
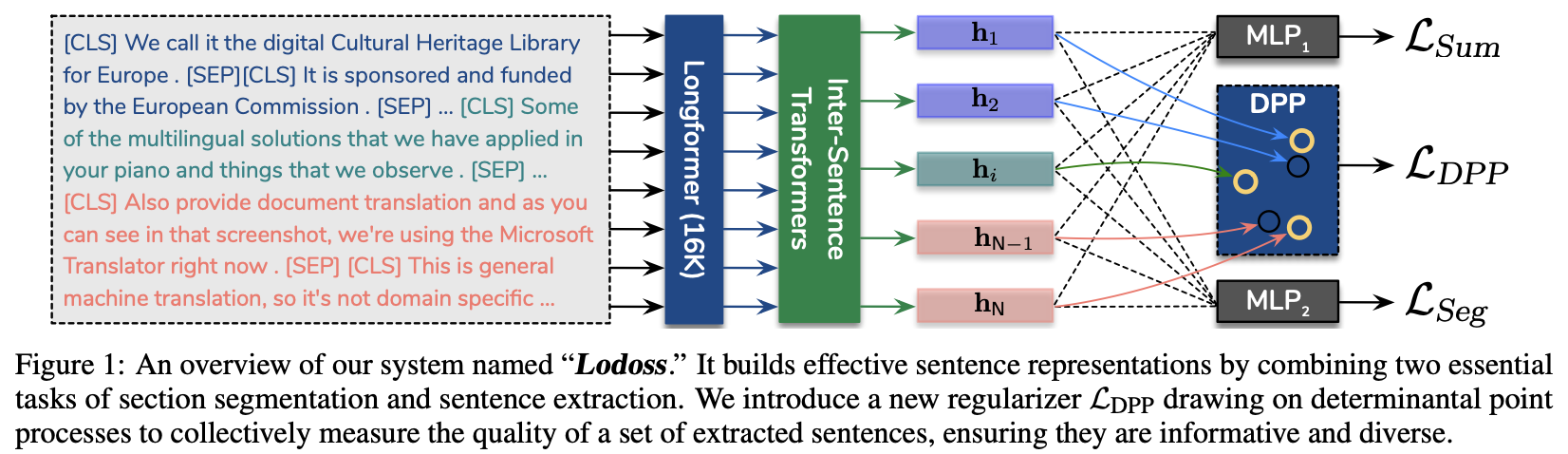
[논문 리뷰] Toward Unifying Text Segmentation and Long Document Summarization
이 논문은 EMNLP2022에 게재된 논문으로, 모델에게 Text Segmenatation에 대한 정보를 학습하게 해 추출 요약의 성능을 높이는 방법을 제안하고 있습니다.section segmentation이 문어 및 구어체 원문의 extractive summariza
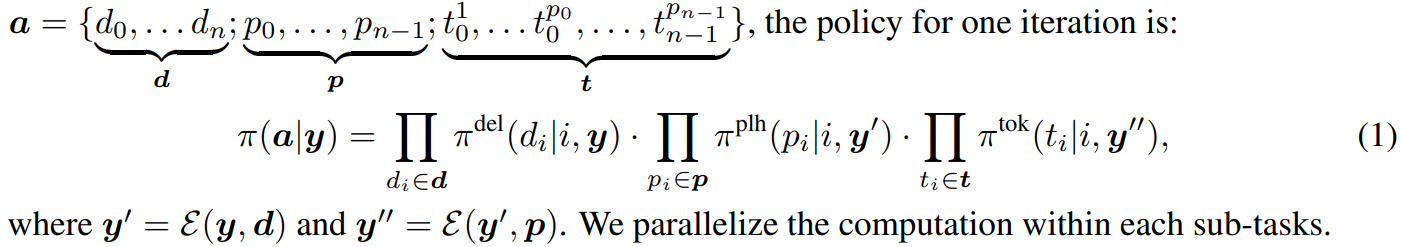
Levenshtein Transformer
본 논문은 2019 NeurIPS에 실린 논문으로, 강화학습을 사용해 좀 더 flexible하고 amenable한 sequence를 생성하는 모델을 제안token을 step-by-step으로 생성하는 것이 아니라, insertion 혹은 deletion을 사용해 현재
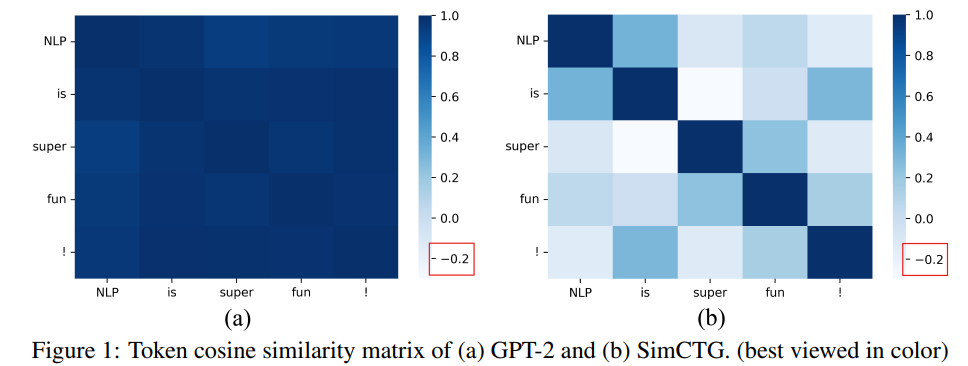
[논문 리뷰] A Contrastive Framework for Neural Text Generation
이 논문은 2022년 9월 26일에 올라온, 2022 NeurIPS에 accept된 논문입니다!논문 리뷰에 너무 많은 시간이 걸리는거 같아서, 이번엔 motivation, proposed methods, experiment conclusion형식으로 리뷰해보려고 합니다
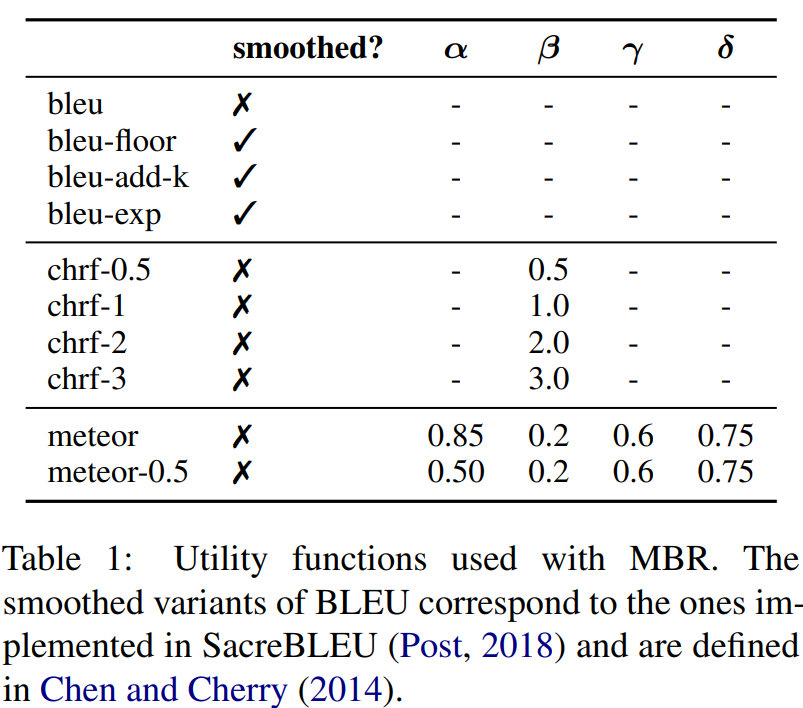
[논문 리뷰] Understanding the Properties of Minimum Bayes Risk Decoding in Neural Machine Translations
현재, NMT(Neural Machine Translation)는 모델이 생성한 번역이 너무 짧거나 빈도가 높은 단어를 overgenerating, 학습 데이터의 copy noise나 domain shift에 poor robustenss한 경향이 있음=> 최근 연구에서
10분 테코톡 Process vs Thread 정리
\*\* 키워드 정리실행 단위 : CPU core에서 실행하는 하나의 단위로 프로세스와 스레드를 포괄하는 개념프로세스 : 하나의 스레드만 가지고 있는 단일 스레드 프로세스동시성 : 한 순간에 여러가지 일이 아니라, 짧은 전환으로 여러가지 일을 동시에 처리하는 것처럼 보
[논문 리뷰] TSDAE : Using Transformer-based Sequential Denoising Auto-Encoder for Unsupervised Sentence Embedding Learning
사전 학습된 transformer와 Sequential Denoising Auto-Encoder를 기반으로하는 새로운 SOTA 방법을 제안in-domain supervised 방법의 93.1%까지 성능 달성TSDAE는 강한 domain adaptation이면서 MLM같
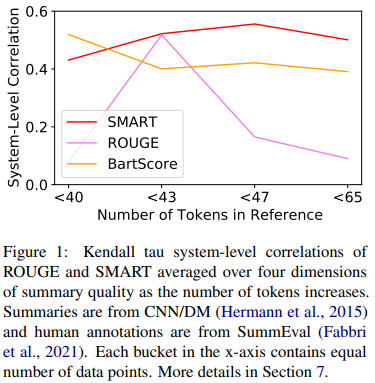
[논문 리뷰] SMART : Sentence as Basic Units for Text Evaluation
SMART는 토큰 대신 문장을 matching시 기본 단위로 사용또한 문장과 문장이 완전히 일치하는 방법이 아니라 matching function을 사용해 soft-matching되는 문장을 사용Candidate 문장은 reference문장 뿐만 아니라 원문 문장과도
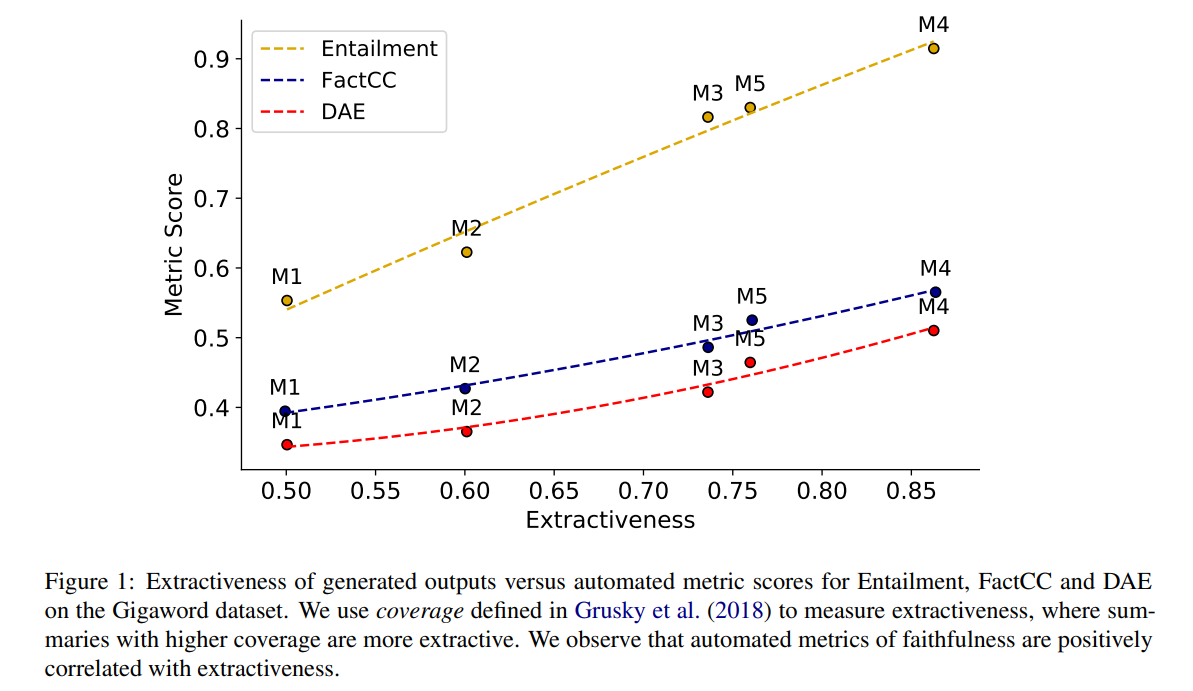
[논문 리뷰] Faithful or Extractive? On mitigating the Faithfulness-Abstractiveness Trade-off in Abstractive Summarization
생성 요약에서 발생하는 incosistency를 줄이기 위해 많은 연구자들이 다양한 모델을 내놓고 있는데, consistency와 abstractiveness사이에 trade-off관계를 이용한 consisteny 성능 향상은 아니었을까?에 대한 의문을 조금이나마 해소
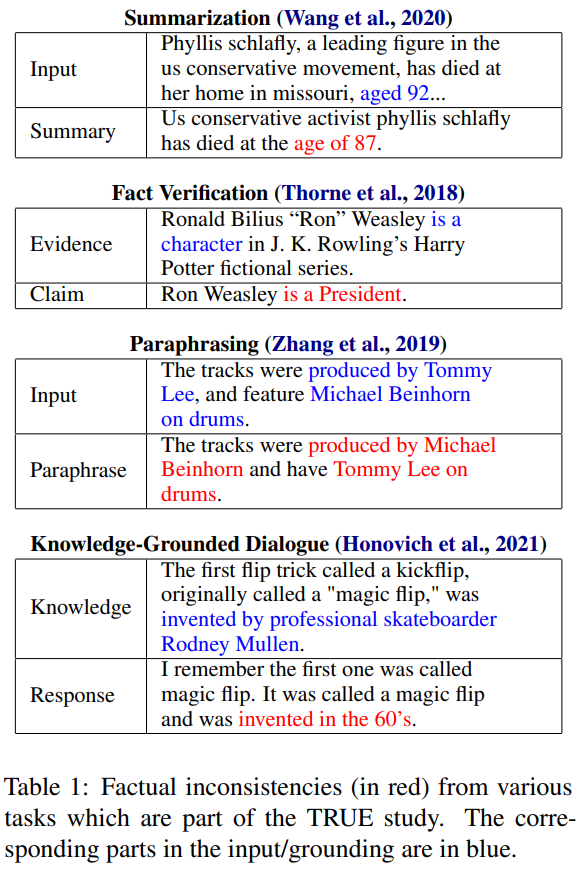
[논문 리뷰] TRUE : Re-evaluating Factual Consistency Evaluation
원문 기반 텍스트 생성은 factual inconsistency라는 치명적 단점 존재factual inconsistency는 생성문이 원문과 맞지 않는 사실 또는 존재하지 않는 사실을 내포하는 것을 의미그래서 최근에 다양한 factual consistency evalu
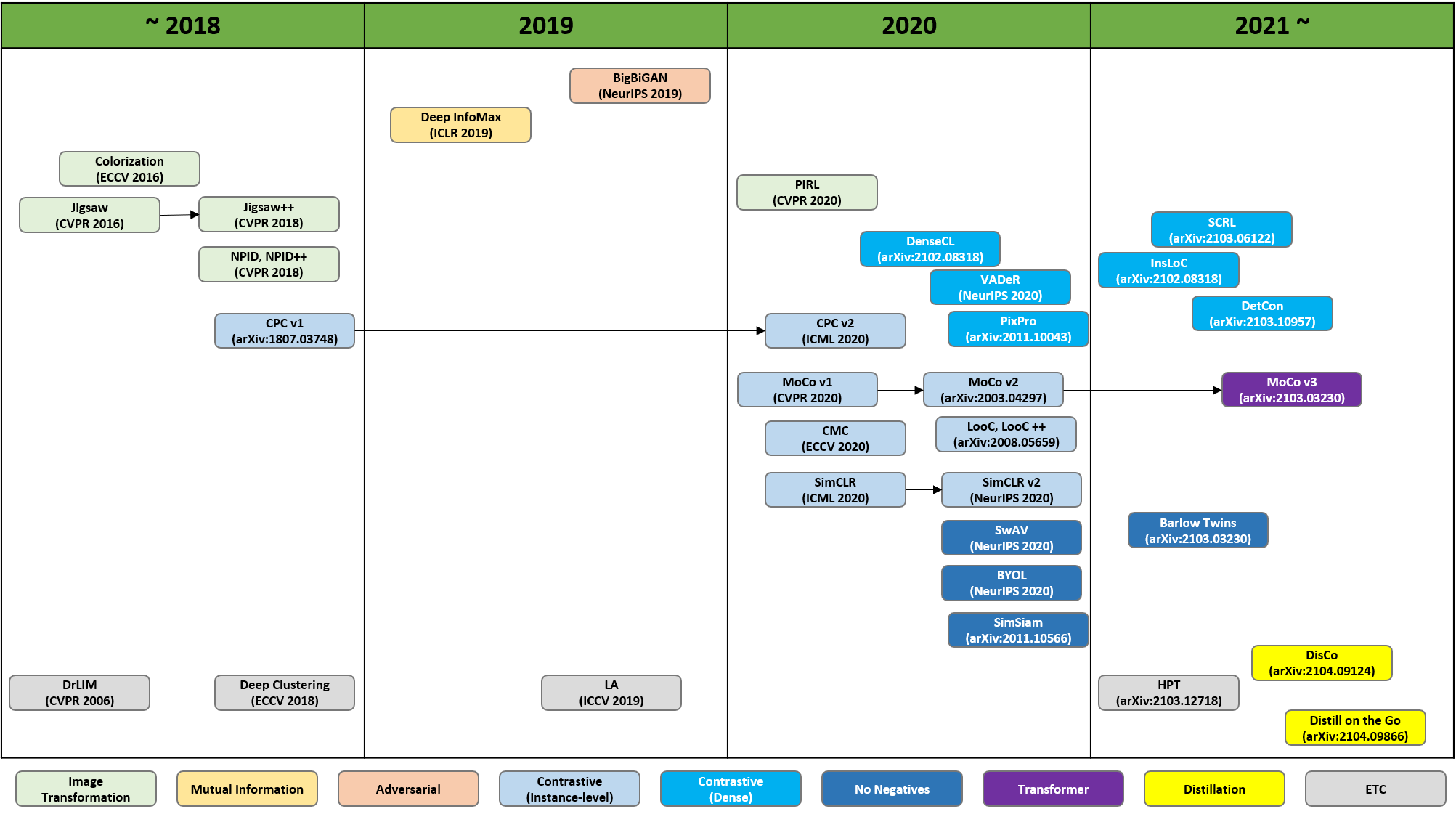
Self-Supervised Learning(DenseCL, MoCo-v3, Barlow Twins)
이 중, Constractive(Dense), No Negatives, Transformer기반 방법인 DenseCL, Barlow Twins, Moco v3에 대해 리뷰해보려 함.2021년 4월에 실린 논문MoCo-v2를 베이스로 하고, MoCo-v2에서 사용한 co
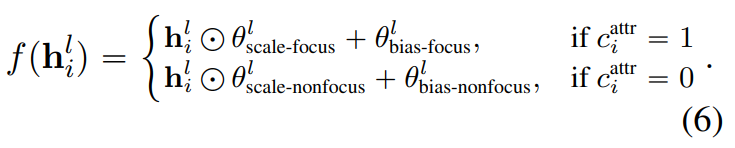
[논문 리뷰] Controlling the Focus of Pretrained Language Generation Models
본 논문은 2022년 5월에 ACL에 실린 논문으로, textcnn의 저자인 Yoon Kim님이 2저자인 논문입니다.간단하게 정리만 한 글입니다.pretrained transofrmers based langauge generation models의 fine-tuning
[운영체제] CH2 컴퓨터의 구조와 성능 향상
컴퓨터는 중앙처리장치(CPU), 메인 메모리(RAM), 입력장치, 출력장치, 저장장치로 구성됨.오늘날의 컴퓨터는 대부분 폰노이만 구조를 따름. 폰노이만 구조 : CPU, 메모리, 입출력장치, 저장장치가 버스로 연결되어 있는 구조: 가장 중요한 특징은 "모든 프로그램은

Evaluation of GANs & GAN Disadvantages and Bias
\*\* 본 포스팅은 cousera GANs 5,6강을 보고 작성되었습니다.예를 들어 classifier의 경우, 답이 정해져 있으므로 모델이 무언가 결과를 내뱉었을 때 옳은지 틀린지 바로 평가할 수 있다.하지만, GAN의 경우 noise를 넣어 진짜인 것 같은 가짜
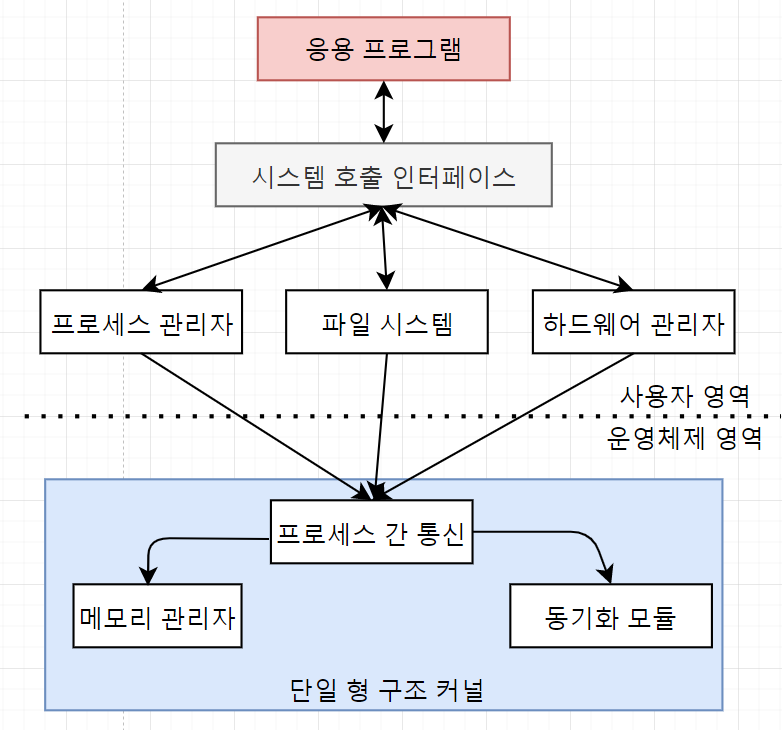
[운영체제] CH1 운영체제의 개요
"쉽게 배우는 운영체제"라는 책을 읽고 간단하게 정리한 게시물입니다.컴퓨터는 운영체제가 없어도 작동하는가?작동함(e.g. ANIAC). 운영체제가 없어도 컴퓨터라고 부르는 이유는 프로그래밍이 가능했기 때문. 하지만 새로운 기능을 구현하려면 매번 회로를 변경해야하고, 복
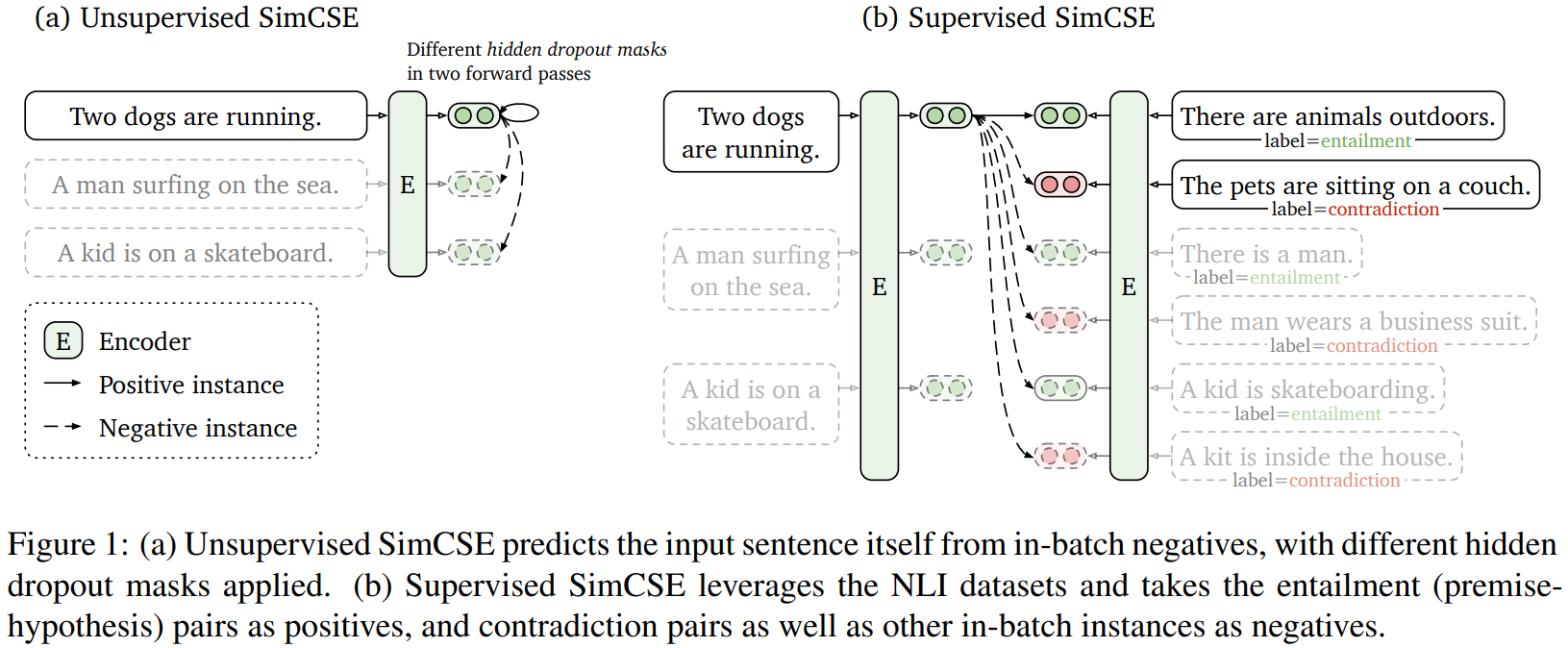
[논문 리뷰] SimCSE : Simple Contrastive Learning of Sentence Embeddings
본 논문에서는 최첨단 문장 임베딩을 크게 향상시키는 간단한 contrastive learning framework를 제안한다. 우리는 먼저 input sentence를 취하고, dropout을 noise로 사용해 constrastive objective에서 스스로를

[논문 리뷰] FEQA : A Question Answering Evaluation Framework for Faithfulness Assessment in Abstractive Summarization
본 논문은 2020 ACL에 실린 논문입니다. Summarization task에서 factual inconsistency를 해결하기 위해 QA방식을 이용해 metric을 제안하고 있습니다. factual inconsistency에 관해 궁금하다면 전의 포스트 중 하나

[논문 리뷰] Characterizing the Efficiency vs. Accuracy Trade-off for Long-Context NLP Models
긴 텍스트를 다루는 NLP의 다양한 응용으로, 더 긴 input sequences를 다룰 수 있는 모델의 정확도를 측정하는 벤치마크들이 부상하고 있다. 하지만, 이러한 벤치마크 들언 input size 또는 model size가 달라짐에 따라 정확도, 속도 그리고 전력

[논문 리뷰] The Factual Inconsistency Problem in Abstractive Text Summarization: A Survey
현재 다양한 신경망 인코더 디코더 모델이 생성 요약 분야에서 좋은 모습을 보이고 있다. 하지만 신경망 모델의 생성 요약 능력은 양날의 검과 같다. 생성 요약의 흔한 문제 중 하나는 원문의 factual information을 왜곡하거나 생성하는 것이다. 이러한 원문과

[Tobigs16] NLP Basic
Tobigs16&17기 정규세션에서 사용했던 NLP Basic교안입니다.Tobigs15기 조효원님의 NLP Basic 강의 내용을 기반으로 내용을 족므 더 추가하는 식으로 정리하였습니다.
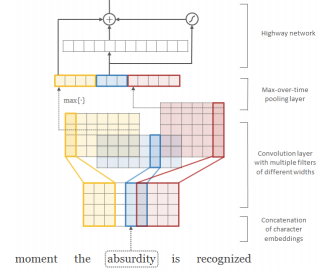
[논문 리뷰] Deep contextualized word representations
이번에 리뷰할 논문은 바로 ELMo의 시작, "Deep contextualized word representations"입니다. Abstract 본 논문에서는 새로운 타입의 deep contextualized word representation을 소개하고 있습니다.