
- 전체보기(167)
- python(60)
- LLM(13)
- ML(13)
- AI(9)
- Tabular(8)
- linux(7)
- github(7)
- 알고리즘(7)
- classical machine learning(7)
- C(6)
- benchmark(4)
- OOP(4)
- 인공지능(4)
- nextjs(4)
- cpp(4)
- pycharm(3)
- pandas(3)
- async(3)
- 코딩테스트(3)
- OS(3)
- 머신러닝(3)
- error(2)
- ubuntu(2)
- Leaderboard(2)
- 파이썬(2)
- DL(2)
- 악당개념(2)
- 비동기(2)
- 구름ide(2)
- class(2)
- React(2)
- 인사이트(2)
- 확률과 통계(2)
- RAGchain(2)
- web(2)
- classical machinelearning(2)
- transformer(2)
- EDA(2)
- trouble shooting(2)
- mac(1)
- Syntax(1)
- BroadCasting(1)
- rag(1)
- Tensor(1)
- asyncio(1)
- github commit(1)
- metric(1)
- PyTorch(1)
- 베이지안(1)
- TDD(1)
- tenacity(1)
- 오픈소스개발방법및도구(1)
- 객체지향 프로그래밍(1)
- Regression(1)
- sample(1)
- 환경변수(1)
- 구름 ide(1)
- csat(1)
- 공개키 이슈(1)
- pakage(1)
- counter(1)
- 책리뷰(1)
- 개념(1)
- 깨달음(1)
- JavaScript(1)
- 파이참(1)
- method(1)
- 공개키(1)
- test code(1)
- pytest(1)
- Feature Engineering(1)
- turtorial(1)
- commit(1)
- Tailwind CSS(1)
- Classification(1)
- 개발환경(1)
- html(1)
- Design Pattern(1)
- LAB(1)
- tool(1)
- machine learning(1)
- NAMING(1)
- issue(1)
- RL(1)
- list comprehension(1)
- RE(1)
- classmethod(1)
- K-fold Cross Validation(1)
- hallucination(1)
- ensemble(1)
- next.js(1)
- react.js(1)
- next js(1)
- 지도학습(1)
- Embedding(1)
- postman(1)
- CNN(1)
- .env(1)
- for루프(1)
- selecting right languages(1)
- super resolution(1)
- drop() 없이 특정값 포함된 row 없애기(1)
- 운영체제(1)
- FastAPI(1)
- .gitignore(1)
- algorithm(1)
- 억까리스트(1)
- vscode(1)
- 논문리뷰(1)
- WSL(1)
- local llm(1)
- CV(1)
- enumerate함수(1)
- boolean mask(1)
- 정규표현식(1)
- 개발 방법론(1)
- GPT(1)
- 회고(1)
- regular expression(1)
- Tokenize(1)
- TROUBLESHOOTING(1)
- 틀렸습니다!(1)
- 자료구조(1)
- llm 서빙(1)
- Trouble Shoot(1)
- 악당 용어(1)
- Paper(1)
- 게시(1)
- 배포(1)
- minsing식 정리(1)
- 반례찾기(1)
- 개발(1)
- image(1)


pyimage1 doesn't exist error
문제 요약:main.py에서 AutoComplete.autocomplete()을 실행하면 PostgreSQL 연결은 성공 메시지가 뜨지만 실제 데이터 조회 (User.get_random_meme())에서 동작하지 않거나, GUI가 에러 (pyimage1 doesn't

What is daemon?
In computing, a daemon is a program that runs as a background process, rather than being under the direct control of an interactive user.


임베딩과 tokenize개념
sequence(text, frame으로 나뉘어진 f0음성등)을 token으로 나눠서 수치화한것, 인덱싱으로 매핑한것token들에 대해서 의미적인 연관성을 기반으로 배치한것

텐서 조작 팁 - unsqueeze는 뭐냐?
unsqueeze는 PyTorch에서 텐서에 새로운 차원(길이 1인 축)을 추가하는 함수입니다.예를 들어, quantized_f0의 shape이 (1703,)라면, quantized_f0.unsq
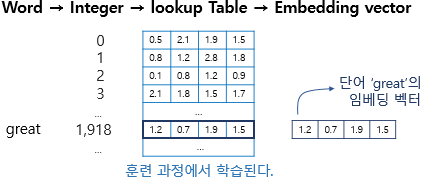
nn.Embedding이란
동기 내가 아는 embedding의 개념은 자연어 혹은 entity들을 사용자가 원하는 의미적 유사도대로 임베딩 space에 수치화 해서 배치하는것으로 알고 있다. 근데 자연어인 lyrics를 바로 nn.Embedding에 통과 시키는것이 아닌 Lyrics가 이미 v

왜 nn.Embedding을 하면 transpose를 하는걸까?
lyrics encoder과 melodyU encoder를 Summation한 뒤의 shape는 (1, 192, 1) - (b, h, time(seq_len))이다. 요녀석들은 enhanced condition encoder에서 다시 FFT 연산을 하는데 동일하게 nn


Mean pooling - 임베딩 차원 맞춰보자이
문제 Lyrics와 quantized f0된 melody를 FFT encoding을 하면 [batch size, hidden channel, time(seq_len)-> 시퀀스 Length]가 나온다. sequence length가 다를 수도 있지 않누?? 해결 m

파이썬 getter -> __getitem__이란?
getitem은 파이썬에서 객체가 인덱싱(obj[key]) 또는 슬라이싱(obj[start:stop])될 때 호출되는 메서드입니다. 이 메서드를 클래스 안에 정의하면, 해당 클래스의 인스턴스를 리스트나 딕셔너리처럼 사용할 수 있습니다. 📌 기본 사용법 🎯 주요 특징 obj[key]가 호출되면 obj.getitem(key)가 자동으로 호출됩니다....

중첩된 여러 자료구조의 Element에 Func mapping하는법
nest_map을 만드세유https://dotiromoook.tistory.com/28

Stack -> Min value구하기
arr 2개stackmin_stackstack은 그대로 구현min_stack은 stack이 반복될때마다 계속 반복적으로 최소값을 각각의 idx로 할당top이라는 Int idx를 Cursor로 활용해서 stack을 구현홀수번째 Idx는 stack짝수번째 idx는 min_
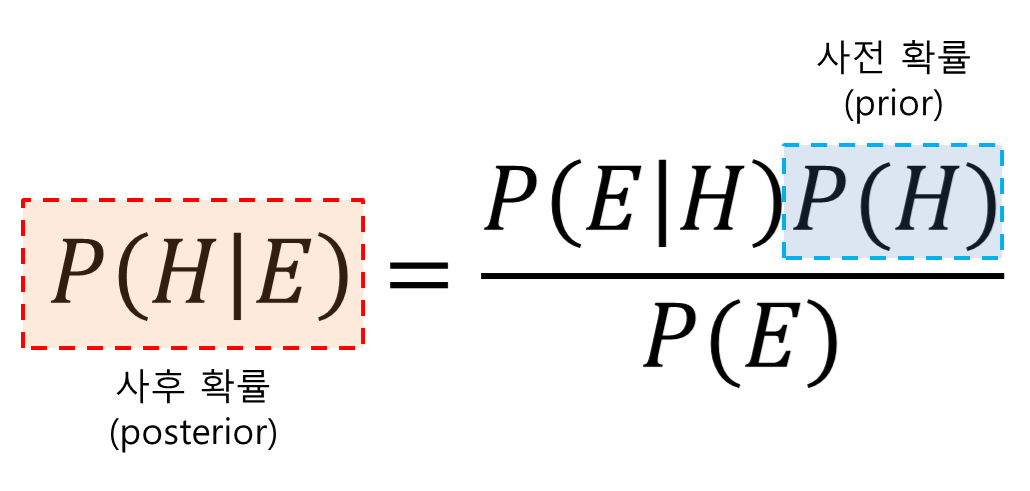
베이즈 정리의 해석
필자의 해석이므로 틀린부분이 있다면 지적해주세요!베이지안 관점의 확률: 기존의 evidence(이미 일어난 단서들, 확률로 표현)와 hypothesis()를 기반으로 미래의 '가능성', 즉 미래의 불확실성을 예측하는 개념이다. (귀납)\-> 기존: 특정 사건들에 대한

기댓값 vs 평균, 왜 llm paper에서는 기댓값을 사용할까?
기댓값: 미래를 예측하기 위해서 확률들을 기반으로 구한값, 미래 가능한 결과에 대한 예측값(귀납-경험/관찰/증거에 기반한 미래 예측 판단)평균: 빈도주의 관점으로 기존 데이터들을 가지고 구한값, 이미 관측된 데이터를 가지고 확실한 값(연역-이미 알고있는 데이터 가지고


모델이 학습한다는 의미
아직 처음 배운거라 오류가 있다면 알려주세용모델의 가중치값을 조정해나아가는 일련의 과정모델의 단어들의 관계나 문장의 의미를 백터로 변환하는 "방법"을 배운 상태

베이즈정리
베이즈 정리는 사건이 발생한 후에 원인을 추론하는 데 사용하는 확률 법칙입니다. 새로운 데이터가 주어질때 모델이 확률을 업데이트 하는 과정에서 사용

문제에서 A와 B가 종속적이라는 정보만 있고, 교집합 확률이나 조건부 확률이 주어지지 않았다면
LLM시대이전 내가 고등학교에서 의문을 품었지만 질문을 구체화하지 못해서 미궁으로 빠졌었다. 문제에서 교집합 확률이나 조건부확률을 주지 않았고, 문제에서 A와 B가 종속적이라는 정보만 있고 조건부 확률도 직접 주어지지 않았다면 어떻게 해야하지?