
- 전체보기(33)
- SKNetworks(7)
- 코딩테스트(5)
- AI(5)
- 부트캠프(5)
- Family AI camp(4)
- 파이썬(4)
- Kanana(3)
- 자료구조(3)
- 프로그래머스(3)
- 소프트웨어설계(3)
- SKN(3)
- 머신러닝(3)
- 큐(2)
- CS(2)
- KANANA 429(2)
- Family AI(2)
- chroma(2)
- kanana-o(2)
- pinecone(2)
- 운영체제(2)
- 코테(2)
- 알고리즘 고득점 Kit(2)
- tlb(2)
- rag(2)
- 스택(2)
- 전진혁(2)
- 프로세스(2)
- 베스트 앨범(1)
- 전화번호 목록(1)
- 배열(1)
- 알고리즘고득점kit(1)
- Match Class(1)
- 디스코드(1)
- 와이어프레임(1)
- H Index(1)
- K번째수(1)
- 가장 큰 수(1)
- itertools(1)
- JJACKLETTE(1)
- "dfd(1)
- prompt(1)
- uml(1)
- 순열(1)
- 품질요구사항(1)
- Second Chance(1)
- HCI(1)
- CountVectorizer(1)
- PCB(1)
- Context Switching(1)
- sLLM(1)
- mmap(1)
- 애자일(1)
- OrderedDict(1)
- 해시(1)
- Prompt Template(1)
- prompt leaking(1)
- AI 전문가(1)
- 스토리보드(1)
- 선점형(1)
- django(1)
- 플레이데이터(1)
- agent(1)
- KANANA429(1)
- WSClock(1)
- 소프트웨어아키텍쳐(1)
- iterable(1)
- BPE(1)
- 비용산정(1)
- 응집도(1)
- Prompt injection(1)
- views(1)
- page fault(1)
- 비선점형(1)
- 가드레일(1)
- 딥러닝(1)
- output parser(1)
- 알고리즘(1)
- collections(1)
- AMAT(1)
- 스케줄링(1)
- 프로토타입(1)
- 트리(1)
- SK네트웍스(1)
- AI캠프(1)
- langgraph(1)
- LRU(1)
- 인터페이스보안(1)
- 디스크 컨트롤러(1)
- 더 맵게(1)
- 이중우선순위큐(1)
- ux(1)
- MLFQ(1)
- python(1)
- 후기(1)
- counter(1)
- 결합도(1)
- family(1)
- PTE(1)
- SOLID(1)
- 드라이버(1)
- JavaScript(1)
- 쉘(1)
- 인코딩(1)
- Deque(1)
- 사용자인터페이스(1)
- 객체지향설계(1)
- LCEL(1)
- 엠버서더(1)
- huggingface(1)
- 모델링(1)
- 스래싱(1)
- 목업(1)
- LFU(1)
- safeguard(1)
- DTM(1)
- 폰켓몬(1)
- 지역성(1)
- bootstrap(1)
- SRTF(1)
- Lora(1)
- 인터페이스(1)
- 레지스터(1)
- Bag of Words(1)
- Latency Cliff(1)
- vectorstore(1)
- 완전탐색(1)
- 인터페이스설계(1)
- Gantt 차트(1)
- MMU(1)
- 인터페이스구현(1)
- 일급시민(1)
- langChain(1)
- 정렬알고리즘(1)
- transformers(1)
- 요구사항확인(1)
- 날씨(1)
- API명세(1)
- RR(1)
- ESB(1)
- 기능요구사항(1)
- 데이터 전처리(1)
- CSS(1)
- 소프트웨어개발(1)
- html(1)
- PEFT(1)
- WebService(1)
- 같은 숫자는 싫어(1)
- erd(1)
- FIFO(1)
- 모듈설계(1)
- 올바른 괄호(1)
- retriever(1)
- 세그먼테이션(1)
- 정렬(1)
- 페이지 테이블(1)
- 서브워드(1)
- 가상 주소(1)
- 백트래킹(1)
- 디스패처(1)
- UI설계(1)
- EAI(1)
- 프로젝트(1)
- mpd(1)
- VectorDB(1)
- 해저드(1)
- 발대식(1)
- 객체지향(1)
- VISION(1)
- 파인튜닝(1)
- OmniModel(1)
- NLTK(1)
- 스케줄러(1)
- 미들웨어(1)
- 주식가격(1)
- 기능개발(1)
- 커널(1)
- 에라토스테네스의체(1)
- CRUD(1)
- PFF(1)
- 시스템콜(1)
- Omni(1)
- 데이터입출력구현(1)
- Prefetcher(1)
- computer science(1)
- hash(1)
- 아키텍쳐패턴(1)
- 화면설계(1)
- 힙(1)
- SK(1)
- 의상(1)
- defaultdict(1)
- 해싱(1)
- 검색알고리즘(1)
- COW(1)
- OS(1)
- 시스템인터페이스(1)
- 스레드(1)
- 다리를 지나는 트럭(1)
- 프로젝트일정계획(1)
- 디자인패턴(1)
- 비기능요구사항(1)
- 페이징(1)
- 정규표현식(1)
- 완주하지 못한 선수(1)

KANANA Omni Model 베타 테스터 후기
KANANA 429 엠버서더 - AI 전문가로 섭외되어 감사하게도 카카오의 신모델 kanana-o의 베타 테스터로서 참여할 수 있었다. 오늘은 그렇게 사용해 본 kanana-o 모델에 대한 후기를 작성해보고자 한다 ! 🧸 kanana-o 모델이란 ?

배열, 스택, 정렬, 해싱까지 데이터 입출력 구현의 기초 정리
자료 구조의 선형·비선형 구조부터 정렬 알고리즘, 이분 검색과 해싱까지 소프트웨어가 데이터를 저장하고 정렬하고 찾아내는 기본 흐름을 한 번에 정리한 글이다.

시스템은 어떻게 연결될까? 인터페이스 설계의 핵심 정리
시스템 인터페이스 명세화부터 미들웨어, EAI·ESB 같은 연계 구조, 구현·검증 방식, 네트워크·애플리케이션·DB 보안까지 인터페이스 설계의 흐름을 한 번에 정리한 글이다.

KANANA Safeguard 모델 사용 후기
이번 포스팅에서는 작년 5월 경 kakao에서 공개한 AI 가드레일 모델인 kanana-safeguard 모델에 대해 소개하고 여러 가지 테스트를 진행해 본 결과를 공유하고자 한다 !GPT, Gemini, Claude 등 모든 언어 모델들은 그 뼈대가 decoder-o
알고리즘 - 완전탐색
완전탐색을 다시 공부하며 에라토스테네스의 체, 인라인 `for if`, `itertools` 활용법을 정리하고, 프로그래머스 고득점 Kit 대표 문제 풀이까지 한 흐름으로 기록한 글이다.

아키텍처, 객체 지향, 디자인 패턴까지 소프트웨어 설계 흐름 정리
소프트웨어 아키텍처 설계부터 객체 지향 분석, 모듈의 결합도·응집도, IPC, 디자인 패턴까지 소프트웨어 설계의 핵심 흐름을 한 번에 정리한 글이다.

UX부터 스토리보드까지, 화면 설계 흐름 한 번에 정리
요구사항 분석 이후 왜 화면 설계가 필요한지부터 UX, UI 종류, 와이어프레임·목업·스토리보드·프로토타입의 차이, 품질 요구사항까지 한 번에 정리한 글이다.

요구사항 확인부터 비용 산정까지, 소프트웨어 설계의 첫 단계 정리
요구사항 확인을 출발점으로 기능·비기능 요구사항의 차이, 애자일 개발 방식, UML과 DFD·DD·ERD, 비용 산정과 일정 계획까지 소프트웨어 설계의 전체 흐름을 한 번에 정리한 글이다.

KANANA 429 발대식 후기
KANANA 429 엠버서더(AI 전문가) 발대식 후기 두근두근.... 삭막했던 삶에 카카오의 KANANA 429가 찾아오게 되었다 !! > KANANA 429란 ? 카카오에서 개발하는 AI 모델의 명칭인 KANANA를 홍보하기 위한 엠버서더의 활동명이다 !
CS Week 3 - 운영체제(2)
이전 WEEK 2 - 운영체제 (1)에서 프로세스와 CPU의 할당을 주된 내용으로 학습하였다면 이번 WEEK 3 - 운영체제 (2)에서는 실제 메모리와 관련된 여러 메커니즘들을 위주로 공부할 차례이다.메모리가 실제로 어떻게 점유되고 어떻게 사용되는지를 알기 위해서는 먼
알고리즘 - 정렬
해시, 큐/스택, 힙 자료구조에 이어 이번에는 알고리즘에 대해 처음으로 접해볼 시간이다. 그 중 이번에 살펴볼 것은 정렬 알고리즘이다. 정렬을 하는 알고리즘이 굉장히 많은 것으로 알고있지만 이 시리즈의 경우 코딩테스트를 위한 정리본이므로 여러 정렬 알고리즘에 대해 다루

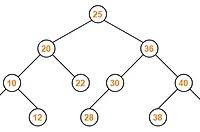
자료구조 - 힙
지난 스택/큐 구조에 이어 이제는 힙 구조에 대해 알아볼 차례이다 !힙은 특정한 규칙(최대 or 최소)을 가지는 완전이진트리로 "전체 정렬된 트리"가 아니라 "부분 정렬된 트리의 집합" 구조를 말한다.트리 전체가 아닌, 부모와 자식간의 관계에 대해서만 특정한 규칙을 확

CS Week 2 - 운영체제(1)
지난 주차 컴퓨터를 이루는 CPU와 메모리, 캐시 메모리 등 여러 하드웨어적인 요소들에 이어 이번 주차는 컴퓨터의 두뇌, 운영체제와 관련된 내용을 공부하였다.그 중에서도 운영체제와 프로세스, 스레드에 대해 알아보고 운영체제가 이들을 어떻게 관리하고 이들이 어떻게 실행되

자료구조 - 큐/스택
지난 해시 구조에 이어 가장 기본적인 자료 구조 중 큐/스택 구조에 대해 알아볼 차례이다.큐(Queue) 구조란 FIFO(First In First Out)이 구현된 구조이며,스택(Stack) 구조란 LIFO(Last In First Out)이 구현된 구조이다.이 두
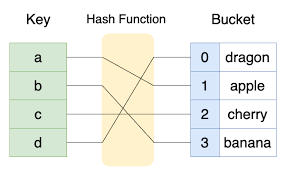
자료구조 - 해시
코딩 테스트와 기초적인 파이썬 실력을 위해 공부중이던 자료구조와 알고리즘 관련 내용을 포스트하기로 결정하였다. 아무래도 남기는게 좋은 것.... 공부 방식의 경우 프로그래머스 - 알고리즘 고득점 Kit의 내용을 기반으로 하였으며 **1) 자료구조 / 알고리즘에 대한
SKNetworsks Family AI 캠프 13기 16주차 회고
지난 주 얕게나마 프론트를 구성하는 세 가지 언어에 대해 알아보았다. HTML, CSS, JavaScript 가 그들이다. 이들을 통해 각각의 페이지가 어떻게 구성될 지, 각 페이지에서 사용자의 이벤트를 캐치하여 어떤 행동을 할지에 대해 정할 수 있었다. 이제 이들을
CS Week 1 - 컴퓨터 구조 기초
카카오 그룹의 CS(Computer Science) 테스트를 처음 접하고 비전공자의 무지함을 직접 실감하니 따로 공부하지 않고는 버틸 수가 없었다...그렇게 시작된 비전공자의 8주 짜리 CS 기초 다지기 !차근차근 달려가다보면 언젠가 끝에 닿으리라 믿으며 첫 주차를 시
SKNetworks Family AI 캠프 13기: 최장 프로젝트의 AI 부트캠프
2025.03.24 (월) 을 시작으로 교육 및 단기 프로젝트로 이루어진 4개월과 최종 프로젝트 2개월, 총 6개월 간의 긴 여정이 2025.09.15 (월) 을 기점으로 끝이 났다. 이번 블로그에서는 최종 프로젝트를 진행하면서 배운 점과 느낀 점을 마지막으로 돌이켜보
SKNetworsks Family AI 캠프 13기 15주차 회고
지난 14주 동안 파이썬부터 시작해 여러 라이브러리를 거쳐 최종 LLM 모델 구성에 도달하기까지 많은 길을 걸어왔다. 이제 모델링에서 빠져나와 시야를 확장시켜 볼 단계이다. 프론트엔드 기초를 배우고, Django를 통해 웹 애플리케이션을 구성해 볼 것이며 AWS를

SKNetworsks Family AI 캠프 13기 14주차 회고
지난 주차까지 LLM API 를 이용하여 여러 체인을 구성해 원하고자 하는 task 를 해결해보는 과정을 배웠다.이렇게 발전된 거대 LLM 모델은 터무니없는 데이터 양을 학습하였기에 분명 막강한 성능을 지녔지만, 여러 방면에 있어 명백한 한계점을 지닌다.1) 특정 작업