑는다이
[기초] 시계열 예측 모델 - RNN 계열
머신러닝 기반 시계열 접근은 공통된 특징을 가진다.시계열 → 특징(feature) 추출고정 길이 벡터 → 회귀 문제시간 의존성은 간접적으로만 존재RNN 계열 모델은 이 접근에 대한 명확한 문제의식에서 출발한다.“왜 시간 정보를 사람이 요약해야 하는가?”“순서 자체를 모
[기초] 시계열 예측 모델 - 머신러닝
머신러닝 모델은 기본적으로 다음 가정을 전제로 한다.입력 샘플들은 서로 독립(i.i.d.)각 샘플은 고정 길이의 벡터순서 정보는 구조적으로 존재하지 않음이 가정은 시계열 데이터와 정면으로 충돌한다.따라서 머신러닝에서 시계열을 사용하려면,시계열의 “시간적 구조”를 직접
[기초] Feature Selection
피처 셀렉션은 흔히“중요한 피처만 남기는 작업”으로 설명되지만, 이 표현은 본질을 충분히 담지 못한다. 보다 정확히 말하면 피처 셀렉션은모델이 학습해야 할 입력 공간(input space)의 차원과 구조를 통제하는 과정이다. 모델은 입력 공간 위에서 함수 근사를 수행한
[기초] 시계열 데이터 스케일링
시계열 데이터에서 스케일링은단순히 값의 크기를 맞추는 문제가 아니다.시간 흐름을 보존하면서미래 정보를 사용하지 않는 것이 핵심이다.시계열 데이터는 다음이 절대 금지다.이 경우,미래 시점의 통계량이 과거 학습에 사용된다이는 모델 성능을 비현실적으로 부풀린다.시계열 스케일
[기초] 비시계열 데이터 전처리
비시계열 데이터는각 관측값(행)이 시간 순서에 의존하지 않는 데이터를 의미한다.대표적인 예시는 다음과 같다.고객 정보 테이블실험 결과 데이터설문조사 데이터정적인 특성 기반 데이터셋이러한 데이터는 일반적으로행 단위 분석을 전제로 한다.비시계열 데이터 분석은다음 가정을 암
[기초] 시계열 데이터 전처리
시계열 데이터 전처리와 통계적 진단시계열 데이터(Time Series Data)는시간의 흐름에 따라 순차적으로 관측된 데이터를 의미한다.수학적으로는 시간 ( t )에 대해 정의된 확률 변수 ( X_t )의 집합으로 표현된다.이 정의에서 중요한 점은 다음 두 가지다.각