
TIL - 2023.09.26
오늘은 NLP 2일차이자 마지막 날..?아직 실습이 남았지만 추석 전으로 무언가를 배우는 날은 끝이고 추석 이후로는 모의경진대회를 한다고 해서 아쉽다ㅠㅜBert도 하이퍼파라미터의 지옥을 벗어날 수 없다...이러한 파라미터들은 에서 관리(?)할 수 있다. BertConf
TIL - 2023.09.18
날짜를 적고 보니 벌써 9월의 반이 지나갔다.이렇게 시간이 빠르다니... 17일은 사촌오빠가 놀러와서 공부를 많이 하지는 못했고 밤에 코드만 몇 번 돌려보았다. 오늘은 그동안 사놓고 한번도 안펴본 <밑바닥부터 시작하는 딥러닝> 책으로 부족한 부분만 공부하기로 했다

TIL - 2023.09.13
CV 이론글창사 - 투자 유치 강의 듣기오늘은 드디어 드디어 컴퓨터 비전 수업을 시작했다. 솔직히 많은 사람들이 컴퓨터 비전이나 생성 모델, nlp를 듣고 싶어서 지금까지 버틴게 아닐ㄲ....지금 11시 20분... 막차를 타기까지 시간이 얼마 안남아 뼈대만 잡고 집으
TIL - 2023.09.12
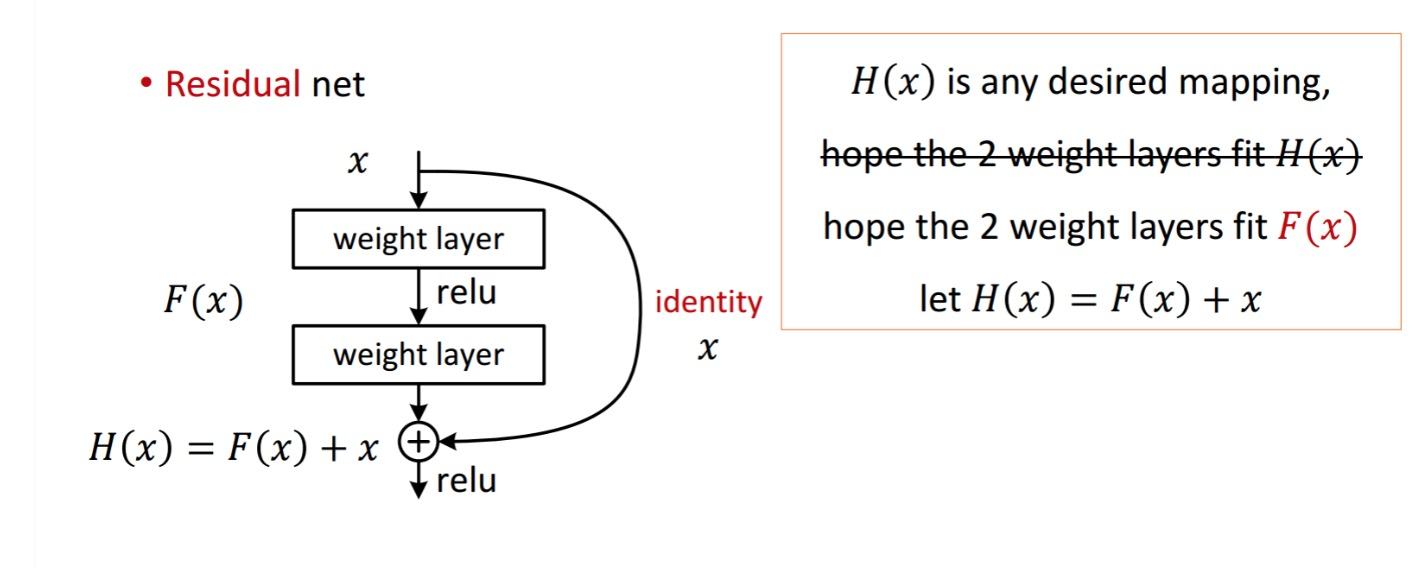
오늘은 저번에 배웠던 CNN, RNN을 이어 다양한 convolutional network 기법들을 배웠다. 다양한 기법이라고 해도 ResNet 나오기 전이라 이제는 역사속으로 사라졌지만 그래도 ResNet이 어떻게 나오게 됐는지, 각 기법들의 shortcomings이
TIL - 2023.09.11
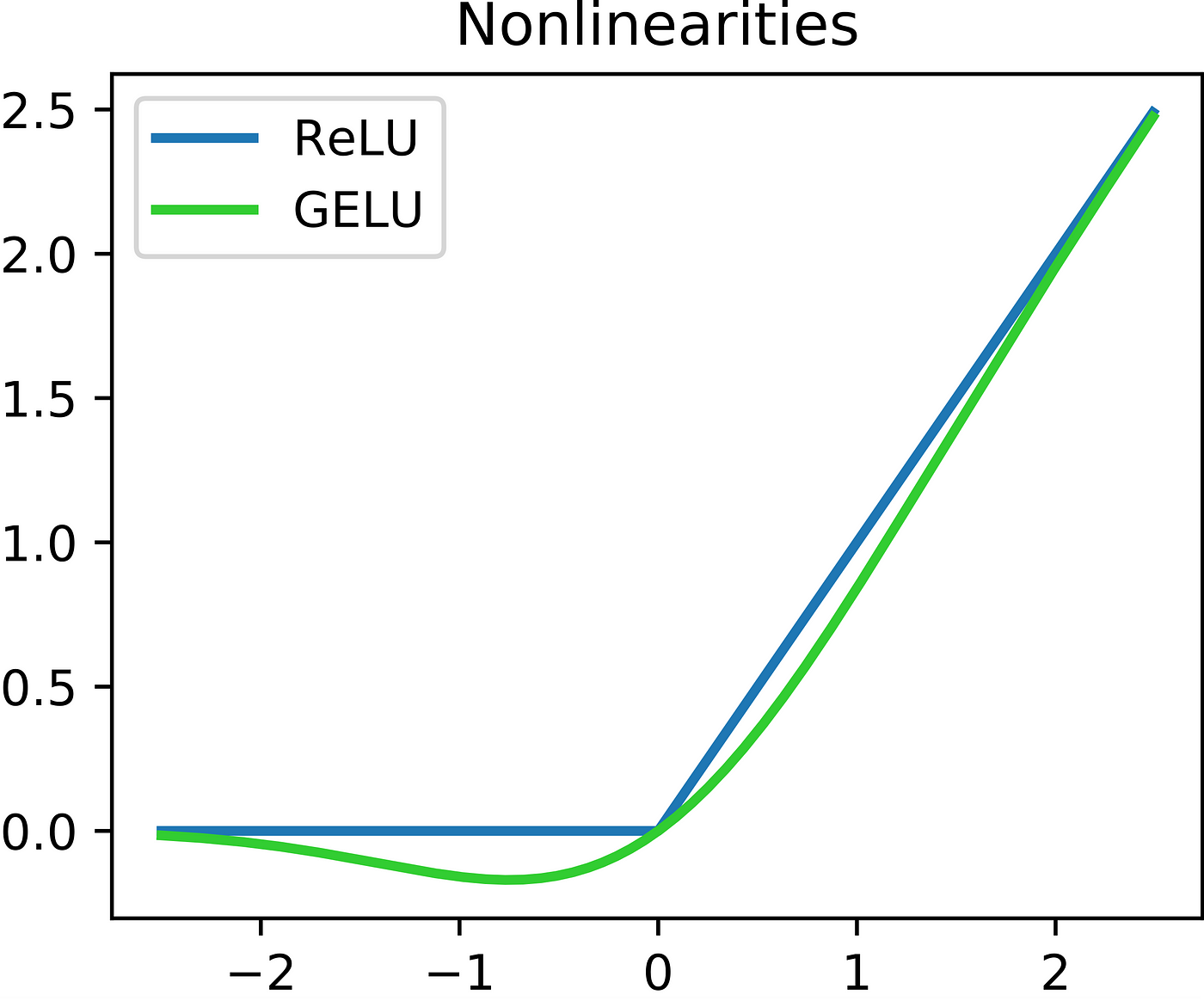
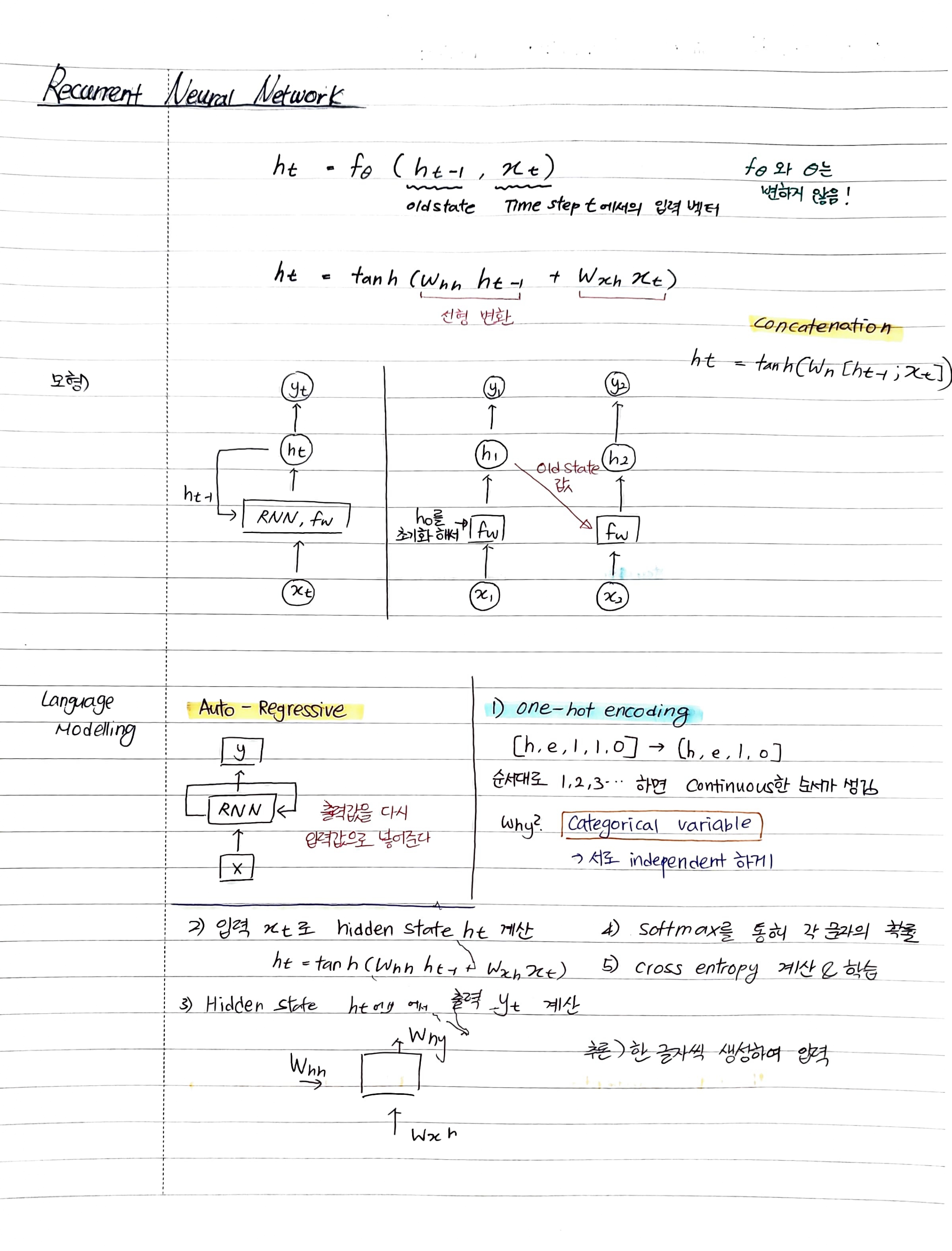
RNN의 단점LSTMself-attentionTransformer다 복습은 못하고 LSTM까지만 했다. 금요일 특강 강의에서 attention이랑 transformer를 공부해서 오늘은 어느정도 채워넣는 느낌이 들었다. 오늘 느낀 것은 노트에 적어가면서 공부하니 오히려
TIL - 2023.08.28
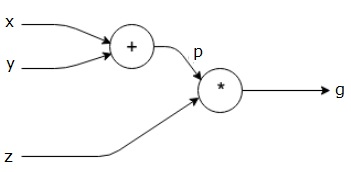
잊기 전에 빨리 쓰는 오늘의 TIL출력층에서 입력층 방향으로 오차를 전파시키며 각 층의 가중치를 업데이트 하는 방식인풋이 2차원 이상; 2개 이상의 변수를 가지는 함수를 다변수 함수라고 하는데, 다변수 함수 $f(x, y)$ 를 $x$로 편미분 하는 것을 $\\frac
TIL - 2023.08.21
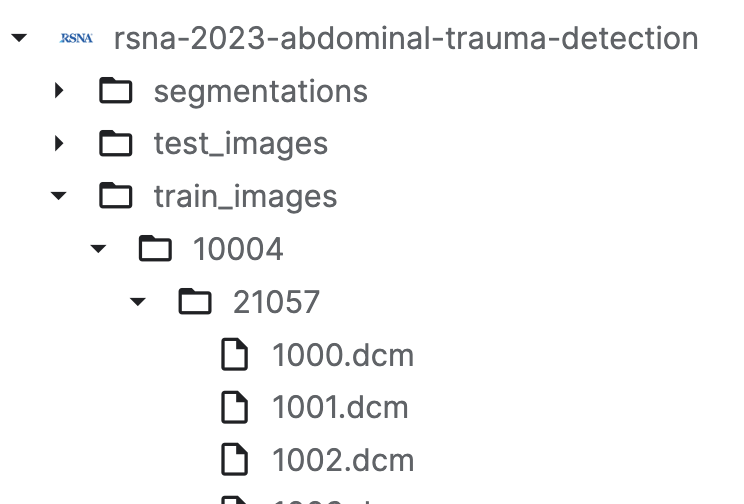
글로벌 클래스 간략하게 읽어가기 모각공 독서 TIL 작성 샐러드 먹기 AWS 환불 메일 작성외상성 복부 부상 판별RSNA EDA | Understanding the Data Firsttrain에서 Keras 모델 생성inference에 만든 Keras 모델 업로드li
TIL - 2023.08.12
오늘은 하루종일 잠만 잔 것...같기도 하고...오빠랑 카페가서 lck도 보고 (왜 베인을 했는가!!!) 집와서 아빠랑 오빠랑 밥먹고... 나름 힐링하는 하루를 보낸 것 같다! 엄청나게 집중해서 공부하지는 못했지만 그래도 나름 힐링하는 나날을 보낸 것 같다.목요일은 스
TIL - 2023.07.27
다항식으로 나타낼 수 없는 (수학적으로 어려운 부분)을 우리가 아는 다항식의 형태로 변환원하는 차수까지 근사 가능하다. \- 차수가 늘어나면 겹치는 구간도 늘어나게 된다.한 변수를 제외한 다른 변수들을 상수로 보고 함수의 단변수 미분을 하는 것반지름의 원 안에서 좌표
TIL - 2023.07.26
LIFO기존 list를 활용push와 pop이 $O(1)$동적배열FIFOQueue를 리스트로 구현할 시 O(N)이 걸린다.→ 다른 방법 필요!Queue 구조 구현양쪽으로 자유로운 입출력head, tail에 pop, push 가능중간 참조는 오래 걸리지만 Queue는 그

TIL - 2023.07.25
절차를 차례대로 실행문제점하나의 수정 사항이 뒤에도 큰 영향을 미칠 수도 있다하나를 고치면 나머지를 고쳐야 할 수도...객체 단위 코드 작성 및 분업Class당 여러 Object을 가질 수 있다.Object들은 다른 Attribute를 가질 수 있지만 Method는 동
TIL - 2023.07.24
테이블 형태의 데이터를 분류하는 트랜스포머less than a second로 분류가 가능하고하이퍼 파라미터 튜닝이 필요 없다PFN은 Bayesian inference를 활용하여 synthetic 데이터셋을 만들어 낸다프로그래머스 > 탐욕법 > 체육복(https:
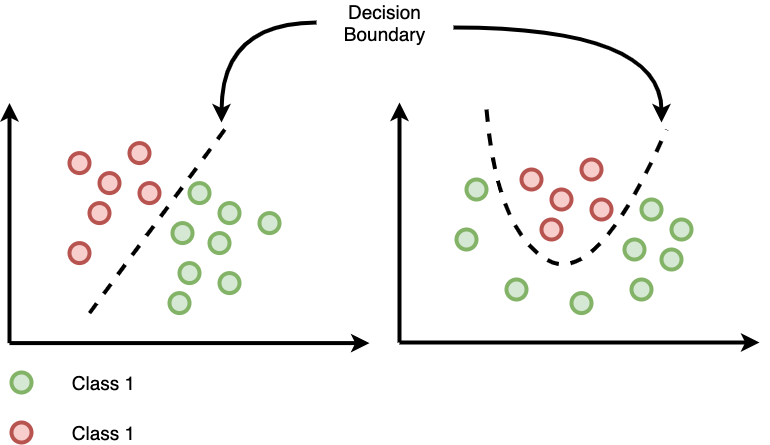
[머신 러닝] 머신 러닝이란?
<머신 러닝 교과서 with 파이썬, 사이킷런, 텐서플로>에서 공부한 내용을 적습니다.머신 러닝 Machine Learning데이터를 이해하는 알고리즘의 과학이자 애플리케이션지도 학습, 비지도 학습, 강화 학습이 있다. 레이블된 데이터직접 피드백출력 및 미래 예측
TIL - 2023.06.15
K-Fold Cross Validation 기법을 활용해서 더 나은 예측을 얻는 예측 기법K개의 모델을 각각 따로 학습 시켜서 K개의 모델이 성능이 가장 높게 나오는 파라미터 조합을 찾는 방식ProcedureGrid로 6가지 하이퍼 파라미터 조합이 있다면5 fold로
TIL - 2023.06.14
K개의 이웃을 고려하여 현재 데이터의 값을 예측KNN과 KMeans는 같지 않다!데이터를 분석하고자 하는 목적에 맞게 가공하는 과정raw data --> (feature engineering) --> feature vecotrfeature space의 차원이 커질수록
TIL - 2023.06.13
맥 말고 윈도우로 쓰는 벨로그는 ... UI가 너무 다르고 딱딱한 것 같다... 마크다운도 미리보기에서는 너무... 굴림체 아니오?Categorical feature에 대해서 학습이 잘 되도록 설계되어 있다.데이터의 갯수를 살펴보자!데이터의 갯수가 10000개 이하라면
TIL - 2023.06.12
오늘은 XGBoost 논문을 배웠는데.. 이건 차근차근 기술블로그로 다시 훑어보며 작성하는게 나을 것 같다.괜히 지금 어설프게 건드렸다가 다 까먹을 것 같아..지금은 아침에 공부하러 오면서 책을 <<1년 안에 AI 빅데이터 전문가가 되는 법>> 책을 읽고 있
TIL - 2023.06.09
블로그 글 (too private)으로 시작한 것들이 적다보니 too professional 해지기 시작한다.이런 내용을 고도화하고 싶어져 연구를 시작하게 됐다.불분명한 것들 (헷갈리는 명제를) formula, equation을 사용해 이론을 가져와 설명을 하면 'cl
TIL - 2023.06.08
오늘은 이론 공부는 없었고 실습 코드만 하루종일 돌렸다.실습 진행하면서 기억 해야할 몇 가지를 적어봐야지으로 데이터를 붙일 때는 자동으로 인덱스를 바꾸는 것이 아니라서처음 들어간 데이터를 바탕으로 DataFrame인덱스가 설정된다.예를 들어, traintrain.num