

Multi-GPU 정리
Multi-GPU 사용하기 위해 정리한 글입니다. 1. Data Parallel (DP) 사용방법: nn.DataParalell 현재 거의 사용하지 않은 방식 문제점 파이토치의 데이터 병렬화 작업때문에 하나의 GPU에 VRAM이 과하게 사용됨 하나의 G
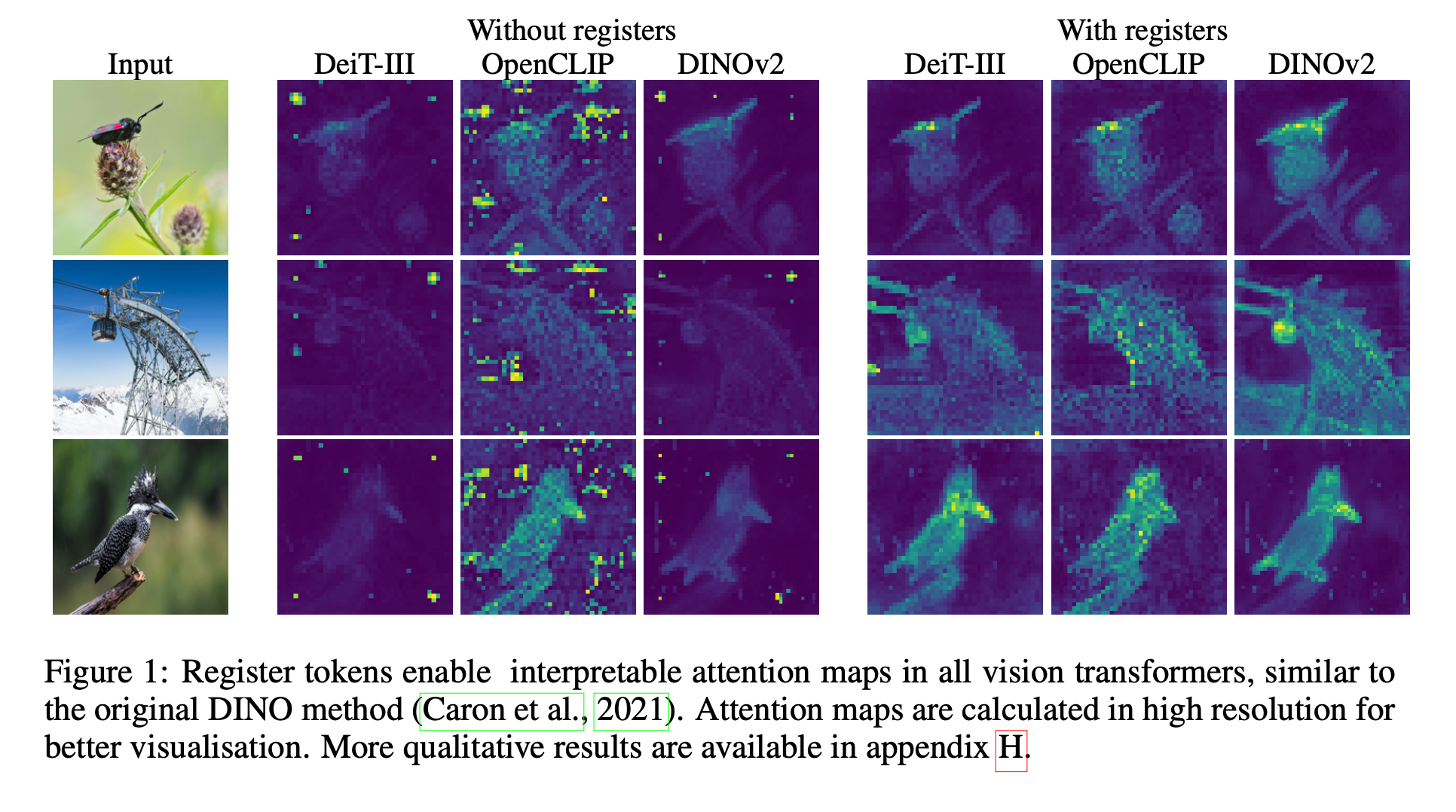
[논문 리뷰] Vision Transformers Need Registers
이 글은 ICLR 2024에 게재된 "Vision Transformer Need Registers"을 리뷰하기 위한 글입니다. 이 논문에서는 Supervised and self-supervised ViT networks의 feature map에 있는 artifacts을
RLHF
이 글은 RHLF를 공부하기 위한 정리 노트입니다. Reference link: https://ebbnflow.tistory.com/382 Referecne paper: Direct Preference Optimization: Your Language Model is
[논문]Dynamic Routing Between Capsules
Object Recognition 기존의 object recognition에는 Convolution Network를 사용하였다. Feature Extracting + max pooling Object Segmentation 기존 CNN의 Maxpooling과정의
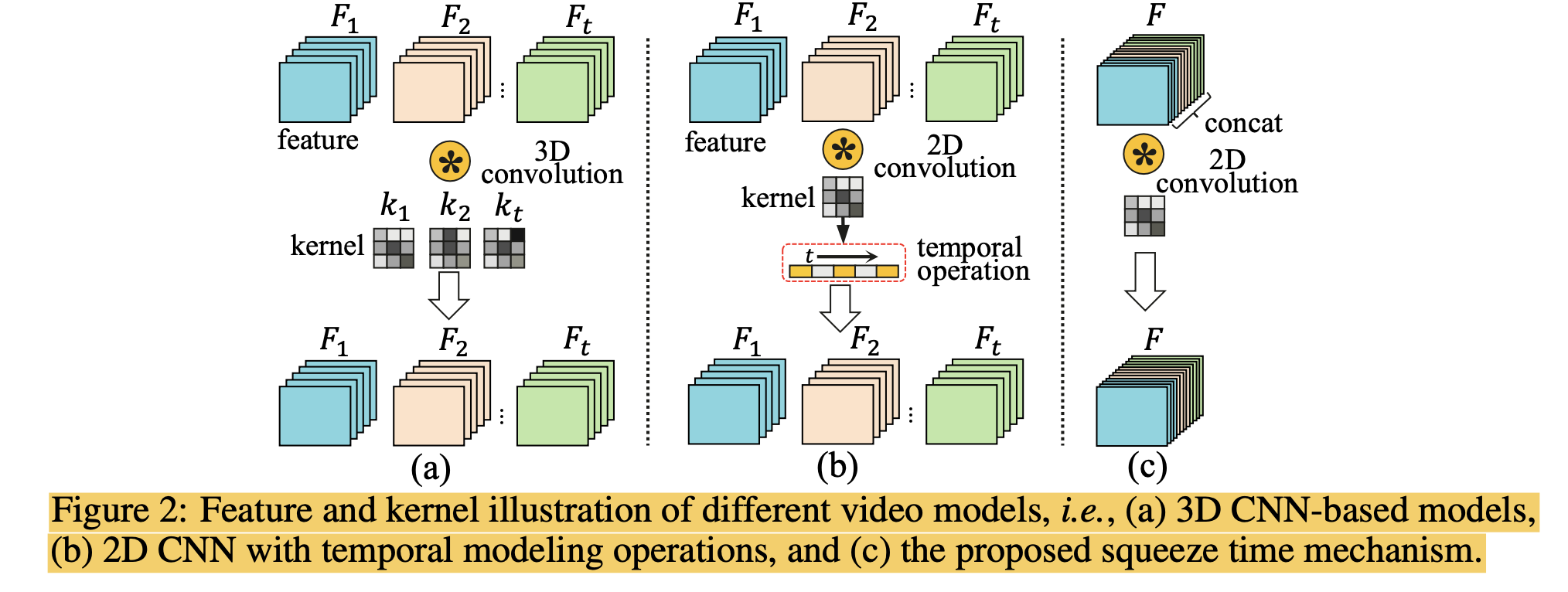
No Time to Waste: Squeeze Time into Channel for Mobile Video Understanding
이 글은 논문 "No Time to Waste: Squeeze Time into Channel for Mobile Video Understanding"에 대한 리뷰글입니다. 최근 video understanding methods는 3D blocks나 2D convolu
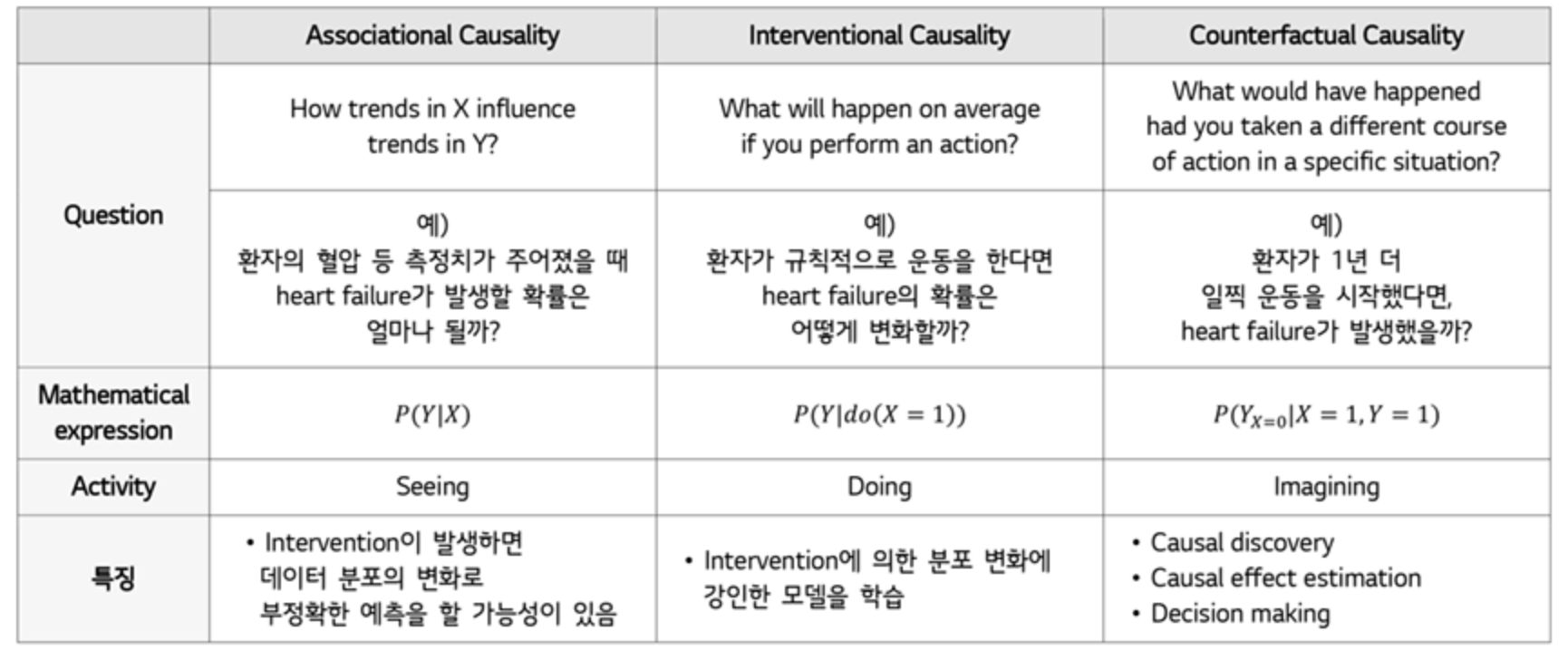
Casual Representation Learning
혼자 공부하려고 정리하는 글입니다.Main ref: https://www.lgresearch.ai/blog/view?seq=306Sub ref: https://lhw0772.medium.com/study-da-domain-adaptation-%EC%9
Batch Normalization
CMU - IntroDL 수업에서 Batch Normalization 수업 자료 정리입니다. 참고: https://gaussian37.github.io/dl-concept-batchnorm/ Gradient Descent 손실 함수에 대해서 미분값이 최소가 되는 점을 찾아 weight을 찾는 과정 Step size = Learning rate 일반적인...

Meta-Learning?
이 글은 메타러닝을 학습하기 위한 정리 글입니다. 참고 자료 https://manywisdom-career.tistory.com/73https://huidea.tistory.com/252https://www.alsemy.com/post/sut
[논문 리뷰] What Makes Training Multi-modal Classification Networks Hard?
이 글은 2020년 CVPR에 게재된 "What Makes Training Multi-Modal Classification Networks Hard?" 논문에 대한 리뷰입니다. Background Why Multimodal?? Uni-Modal Model (Visi
[논문 리뷰] Towards Casual VQA: Revealing and Reducing Spurious Correlations by Invariant and Covariant Semantic Editing
들어가기 전에 이 글은 2020년 CVPR에 게재된 "Towards Casual VQA: Revealing and Reducing Spurious Correlations by Invariant and Covariant Semantic Editing" 논문 리뷰입니다.

[논문 리뷰] Self-supervised Learning from a Multi-view Perspective
들어가기 전에이 글은 2021년 ICLR에 게재된 "SELF-SUPERVISED LEARNING FROM A MULTI-VIEW PERSPECTIVE" by Yao-Hung Hubert Tsai, Yue Wu, Ruslan Salakhutdinov, and Louis-