
- 전체보기(21)
- ML(6)
- spark(3)
- 파이썬머신러닝완벽가이드(3)
- bioinformatics(2)
- Algorithms(1)
- docker(1)

[Docker] Let me like you, Docker : part 1
A python file("hw1.py") runs well on my laptop.But what if it does not on my friend's?➡ ModuleNotFoundError: No Module named 'xgboost'➡ The module isn
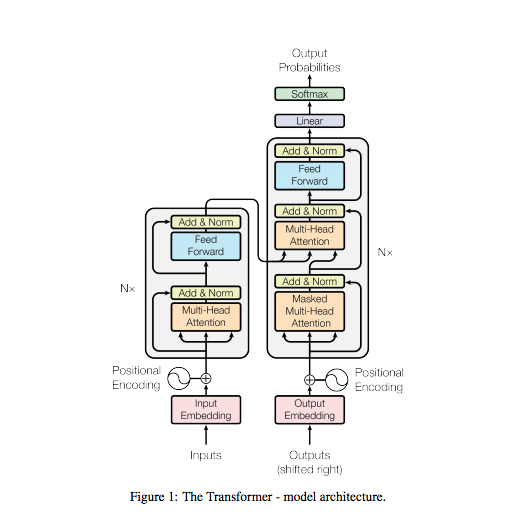
[Paper Review] Attention is all you need
Before RNN LSTM : slow to train Can we parallelize sequential data? Transformers Input sequence can be transmitted **parallel ** No concept of t
[Algorithms] 다익스트라(Dijkstra)
문제 상황Va -> Vb까지의 최단경로Va -> 모든 노드 의 최단경로모든 노드 -> 다른 모든 지점 의 최단 경로그리디 알고리즘으로 분류됨매 상황에서 가장 비용이 적은 노드를 선택해서 임의의 과정을 반복동작 단계출발노드 설정최단거리 테이블 초기화현재 위치한 노드의 인
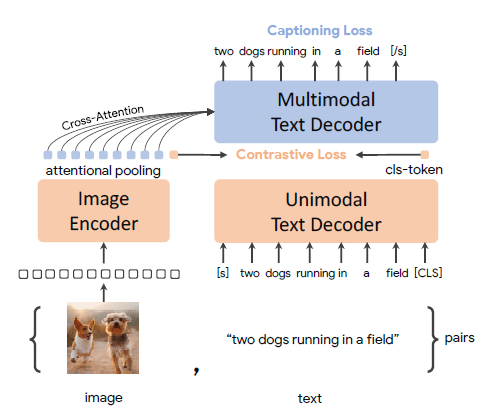
[Paper Review] CoCa: Contrastive Captioners are Image-Text Foundation Models
"CoCa: Contrastive Captioners are Image-Text Foundation Models" History of Vision and Language training Vision pretraining pretrain ConvNets or Tran
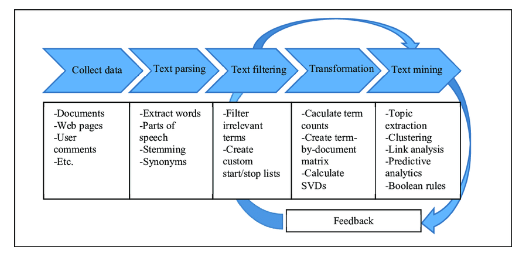
[파이썬 머신러닝 완벽가이드] 8장: Text Analysis
NLP vs 텍스트 분석텍스트 분석 주요 영역 텍스트 분류(어떤 카테고리에 속하나) 감성 분석(텍스트에서 나타나는 주관적인 기분 등의 요소를 분석) 텍스트 요약 텍스트 군집화와 유사도 측정텍스트 문석 머신러닝 수행 프로세스 데이터 사전가공-> Feature
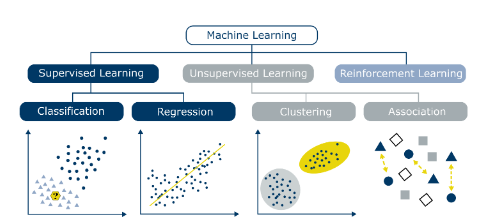
[파이썬 머신러닝 완벽가이드] 5장: Regression
회귀 데이터의 값이 평균과 같은 일정한 값으로 돌아가려는 경향 (아무리 키가 큰 집안의 아이도 무한정 키가 커지지는 x) 회귀: 여러개의 독립변수와 종속변수 간의 상관관계를 모델링하는 기법을 통칭 머신러닝에서 회귀의 핵심: 최적의 회귀 계수를 찾아내는

[Bioinformatics] Presentation: ShRec3D
I gave a 40-minute presentation in the Introduction to Bioinformatics class at the University of Miami. It was reviewing the paper "3D Genome Reconstr
[Bioinformatics] Paper Review: Hi-C
Chromosome conformation capture is a way that enables researchers to observe interactions between loci. These loci are in close contact in the 3-dimne
[파이썬 머신러닝 완벽가이드] 4장ㅣ 분류
쉽고 직관적과적합(overfitting) sol) 트리크기를 사전에 제한각 노드에는피처의 규칙 조건 gini samples: 현 규칙에 해당하는 데이터 건수 value: 클래스 값 기반의 데이터 건수ex) 41,4,10 이면 해당 조건을 만족하는 a품종은 4

[GDSC-ML] Practice: Improve accuracy of ImageNet Classification project
learning_rate: 2e-05, batch size: 16 learning_rate: 0.001, batch size: 256

[ML] Hyperparameter Tuning: Learning rate and Batch size
https://openreview.net/pdf?id=B1Yy1BxCZBatch Sizesmall: converges quickly at the cost of noise in the training processlarge: converges slowly wit
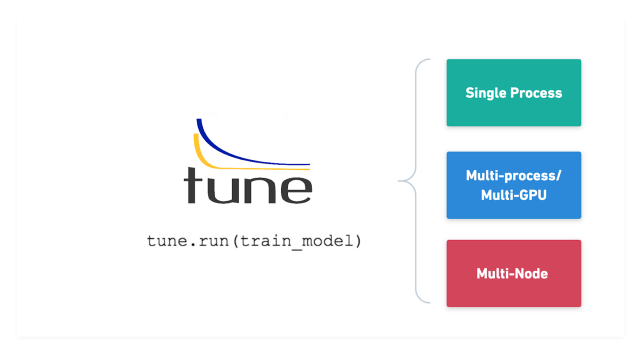
[ML] Various ways for Hyperparameter Tuning in Machine Learning
The process of finding the right combination of hyperparameters to maximize the model performanceRandom SearchGrid SearchEach iteration tries a combin
[Spark] Spark DataFrame / SQL
Spark DataFrame / SQL 목표 정형 데이터를 쉽게 다룰 수 있는 Spark Dataframe, Dataset에 대해 이해한다 Spark DataFrame, DataSet 에 대해 SQL 연산을 수행해본다 Spark SQL 특징 In
[파이썬 머신러닝 완벽가이드] 8장: Text Analysis
NLP vs 텍스트 분석텍스트 분석 주요 영역 텍스트 분류(어떤 카테고리에 속하나) 감성 분석(텍스트에서 나타나는 주관적인 기분 등의 요소를 분석) 텍스트 요약 텍스트 군집화와 유사도 측정텍스트 문석 머신러닝 수행 프로세스 데이터 사전가공-> Feature V
[GDSC-ML] Apply PyTorch template to Mnist classification
The second GDSC-ML session was to convert MNIST CNN project with Jupyter notebook file into Python scripts. Like most people, I was used to do ML pr
[Processing] how to enable auto-complete in Processing
check code completion with CTRL+spacefind "preferences.txt" and change pdex.completion.trigger=trueProcessing version: processing-4.0.1
Spark RDD
RDD: resilient distributed data 스파크에서 in-memory 기반으로 분산환경에서 대용량 데이터를 처리하기 위해 만든 일종의 자료구조 목적: 뷴산 컬랙션의 성질과 장애 내성을 추상화 -> 직관적이고 효율적인 대규모 데이터 셋 처리
[Hadoop & Spark] Hadoop의 map/reduce와 spark의 RDD연산의 차이
Hadoop은 mapreduce 방식으로 데이터를 분산 처리한다. 여러 곳에 분산 저장된 데이터를 처리 하기 위해 mapreduce 방식으로 데이터를 처리한다.spark 역시 mapreduce 방식의 데이터처리 구조를 지원한다. spark도 여러 곳에 저장된 데이터