
- 전체보기(12)
- python(4)
- ML/DL(3)
- 논문리뷰(2)
- 데이터최적화(2)
- labeling(1)
- Vectorization(1)
- Statistics(1)
- 논문 리뷰(1)
[Paper Review] LightGBM : A Highly Efficient Gradient Boosting Decision Tree
Find-A에서 프로젝트 팀으로 데이터 분석팀 팀장을 하게 되었는데, 그 덕에 가끔씩 정규세션에 참여하여 관련해서 발표를 진행하게 되었다. 발표 주제를 LightGBM으로 정했는데, 많이 쓰는 모델이면서도 정확하게 어떻게 알고리즘이 동작하는지 알고 쓰는 사람이 많지는
Type Casting을 활용한 최적화(feat.대용량 데이터)
직전 포스팅에 이어, 데이터를 보다 효율적으로 다룰 수 있는 또 다른 방법을 알아보자. int와 float을 활용한 최적화이다.int(정수형)와 float(부동 소수점) 데이터 타입은 여러 종류가 있고, 각각 메모리 크기와 표현할 수 있는 값의 범위는 다르다.예를 들어

Vectorization을 활용한 최적화(feat.대용량 데이터)
인턴 시절 145만개 정도 되는 공정 데이터를 분석해야 하는 상황이 있었다. 당시 여러 공정 장비를 활용해서 파생변수를 만들어야 했는데, 데이터가 꽤 많다보니 시간이 상당히 걸렸었다. 그 때 데이터 전처리 시 최적화 기법을 찾아봤었고, 그 중 vectorization을
가설검정 총체적 정리(p-value만 따질게 아니다)
가설검정을 전체적으로 정리해보자 통계적 가설검정(Stastical hypothesis)은 항상 오류를 수반한다. 때문에 가설의 기각/채택 여부를 확률적으로 접근할 수 밖에 없다. 일반적으로 가설검정을 위한 실험 설계 시 귀무가설과 대립가설을 둔다. H0 : nega
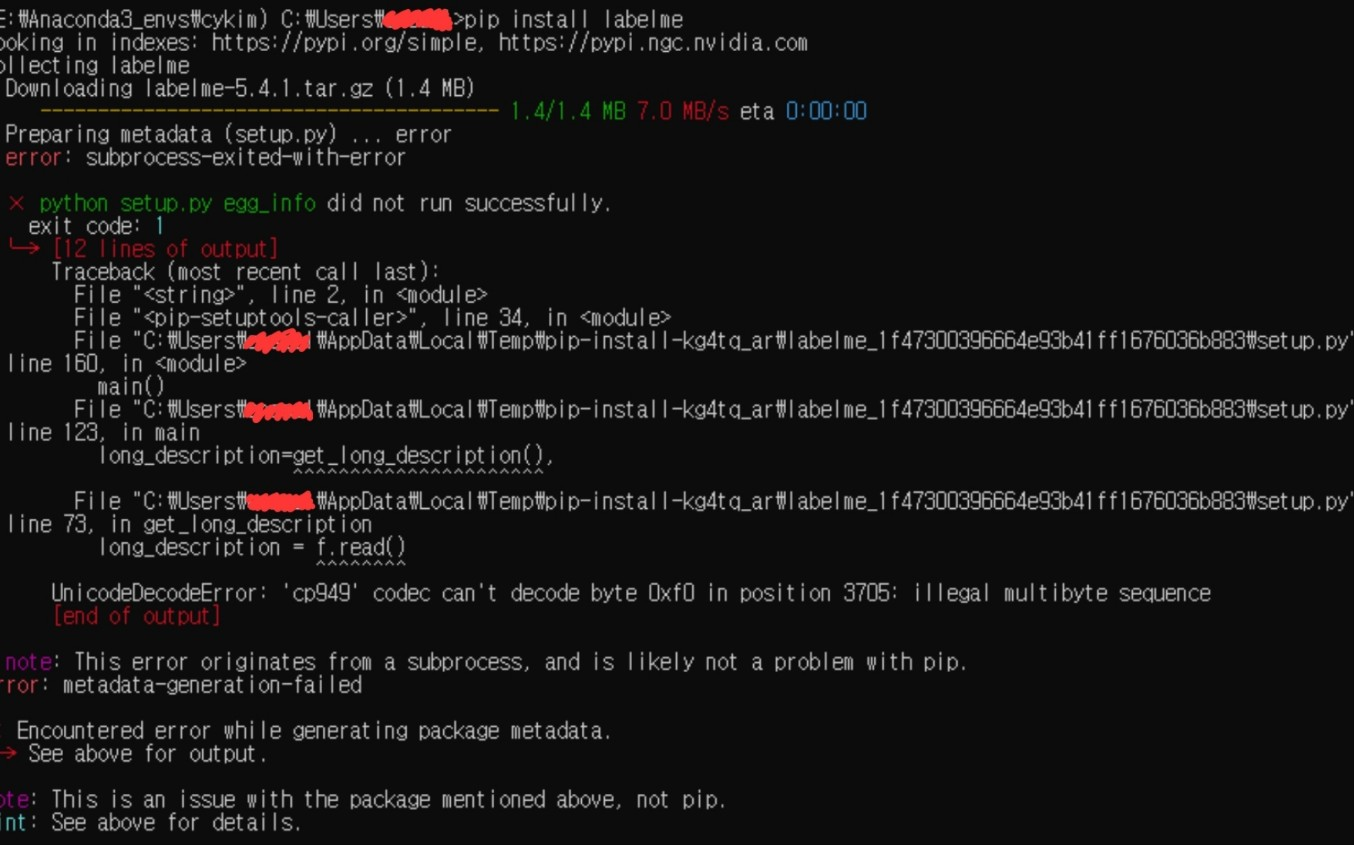
Labelme 설치
회사에서 OCR 모델을 구축하게 되었다. PaddleOCR의 text recognizer를 fine-tuning하기 위해 text detection과정을 거치는 도중, annotation 방법을 공유하고자 포스팅하게 되었다.처음에는 roboflow를 활용했지만,,, a
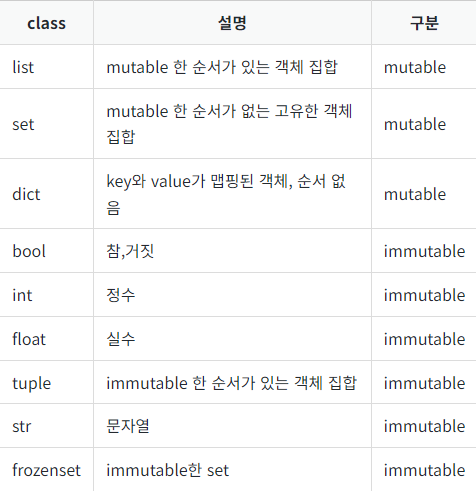
Mutable과 Immutable, 알아야 하는 이유
파이썬의 객체는 크게 두 가지 종류로 나눌 수 있다.mutable(값이 변하는 객체)와 immutable(값이 변하지 않는 객체)이다. 이를테면 list, dict 등은 특정 값을 넣고 빼고 할 수 있으므로 mutable하다고 할 수 있지만, str이나 tuple과 같
참조(Reference)와 얕은 복사(Shallow copy), 깊은 복사(Deep copy)
데이터 전처리, 분석, 모델링 등등 내가 하는 모든 업무에 파이썬을 빼고 살 수는 없다. 하지만 종종 "왜 이렇게 뜨지?"라며 의문이 들 때가 있었고, 코드 상의 문제도 있지만 많은 경우 파이썬 자체적인 이해가 필요한 부분이기도 했다. 그 중 하나가 참조의 영역이다.참
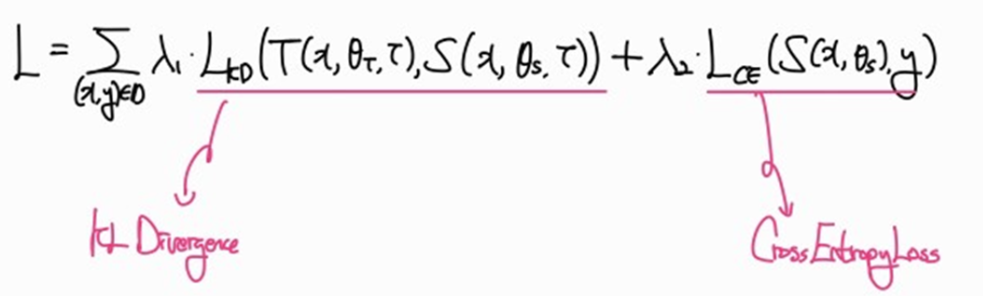
Knowledge Distillation에 대한 고찰(feat. Cross Entropy)
https://arxiv.org/abs/1503.02531Knowledge Distillation(지식증류)를 활용해서 모델 경량화를 진행하던 도중 한 가지 의문이 발생했고 한번 수식을 파고 들어봤다. 까먹기전에 블로그에 올려놔야겠다.Knowledge Dist
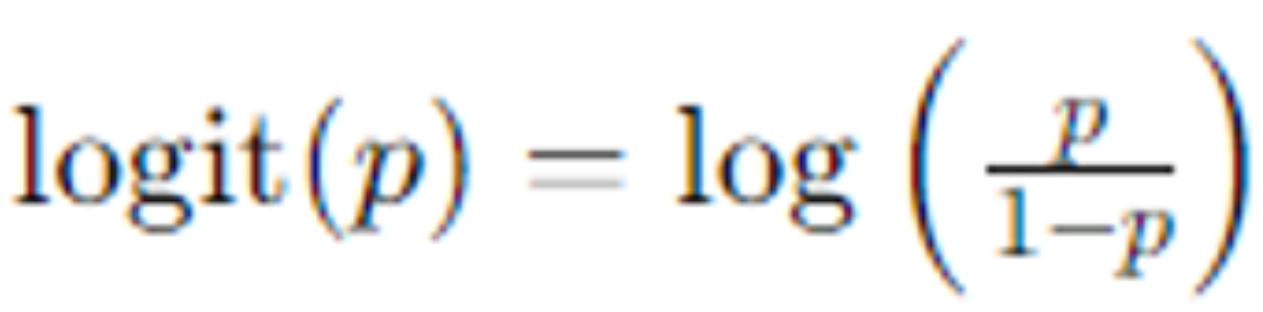
Logit in Deep Neural Network
딥러닝 모델의 출력값은 로짓(logit)이라고 불리는 값으로 결과를 내놓는다. 여기서 로짓값은 모델의 마지막 선형 레이어에서 나온 예측값으로, 활성화함수를 거치지 전의 값이라고 생각할 수 있다. 보통 해당 로짓값에 소프트맥스(softmax) 함수를 사용해서 크로스 엔트

[Paper Review] ADAM: A METHOD FOR STOCHASTIC OPTIMIZATION
https://arxiv.org/abs/1412.6980모델링 과정에서 매개변수가 어떻게 학습이 되는지 머릿속으로 그려볼 필요가 있었다. Optimizer의 종류에 따라 손실함수 f의 움직임이 달라진다. 다양한 Optimizer의 중심이라고 할 수 있는 Ada

[Paper Review] TS-Bert: Time series Anomaly Detection via Pre-training Model Bert
https://www.researchgate.net/publication/352321708_TS-Bert_Time_Series_Anomaly_Detection_via_Pre-training_Model_Bert해당 논문은 2021년에 나온 논문으로 트랜스포머 계
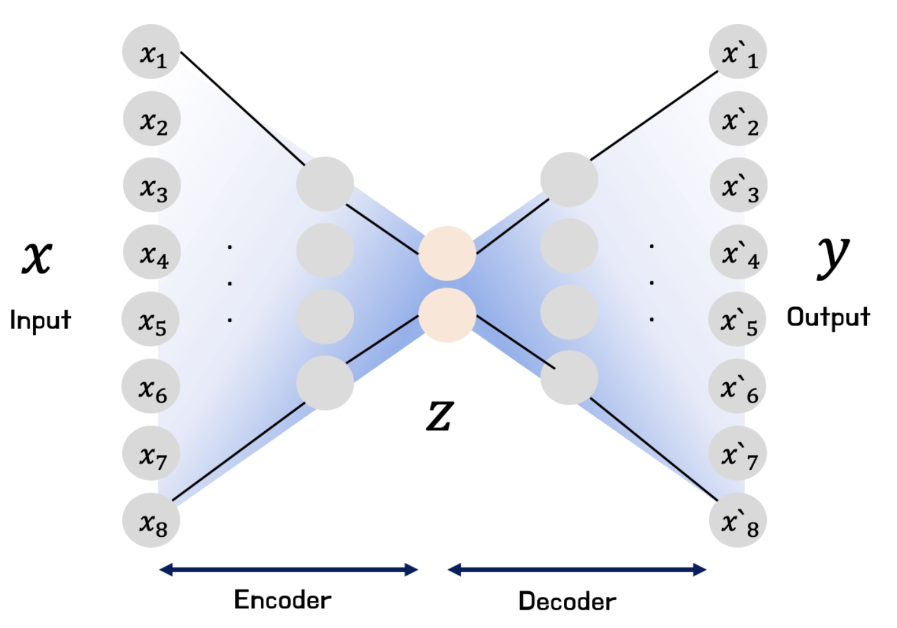
Imbalanced Target with AutoEncoder
신용카드 이상 거래 탐지와 같은 task는 데이터의 불균형 정도가 매우 심하다 (정상 거래 : 이상 거래의 비율이 9 : 1인 경우가 대다수다). Classification task에서 label의 불균형이 존재할 경우 보통 Oversampling과 Undersamp