
- 전체보기(97)
- dev(24)
- LLM(16)
- NLP(13)
- AI(13)
- python(11)
- rag(11)
- 글또(11)
- nmt(10)
- 기계번역(8)
- agent(6)
- FastAPI(6)
- llama3(5)
- langChain(5)
- 회고(5)
- 인공지능(5)
- WeCode(5)
- transformer(5)
- Paper(4)
- github(3)
- Backend(3)
- opensource(3)
- 수강후기(3)
- 온라인강의(3)
- 리뷰(3)
- ASR(3)
- 유데미(3)
- git(3)
- 음성인식(3)
- 내출어(3)
- udemy(3)
- OLLAMA(3)
- OSSCA(3)
- 자연어처리(2)
- 우아한스터디(2)
- RAGAS(2)
- 오픈소스(2)
- pgvector(2)
- MT(2)
- speechRecognition(2)
- express(2)
- MNMT(2)
- mlops(2)
- LLaMA(2)
- langgraph(2)
- OpenNMT(2)
- 머신러닝(2)
- Speaker_Diarization(2)
- LangCon(2)
- rhasspy(1)
- 개발자원칙(1)
- JavaScript(1)
- COMET(1)
- whisper(1)
- 허깅페이스(1)
- Triton(1)
- Nginx(1)
- docker(1)
- chatbot(1)
- 대규모언어모델(1)
- 화자분할(1)
- OpenAI(1)
- 여행(1)
- vectorstore(1)
- 생성모델(1)
- 데이터셋(1)
- SQLAlchemy(1)
- DEVOCEAN(1)
- 고투런(1)
- AutoRAG(1)
- voice2json(1)
- koalpaca(1)
- alpaca(1)
- 생성형AI(1)
- streamlit(1)
- postgre(1)
- gunicorn(1)
- Multi-Agent(1)
- unsloth(1)
- MTPE(1)
- 음성비서(1)
- dalai(1)
- airflow(1)
- jsgf(1)
- 랭콘(1)
- 파이썬(1)
- WMT(1)
- SpeakerRecognition(1)
- 위코드(1)
- APE(1)
- simple-diarizer(1)
- 화자인식(1)
- memo(1)
- 비제이퍼블릭(1)
- 데보션(1)
- 언어모델(1)
- 독후감(1)
- review(1)
- 강화학습(1)
- 트랜스포머(1)
- pyannote(1)
- MachineTranslation(1)
- Fairseq(1)
- npm(1)
- TorchServe(1)
- prompt(1)
- huggingfaceoss(1)
- 언어학(1)
- summarization(1)
- 모코숲(1)
- K-DEVCON(1)
- PCF(1)
- RRF(1)
- 모델경량화(1)
- 골든래빗(1)
- 화자분리(1)
- JavaSpeechGrammarFormat(1)
- PyTorch(1)
- hybridsearch(1)
- 딥러닝(1)
- Fast-Whisper(1)
- TDD(1)
- LangCon2024(1)
- ensemble retriever(1)
- 에이전트(1)
- moonlight(1)
- ctranslate(1)
- Diart(1)
- ML(1)
[LLM-MT 시리즈] (논문 구현🪄) DRT: Deep Reasoning Translation via Long Chain-of-Thought
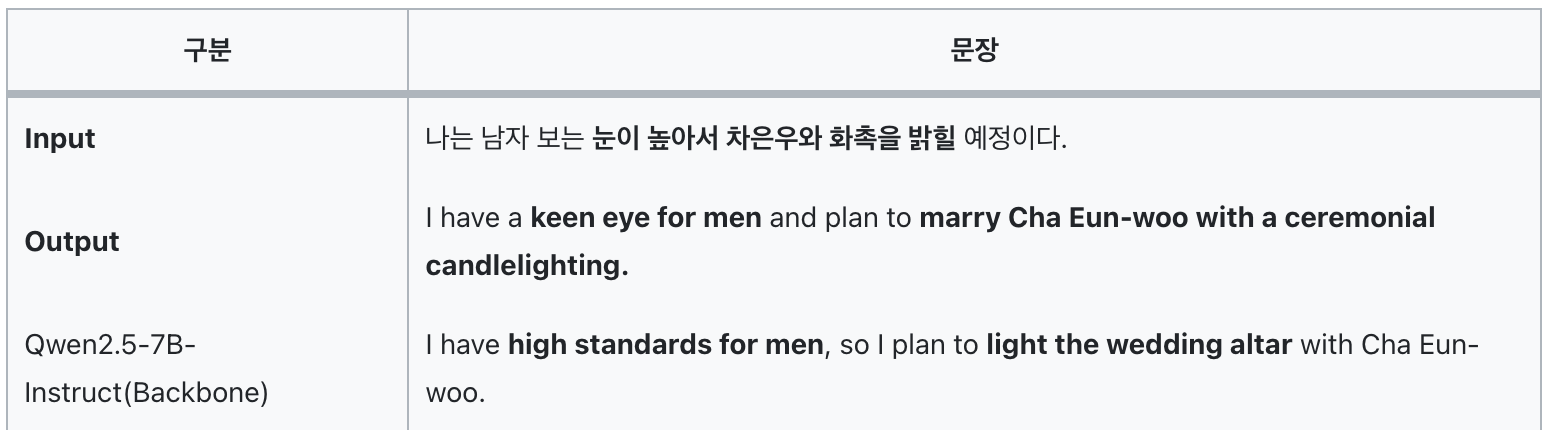
Source 문장을 입력하면 Target 언어로 번역한 결과와 번역 과정(Thinking trace)을 생성하는 'DRT' 모델 구현📄 논문 : DRT: Deep Reasoning Translation via Long Chain-of-Thought📝 논문 리뷰 :
[LLM-MT 시리즈] (논문 리뷰) DRT: Deep Reasoning Translation via Long Chain-of-Thought
논문 : DRT: Deep Reasoning Translation via Long Chain-of-Thought데이터셋 : GitHub (코드 없이 데이터셋만 공개)DRT 모델 : DRT-7B / DRT-8B / DRT-14BDRT: 문학 번역을 위한 긴 사고 과정 기

[OSSCA] 2025 참여형 : 합격 후기
OSSCA '체험형' 프로그램 멘티로 선발되어 지원서 작성 경험을 공유합니다.최근 OSSCA 체험형 1차 프로그램을 성공적으로 마쳤고,\[OSSCA] 2025 체험형-1차 : 합격 후기너무 좋은 경험이었기에 체험형 다음 단계인 참여형 프로그램에 지원했다!홈페이지 : h
[K-Devcon] 고투런 2기 - AI 여행 에이전트 프로젝트 후기
👩🏫 정유선 멘토님 20년차 AI 엔지니어에게 배우는 AI 에이전트의 모든 것 결과공유회 발표자료 : Travel Agent : 나만의 여행 비서 만들기 GitHub : GoToLearn-AI_Agent 스터디 개요 진행방식 팀 구성 : 멘토님 1인 + 멘티
[OSSCA] 2025 체험형-1차 : PR Agent 프로젝트 후기
오픈소스 컨트리뷰션 프로젝트를 6주에 걸쳐 수료했다. 우리 조는 당초 프로젝트 목표대로 6주 안에 PR을 보내지는 못했지만 수료 이후에도 계속해서 개발과 보완, 피드백 반영을 거쳐 최종적으로 PR 및 Merge 완료했다! 프로젝트 소개 1. 프로그램 개요 프로그램

[OSSCA] 2025 체험형-1차 : 합격 후기
OSSCA '참여형' 프로그램 멘티 모집을 앞두고, 최근 활동을 마친 '체험형' 지원서 작성 경험을 공유합니다.(따로 보관해두지 않고 기억을 되짚어 작성하는 포스팅이므로 실제로 제가 작성했던 지원서 내용과 조금 다를 수 있습니다.)약 2년 전, 입사 면접 자리에서 면접
[NMT] COMET : 신경망 기반 번역 품질 평가 지표
부제 : ChatGPT 를 이용해 10분만에 이해하는 COMETCrosslingual Optimized Metric for Evaluation of Translation최근 몇 년간 주목받고 있는 신경망 기반 번역 품질 평가 지표기존의 BLEU, METEOR, TER처
[LLM-MT 시리즈] LLM 시대의 관용구 번역
본 글은 LLM 관용구 번역 논문을 보고 깜짝 놀라서 새벽 4시에 의식의 흐름대로 작성한 글입니다. 😇쌩초보 NLP 연구자이던 2020년, 나는 2편의 관용구 기계번역 논문을 국내 학회에서 발표했다.관용구 기계번역을 위한 한-영 데이터셋 구축 및 평가 방법한국어 관용

[LLM-MT 시리즈] 초월번역기를 만들어 보자
원문 : What were you guys smokin' when you came up with that?직역 : 그걸 생각해냈을 때 여러분은 무엇을 피우고 있었나요?요즘은 LLM 의 시스템 프롬프트에 출발어 - 도착어를 지정하고, context 를 번역하도록 작성하는
LangCon2025 후기
LangCon2025 안내 페이지 (참고) LangCon2024 후기 매년 3월에 열리는 자연어처리 컨퍼런스 LangCon 에 올해도 다녀왔습니다. 올해에는 AI Agent 를 어떻게 구현하는지 궁금해서 핸즈온 세션만 4개 다 들었습니다. Hands On LLM기반
[리뷰] 자연어 처리를 위한 허깅페이스 트랜스포머 하드 트레이닝
장점 자연어처리 거의 모든 태스크를 다룸 문장분류, QA, NER, 번역 등등 심지어 인코더, 디코더, 인코더-디코더 모델별로 각각! 최신 기술 but 현업에서 반드시 필요한 경량화도 쉬운 설명 + 코드 제시 실무에 즉시 활용 가능 (꼭 필요한 코드만 간추려서
[RAG 시리즈] ChatBot 구축하기 : Rule Base 부터 LangGraph 까지
보험사, 금융사, 사내 메뉴얼 등 문서를 참조하는 챗봇에서 RAG가 사용되는 경우가 많은데요,다시 말해, 좋은 챗봇을 구축하는 일 또한 RAG개발에 수반되는 업무입니다.이번 포스팅에서는 Rule Base 로 챗봇을 구축한 경험을 공유하고,최근 AI Agent 개발에 쓰

[리뷰] 프롬프트 엔지니어링의 비밀
프롬프트 엔지니어링의 비밀 : 10가지 사례로 쉽게 터득! LLM과 챗GPT에게 원하는 결과를 얻는 비법!요즘에는 LLM API(ex : ChatGPT) 를 사다가 웹 개발물에 붙여서 서비스를 만드는 경우가 정말 많다.이 책을 읽게 된 동기는 최근 모 번역 스타트업 면
[RAG 시리즈] 임베딩 모델별 RAG 성능 비교
지난 포스팅에서 다음과 같은 고찰을 했는데요, 따라서 이번 포스팅에서는 embedding 모델별 RAG 품질을 비교합니다. 또한 유료로 사용하는 OpenAI 모델뿐만 아니라 무료(속도는 느리지만) HuggingFace 모델도 함께 비교합니다. 튜토리얼 코드 : Gi
[RAG 시리즈] RAGAS 를 이용한 실전 RAG 평가
RAGAS 는 RAG 의 평가지표 중 특히 Rule Base 지표들을 자동으로 계산하기 위해 만들어진 프레임워크입니다.쉽게 말해 RAG 파이프라인을 구축한 후,파이프라인의 input / output 을 이용해 평가 지표 계산에 필요한 데이터셋 (question, ans
[회고] 2024년 회고
2024년에는 LLM 에 입문했고, 새로운 프로젝트들을 해 보았고, 운 좋게 대기업에서 지원하는 스터디에 3개나 합격해서 완주했고, 글또 활동하는 동안 패스 한 번 쓴 적 없이, 지연 한 번 없이 글을 제출하고 있고 회고에 쓸 거리가 생각보다 많을 만큼 돌이켜 보니 많

[RAG 시리즈] PDF 로부터 데이터를 추출하는 라이브러리 비교 (PyPDF, Fitz, PdfPlumber)
실무에서 RAG 서비스를 개발할 때 RAG 및 LLM 의 성능을 개선하는 것만큼 중요한 점은 서비스에 사용할 문서에서 RAG가 질의에 맞는 내용을 검색하고 검색 결과 데이터를 LLM에 적합한 형태와 크기로 제공하는 것인데요. 다시 말해, 문서 데이터 또는 문서 파일을
[RAG 시리즈] Multi-Query 와 Fusion 기법
RAG(Retrieval-Augmented Generation)에서 retrieve 단계에서 사용하는 multi-query와 fusion 기법은 질의의 정확성을 높이고 더 풍부한 정보를 얻기 위해 사용됩니다. 두 기법은 주로 검색 결과의 질을 높이고, 다양한 정보 조합

[RAG 시리즈] Hybrid Search 와 재순위화 알고리즘 (RRF 를 곁들인..)
Hybrid Search 설명을 위해 다음 포스팅 글 중 일부를 발췌하여 재구성했습니다. [우아한 스터디] RAG 성능을 끌어올리는 Pre-Retrieval (Ensenble Retriever) 와 Post-Retrieval (Re-Rank) 하이브리드 검색 구현하기
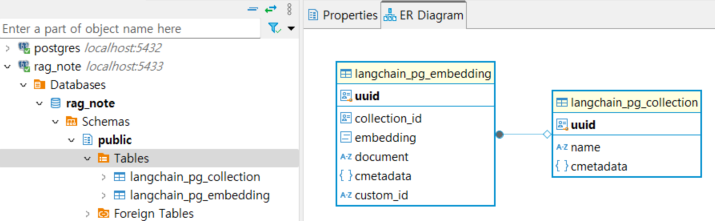
[RAG 시리즈] LangChain VectorStore DB구조와 활용
[RAG 시리즈] PGVector 와 프롬프트를 이용한 RAG 고도화 포스팅에서 PDF 파일 로드 -> 청킹 -> vector store 에 저장하는 과정을 다루었는데요, 이번 포스팅에서는 vector store DB에 데이터가 어떤 형태로 저장되어 있는지 살펴보고,