TIL
1.데이터란?
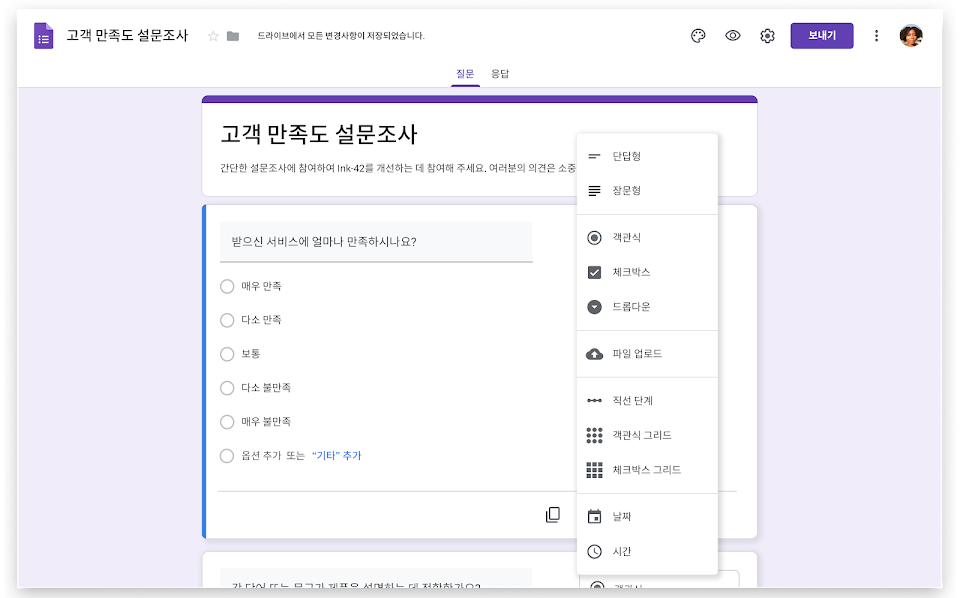
우리 생활 모든 곳에 존재.예를 들어, 우리가 하는 카톡, 주고 받는 영상 등이 모두 다 데이터다.그리고 조별과제 때 한번씩은 경험해봤을 것이다. 설문조사.나는 예전에 설문조사를 통해서 가장 많이 선택된 사안으로 문제를 해결한 경험이 있다. 이처럼 데이터는 우리 주위에
2.데이터 관련 이슈

무분별한 개인 정보 전파같은 데이터, 다른 해석너무 많은 대시보드와 비슷한 테이블불분명한 데이터 오너십등등....
3.데이터 기반 의사결졍
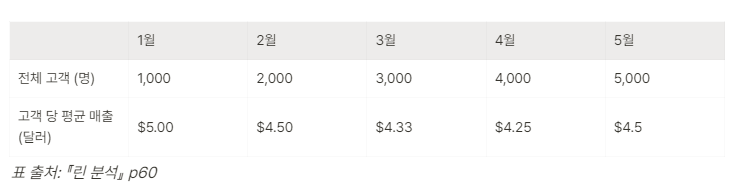
데이터에서 인사이트를 찾는 방법중요 지표를 데이터 기반으로 정의하고 시각화하기가설을 바탕으로 실제 데이터를 보고 확인하기코호트 분석을 통해 고객 이탈률 분석, 고객 잔존률 분석데이터 분석가의 역할중요 지표를 정의하고 이를 대시보드 형태로 시각화대시보드로는 태블로와 룩커
4.Gen AI
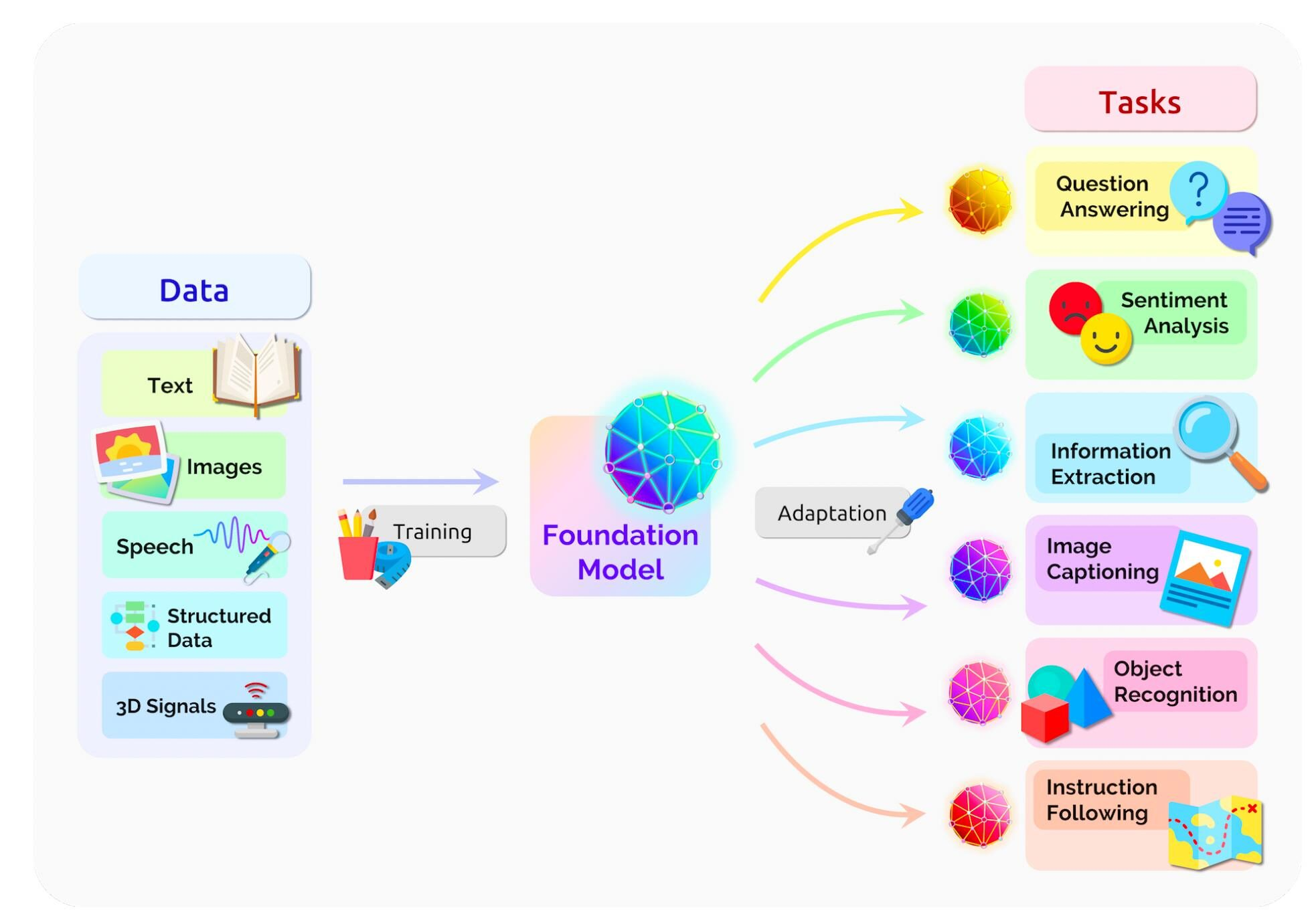
학습된 컨텐츠 바탕으로 새로운 컨텐츠를 만드는 딥러닝 기술생성형 AI딥러닝 안에 Gen AI가 있으며, 그 안에 LLM(Large Language Model)이 있다광범위한 데이터 셋을 학습시킨 러닝 모델 한 유형Pre-trainedUnsupervised Learnin
5.데이터 종류
숫자로 이루어진 데이터숫자 0~9로 이루어짐ex) 4, 1002, 92%년, 월, 일 등 날짜를 표시하이픈이나 슬래시로 표현 가능ex) 2023-10-02핸드폰 번호, 주민등록번호, 숫자, 기호 명칭과 같은 데이터문자와 숫자가 혼합된 데이터ex) 010-1234-567
6.엑셀 데이터 소개 및 함수
모든 범위 값의 합계EX) =SUM(숫자1,숫자2....)모든 범위 값 중의 최소값EX) =MIN(숫자1,숫자2....)최댓값EX) =MAX(숫자1,숫자2....)평균값EX) =AVERAGE(숫자1,숫자2....)가장 많이 사용하는 함수 중 하나특정 값과 예상 값을 비
7.kaggle
https://www.kaggle.com/업로드중..데이터 과학의 현장, 경쟁, 그리고 협업의 메카오늘은 데이터 과학의 현장에서 지식을 쌓고 실전 경험을 쌓을 수 있는 플랫폼 중 하나인 캐글에 대해 알아보려고 한다. 캐글은 데이터 과학자들의 지식 공유, 경쟁,
8.kaggle
https://www.kaggle.com/업로드중..데이터 과학의 현장, 경쟁, 그리고 협업의 메카오늘은 데이터 과학의 현장에서 지식을 쌓고 실전 경험을 쌓을 수 있는 플랫폼 중 하나인 캐글에 대해 알아보려고 한다. 캐글은 데이터 과학자들의 지식 공유, 경쟁,
9.결측치
0이 아닌 값NA: Not AvailableNaN: Not a NumberNull: Nothing실제로 값을 입력하지 않은 경우설문조사 특정 질문에 미응답데이터 오류데이터의 손실을 불러온다데이터 편향이 발생할 수 있다분석된 결과가 부정확할 수 있다.변수의 결측값을 평균
10.SQL & RDB
1. SQL 1. 사용 목적 원하는 형태로 데이터를 조회한다 효율적으로 데이터를 조회한다 간단한 데이터 분석을 수행한다 2. RDBMS vs NoSQL RDBMS RDB: 관계형 데이타 모델에 기초를 둔 데이타베이스다. 관계형 데이타 모델이란 데이타를 구성하는데 필
11.데이터 타입
0과 1로만 구성매우 작은 정수Signed 범위: -127 ~ 127TRUE/FALSEex)작은 정수\-32768 ~ 32767중간 크기 정수\-8388608 ~ 8388608정수\-2147483648 ~ -2147483647int보다 2배 많은 비트를 사용하는 정수\
12.SQL 효율적으로 짜기
최대한 필터링을 해서 집합을 작게 유지한뒤 join하는 것이 좋다. \- 필터링을 먼저 하자쿼리 파인딩실행 시간 측정SELECT @@profilingSET @@profiling = 10이면 off, 1이면 on모르는 테이블을 알아볼 때는 데이터를 일부를 보면서 파악하
13.TIL
이탈자 구하기Recency가 90일 이상인 유저 수 / 총 유저 수 x 100데이터 쿼리이탈자의 자녀 유무(kidhome, teenhome)에 따른 비율십대만 있을 경우: 30%아이만 있을 경우: 21%둘다 있을 경우: 10%둘다 없을 경우: 28%학력이 Graduat
14.sql을 이용한 데이터 분석(2)
사용자ID: 사용자마다 가지고 있는 고유ID세션ID: 사용자의 활동을 tracking 하는 ID \- 세션: 사용자의 방문을 논리적 단위, 사용자가 외부 링크를 타고 오거나 혹은 time session을 두고 뭔가를 하면여러 개의 세션을 가짐채널 이름과 시간 기록한다
15.Group by
테이블 레코드를 그룹핑하여 그룹별로 다양한 정보를 계산그룹핑 할 필드를 결정(하나 이상)그룹별로 계산할 내용 결정여기서 Aggregate 함수COUNT, SUM, AVG, MIN, MAX, LISTAGG...가장 많이 사용되었다는 정의사용자 기반 혹은 세션 기반필요 정
16.CTAS
SELECT를 가지고 테이블 생성간단하게 새로운 테이블을 만드는 방법자주 사용하는 테이블을 미리 만들기다음 두개의 카운트를 비교
17.JOIN
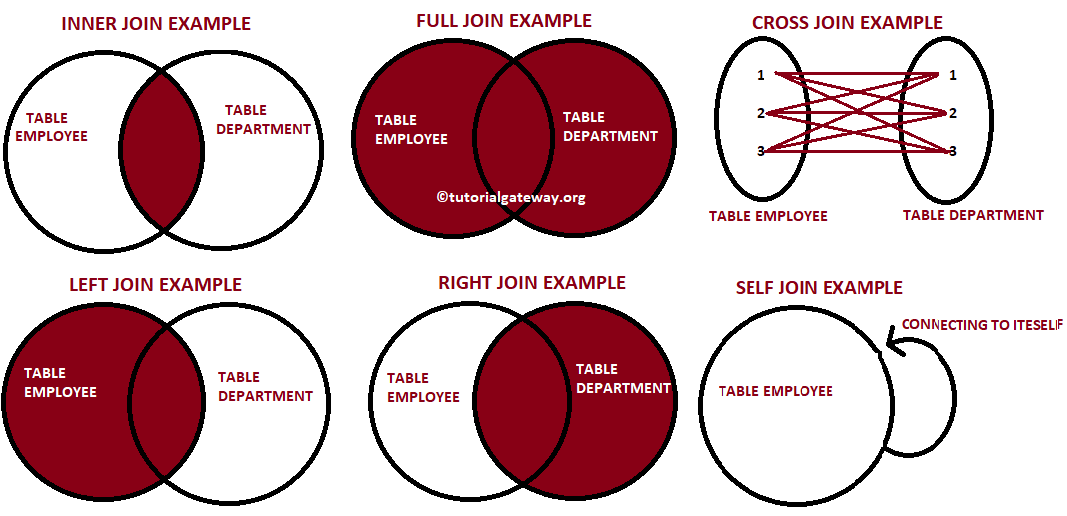
SQL 조인은 두 개 혹은 그 이상의 테이블들을 공통 필드를 가지고 머지하는데 사용한다. 분산되어 있던 정보를 통합하는 데 사용된다. 조인의 방식에 따라 다음 두 가지가 달라진다. 보통 INNER와 LEFT로 95% 해결 가능어떤 레코드들이 선택되는지?어떤 필드들이 채
18.pandas 한글 깨짐 해결
excel 파일을 읽고 google colab에 시각화 기능을 진행하게 되면 이러한 광경을 보게 된다.이는 한글 폰트가 설정되지 않아서이다.이런 식으로 한글 폰트를 install 해준 후에실행해주면 정상적으로 나오는 걸 볼 수 있다.
19.pandas dataframe

type(df): 유형 보기df.info(): 전체적인 구조df.head(): 앞 5열df.head(3): 앞 3열df.tail(): 뒤 5열df.locindex: series 조회df.loc\[\[]]: data frame 조회\-df.loc0:3, "이름":"체중"
20.dataframe

.sum(): 합.sum(axis=0): index 방향, 세로로 합.sum(axis=1): colums 방향, 가로로 합.max(): 최대.min(): 최소.mean(): 평균.median(): 중간값.prod(): 곱셉 연산필요한 column만 가져오기열 순서 바꾸
21.DataFrame 심화

pd.read_csv("", index_col): 파일 읽어오기head(): 상위 5개만 읽기info(): 데이터 프레임 정보(결측치, 데이터, 메모리...)describe().round(): 집계 통계 기술describe(exclude="int", "float"):
22.데이터 분석
궁극적으로 해결하고자 하는 것이 무엇이며, 원인이 무엇이며, 상황을 판단하는 지표나 기준이 무엇이냐풀고자 하는 문제를 명확하게 정의큰 문제를 작은 문제로 정의작은 문제들에 대해 가설을 세우고데이터 분석을 통해 가설을 검증하고 피드백 반영검증해보고자 하는 가설을 해결해주
23.정규화
데이터에서 하나의 sample은 여러 가지 속성 값들을 통해 표현이 가능하다.혹여나 이상치 문제가 심각하거나, 속성 값(feature)들의 크기 및 단위가 다양하고 크게 다른 경우 데이터 분석이 어려워진다.그래서 정규화와 스케일링을 통해 일정하게 맞춰주는 작업이 필요하
24.통계학(1)
통계학: 여러 사건(event)들을 수학적으로 모델링하고, 이를 분석사건은 근본적으로 발생하기 전 불확실성 내포하고 있으므로, 이를 표현할 수 있는 수단이 확률이다Experiment: 동전을 던지는 행위Sample:Experiment의 결과Sample space: Ex
25.기술통계
숫자로 표현되는 수치 데이터를 이용하여 분석주로 평균, 중앙값, 최빈값을 통해 어느 값을 중심으로 뭉쳐있는지 확인분산, 표준편차, 분위수, q1(25%), q3(75%)를 통해 어떤 형태로 퍼져있는지 확인전반적인 주요 통계 확인Numeric: count, mean, s
26.SQL_Analysis
SQL 중요성 데이터 관련 직군 데이터 엔지니어 파이썬, 자바/스칼라, sql, 데이터베이스, etl/elt, spark, hadoop 데이터 분석가 sql, 비즈니스 도메인 지식, 통계(AB 테스트 분석) 데이터 과학자 머신러닝, sql, 파이썬, 통계
27.데이터 시각화
데이터분석 결과를 plot이나 graph를 통해서 시각적으로 전달matplotlib다양한 데이터를 많은 방법으로 도식화 가능
28.데이터웨어하우스
회사에 필요한 모든 데이터 저장프로덕션 데이터 베이스와는 별도여야 함AWS의 Redshift, Snowflake 등고객이 아닌 내부 직원을 위한 데이터 베이스처리속도가 아닌 데이터 크기가 중요ETL OR Data Pipeline데이터를 읽어다가 데이터 웨어하우스에 저장
29.데이터 웨어하우스 & 파이프라인
데이터 레이크 구조화 데이터 + 비구조화 데이터 (로그파일) 보존 기한이 없는 모든 데이터를 원래 형태로 보존 ETL 데이터 레이크와 데이터하우스 바깥에서 안으로 데이터를 가져오는 것 ELT 데이터 레이크와 데이터하우스 안에서 데이터 처리 데이터 소스 프로덕션 데
30.ETL 실습 (with Redshift)
웹상에 존재하는 이름, 성별 csv file을 Redshift 테이블 복사Extract: URL 읽어서 데이터 리턴Transform: data를 name, gender 리스트로 변환하여 리턴Load: list를 Redshift 테이블로 load
31.snowflake
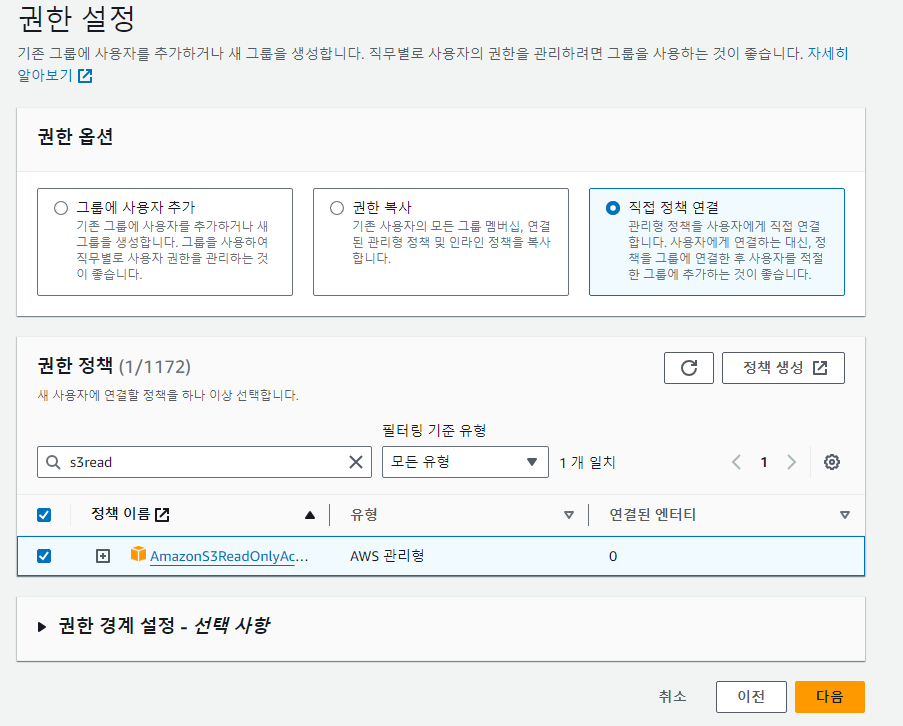
레코드를 하나씩 적재하지 않고 벌크로 레코드들이 있는 파일을 통쨰로 적재레코드 파일들을 클라우드 스토리지에 업로드클라우드 스토리지에 있는 파일을 copy 명령으로 목적 테이블에 적재클라우드 스토리지와 접근 권한 설정이 중요레코드들이 있는 파일들이 적재될 버킷 생성클라우
32.좋은 지표(KPI)
목표 설정과 집중성과 측정의사 결정동기 부여 및 책임감리소스 할당 (우선 순위)커뮤니케이션 (공동의 언어)추상적인 목표를 가시적이고 측정 가능한 목표로 전환조직 내에서 달성하고자 하는 중요한 목표정량적인 숫자 선호명확한 정의KPI의 수는 적을수록 적음Primary vs
33.이커머스 지표 정리
Active 정의단순 로그인? 어떤 행동?페이스북이라면 좋아요, 글을 하나라도 읽기DAU: 하루 기준WAU: 일주일 기준MAU: 한달 기준사용자 이탈률(Churn Rate)보통 월 기준으로 사용자가 우리 서비스를 이탈하는 지 여부반대는 잔존률고객 잔존률: 서비스를 계속
34.마케팅 지표 정리
제품 및 서비스를 고객에게 노출시키는 방법디지털 접점, 오프라인 접점네이버 광고, 구글 광고, TV/신문 광고...고객 접점 경로의 시간 순 기록이 디지털 마케팅 데이터 분석의 시작접점 = Touch point = channel디지털 접점에 우리 서비스에 대한 광고를
35.Superset
다양한 형태의 visualization와 손쉬운 인터페이스대시보드 공유SQLAlchemy와 연동 가능API와 Plugin Architecture 제공으로 확장성 좋음Flask와 React.jssqlite metadata databaseRedis caching layer
36.Tableau

정성적 데이터로, 일반적으로 x축(columns)에 배치됨데이터를 세분화, 분류하는데 사용되는 카테고리Dimension을 사용해 그룹핑, 필터링 수행ex) 제품 이름, 날짜, 지역, 연령대, 부서정량적 데이터, 즉 숫자로 차트의 Y축(Rows)에 표시됨ex) 매출액,
37.EDA
현업에서 깨끗한 데이터란 존재하지 않음데이터 품질 체크중복 레코드 체크최근 데이터 존재 여부 체크Primary key uniqueness 체크값이 비어있는 컬럼이 있는지 체크기술 통계 분석결측치 탐지 및 처리이상치 탐지 및 처리데이터 시각화상관 관계 분석(고급) 피처