0. 읽은 논문들
- [21][2600]ViViT: A Video Vision Transformer
- [22][1010] VideoMAE : Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training
- [22, 12/317] InternVideo: General Video Foundation Models via Generative and Discriminative Learning
- [23, 3][367] VideoMAE V2: Scaling Video Masked Autoencoders with Dual Masking
- [23, 5][562] VideoChat: Chat-Centric Video Understanding
- [24,3][110] INTERNVIDEO2: SCALING FOUNDATION MODELS FOR MULTIMODAL VIDEO UNDERSTANDING
0.1. 그 외
학습시 사용하는 데이터셋
- action clasfication 학습시 사용하는 데이터셋
- video-text caption 데이터셋
- 우리는 아래 데이터셋 중, Kinetics와 SSV2를 위주로 글을 설명해나갈 것이에요. 왜냐면 두 데이터셋은 영상 길이도 다르고, fps도 크게 다른데, 어떻게 학습에 동시에 활용할 것인지가 궁금하기 떄문이에요.
- 그리고 위 2개 데이터셋이 가장 많이 사용되기 때문이에요.
| Dataset | Input Resolution | FPS | 클립 길이 | 특징 |
|---|---|---|---|---|
| Kinetics‑400/600/700 | 원본 영상은 다양하지만, 모델 학습 시 일반적으로 224×224 (또는 256×256)로 리사이즈함 | 약 25 | 약 10초 | YouTube에서 추출된 액션 인식용 클립. 400~700개 클래스의 다양한 인간 활동이 포함됨 |
| Something‑to‑Something V2 (SSV2) | 원본은 다양하나, 후처리 시 224×224 또는 256×256으로 리사이즈하는 경우가 많음 | 약 12 | 평균 약 4초 (2~6초 범위) | 일상적인 사물 조작 및 상호작용과 같이 미세한 시간적 변화를 요구하는 액션 이해에 초점 |
| Charades | 원본 영상은 약 320×240이지만, 학습/평가 시 224×224 또는 256×256 등으로 리사이즈됨 | 약 30 | 평균 약 30초 | 실내에서의 일상 활동을 담은 긴 클립. 복잡한 활동과 상호작용을 포괄함 |
| AVA (Atomic Visual Actions) | 최신 연구에서는 높은 공간 해상도를 위해 448×448로 리사이즈하여 사용하는 경우가 많음 | 약 30 | 3초 (주석 프레임 중심, 전후 1.5초씩) | 영화와 같은 장편 영상에서 1초마다 주석이 달린 프레임을 중심으로, 3초 길이의 클립을 추출하여 행동 인식을 수행함 |
| WebVid‑2M / WebVid‑10M | 원본 비디오는 다양하나, 모델 학습 시 일반적으로 224×224 (또는 256×256)로 리사이즈함 | 원본은 다양 (학습 시 균일 샘플링) | WebVid‑2M: 평균 약 18초 WebVid‑10M: 유사 | 웹 스크래핑을 통해 수집된 대규모 비디오-텍스트 데이터셋. WebVid‑2M은 약 2.5M, WebVid‑10M은 약 10M 비디오-텍스트 쌍을 포함하며, retrieval 등 멀티모달 태스크에 활용됨 |
| HowTo100M | 원본 영상은 다양하지만, 모델 학습 시 일반적으로 224×224 (또는 256×256)로 리사이즈함 | 약 25–30 | 평균 약 4초 | YouTube 등에서 수집한 내레이션 영상 기반 데이터셋. ASR 전사 캡션을 활용하여 자동 생성된 텍스트로 구성되며, 대규모 instruction 데이터셋임 |
~24.3 동향
공통
- pre-training 시, 6 ~ 7.25 fps 간격으로 비디오 frame input을 받아 딥러닝 네트워크의 input으로 사용하여 학습했음. 그리고 한번에 넣는 비디오가 커버하는 시간 길이도 2.2~2.66초로 거의 비슷함.
- 비디오 frames를 input으로 넣을 때는 720 by 1080 이미지 원본을 -> 256 by 384 ~ 320 by 480 로 리사이징 한 후 -> 리사이징 이미지를 224 by 224 로 crop(좌 or 중앙 or 우 영역)해서 최종적으로 인풋으로 활용함
23~24.3
- video language model(ViLM)은 연구중인데, 성능이 아쉬움
- video foundation model / video language model(ViLM)을 학습하기 위해
- 마스킹된 비디오 모델링
- 비디오-오디오-텍스트 대조 학습
- 다음 토큰 예측 학습
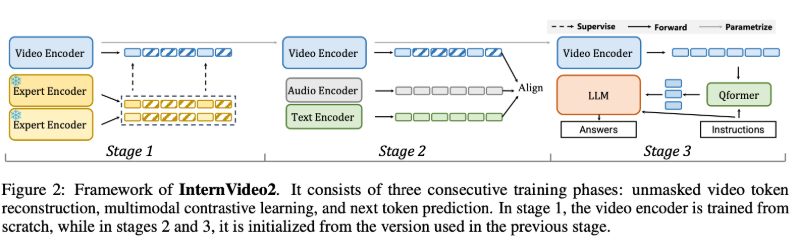
- audio와 text encoder도 같이 학습시킴
- 비디오-text caption 데이터셋을 직접 만듦
- 비디오, 오디오, 스피치(말소리)를 모두 이용하여, 영상에 대한 (더 퀄리티 좋은) text caption을 생성
- Visual instruction tuning (A.K.A. llava) 의 비디오 버전으로, Video Instruction tuning 데이터를 생성하는 방법을 제시 (Detailed Video Descriptions 데이터 + Video Conversations 데이터)
22~23
- video foundation model을 비디오 task 10개에 대해 검증했으며, 비디오 task를 비디오 동작 인식 및 탐지, 비디오와 텍스트 연결 작업, 그리고 오픈월드 비디오 애플리케이션의 3가지 분류로 나누어 평가함.
한계점
- 고정된 입력 해상도(224 by 224),
- 3분 이상의 장기 비디오 처리에 어려움
- 시공간적 및 인과 추론 능력의 미흡
- 시간에 민감하고 성능이 중요한 응용 분야에서의 성능이 별로임
앞으로의 계획
- 아래 한계점을 극복 가능한 논문들 스터디
- 고정된 입력 해상도(224 by 224) (더 큰 해상도가 필요해보임)

모든 의사 결정 과정을 지나칠 정도로 모두 기록하고, 나중에 스스로 피드백 하는 것