XAI for object detection
1.Setting
데이터
-
일반 Object Detector 논문들의 dataset 사용.
-
즉, object에 대한 annotations(class, bounding box)이 있는 dataset.
-
이 때, 웬만하면 자율 주행 domain에도 적용될 수 있는 data를 쓰는 편이 좋긴 하다(다만 evaluation을 위해 다른 dataset에도 적용될 수 있는 연구를 하는 게 더 좋을듯).
설명 대상 및 레벨
※ 모두 1개의 image를 대상으로하는 local explanation.
설명 대상 : user
설명 레벨 : Adversarial Explanation, Attention map 등 직관적인 설명
설명 대상 : engineer
설명 레벨 : Bayesian, feature map, VQA 등 추론이 필요한 설명
픽셀 단위 설명 or object part 단위 설명
- LIME, SHAP, Grad-CAM 등 기존의 XAI 기법들은 pixel level에서 설명을 제공함.
- XCNN은 object part를 학습하게끔 하는 conv-layer 내 filter들을 이용하기에 object part level에서 설명을 제공함.
Considering Background or only detected object?
-
Faster R-CNN, YOLO 등 detector 모델도 물론 object 외에 background를 분류하긴 한다.
-
다만, YOLO가 Faster R-CNN에 비해 background detection을 두 배 가량 더 잘 한다고 한다.
-
이처럼 background를 간단하게나마 고려할 필요가 있을 지?
-
만약 그래야 할 것 같다면, Motion Representations for Articulated Animation 연구에는 object와 background를 decouple(분리)하는 task 또한 포함되어 있으니, 필요하다면 참고할 만 하다.
-
또한, 이는 detection을 넘어선 Scene understanding(?) task에 가까울 듯.
-
감사하게도 아래서 소개할 DETR 모델은 Segmentation까지 다루긴 하니, 참고해보자.
모델 크기
- 확장성 등을 위해 심플한 모델을 만드는 게 좋음.
- 무작정 기존에 존재하는 2stage detector에 XAI 기법을 더해서 3stage, 4stage로 만드는 등 과도하게 모델들을 엮어 멀티모달을 만드는 것은 좋지 않음.
성능 변화
※ 되도록이면 성능 저하가 없는 것이 좋다.
성능 저하가 적거나 없는 모델
1. 모든 post-hoc XAI(LIME, SHAP, Grad-CAM, etc.)
2. XCNN(Interpretable CNN)
성능 저하 심한 모델
1. Adversarial Explanation
- 얘는 설명력과 성능이 반비례한다. 사용하고 싶다면 성능저하 문제는 어떻게든 해결해야한다.
- 가령, 설명이 필요 없는 기본적인 Object Detection Inference는 유지하되, 설명이 필요한 모듈만 추가로 학습시킨다거나..
사용할 수 있는 보조 기법
Classification-based
- XCNN(Interpretable CNN)(object part를 학습하는 conv-layer)
- 이 때, object part를 학습한다는 측면에서 Motion Representations for Articulated Animation의 이론을 참고할 수도 있을 듯
- Adversarial Explanation
- 그 외 다양한 XAI 기법들(LIME, SHAP, Grad-CAM, etc.)
Others
-
Interpretable Object Detection by Latent Structure(RoI 강화 등)
-
All Bayesian Apporach
- XAI approach to image captioning
-
Self attention (map)
- transformer 기반 모델들의 attention은 XAI로서 적용될 수 있는 여지가 있다.
- Attention은 설명이 아니라는 논문이 존재함(Attention is not Explanation)
- Attention은 설명이 아닌게 아니라는 논문도 존재함(Attention is not not Explanation)
-
VQA 관련 아이디어들
- VQA는 태스크 자체가 Object detection을 포함하고 있으며, (문장 관련이지만) 고도의 추론 자체도 필요하기 때문에, VQA에 쓰인 구조 중 text를 제외한 visual 관련 idea들을 사용할 수도 있음.
2. Base detector
2.1. CNN 기반
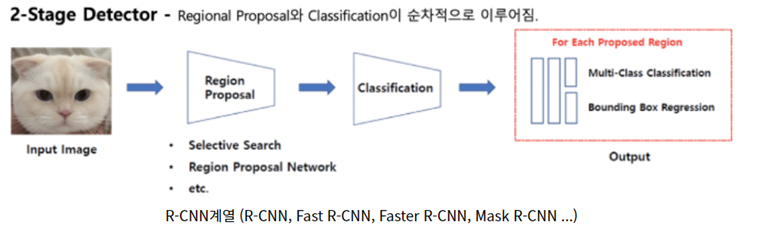
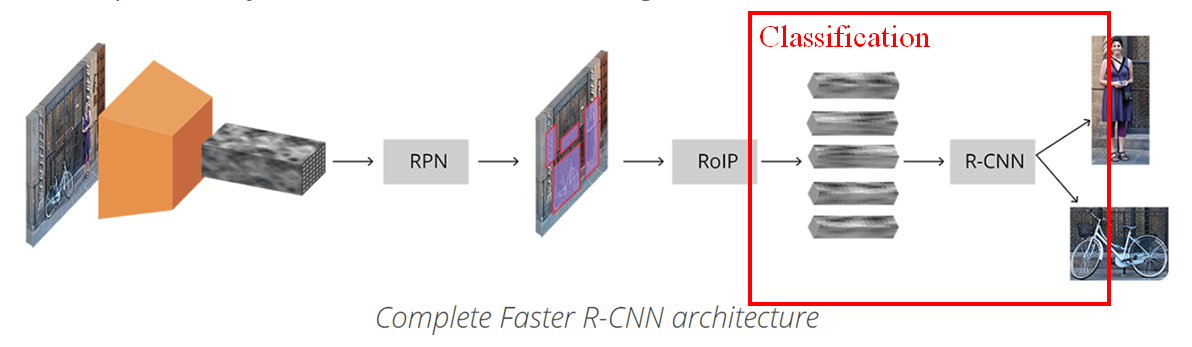
2.1.1. Faster R-CNN (2-STAGE detector)
- VQA-related technique
- XCNN
- Interpretable object detection
- Adversarial Explanation
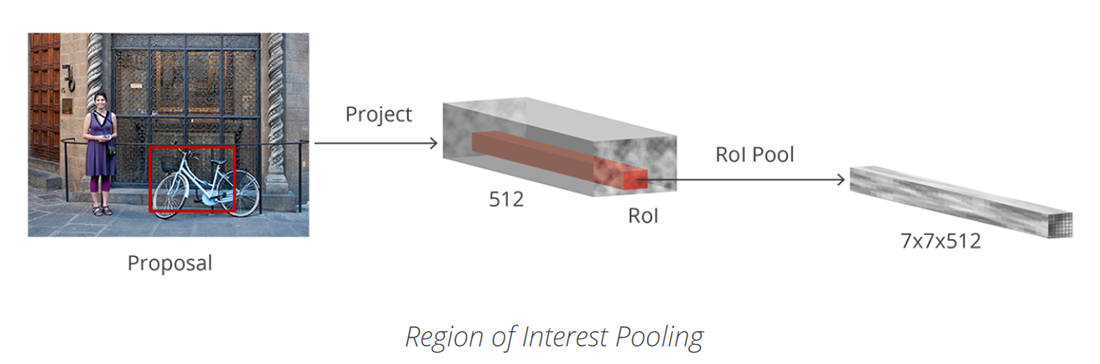
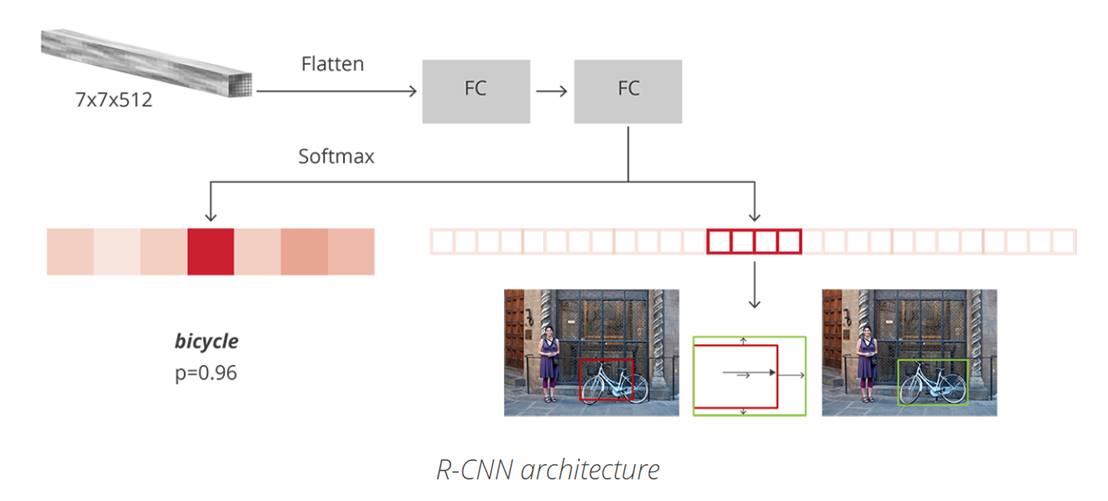
다만, 분류 과정은 아래와 같다. RoI를 7x7x512로 projection 할 때 어떤 형태로 진행되는 지 알아야 한다.
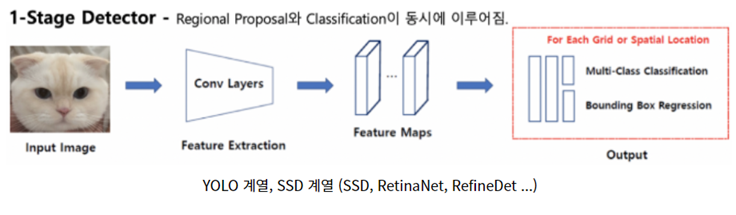
2.1.2. YOLO (1-Stage detector)
- VQA-related technique
- XCNN
- Interpretable object detection
- Adversarial Explanation(I doubt it..)
2.2. Transformer 기반
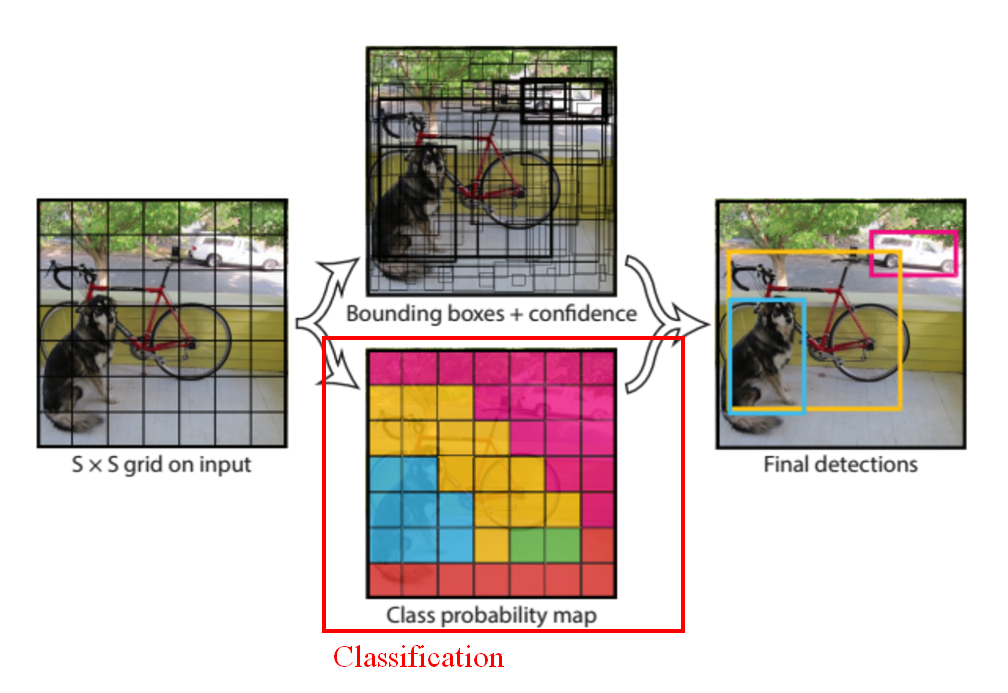
2.2.1. DEtection TRansformer (DETR; End-to-END)
-
self attention map
-
semantic segmentation
-
feature map을 생성할 때 CNN-based model을 사용하는 만큼, 공간 정보(positional information..?)를 보존한다면 특정 기법들을 활용할 수는 있을 듯
- CNN을 완전히 떠나보낸 vision transformer와는 다르게, CNN을 통해 feature map을 생성한 다음, transformer에 투입한다.
- transformer 기반 모델 답게 attention map을 얻을 수 있다.

3. For Classification model?
※ Object Detection 연구를 하는 데 답이 없을 경우.
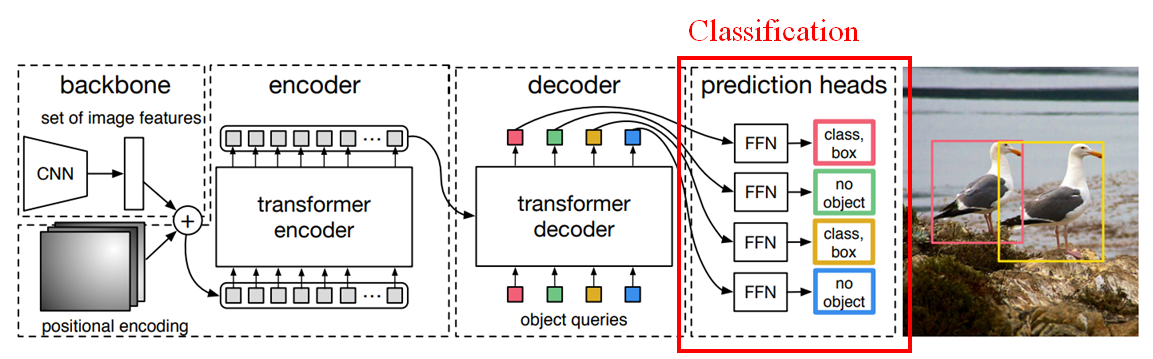
Vision-transformer(2021)
- Object Detection이 아닌, classifcation model.
- 각 이미지를 패치로 나누어 단어처럼 다루는 Vision transformer를 이용해 Explanation을 제공할 수 있을까.
- 성능은 SOTA인 반면, 연산량을 대폭 줄였기 때문에 조금 더 용이할 수도 있을 것 같다.
- 단, 이 모델을 사용할 경우 (할 수 있다면 )Adversarial Explanation을 적용하는 게 낫지 않을까 싶다.
2. Future Plan
추가 리딩 필요한 논문들
리딩이 필요한 논문 및 개념
Towards Interpretable Object Detection by Unfolding Latent Structures
- 제목에 읽을 이유가 있다.
- RoI를 계층적으로 구성하는 등 RoI내 정보를 풍부하게 하여 설명을 제공하는 듯.
Interpretable Learning for Self-Driving Cars by Visualizing Causal Attention
- causal을 어떤식으로 처리했는지.
- 또한, Attention이 DETR과 다른 개념인지? attention heat map이란 개념이 transformer와 어떻게 다른 지 궁금.
Building
explainable ai evaluation for autonomous perception
- 극단적인 날씨, 저조도 등의 이슈를 어떤 방식으로 해결했는지.
MAF: Multimodal Alignment Framework for Weakly-Supervised Phrase Grounding (aclweb.org)
- VQA 관련 태스크인데, 어떤 식으로 Object detecting을 수행했는지?
Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech
- Adversarial Learning이 어떻게 적용되는 지?
Attention 위주
- Attention은 설명이 아니다.
Attention is not not Explanation
- Attention은 설명이 아닌게 아니다.
Transformer 위주
- 필수
On the relationship between self-attention and convolutional layers
- self-attention 개념을 vision(즉, cnn기반) 분야와 연관지은 논문.
- 이는 아래의 positional encodings과도 관련 있다.
즉, self-attention map의 개념에 대해 간단히 정리된 글을 읽을 필요가 있다
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
- Vision transformer
- Attention에 관련된 내용이 있으며, DETR에 있는 self-attention map 생성과 결부지어 비교할 필요 있음.
- 참고 : DMQA
- DETR후속
RelationNet++: Bridging Visual Representations for Object Detection via Transformer Decoder
- 제목 참고.
- Vision transformer, Object detection 관련 분야의 Backbone으로 자주 쓰이는 듯.
positional encodings 관련
Image transformer. In: ICML (2018)
Attention augmented convolutional networks. In: ICCV (2019)
positional encodings 관련 개념만 발췌하자.
후속 논문 찾아볼 것
※ XAI, object detection 관련 후속 연구가 있는 지.
-
XCNN
-
DETR
-> https://velog.io/@sjinu/%ED%9B%84%EC%86%8D%EC%97%B0%EA%B5%AC-XCNN-and-DETR

글 잘 읽었습니다!
저도 Object Detection쪽에서 XAI 연구를 해보고 싶은데 혹시 어떻게 연구가 진행되셨나요?