
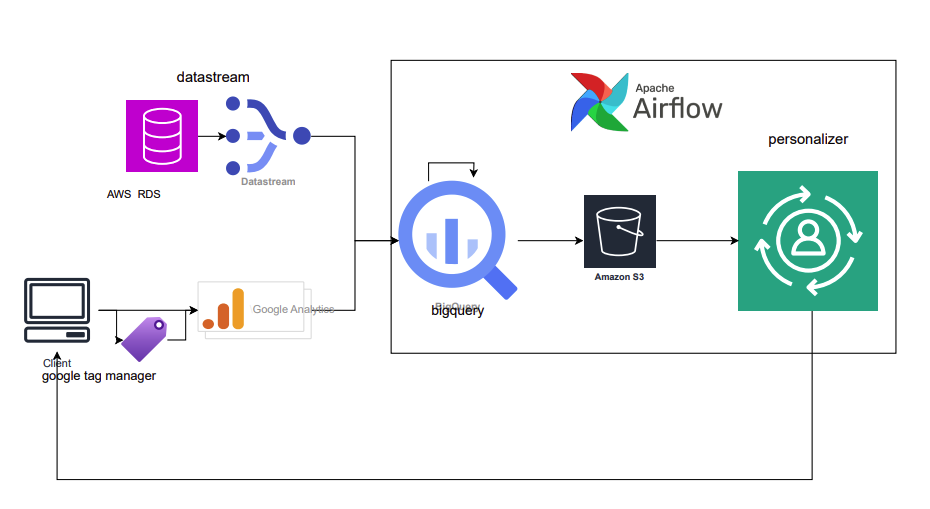
☁️ AWS Personalize로 추천 시스템 구축: 행동 데이터 추가로 성능 2배 향상시키기(feat: Airflow)
클라우드 서비스를 이용한 추천 시스템 구축과 성능 개선을 위한 데이터 파이프라인 구축 및 재학습 파이프라인 구축 과정을 공유하고자 합니다

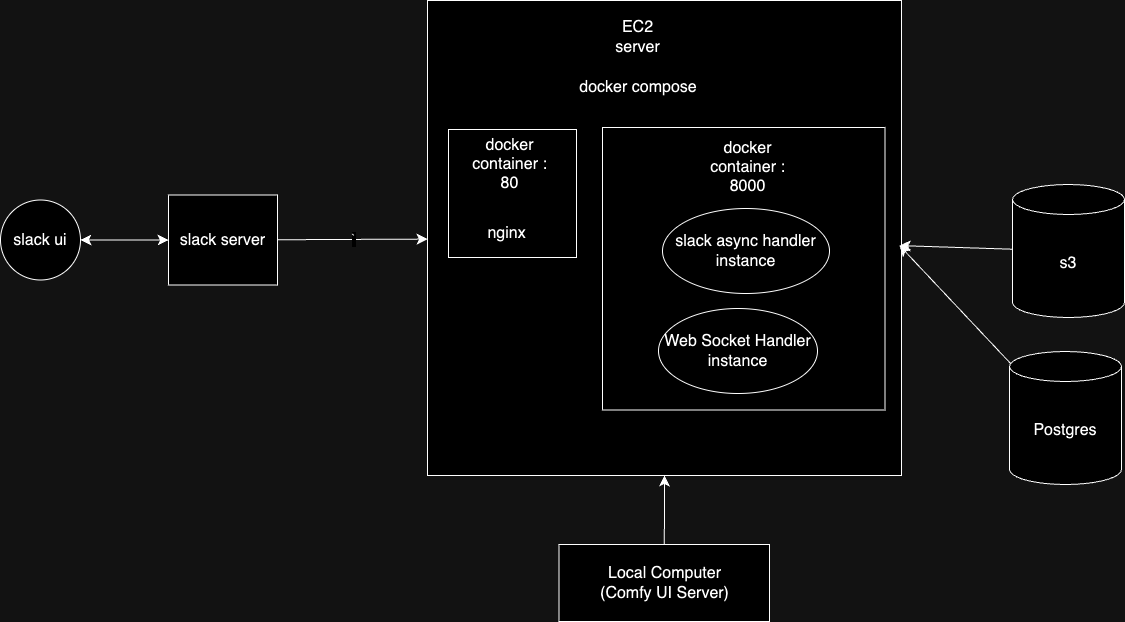
이미지 생성 Slack Bot 만들기
genAI를 사용해보던 중 이미지를 생성하는 slack bot을 만드는 프로젝트를 해보면 재밌겠다고 생각하여 진행해보았습니다 :)

AUTOMATIC1111 을 이용해 Stable Diffusion 맛보기
최근 생성형 AI 기술을 이용해 어떤 서비스 혹은 기능을 개발할 수 있을지에 대해 고민중에 있습니다. 그 과정에서 기술에 대한 깊은 이해에 앞서 해당 기술를 빠르게 사용해볼 수 있는 방법에 대해 공유하고자 합니다 그 중에서도 이미지 혹은 텍스트 기반 이미지 생성 기술

나는 어떻게 팀원들에게 도움이 될 수 있을까?
개인적인 불만일까 해결해야할 문제일까? 팀원들과 업무 회고, 티타임을 진행하다보면 공통적인 '불만 사항'을 발견할 때가 있다. 불만 사항이 지속된다면 팀원들의 만족도는 떨어질 것이고, 만족도가 떨어진다면 적극성이 떨어지며 퇴사, 목표 달성 실패가 발생하고 이는 팀 전체에 급속도로 퍼지게 되어 긍정적인 미래를 기대하기 힘들다. 따라서 '공통적으로 발생하는...
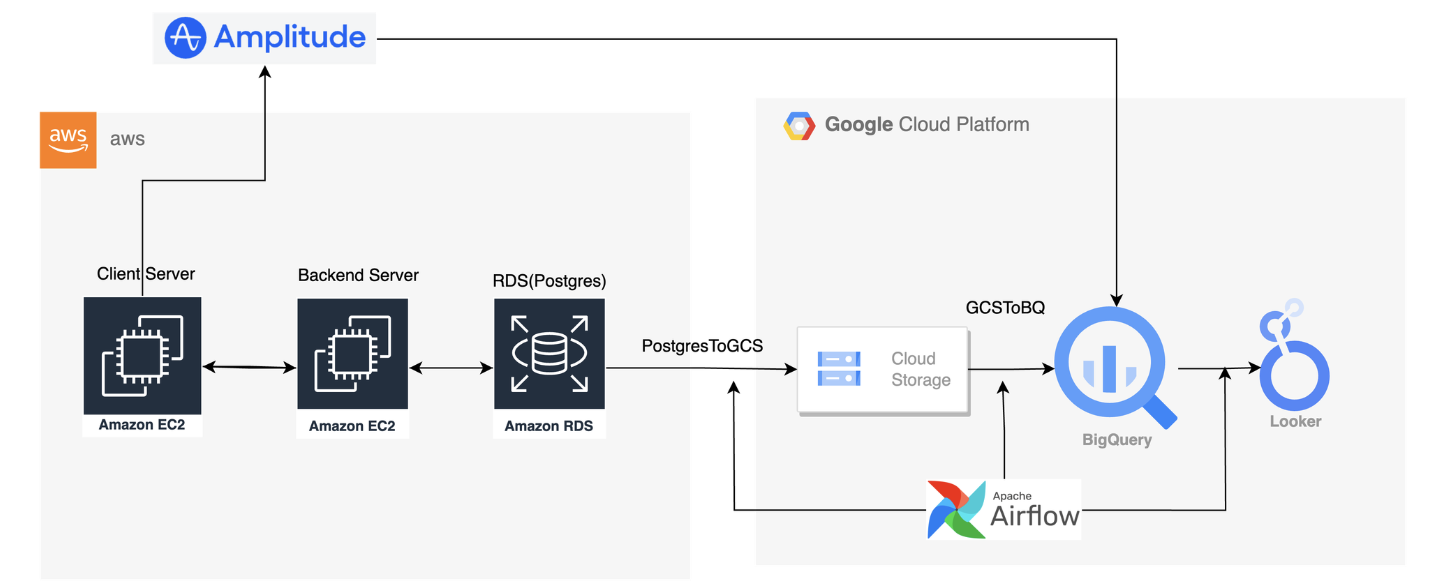
소규모 팀에서 데이터 파이프라인 구축
소규모 팀에서 데이터 파이프라인을 구축하게 된 배경부터 문제 정의에 따른 해결 방법, 마주한 기술적 문제와 배운점에 대해서 기록해보았습니다

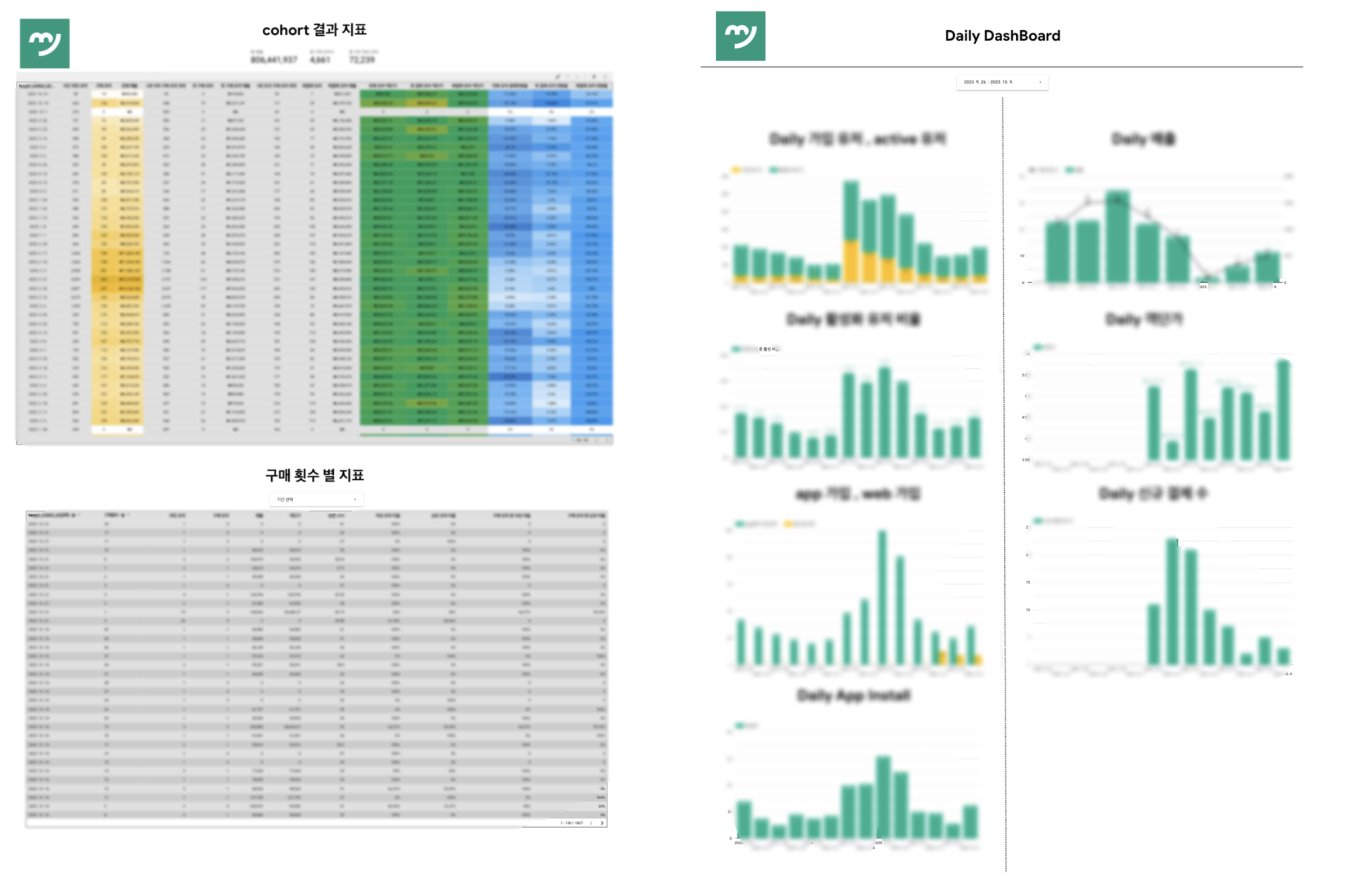
Airflow와 Looker Studio로 대시보드 만들기
데이터를 가치있게 쓰기 방법 중에 하나는 많은 사람들이 데이터에 접근하고 이를 기반으로 생각하고 소통하고 의사결정 하는 것이라고 생각한다. 그러기 위해서는 사용자들이 쉽게 사용할 수 있는 형태로 데이터를 제공해야한다. 팀원들이 데이터에 쉽게 접근하기 위해서는 정제된 데

데이터 파이프라인 구축
데이터 파이프라인? 데이터 파이프라인은 데이터를 사용하기 위해서 데이터를 추출(수집), 가공, 적재하는 과정이다. 데이터를 이용하여 매출, 신규/재 결제 전환율, 활성화 유저의 비율 등 의사결정에 필요한 정보들을 팀에 제공할 수 있다. 뿐만 아니라 수집된 데이터를
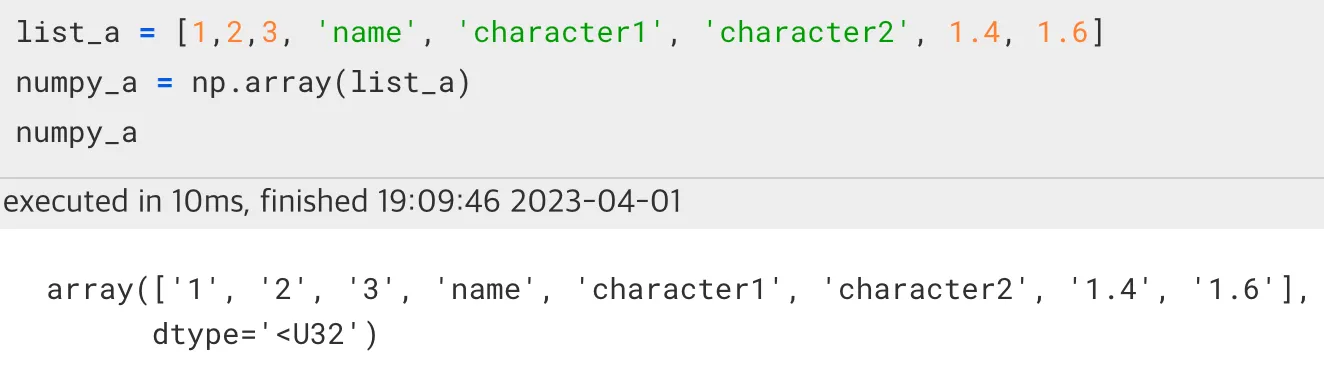
Numpy Structured Array
이전 포스팅에서 numpy array의 빠른 이점에 대해서 알게 되었다.하지만 실제 프로젝트에서는 여러형태의 data type으로 구성된 list를 다룰 경우가 더 많았다. 이럴 때는 어떻게 numpy array를 사용하여 그 이점을 활용할 수 있을까?만약 여러 dat
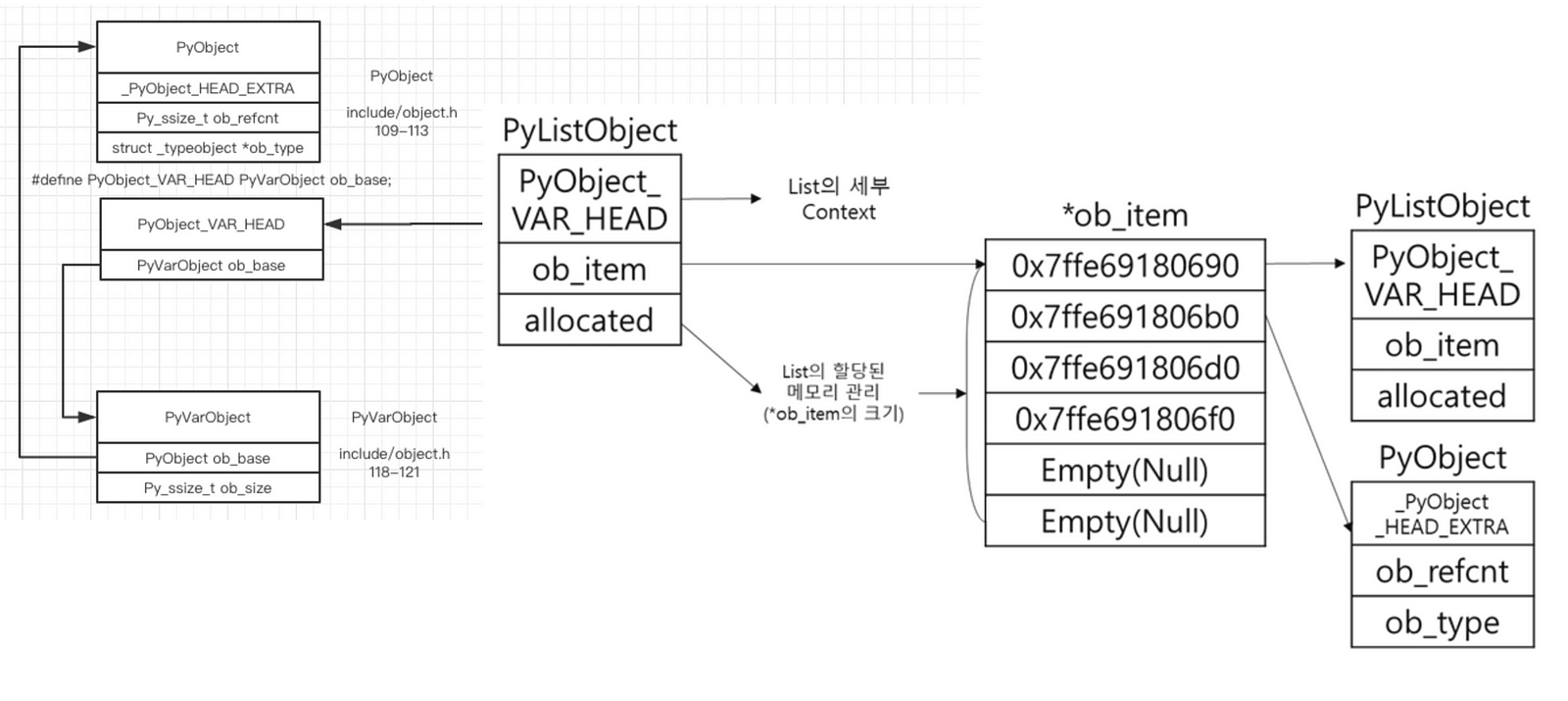
Python list and Numpy array
현재 진행중인 프로젝트에서 많은 상품의 정보를 한 번에 받아놓고 후에 특정 feature에 따른 조건 검사를 할 때 numpy를 사용한다. 이 때 numpy array를 사용한 이유는 numpy가 python list보다 빠른 속도와 메모리 효율을 가지며, vector


Wide and Deep Learning for Recommender Sys 구현
wide & deep 논문을 읽고, 간략하게 모델 구현논문에 언급되었던 wide model에 input으로 주기 위한 cross-product과정은 다음을 참고하였습니다https://github.com/jrzaurin/pytorch-widedeepkeras를
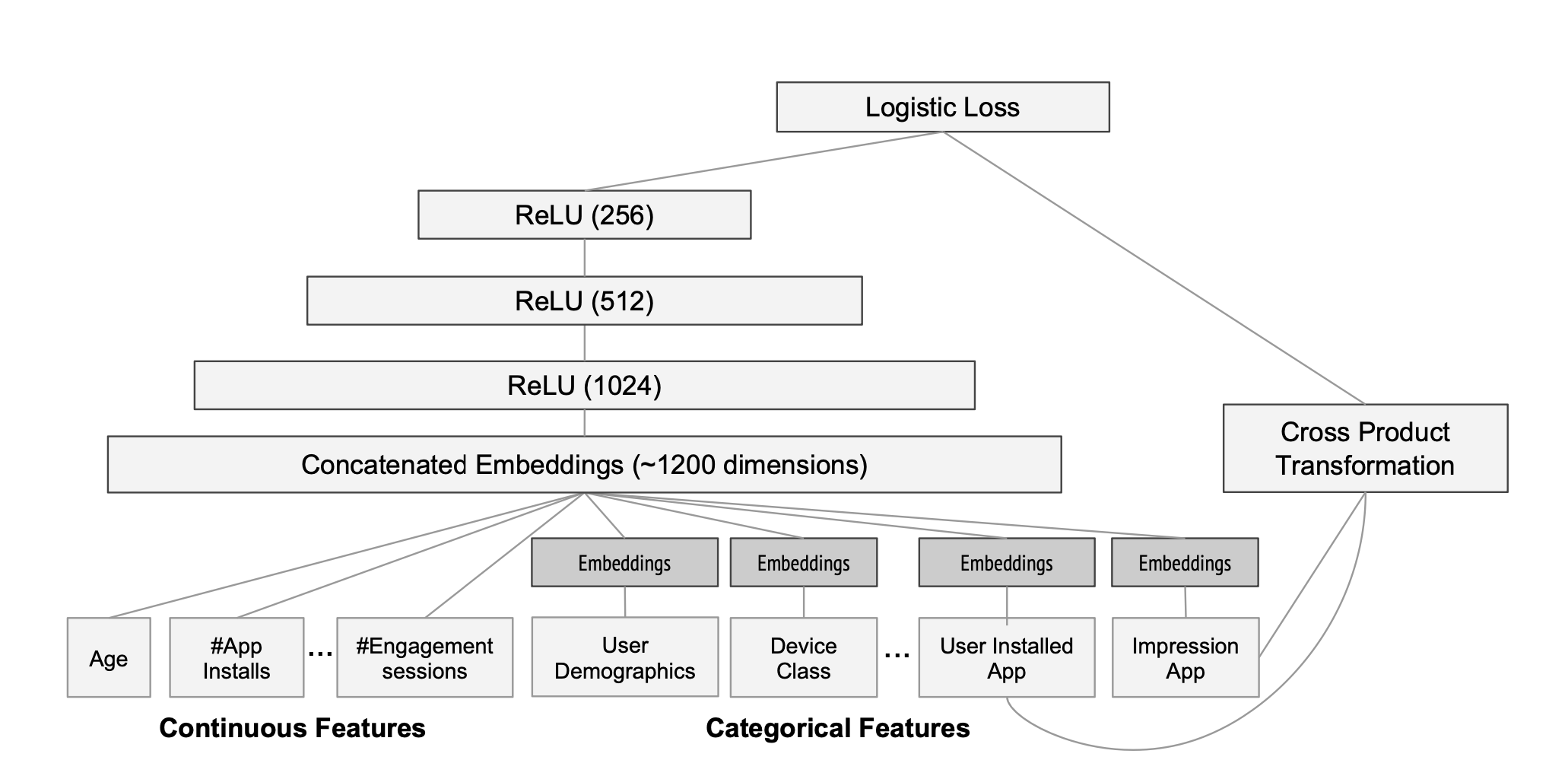
Wide & Deep Learning for Recommender System 논문 읽기
Wide : Memorizationcross-product feature transformations 을 통해 feature간 interaction을 고려할 수 있다more feature engineering effortDeep : Generalizationgenera
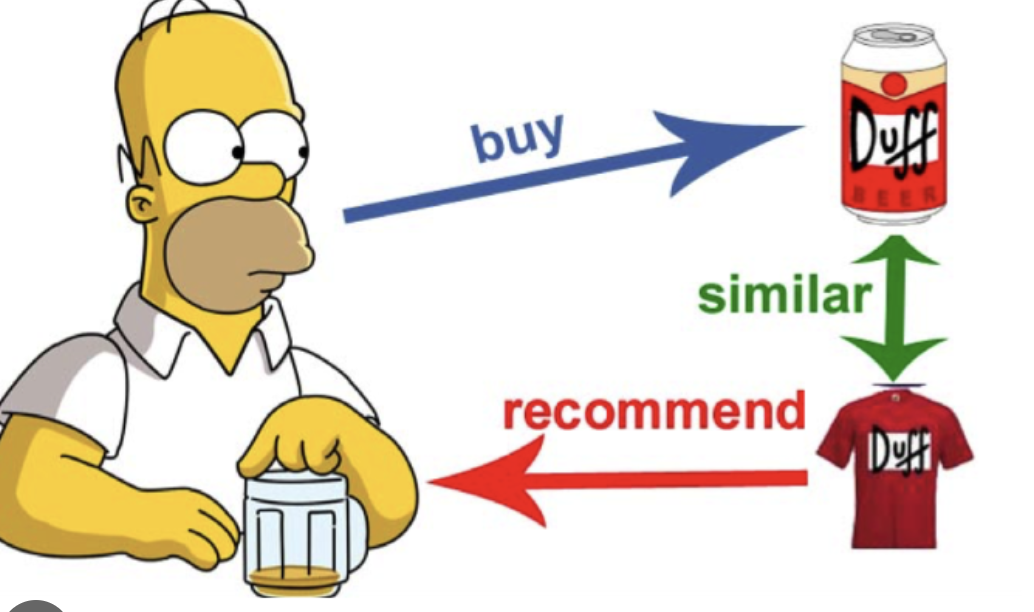
Neural Collaborative Filtering 논문 읽기
Contents Based Filtering유저가 아이템 A를 좋아할 때, A와 비슷한 특징을 갖는 아이템을 추천해주는 방식ex) 장르가 비슷하거나, 감독이 똑같거나 등등Collaborative Filtering사용자의 행동 양식(평점, 구매이력) 을 기반으로 하여 추

YOLO 논문 읽기
Unified, Real-Time Object DetectionUnified: 통합기존 object dection의 방식이 아닌 regressions 문제로 접근한다이미지 전체에 대해 하나의 신경망이 한 번의 계산으로 bounding box와 class probabil

[회고] 2년간의 스타트업 개발자 회고
왜 회고를 하나? '지금 내가 잘 하고있나?'를 묻기 시작하고, 그 시작점에서 이제까지의 일들을 돌아보는 시간을 가져야 겠다고 생각했다. 또 더욱 시간이 지나 기억이 흐려지거나, 왜곡되지 않돌록 하기 위해서 기록을 남기고자했다.혼자 메모장에 적어 남기는 것보다 누군가