
[MLOps] Azure Web App 기반 Flask 애플리케이션 배포하고 CI/CD 파이프라인 구축하기 1
<MLOps 실전 가이드> 책 실습 두번째, 공식 문서의 가이드를 따라 Flask 프로젝트를 Azure Web App에 배포해 보자. https://learn.microsoft.com/ko-kr/azure/devops/pipelines/ecosystem
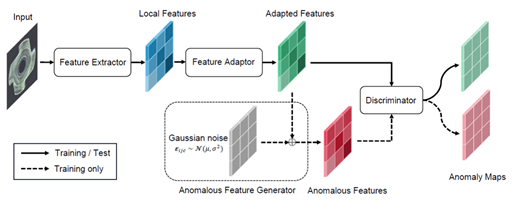
SimpleNet: A Simple Network for Image Anomaly Detection and Localization (CVPR 2023)
SimpleNet
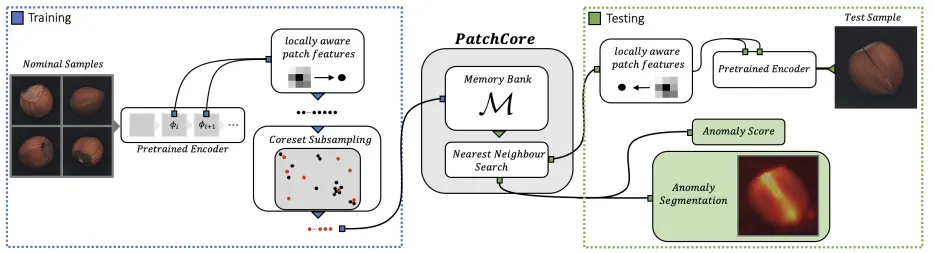
[논문 리뷰] PatchCore: Towards Total Recall in Industrial Anomaly Detection (Roth et al., CVPR 2022)
ㅇㅇ
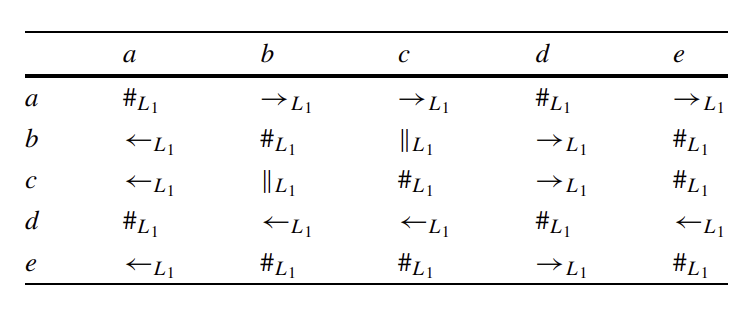
[Process Mining] Alpha Algorithm
알파 알고리즘은 event log를 입력으로 받아 petri-net을 산출하는 알고리즘이다. Process Discovery와 관련해서 baseline이 되는 가장 기본적이며 단순한 알고리즘이다.먼저 α-Algorithm의 Basic Idea에 대해 알아 보자.입력:
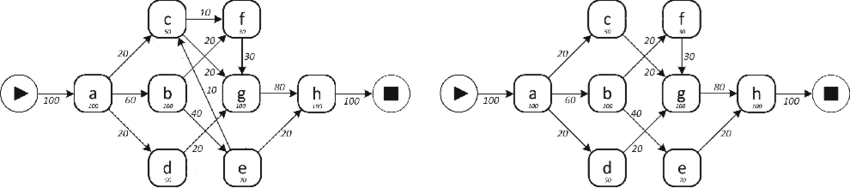
[Process Mining] Procees Discovery (1) Petri Net
Process Discovery 추출한 event log를 통해 process model을 도출하는 과정이다. (여기서 event log는 이전 글에서 소개했듯 multiset of traces이고, process model은 set of traces를 정의한다.)
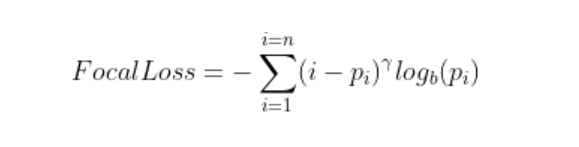
[Process Mining] 이벤트 로그(event logs)
하나의 프로세스는 여러 케이스(cases)로 이루어진다. 하나의 케이스는 여러 이벤트(events)로 이루어지며, 각 이벤트는 정확히 하나의 케이스와 관련된다. 케이스 내의 이벤트들은 순서가 지정된다. 이벤트는 속성(attributes)을 가질 수 있다. 대표
[ML] Data Imbalance Problems, Undersampling, Oversampling
데이터 불균형 문제 대부분의 분류 알고리즘은 학습 데이터에 범주간 비중이 비슷할 때, 각 범주의 특징을 충분히 학습할 수 있다. 하지만 현실 상황에서는 특정 범주가 다른 범주에 비해서 매우 적은 경우가 많다. 표본 수가 상대적으로 많은 class를 majority c
[ML] Logistic Regression
## Logistic Regression (로지스틱 회귀) <br> Logistic Regression (로지스틱 회귀)란 Binary Classification (이진 분류) 문제를 해결하기 위한 모델이다. ex) 스팸 메일, 질병 양성/음성 분류 등 Sigm
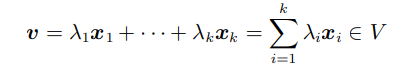
[Linear Algebra] Linear Combination, Linear Independence, Basis
Vector space V 와 유한한 수의 벡터 x1,…,xk ∈V 가 있을 때, 아래의 형태를 만족하는 모든 v∈V (λ1 ,…,λk ∈R) 를 벡터 x1, …,xk 의 linear combination 이라고 한다. 간단하게 말하면 벡터를 스칼라곱과 벡터끼리의 합
[ML] Regression
Linear Regression (선형 회귀) 데이터를 가장 잘 설명하는 모델을 찾아 입력값에 따른 결과값을 예측하는 알고리즘 완벽한 예측은 불가능하기 때문에, 데이터의 실제값과 예측값의 차이를 최소한으로 하는 선을 찾아야한다. 선형 회귀는 크게 두 가지 종류로
[ML] Generalization, Overfitting, Underfitting, Bias & Variance
Generalization (일반화) 학습에 사용된 데이터가 아닌 처음 보는 새로운 데이터에 대해 올바른 예측을 수행하는 능력 what is good model ? 머신러닝에서 좋은 모델은 현재 데이터를 잘 설명하며, 미레 데이터에 대한 예측 성능이 좋은 모델이다
[ML] Feature Selection, Regularization (Lasso, Ridge, ElasticNet)
모델의 성능을 높이기 위해 단순히 많은 feature를 사용하는 것이 항상 좋은 것은 아니다. 불필요한 feature가 많아질수록 모델은 학습 데이터에 과도하게 적합되는 overfitting 문제가 발생할 수 있다. 이를 방지하기 위해 feature selection
[ML] 머신러닝 개요
What is Machine Learning ? > Machine Learning is “the field of study that gives computers the ability to learn without being explicitly programmed.”
[CV] 이미지 처리 기초
Image Processing 이미지 처리 Analog Image Processing 물리적 수단을 이용하여 이미지를 조작하거나 편집하는 것 Digital Image Processing 컴퓨터가 디지털 이미지를 처리하는 데 수학적 알고리즘과 계산 기술에 의존
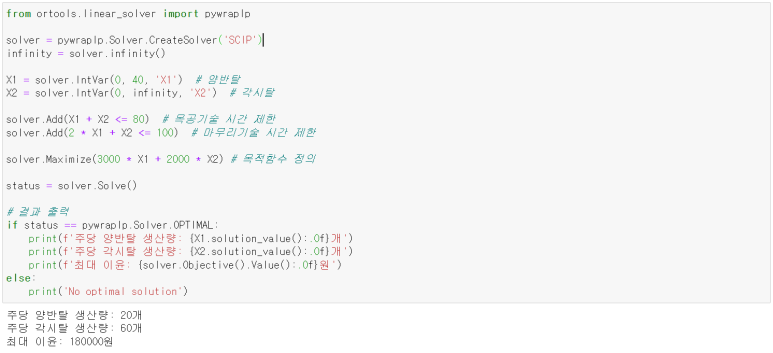
Linear Programming 정리
최적화 : 문제가 주어졌을 때, 문제에 대한 가장 최적의 해를 찾는 것이다. 결정변수와 목적함수 (최대화 or 최소화), 제약조건들에 대한 식을 만들 수 있다. 선형계획법(LP: linear programming) : 최적화 기법 중 하나이자, 제약조건들과 목적함수