
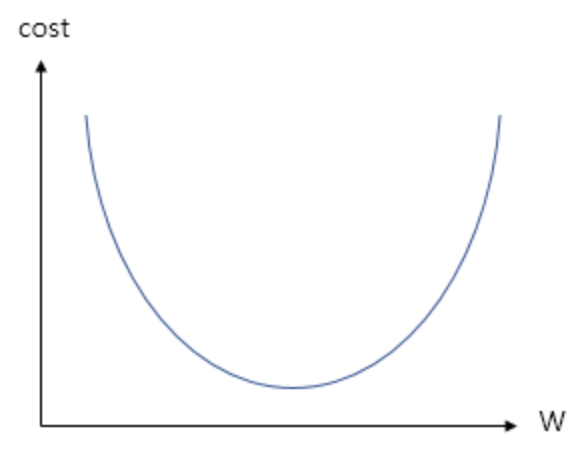
[DL] 경사 하강법(Gradient Descent)
인공신경망은 손실 함수를 통해 자신의 파라미터를 검증한다.특정 파라미터를 통해 나온 손실함수 값이 가장 낮은 곳이 최적의 파라미터이다.경사하강법은 비용 함수를 최소화하는 매개변수를 찾기 위해 사용되는 알고리즘이다.한마디로, 주어진 함수에서 극소점을 찾기 위해 기울기(g
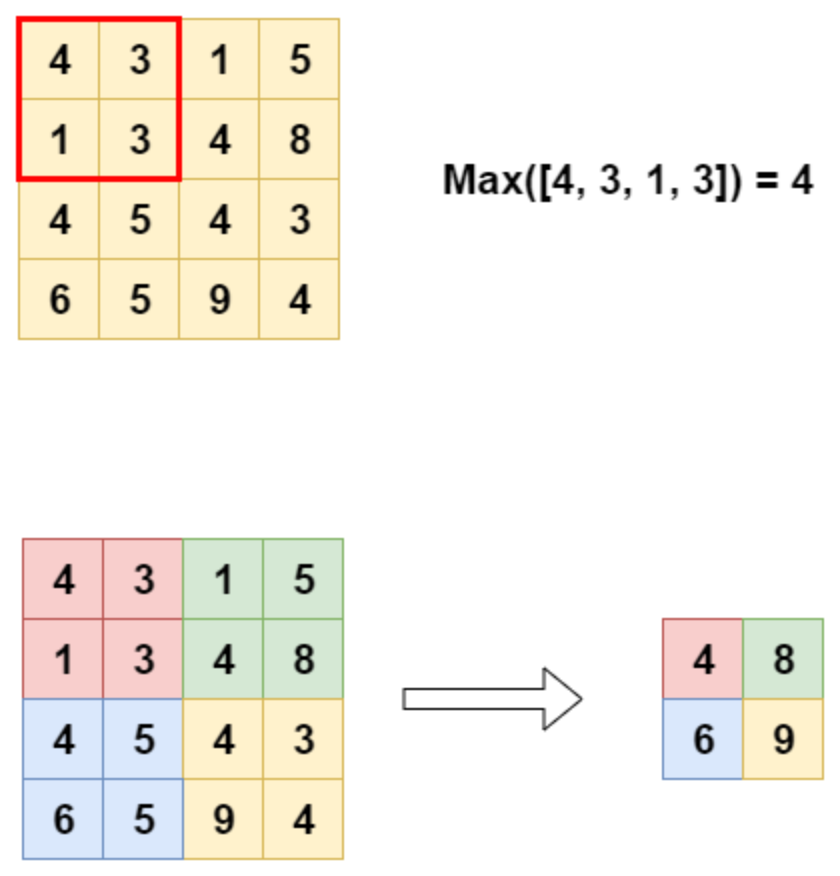
[DL] 풀링 계층 (Pooling Layer) 종류 (작성중)
CNN의 Layer 유형 3가지Convolution LayerPooling LayerFully Connected LayerStride는 입력 이미지에서 필터를 몇 칸 씩 건너 뛰며 적용할지를 의미.Stride = 1, 한칸씩 건너뛰며 필터 적용(n,n) 이미지에 대해
[ML] 머신러닝에서의 다중공선성 문제 (작성중)
다중공선성 문제 독립 변수 간 상관관계가 매우 높을 때, 하나의 독립변수의 변화가 다른 독립변수에 영향을 미쳐 모델이 불안정해지는 것을 의미한다. Reference https://velog.io/@jkl133/%EB%8B%A4%EC%A4%91%EA%B3%B5%EC%8
[DL] 과적합(Overfitting)과 해결법
신경망이 훈련 데이터에만 지나치게 적응되어, 그 외 데이터에는 제대로 대응하지 못하는 상태.이는 모델이 훈련 데이터의 노이즈까지 학습하여 발생한다.모델은 데이터의 양이 적을 경우, 데이터의 특정 패턴, 노이즈까지 쉽게 암기하기 때문에 과적합이 발생할 확률이 높다.데이터
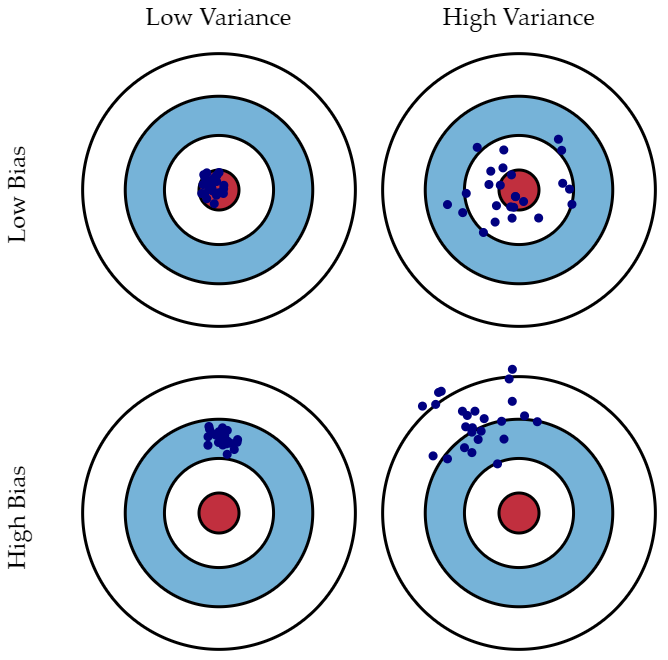
Bias(편향) - Variance(분산) Trade-Off
Bias-Variance trade-off 란, 모델링 할 때 error 처리를 위해 중요하게 알아야하는 개념이며, 자주 헷갈릴 수 있다.편향은 예측값과 실제값의 차이다.편향이 크다는 것은 예측값-실제값 차이가 크다는 것이는 "과소적합"을 의미한다.분산은 입력에 따른

[ML] Feature Selection
Feature selection은 모델링 시 raw data의 모든 feature를 사용하는 것은 computing power와 memory 측면에서 매우 비효율적이기 때문에일부 필요한 feature만 선택하는 방법ㅣ다.유사하지만 다른 표현의 3가지 feature 처리
[ML] 주성분 분석(PCA)에 대한 이해
1. 차원 축소 밑의 데이터는 외출 활동이 좋은지 아닌지 분류하는 모델을 만들고자 할때, 날씨 데이터의 Feature가 101가지로 들어온 데이터다. 이는 101차원의 데이터와 같은 의미다. 
[논문 리뷰] Spectral images based sound classification using CNN with meaningful data augmentation (2020)
많은 오디오 녹음에는 배경 소음, 매우 짧은 간격 및 클립의 급격한 변화가 있기 때문에, 짧은 audio clips을 통해 특징을 추출하고 다양한 소리를 분류하는 것은 쉽지 않다. possibility of overfitting의 위험을 피하기 위해 training
[Python] predict vs predict_proba 차이
predict() 메소드는 범주를 예측하여 반환하고,predict_praba() 메소드는 확률(probability)을 반환합니다.
[논문] 딥러닝 논문 TIP
awesome-deep-learning-papers2012년부터 2016년까지 발표된 논문 중 다양한 연구에 활용할 수 있는 획기적인 딥러닝 논문 100편을 정리한 깃허브 레포지토리입니다.링크텍스트Papers You Must Read (PYMR)고려대학교 DSBA 연구

파이토치(PyTorch) 한번에 끝내기 : (2) Autograd(자동 미분)
본 포스트는 이수안컴퓨터연구소님의 파이토치 한번에 끝내기 PyTorch Full Tutorial Course 강의를 듣고 작성되었습니다.torch.autograd 패키지는 Tensor의 모든 연산에 대해 자동 미분 제공이는 코드를 어떻게 작성하여 실행하느냐에 따라 역전

파이토치(PyTorch) 한번에 끝내기 : (1) 텐서(Tensors)
본 포스트는 이수안컴퓨터연구소님의 파이토치 한번에 끝내기 PyTorch Full Tutorial Course 강의를 듣고 작성되었습니다. 파이토치(Pytorch) >- 페이스북이 초기 루아(Lua) 언어로 개발된 토치(Torch)를 파이썬 버전으로 개발하여 2017년
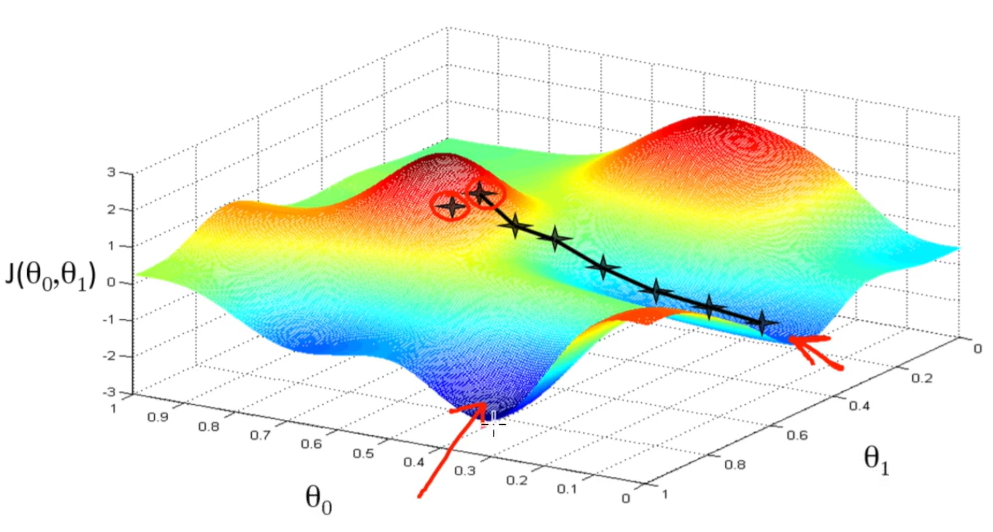
[DL] 딥러닝 구조와 개념
이 글은 딥러닝 호형님의 딥러닝 전체 흐름보기 강의를 바탕으로 작성되었습니다.지도 학습 (supervised learning)비지도 학습 (Unsupervised learning)강화학습 (Reinforcement learning)문제 이해/Data 처리학습 데이터 생
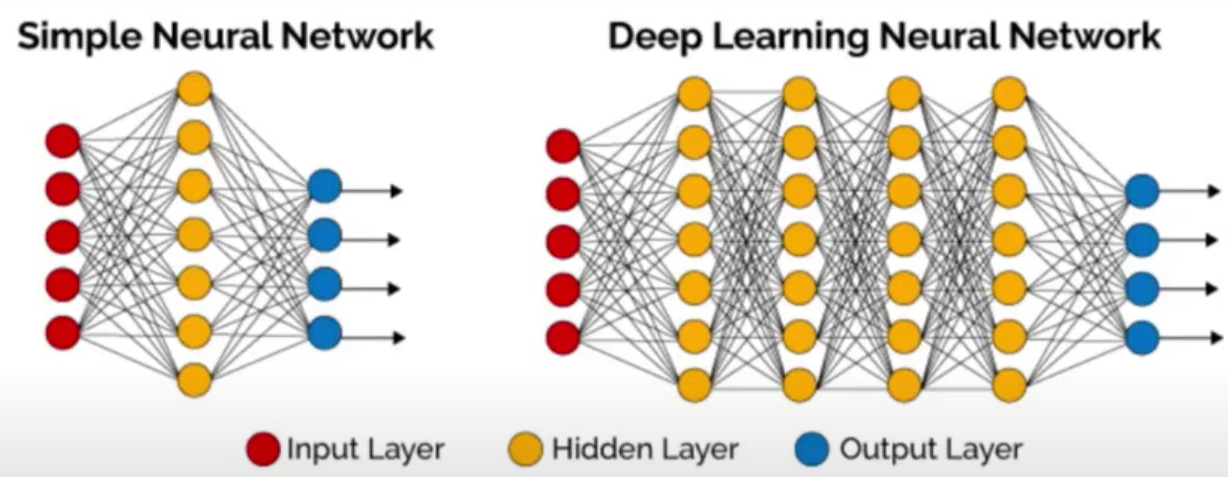
[DL] 딥러닝 신경망 알고리즘 이해하기
이 글은 데이터 스테이션님의 딥러닝 신경망 알고리즘 이해하기 ! 강의를 듣고 작성되었습니다. 1. 신경망 알고리즘 layer (층) : 노드 한줄 Node (노드) Weight (가중치) 비정형(저차원) 데이터를 처리할때 쓰임 2. 신경망 알고리즘 기본 작동 원
[interview] 통계 및 수학
고유값(eigen value)와 고유벡터(eigen vector)에 대해 설명해주세요. 그리고 왜 중요할까요?샘플링(Sampling)과 리샘플링(Resampling)에 대해 설명해주세요. 리샘플링은 무슨 장점이 있을까요?확률 모형과 확률 변수는 무엇일까요?누적 분포 함
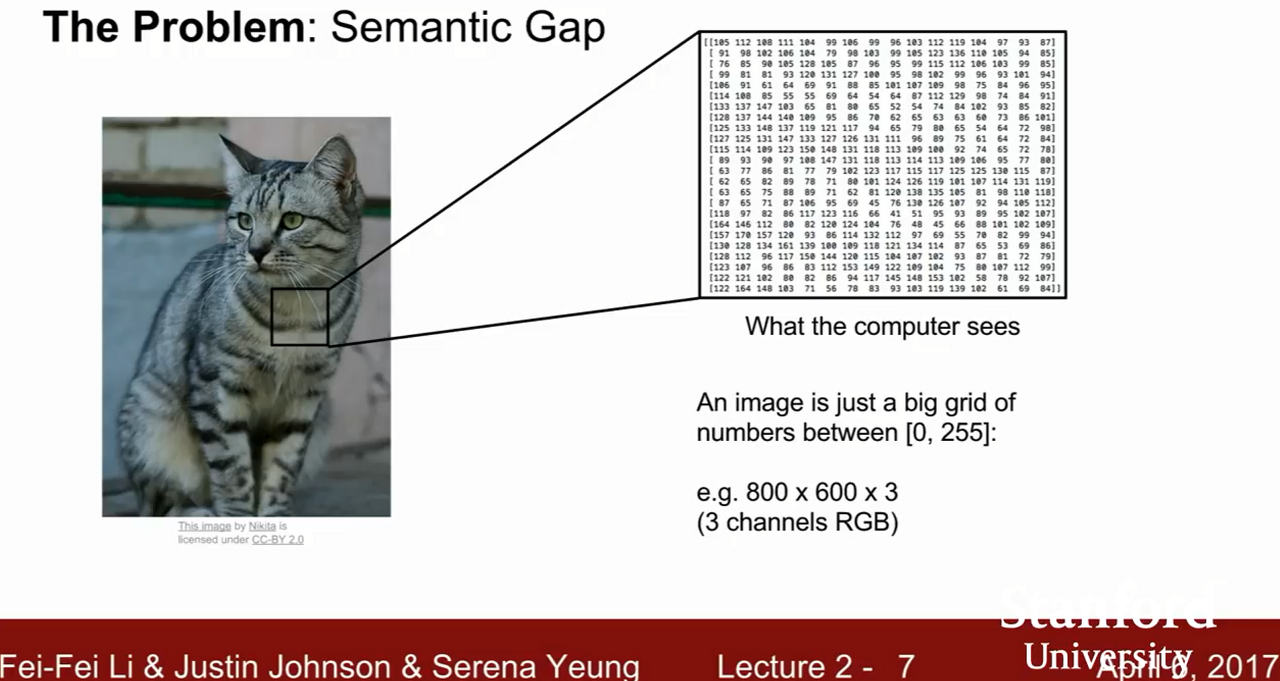
[CS231N] Lecture 02 : Image Classificaion pipeline
데이터 중심 접근 방법 (Data-Driven Approach)Nearest Neighbor (NN)K-Nearest NeighborsLinear Classification (선형 분류)이미지를 분류하는 것이미지가 입력되면 시스템에서 미리 label해놓은 분류된 이미지
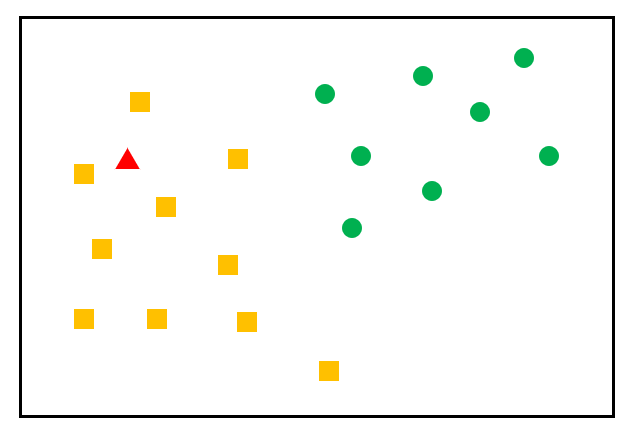
[ML] K-NN (K-최근접 이웃)알고리즘
K-최근접 이웃 (K-NN, K-Nearest Neighbot) 알고리즘분류 (Classification)지도학습비슷한 특성을 가진 데이터는 비슷한 범주에 속하는 경향이 있다는 가정주변의 가장 가까운 K개의 데이터를 보고 데이터가 속할 그룹을 판단하는 알고리즘가장 가까
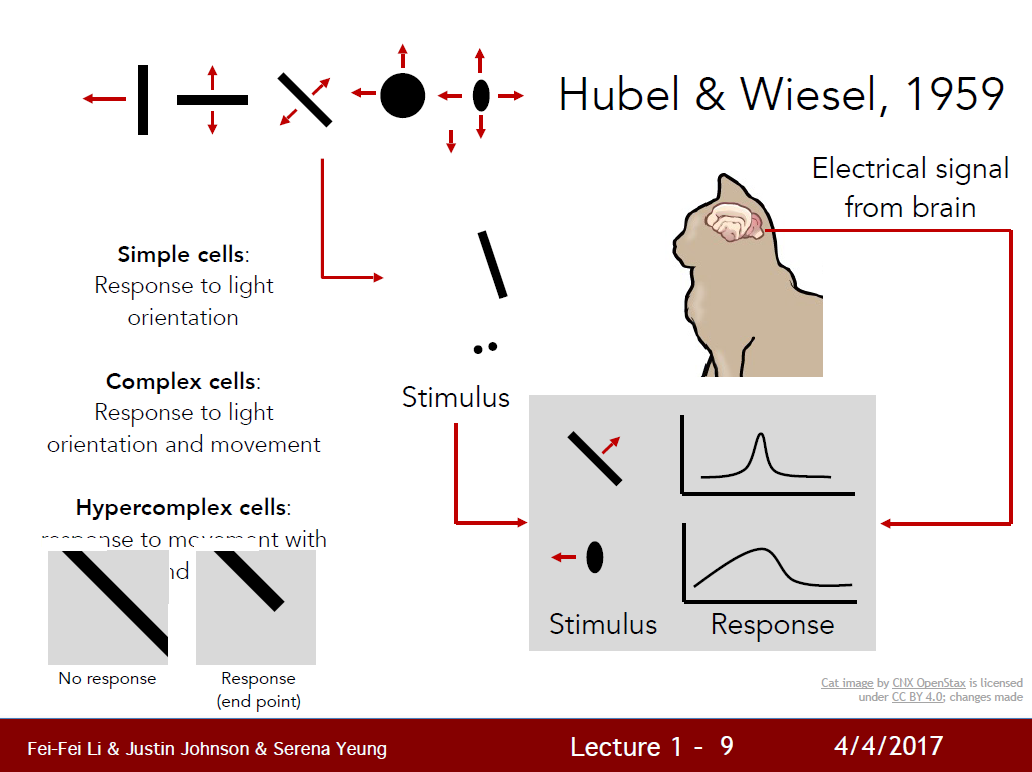
[CS231N] Lecture 01 : Introduction and Historical Context
컴퓨터 과학의 연구 분야 중 인간이 시각적으로 하는 일들을 대행하도록 시스템을 만드는 것.2015년부터 2017년까지 CSICO에서 발표한 통계자료에 따르면 인터넷 트래픽 중 80%는 인터넷 비디오데이터였다.인터넷의 데이터 대부분이 시각적인 자료였다. 이러한 시각적 자
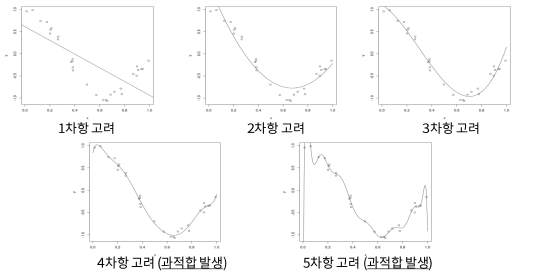
[ML] 과적합(Overfitting)과 규제(Regularization)
\-모델이 train 데이터에 지나치게 적응되어 그 외 데이터에는 대응하지 못하는 상태.EX) 아래와 같은 회귀 문제에서, 두번째 모델이 최적의 모델이다1\. 첫번쨰 모델 : 과소적합(Underfitting), 주어진 데이터를 아직 제대로 반영하지 못함.2\. 두번쨰
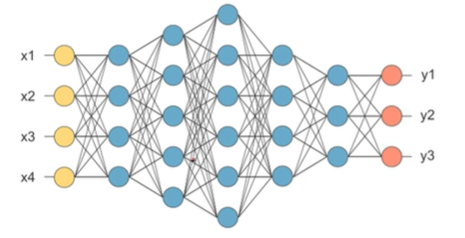
[DL] 딥러닝 주요 모델
입력,은닉,출력층으로 구성된 모형각 층을 연결하는 노드의 가중치를 업데이터하며 학습overfitting이 심하게 일어나고, 학습 시간이 매우 오래 걸림다층의 layer 통해 복잡한 데이터 학습이 가능토록 함알고리즘 및 GPU의 발전이 deep learning의 부흥을