[데이터 엔지니어링 데브코스 2기]
1.[데이터 엔지니어링 데브코스 2기] TIL-2주차-파트01 자료구조와 알고리즘

이를 반복 알고리즘으로 표현하면 다음과 같다.
2.[데이터 엔지니어링 데브코스 2기] TIL-2주차-파트02 자료구조와 알고리즘
일부 연산이 추가됨으로써, 기존에 있던 불필요한 연산들을 줄일 수가 있다.하지만, 아직 연결 리스트(Linked List)에는 다른 단점들이 존재하며, 이를 보완하기 위해 이중 연결 리스트(Double Linked List)가 필요하다.
3.[데이터 엔지니어링 데브코스 2기] TIL-2주차-파트03 자료구조와 알고리즘
Queue의 활용 예) 운영 체제 시스템 내부, 네트워킹 시스템 내부 ..1) 배열 : Python의 list2) 연결 리스트 : Doubly Linked List배열 queue의 연산별 시간 복잡도구현 방식)일반적으로 1번의 방법이 더 유리하다. 2의 방식으로 할 경
4.[데이터 엔지니어링 데브코스 2기] TIL-2주차-파트04 자료구조와 알고리즘
Hash에 대한 접근은 O(1)으로 상수 시간에 접근이 가능하다.결과가 같게 나오더라도 알고리즘마다의 시간 복잡도를 고려하여 최적의 알고리즘을 선택하는 것이 중요하다.
5.[데이터 엔지니어링 데브코스 2기] TIL-2주차-파트05 자료구조와 알고리즘/ChatPT특강
1. ChatGPT ChatGPT란, GPT를 chat bot으로 Fine-tuning한 application이다. 여러 AI 관련 용어들이 포함되어 있으므로 해당 용어들을 먼저 정리한다. 1) LLM(Large-Language Model) GPT의 근본이 되는 인공지
6.[데이터 엔지니어링 데브코스 2기] TIL-3주차-파트02 파이썬으로 웹 다루기
li { margin-top : 15px; } 0. 강의 내용 HTML 기본 내용 1. HTML(Hyper-Text-Markup-Language) 웹 브라우저가 이해할 수 있는 언어. 1) tag의 구분 tag 구분은 크게 두 가지로 나눌 수 있다.
7.[데이터 엔지니어링 데브코스 2기] TIL-3주차-파트03 파이썬으로 웹 다루기(웹 스크래핑 기초)
본 장에서는 HTTP가 나오게 된 이유와 개념을 소개한다.인터넷과 웹의 개괄적인 역사는 다음과 같다.그렇다면 웹은 무엇일까?웹(WEB, World Wide Web)은 Internet에서 정보를 주고 받는 하나의 시스템이다.이어서 또 질문을 할 수가 있다. 그렇다면 웹에
8.[데이터 엔지니어링 데브코스 2기] TIL-3주차-파트04 파이썬으로 웹 다루기(HTML parser)
BeutifulSoup이란, Python의 라이브러리로 requets로 얻은 html 텍스트를 파싱해 주는 역할을 한다.
9.[데이터 엔지니어링 데브코스 2기] TIL-3주차-파트05 파이썬으로 웹 다루기(selenium)
Selenium이란, Python을 이용해서 웹 브라우저를 조작할 수 있는 자동화 프레임워크입니다.Python으로 웹 브라우저를 조작하기 위해서는, selenium 프레임워크뿐만 아니라 웹 브라우저를 제어할 수 있는 webdriver도 필요합니다. 따라서, 다음과 같은
10.[데이터 엔지니어링 데브코스 2기] TIL-3주차-파트06 파이썬으로 웹 다루기(데이터 시각화)
Seaborn은 Python 라이브러리로 데이터를 시각화할 때 유용하게 사용되는 라이브러리입니다. 그리고 Seaborn은 matplotlib를 기반으로 하고 있어 matplotlib.pyplot과 함께 사용됩니다.다음은 예시 코드입니다.
11.[데이터 엔지니어링 데브코스 2기] TIL-4주차-파트02 장고를 활용한 API서버 만들기(Django)

0. 개발 환경 설정하기 다음 순서에 따라 환경을 설정합니다. 파이썬 설치하기 및 파이썬 Path 시스템 변수에 추가. cmd 창을 켠 후, 원하는 디렉토리(디렉토리 이동 명령어 : )에서 명령어 실행(파이썬 가상환경 생성). 명령어로 해당 가상환경 활성화. 명령어
12.[데이터 엔지니어링 데브코스 2기] TIL-4주차-파트03 장고를 활용한 API 서버 만들기(Views와 Templates)
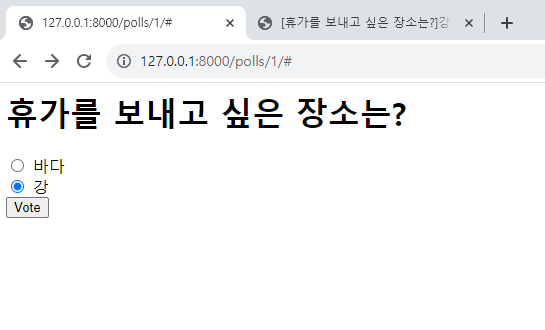
1. Views(뷰)와 Templates(템플릿) Views : 장고의 모델(DB)을 읽어서 정보를 활용하여 출력(렌더링)하는 역할. Temaplates : html 코드를 활용하여 데이터를 예쁘게 출력하는 도구. 이를 활용한 예시 절차는 다음과 같습니다. pol
13.[데이터 엔지니어링 데브코스 2기] TIL-4주차-파트04 장고를 활용한 API서버 만들기(Serializer, HTTP Methods, Mixin, generics)
Serializer : 모델 인스턴스나 QuerySet과 같은 데이터를 JSON 형식의 파일로 변환하는 작업입니다.Model -> JSONDescrializer : Serializer의 반대 개념으로, JSON 데이터를 정해진 포맷에 맞춰 Model로 변환하는 작업입니
14.[데이터 엔지니어링 데브코스 2기] TIL-4주차-파트05 장고를 활용한 API서버 만들기(Users, Authentication)
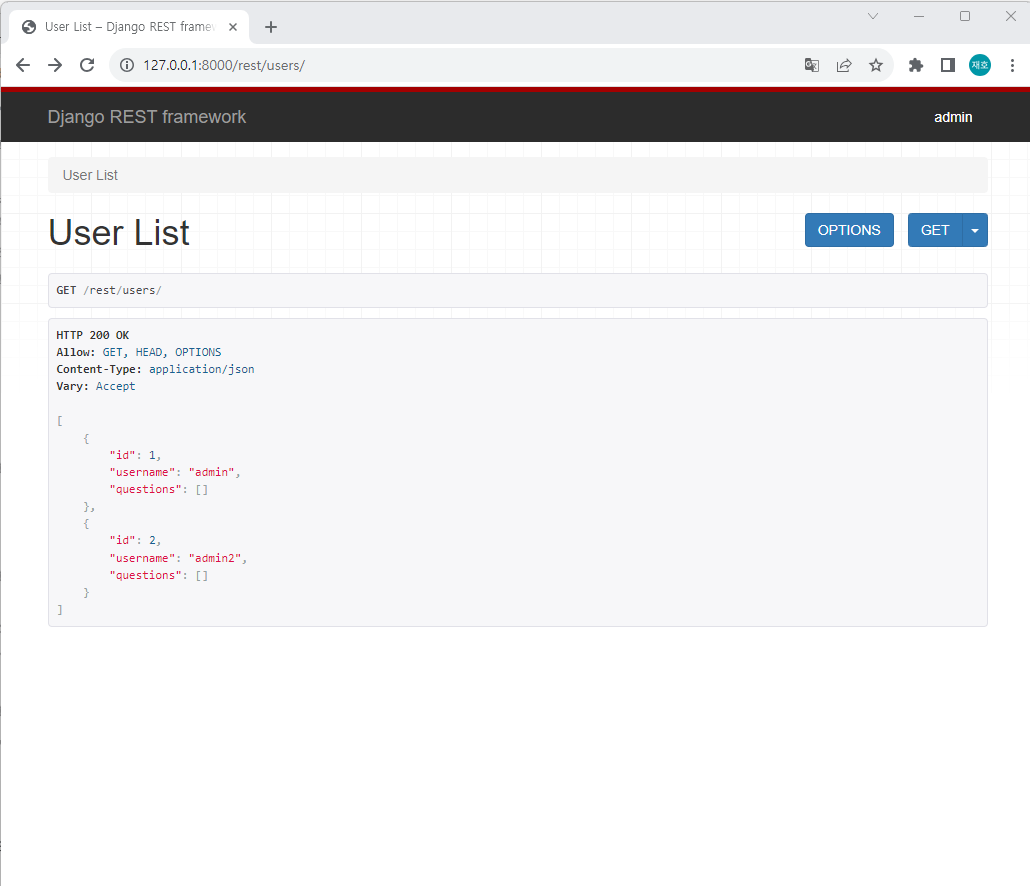
장고에서는 특정 모델(테이블)에 대한 유저를 정의할 수가 있습니다.코드와 함께 예시를 살펴 보면 다음과 같습니다.polls/models.py 파일을 다음과 같이 수정합니다터미널에서 python manage.py makemigrations 명령어를 입력 후, python
15.[데이터 엔지니어링 데브코스 2기] TIL-4주차-파트06 장고를 활용한 API서버 만들기
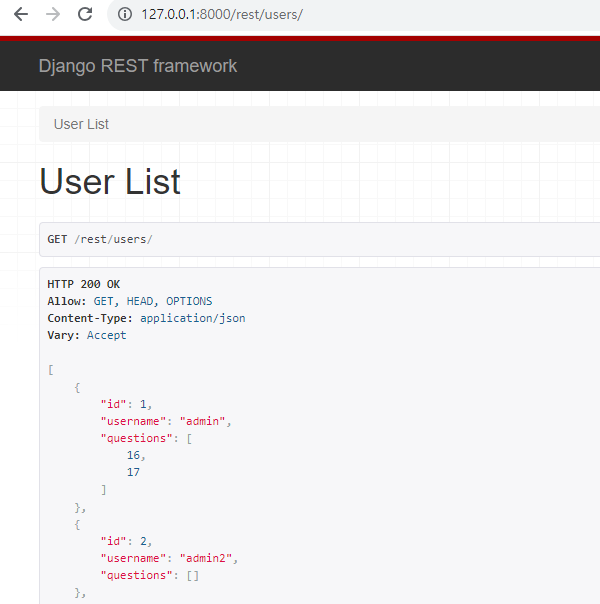
이전에 유저 목록을 조회할 때,사진에서 처럼 1번 유저의 questions가 id로 출력되고 있는 것을 확인할 수 있습니다. 이를 question의 str로 출력되도록 바꿔 보겠습니다.polls_api/serialziers.py 에서 UserSerializer를 수정합
16.[데이터 엔지니어링 데브코스 2기] TIL-5주차-파트02 [프로젝트]크롤한 웹데이터로 만들어보는 웹사이트(1)
4주차까지 배웠던 파이썬을 활용한 웹 크롤링 및 Django 프레임워크 등을 활용하여, 한 주 동안 웹 크롤링을 기반으로한 데이터 시각화 웹사이트를 만듭니다.팀원들과 얘기를 나누면서 나왔던 주제 선정을 위한 몇 가지 조건(?)과 고려 사항들을 나열해 보자면,데이터 수가
17.[데이터 엔지니어링 데브코스 2기] TIL-5주차-파트03 [프로젝트]크롤한 웹데이터로 만들어보는 웹사이트(2)
1. 로직 구현 제가 맡은 파트는 https://www.musinsa.com/app/styles/lists (코디숍) https://www.musinsa.com/app/codimap/lists (코디북) https://www.musinsa.com/app/styles/v
18.[데이터 엔지니어링 데브코스 2기] TIL-5주차-파트04 [프로젝트]크롤한 웹데이터로 만들어보는 웹사이트(3)
.
19.[데이터 엔지니어링 데브코스 2기] TIL-5주차-파트05 [프로젝트]크롤한 웹데이터로 만들어보는 웹사이트(4)
1. 진척사항 2. 추후 계획 3. 회의 내용 4. 몰랐던 내용
20.[데이터 엔지니어링 데브코스 2기] TIL-5주차-파트06 [프로젝트]크롤한 웹데이터로 만들어보는 웹사이트(5) / 특강(좋은 코드란 무엇인가)
1. 프로젝트 1-1. 진척 사항 1-2. 추후 계획 1-3. 회의 내용 1-4. 몰랐던 내용 2. 특강 : 좋은 코드란 무엇인가?
21.[데이터 엔지니어링 데브코스 2기] TIL-6주차-파트02 데이터 웨어하우스와 SQL과 데이터분석(1)
Data 관련 직군은 크게 세 가지로 구분할 수 있습니다.1\. 데이터 엔지니어 : 데이터 프로세스(ETL, ELT 등) 관련 엔지니어.2\. 데이터 분석가3\. 데이터 과학자데이터 엔지니어는 SQL을 활용하여 데이터를 데이터 웨어하우스에 저장하며, 분석가와 과학자는
22.[데이터 엔지니어링 데브코스 2기] TIL-6주차-파트03 데이터 웨어하우스와 SQL과 데이터분석(2)
1. AWS 가입 및 RedShift의 cluster 생성 다음의 절차에 따라 진행하였습니다. AWS 가입 및 무료 계정 등록. AWS console에서 RedShift 검색 후, redshift serverless trial free 등록. redshift ser
23.[데이터 엔지니어링 데브코스 2기] TIL-6주차-파트04 데이터 웨어하우스와 SQL과 데이터분석(3)
1. GROUP BY와 AGGREGATE 함수 GROUP BY는 테이블의 레코드를 그룹핑하여 그룹별로 다양한 정보를 계산하는 함수입니다. 두 단계로 이루어집니다. 먼저 그룹핑을 할 필드를 지정합니다. (하나 이상의 필드) => GROUP BY로 지정
24.[데이터 엔지니어링 데브코스 2기] TIL-6주차-파트05 데이터 웨어하우스와 SQL과 데이터분석(4)
JOIN이란, 두 개 혹은 그 이상의 테이블들을 공통 필드를 가지고 merge하는 방법입니다. 여러 테이블들의 각 레코드에 대해서 특정 key를 가지고 merge를 합니다.왼쪽 테이블을 LEFT라고 하고, 오른쪽 테이블을 RIGHT라고 가정합니다.대부분 LEFT JOI
25.[데이터 엔지니어링 데브코스 2기] TIL-6주차-파트06 데이터 웨어하우스와 SQL과 데이터분석(5)
노가다 방식 (예, 251번 사용자 단일)ROW_NUMBER 활용ROW_NUMBER() OVER (PARTITION BY field1 ORDER BY field2) nn=> field1을 기준으로 그룹핑을 하며, field2를 기준으로 레코드마다 일련 번호를 붙이겠다는
26.[데이터 엔지니어링 데브코스 2기] TIL-7주차-파트02 AWS 클라우드(1)
AWS : 전 세계적으로 가장 많이 사용되는 클라우드 플랫폼.클라우드 컴퓨팅 : IT 리소스를 인터넷을 통해 온디맨드로 제공하고 사용한 만큼만 비용을 지불하는 방식.클라우드 유형:On Premiss : 클라우드를 이용하지 않고 본인이 처음부터 끝까지 모든 환경을 구축하
27.[데이터 엔지니어링 데브코스 2기] TIL-7주차-파트03 AWS 클라우드(2)
Route53은 도메인 관련 기능(도메인 등록, DNS 라우팅, 상태 확인 등)을 지원하는 서비스입니다.Route53에는 public host zone과 private host zone이 존재합니다.Route53 = DNS + 모니터링 + L4 + GSLB.작동 방식)
28.[데이터 엔지니어링 데브코스 2기] TIL-7주차-파트04 AWS 클라우드(3)
IAM(Identify and Access Management)는 AWS 리소스에 대한 엑세스를 안전하게 제어할 수 있는 웹 서비스입니다.IAM을 사용하여 리소스를 사용하도록 인증(로그인) 및 권한 부여된 대상을 제어합니다.AWS 계정을 생성할 때는 해당 계정의 모든
29.[데이터 엔지니어링 데브코스 2기] TIL-7주차-파트05 AWS 클라우드(4)
1. AWS CLI 2. RDS 3. Front 4. CI/CD 5. Route53
30.[데이터 엔지니어링 데브코스 2기] TIL-7주차-파트06 AWS 클라우드(5)
6\. ApiGateway
31.[데이터 엔지니어링 데브코스 2기] TIL-8주차-파트02 데이터 웨어하우스 관리와 고급 SQL과 BI 대시보드(1)
데이터 조직의 비전은 신뢰할 수 있는 데이터를 바탕으로 부가 가치를 생성하는 것이다.부가 가치: 데이터 분석, 데이터를 바탕으로 한 ML로 개인 추천 서비스.중요한 것은 데이터로 매출 증가에 기여한다는 것을 보여 주어야 인정받을 수 있다.고품질 데이터를 기반으로 의사
32.[데이터 엔지니어링 데브코스 2기] TIL-8주차-파트03 데이터 웨어하우스 관리와 고급 SQL과 BI 대시보드(2)
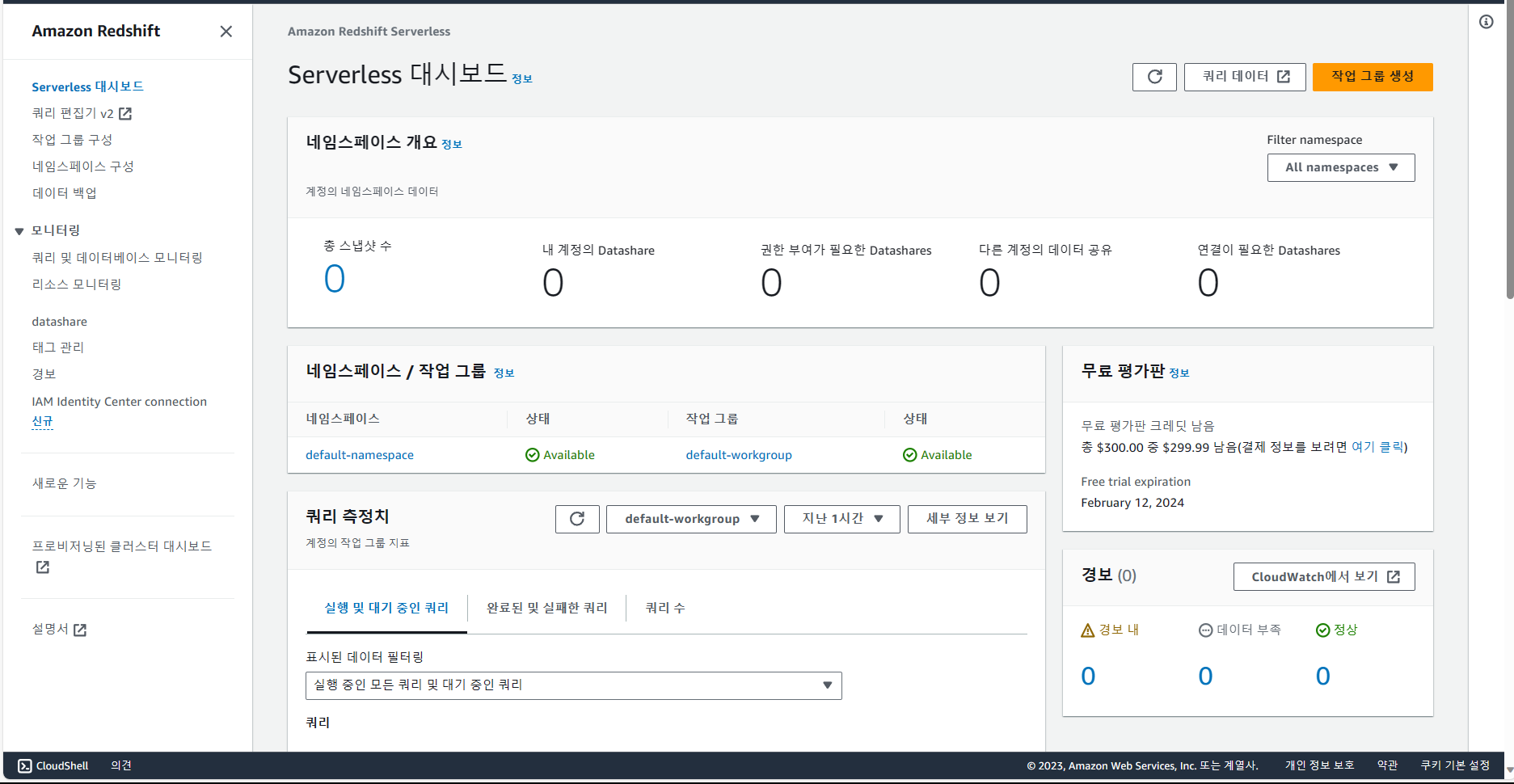
특징 1)AWS의 클라우드 기반 빅데이터 웨어하우스.2PB의 데이터까지 처리 가능. (최소 160GB로 시작하여 점진적으로 용량 증감 가능)Still OLAP. (프로덕션 DB로 사용 X. 느린 속도, 큰 용량.)칼럼 기반 스토리지. (칼럼별 압축이 가능하여 칼럼 추가
33.[데이터 엔지니어링 데브코스 2기] TIL-8주차-파트04 데이터 웨어하우스 관리와 고급 SQL과 BI 대시보드(3)
일반적으로 사용자별 테이블별 권한 설정을 하지는 않음. (너무 복잡함.)역할(Role) 혹은 그룹(Group) 별로 스키마 별 접근 권한을 주는 것이 일반적임.최근 PBAC(Role Based Access Control)가 새로운 트렌드로 사용됨. (그룹은 계승이 안
34.[데이터 엔지니어링 데브코스 2기] TIL-8주차-파트05 데이터 웨어하우스 관리와 고급 SQL과 BI 대시보드(4)
1. Snowflake란? 2014년에 클라우드 데이터 웨어하우스로 시작됨. 데이터 클라우드로 큰 발전. 글로벌 클라우드(AWS, GCP, Azure)에서 모두 동작. (멀티 클라우드) 데이터 판매를 통한 매출을 가능하게 해주는 Data Sha
35.[데이터 엔지니어링 데브코스 2기] TIL-8주차-파트06 데이터 웨어하우스 관리와 고급 SQL과 BI 대시보드(5)
대시보드 혹은 BI(Business Intelligence) 툴이라고 부르기도 함.KPI(Key Performance Indicator)와 같은 지표와 데이터 등을, 데이터를 기반으로 계산/분석/표시해 주는 툴.데이터 결정권자들에게 많은 도움이 됨.데이터 기반 결정(D
36.[데이터 엔지니어링 데브코스 2기] TIL-9주차-파트02 [프로젝트]데이터 웨어하우스를 이용한 대시보드 구성(1)
https://www.kamis.or.kr/customer/main/main.do 의 농산물 일일 가격 데이터를 통해서 (전일 비교 등) 가격 등락률을 보여주는 대시보드 구성.전체적인 구상: raw data -> AWS S3(스토리지) -> Snowflake(
37.[데이터 엔지니어링 데브코스 2기] TIL-9주차-파트03 [프로젝트]데이터 웨어하우스를 이용한 대시보드 구성(2)
저장한 csv파일을 S3로 저장하는 파이프라인 구현을 완료함.S3를 연동할 때 access key를 노출시키지 않고 안전한 방법으로 입력하여 코드 실행을 자동화하고 싶음. 해당 관련 기술을 더욱 모색해야 함.
38.[데이터 엔지니어링 데브코스 2기] TIL-9주차-파트04 [프로젝트]데이터 웨어하우스를 이용한 대시보드 구성(3)
raw data -> S3 적재.airflow를 통해서 데이터 파이프라인을 자동화할 수 있는 시스템을 구축하고 싶음.https://data.kma.go.kr/data/rmt/rmtList.do?code=400&pgmNo=570 에서 날씨 데이터를 받아서 일일
39.[데이터 엔지니어링 데브코스 2기] TIL-9주차-파트05 [프로젝트]데이터 웨어하우스를 이용한 대시보드 구성(4)
.날씨 데이터를 활용할 지는 아직 미지수.
40.[데이터 엔지니어링 데브코스 2기] TIL-10주차-파트02 데이터 파이프라인, Airflow(1)
데이터 파이프라인은 한 마디로 하면 ETL과 같음."데이터 소스 -(ETL)-> 데이터 인프라(데이터 레이크 및 웨어하우스) -> 데이터 분석 및 데이터 과학 -> 프로덕트 서비스 개선 -> 매출 상승"으로 이루어진 일련의 과정.외부에 있는 데이터(데이터 소스)를 내부
41.[데이터 엔지니어링 데브코스 2기] TIL-10주차-파트03 데이터 파이프라인, Airflow(2)
멱등성 보장 X 버전멱등성 보장 버전BEGIN; ~ COMMIT; ~ ROLLBACK; 을 통해서 데이터 정합성을 만족 가능함.트랜잭션이란?은행 계좌 입/출금과 같이 중간에 실패하면 불완전한 상황에 놓이는 작업에 활용함.따라서 여러 작업들을 하나의 작업처럼 (atomi
42.[데이터 엔지니어링 데브코스 2기] TIL-10주차-파트04 데이터 파이프라인, Airflow(3)
Python Operator를 사용해서 Airflow DAG를 만듦.Python Operator 기본 구조.print_hello와 print_goodbye라는 함수를 Python Operator로 구현해 보기.다른 방식인 Airflow Decorators로 구현해 보기
43.[데이터 엔지니어링 데브코스 2기] TIL-10주차-파트05 데이터 파이프라인, Airflow(4)
주요 정보 : https://hongcana.tistory.com/122airflow.cfg에는 두 종류의 타임존 관련 키가 존재함.default_ui_timezone : 웹서버 UI 우측 상단에 표시되는 타임존 관련.default_timezone : 스케쥴과
44.[데이터 엔지니어링 데브코스 2기] TIL-10주차-파트06 데이터 파이프라인, Airflow(5)
OLTP(MySQL) -> S3 -> OLAP(Redshift)를 Full Refresh 버전과 Incremental Update 버전으로 나눠서 진행.AWS 관련 권한 설정Airflow DAG에서 S3 접근 (쓰기 권한)Redshift가 S3 접근 (읽기 권한)IAM
45.[데이터 엔지니어링 데브코스 2기] TIL-11주차-파트02 개발환경 구축을 위한 Docker와 K8S 실습 (1)
1. Airflow 운영 상의 어려움 > 만약 관리해야 하는 DAG의 수가 100개를 넘어간다면 어떨까. 아마 다음과 같은 이슈들이 발생할 것이다. 데이터 품질 및 데이터 리니지 이슈. 라이브러리 충돌. Worker의 부족. Worker 서버들의 관리와 활용도 이슈.
46.[데이터 엔지니어링 데브코스 2기] TIL-11주차-파트03 개발환경 구축을 위한 Docker와 K8S 실습 (2)
hangman_web이라는 repo를 실행.1\. 테스트 수행.2\. Docker Image 빌드.3\. Docker Image를 Docker Hub으로 푸시.위 과정을 Github repo에 Github Actions로 구현.hanaman repo: https
47.[데이터 엔지니어링 데브코스 2기] TIL-11주차-파트04 개발환경 구축을 위한 Docker와 K8S 실습 (3)
Docker 명령어 - 이미지 관련. : 이미지 빌드 : 이미지 삭제. : 이미지 삭제. > Docker Hub 관련. > Container 관련. docker psdocker ps -adocker ps -qdocker {stop, start, restart, ki
48.[데이터 엔지니어링 데브코스 2기] TIL-11주차-파트05 개발환경 구축을 위한 Docker와 K8S 실습 (4)
.dockerignore란?,Image build할 때 추가하지 말아야 할 파일 및 폴더 지정.만약 Dockerfile에서 COPY 명령어를 사용할 때 저장되는 일부 파일 등에 대해서 적용 가능.Docker Compose란?,다수의 컨테이너로 소프트웨어로 구성된 경우에
49.[데이터 엔지니어링 데브코스 2기] TIL-11주차-파트06 개발환경 구축을 위한 Docker와 K8S 실습 (5)
Dockerfile -> Docker Image 생성 -> 빌드 -> Docker Container에서 실행.docker compose로 다수의 컨테이너 관리 가능.다수의 서버 관리 방법은 다음과 같음.1\. 문서화 : Not scalable.2\. 코드(자동)화 :
50.[데이터 엔지니어링 데브코스 2기] TIL-12주차 Airflow의 다양한 고급 기능과 CI/CD 환경 설정에 대해 학습 (1)
다음 명령어로 airflow 레포 클론. git clone https://github.com/learndataeng/learn-airflow.gitlearn-airflow 폴더에서 이미지 관련 yml 파일 다운로드. curl -LfO 'https://
51.[데이터 엔지니어링 데브코스 2기] TIL-12주차 Airflow의 다양한 고급 기능과 CI/CD 환경 설정에 대해 학습 (2)
1. 구글 시트를 테이블로 복사하는 예제 > 절차. 시트 API를 활성화하고 구글 서비스 어카운트를 생성한 후 해당 내용을 JSON 파일로 다운로드. 어카운트에서 생성해 준 이메일을 조작하고 싶은 시트에 공유. Airflow DAG 쪽에서 해당 JSON 파일로 인증하
52.[데이터 엔지니어링 데브코스 2기] TIL-12주차 Airflow의 다양한 고급 기능과 CI/CD 환경 설정에 대해 학습 (3)
복습)1\. 만약 활성화된 dags만 조회하고 싶다면?config API를 허용하는 환경 변수 세팅은?airflow.cfg 파일에서 webserver 섹션의 expose_config 값을 True로 설정.docker-compose.yaml에서 다음과 같이 세팅.vari
53.[데이터 엔지니어링 데브코스 2기] TIL-12주차 DBT 소개, 데이터 디스커버리, 툴 학습 (1)
Airflow 로그 파일은 용량이 크기 때문에 주기적으로 삭제 및 백업을 해야 함.로그 위치.base_log_folder와 child_process_log_directory 라는 두 개의 폴더에 로그 파일이 저장됨.docker compose의 경우, 호스트 볼륨으로 존
54.[데이터 엔지니어링 데브코스 2기] TIL-12주차 DBT 소개, 데이터 디스커버리, 툴 학습 (2)
1. dbt > dbt Seeds란, dimension 테이블들을 csv 파일로 읽기 쉽게 만들어서 DW로 로드하는 방법. seeds라는 폴더 밑에 적당한 .csv 파일로 생성. dbt seed 실행 시, 스키마 밑에 기본으로 지정된 csv 파일 이름으로 테이블이 생
55.[데이터 엔지니어링 데브코스 2기] TIL-13주차 [프로젝트]End-to-end 데이터 파이프라인 구성하기
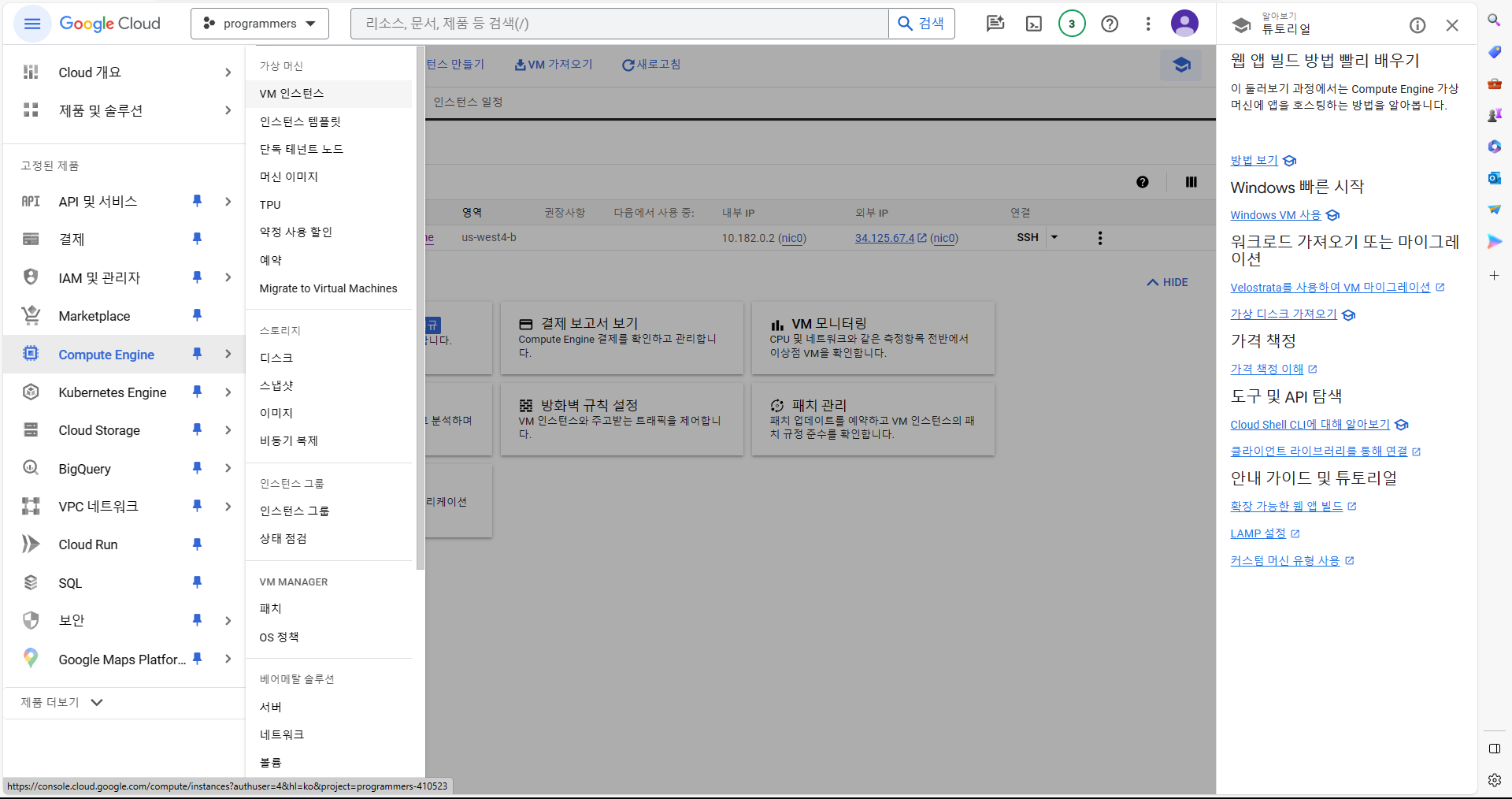
https://apiportal.koreainvestment.com/apiservice/apiservice-domestic-stock-quotations사용 기술 : docker, airflow, GCP Compute Engine, Snowflake, AWS
56.[데이터 엔지니어링 데브코스 2기] TIL-14주차 빅데이터 처리 시스템, Hadoop, Spark (1)
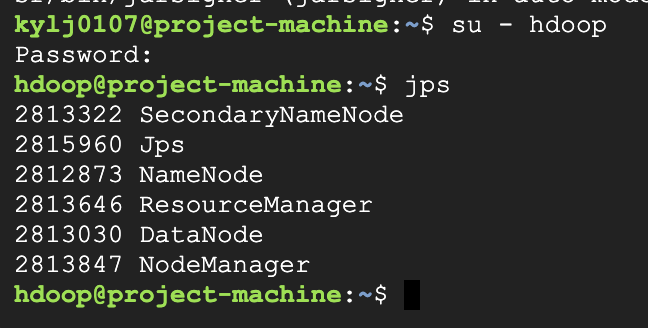
요약.빅데이터 처리를 위해 하둡이라는 오픈소스가 등장함. \- 분산 파일 시스템(HDFS)과 분산 컴퓨팅 시스템(맵리듀스->YARN)으로 구성됨. \- 맵리듀스 프로그래밍의 제약성으로 인해 SQL이 재등장.Spark은 대세 대용량 데이터 분산 컴퓨팅 기술. \-
57.[데이터 엔지니어링 데브코스 2기] TIL-14주차 빅데이터 처리 시스템, Hadoop, Spark (2)
Spark 데이터 시스템 아키텍처.내부 데이터(HDFS, AWS S3, Azure Blob, GCP Cloud Storage) -> 리소스 매니저(YARN, K8s) -> Spark Core Engine -> Spark SQL, Spark Streaming, ...외부
58.[데이터 엔지니어링 데브코스 2기] TIL-14주차 빅데이터 처리 시스템, Hadoop, Spark (3)
SQL은 빅데이터 세상에서 중요함 !데이터 분야에서 일하기 위해서는 필수적인 기술.구조화된 데이터를 다루기 위해 SQL은 필히 사용됨.모든 대용량 데이터 웨어하우스는 SQL 기반.Spark도 Spark SQL로 지원하고 있음.Spark SQL이란,데이터 프레임 작업을
59.[데이터 엔지니어링 데브코스 2기] TIL-14주차 빅데이터 처리 시스템, Hadoop, Spark (4)
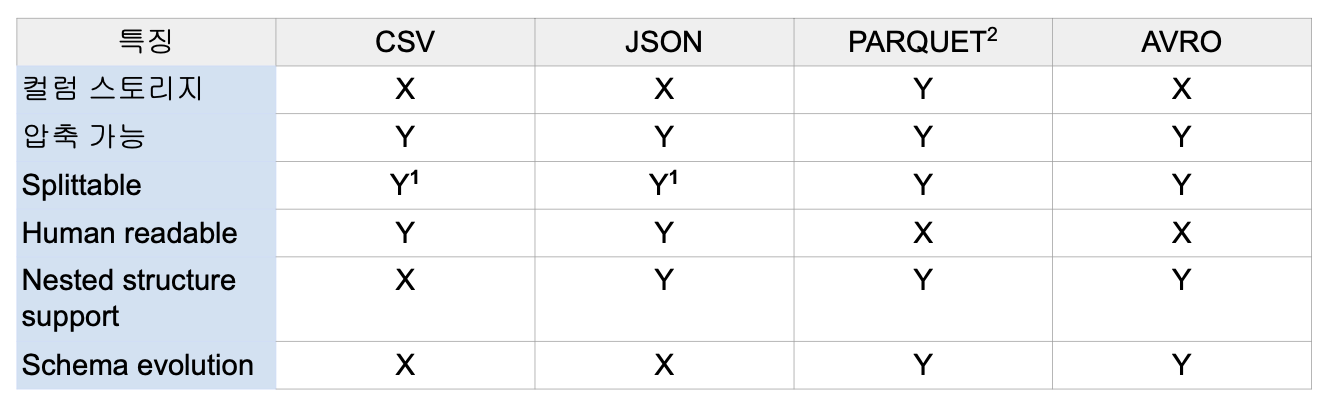
Unstructured - Semi-Structured - Structured.Text - JSON,XML,CSV - PARQUET,AVRO,ORC,SequenceFileStructured는 사람의 눈으로 읽을 수가 없음. 바이너리 파일.Parquet.Spark의 기본
60.[데이터 엔지니어링 데브코스 2기] TIL-15주차 Kafka와 Spark Streaming 기반 스트리밍 처리 (1)
구글 검색 엔진 -> 초기엔 주기적인(배치 O, 실시간 X) 페이지 검색 인덱스 정보 갱신 및 저장 -> 중간에 정보가 바뀌면 다음 갱신 전까지 잘못된 정보를 저장함 -> 실시간 데이터 처리의 필요데이터 처리의 일반적인 단계.데이터 수집 -> 데이터 저장 -> 데이터
61.[데이터 엔지니어링 데브코스 2기] TIL-15주차 Kafka와 Spark Streaming 기반 스트리밍 처리 (2)
데이터 웨어하우스(AWS Redshift)의 도입.ETL 프로세스 개발.Airflow프로덕션 DB 테이블 스키마의 변경(updated_at과 deleted 필드 추가).사용자 이벤트 로그를 프로덕션 DB에서 저장하는 방식에서 nginx 로그로 뺴는 작업 수행.Hadoo
62.[데이터 엔지니어링 데브코스 2기] TIL-15주차 Kafka와 Spark Streaming 기반 스트리밍 처리 (3)
Kafka란,실시간 데이터 처리를 위한 오픈소스 분산 스트리밍 플랫폼.다수의 서버에 로그가 분산되어 저장됨. (Distributed Commit Log)다수의 서버에 저장하기 때문에 Scalability가 있으며, 서버를 Broker라고 부름.Scale Out: 서버(
63.[데이터 엔지니어링 데브코스 2기] TIL-15주차 Kafka와 Spark Streaming 기반 스트리밍 처리 (4)
Kafka CLI tool.docker ps를 통해 broker의 컨테이너 아이디로 접근.docker exec -it Broker_Container_ID shkafka-{topics, configs, console-conumer, console-producer} 등의
64.[데이터 엔지니어링 데브코스 2기] TIL-15주차 Kafka와 Spark Streaming 기반 스트리밍 처리 (5)
실시간 데이터 스트림 처리를 위한 Spark API.Kafka Kinesis, Flume, TCP 소켓 등의 다양한 소스에서 발생하는 데이터 처리 가능.Join, Map, Reduce, Window와 같은 고급 함수 사용 가능.Semi-realtime data 처리.S
65.[데이터 엔지니어링 데브코스 2기] TIL-16주차 머신러닝, Scikit-learn, 실전 머신러닝 문제 실습 (1)
큰 그림 그리기.주제는 무엇인지.지도학습, 비지도학습, 강화학습 중 무엇인지.분류 문제인지 회귀 문제인지.배치학습인지 온라인학습인지.데이터 구하기.데이터 시각화로 통찰 얻기.학습용 데이터 준비.모델 선택 및 훈련.모델 조정(fine-tuning).모델을 기반으로 솔루션
66.[데이터 엔지니어링 데브코스 2기] TIL-16주차 머신러닝, Scikit-learn, 실전 머신러닝 문제 실습 (2)
C_ij = sigma(A_ik \* B_kj)선형 종속: {x_1, x_2, x_3, ... x_n}의 벡터 집합에서, x_1 + x_2 = x_3처럼 한 벡터를 다른 벡터의 조합으로 나타낼 수 있는 경우.선형 독립: 선형 종속이 아닌 경우.rank.v_1 + v_2
67.[데이터 엔지니어링 데브코스 2기] TIL-16주차 머신러닝, Scikit-learn, 실전 머신러닝 문제 실습 (3)
표본 집합 S: 실험의 결과로 발생하는 모든 결과의 집합.확률 P: S에서 특정 사건이 발생할 확률 (P(사건)).확률 변수 X: S의 원소 e를 X(e) = x에 대응시키는 함수.예) S = {HH, HT, TH, TT}.X(HH) = 2X(HT) = 1X(TH) =
68.[데이터 엔지니어링 데브코스 2기] TIL-17주차 대용량 데이터 훈련 대비 Spark, SparkML 실습 (1)
Broadcast Variable.룩업 테이블 등을 브로드캐스팅하여 셔플링을 막는 방식으로 사용. \- 브로드캐스트 조인에서 사용되는 것과 동일한 테크닉.대부분 룩업 테이블을 Executor로 전송하는 데 사용.많은 DB에서 스타 스키마 형태로 팩트 테이블과 디멘션
69.[데이터 엔지니어링 데브코스 2기] TIL-17주차 대용량 데이터 훈련 대비 Spark, SparkML 실습 (2)
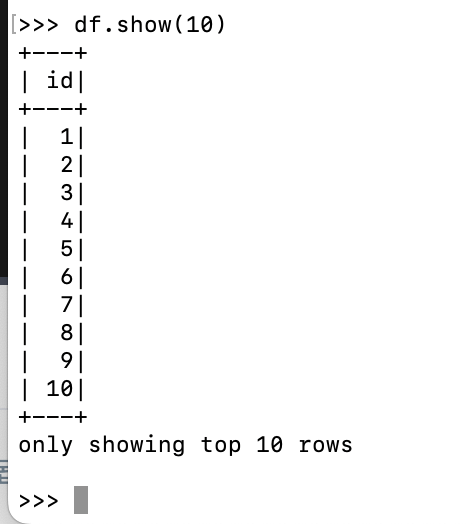
터미널에서 pyspark으로 실행.df = spark.range(1, 1000000).toDF("id") : 1부터 999,999들의 값들은 갖는 레코드로 구성이 된 RDD를 만든 후, DF으로 바꾸면서 필드명은 id로 줌.df.show(10) : df의 10개의 레코
70.[데이터 엔지니어링 데브코스 2기] TIL-17주차 대용량 데이터 훈련 대비 Spark, SparkML 실습 (3)
Dynamically optimizing skew join.Skew 파티션으로 인한 성능 문제를 해결하기 위함.한두 개의 오래 걸리는 테스크들로 인한 전체 Job/Stage 종료 지연 방지.먼저 skew 파티션의 존재 여부 파악 -> skew 파티션을 작게 나눔 ->