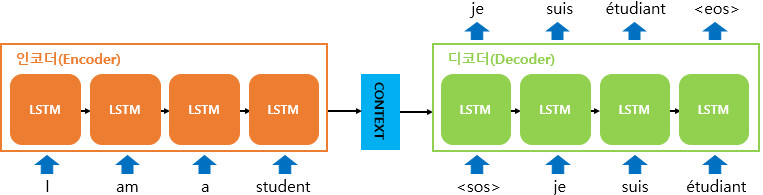
[논문 리뷰] Graph-constrained Reasoning: Faithful Reasoning on Knowledge Graphs with Large Language Models
미완성본 본 논문은 ICML 2025 포스터 발표로 소개된 논문으로, 대형 언어모델과 지식 그래프를 결합하여 추론의 신뢰성을 높인 연구를 다룬다. 1. Background LLM은 뛰어난 추론 능력을 가지고 있다. 하지만 모델의 활용도가 높아질수록 환각(Hallucination) 현상에 대한 경각심 또한 커지고 있다. 이때 언어 모델의 환각이란, 사실과...

지식 그래프 설계 기초 (개념적)
해당 포스트에서는 지식 그래프를 구축하는 방법과 그 기초에 대해 살펴본다. 더 나아가 각 노드를 구성하는 데이터들의 구조를 파악하여 지식 그래프가 전반적으로 어떻게 구축되는지 개념적인 내용을 다룬다.
효율적인 학습을 위한 경량화 방법
OOM, Out of Memory 오류는 제한된 환경에서 학습을 하다보면 가장 쉽게 마주할 오류일 것이다. 오늘의 포스트는 이를 해결하기 위한 LLM 학습에서의 핵심적인 경량화 방법에 대해 정리해둔 포스트다. Quantization (양자화) 제일 직접적인 메모리

Multi-Policy Agent의 메모리 효율화
오늘의 포스트는 리뷰가 아닌 내 연구에 대한 기본적 초석을 다지기 위해 간략히 정리하는 노트이다.
[논문리뷰] Probing the Geometry of Truth: Consistency and Generalization of Truth Directions in LLMs Across Logical Transformations and Question Answering Tasks
요즘 Cross Lingual Generalization에도 관심이 생겨 가볍게 읽어본 논문이었는데, 가벼운 학습만으로 효과를 입증했고 심지어 LLM 학습이 아닌 회귀 분석? 수준의 머신러닝 학습만으로 ACL Findings에 기재된 논문이라는 점에서 흥미로워 가져와봤
[DL기초] Softmax의 성질과 관련된 마스크 행렬의 덧셈
들어가기에 앞서, 기본적인 어텐션 연산에 대한 설명은 해당 포스트에서 하지 않겠다!대신... 공부를 하다가 간과했던 부분이 알고보니 꽤 재밌는 내용이어서 가지고 왔다! 사실 제발 아무도 안봤으면 좋겠다. 지금 당장은 글로 정리가 좀 덜된 것 같아서 부끄럽슨.. ...

[RL] GRPO와 PPO
오늘은 시간이 없으니 GRPO와 PPO에 대해 공부한 내용을 개념/수식적으로 간략히 정리하는 글을 작성하겠다. 우선은 기본적인 개념적 강화학습과 Markov Decision Process(MDP)에 대한 내용을 알고있다고 가정하겠다.

AI를 하는데 Slicing을 모른다고?;;
Slicing은 Python과 Pytorch같은 라이브러리에서 배열이나 텐서의 "특정 부분"을 선택하는 방식임.따라서, 특히 Logit 계산을 해서 정확한 input이나 loss 등의 입력을 통한 DL 학습에 필수적인 요소이다!!!헷갈리면 절대 안됨 그러면 그냥 죽음

Cross-Encoder vs. Bi-Encoder
기초를 잘 다집시다 🥺😅..(Dear myself..)기본적으로 어떤 내용일까?언어 모델 중 하나인 "BERT"에 사용되는 기본적인 내용으로, 언어 모델에 관심이 있고, 특히 NLU 과정에 대해 공부하고자 하는 학생이라면 꼭 알고 넘어가야되는 내용이다.
[RLHF] DPO(Direct Preference Optimization) 정리
RLHF(Reinforcement Learning from Human Feedback)은 인간의 피드백을 바탕으로 언어 모델을 최적화시키는 대표적인 방식이다. 이때, 학습 방식은 크게 두 가지로 나눌 수 있는데,인간 피드백 데이터를 이용해 보상 모델(Reward Mod

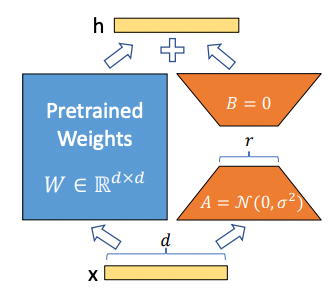
[LoRA] 하이퍼파라미터 정리
LoRA는 대형 언어 모델(LLM)의 일부 선형 변환 레이어에 “저용량 어댑터”를 추가하여, 모델 파라미터를 거의 건드리지 않으면서 새로운 태스크로 미세 조정(fine-tuning)할 수 있는 기술입니다.장점: 전체 모델을 재학습·저장할 필요 없이, 어댑터(작은 행렬)
Screen 관련 Command 정리
<session_name> 으로 새 세션 생성 및 진입실행 중인 screen 세션 목록 확인분리(detached)된 <session_name> 세션에 재접속<session_name> 세션을 강제로 분리했다가 재접속동일한 세션에 다중 접속(공유)<s
Unsloth 설치 문제 Trouble Shooting
내가 처한 문제 상황과 오류 코드는 다음과 같았다.Unsloth을 활용한 학습 및 추론이 필요한 상황이었으나, 환경 설정 과정에서 Unsloth이 환경 버전과 안맞아 문제 발생(기준 2025.06.)실패 !!!하지만 진짜 Unsloth을 꼭 필요한 상황이어서 포기할 수
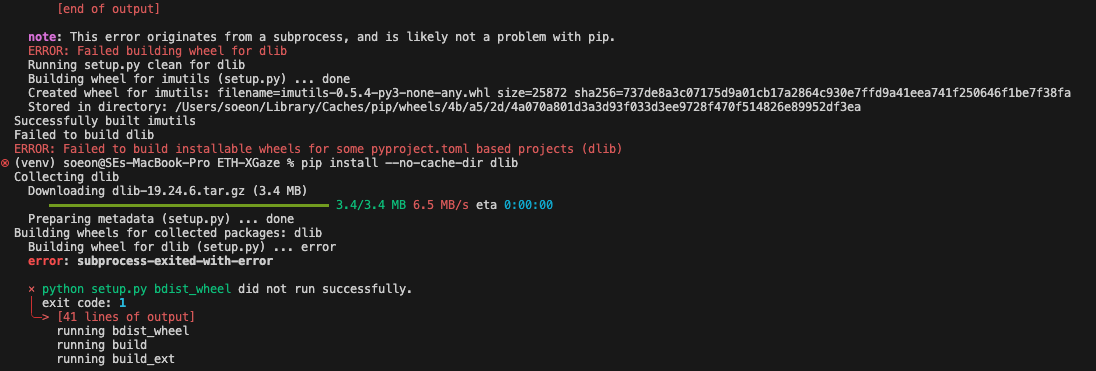
[Trouble-Shooting] dlib Installation Error(dlib 설치 오류)
이런 오류는 한 번쯤은 만나게된다. 해결방법1\. 기존의 cmake 삭제 및 재설치파이팅 ~.~!!
코랩 런타임 유지 꿀팁
코랩으로 오랜 시간(내 기준.. 4시간 이상)의 학습을 돌릴 땐 창을 닫으면 안되며, 켜진 창을 계속 터치해줘야된다는 불편함이 있었다.코랩은 일정 시간동안 화면이 켜져있다해도, 움직임이 없으면 런타임이 끊기는 것 같았다.이번 미국에서 비효율의 끝판왕인 나를 보더니 다른