
특정 Layer의 weight를 고정시키기
tensorf 정리
renderModule에서 nn.Linear의 첫번쨰 intput 같은 경우에는, 2 $\\times$ viewpe $\\times$ 3 + 2 $\\times$ feape $\\times$ P(=27) + 3 + P(=27)의 input channel로 nn.Line
WGAN
1. WGAN WGAN propose to use the Wassertein distance to measure the distance between the two distribution.
Lipshitz Continous Visualization
https://www.desmos.com/calculator/dobs3sfeiv?lang=ko
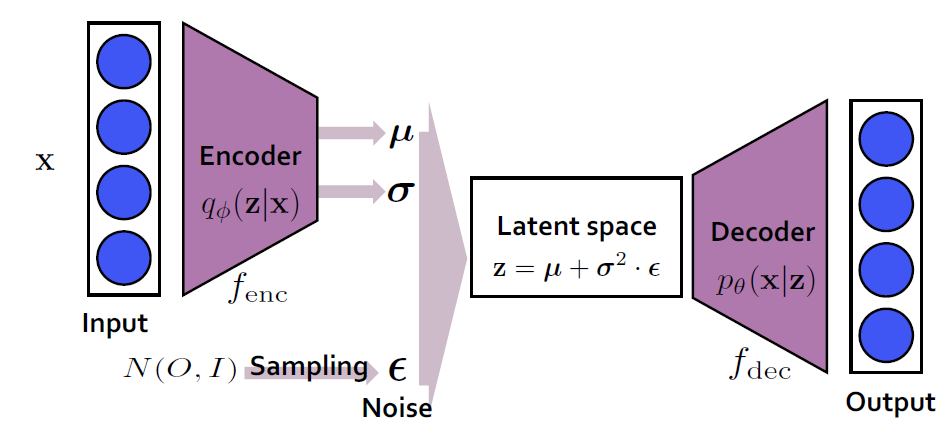
한줄 정리 - VAE
VAE는 image generation 분야에서 GAN 이전시대에 주름 잡던 모델이다.한줄 정리: Encoder를 통해서 input data x를 latent space로 보내고, latent space의 mean과 variance를 구한다. mean과 variance
Markdown 수식 모음
https://ko.wikipedia.org/wiki/%EC%9C%84%ED%82%A4%EB%B0%B1%EA%B3%BC:TeX\_%EB%AC%B8%EB%B2%95이 곳에서 MarkDown 또는 Tex 수식 작성에 필요한 문법을 구할 수 있다.
Stanford CS230 Career Advice
https://youtu.be/733m6qBH-jI정규 강의에서 career advice까지 해주다니... 정말 탑 학교는 다르다고 느낀다...
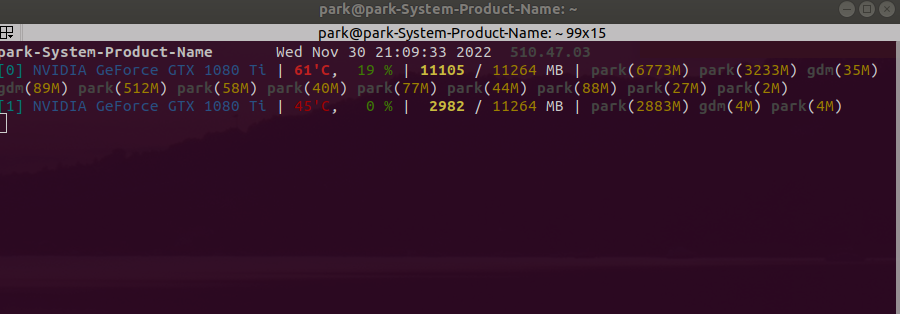
nn.dataparrel 사용시 GPU 몰림 현상
NeRF 코드를 'model = nn.DataParallel(model).to(device)' 를 사용하여 GPU 분산처리를 시도하였다.문제점그러나 다음과 같이 한 GPU에 memory가 쏠리는 문제가 발생하였다.모델에서 weight는 분산되서 사용될 지 몰라도, lo

torch.unsqueeze()와 torch.flatten()의 차이
일반적인 torch array코드결과torch.unsqueeze()코드결과torch.flatten()코드결과

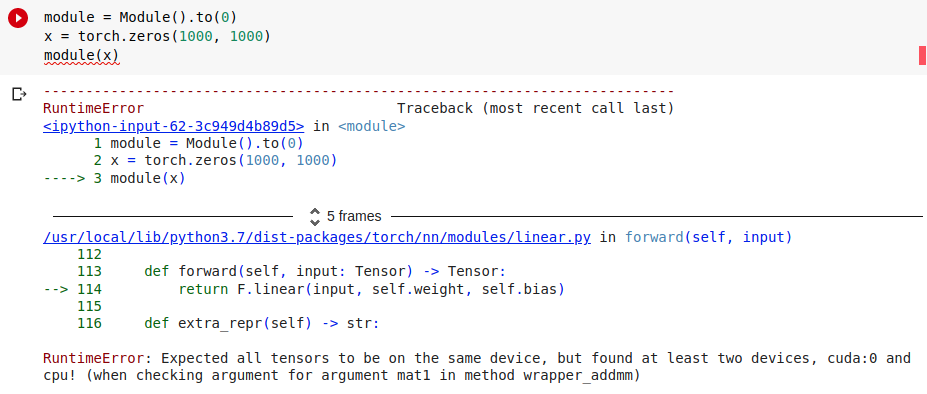
nn.module에서 CPU, GPU 혼합 사용으로 인한 error
다음과 같이 module이 정의될 때, 아래와 같이 연산을 진행해보았다.module에서 to(0)연산을 통해 module의 parameter를 GPU로 보냈지만, x는 여전히 cpu에 남아있기 때문에 'RuntimeError: Expected all tensors to
colab에서 성가신 자동완성 window 끄기
colab에서 코딩을 하다 보면, 다음과 같이 자동완성 창이 보조 설명으로 떠서 위에 있는 코드들을 가린다. 이 창 이름이 뭔지 몰라서 어떻게 검색해야될지 몰랐는데, 그냥 구글에 colab annoying window라고 검색하니까 바로 결과가 바로 나와버렸다..

NeRF Code Review - def raw2outputs
RGBσ의 직접적인 optimization을 진행하는 부분. 이 곳에서 model을 통해 output으로 나오는 RGB 값과 estimation되는 C(r)값, weight값, T_i, volume density값 등, 핵심적인 변수들을 계산한다.
NeRF Code Review - def render_rays
NeRF Code의 run_nerf.py에서 def render_ray 함수 리뷰.
NeRF Code Review - def batchify(fn, chunk)
if chunk is None:chunk가 정해져 있지 않으면, fn을 반환한다. default 값으로 1024\*64가 저장되어 있다.def ret(inputs):return torch.cat(\[fn(inputsi:i+chunk) for i in range(0, i
NeRF Code Review - class NeRF(nn.Module)
코드해석input_pts : rays_o에 해당하는 ray 위치 정보. shape = 1024\*64, 63 아마 60+3(?)input_views : rays_d에 해당하는 ray의 방향 정보 shape = 1024\*64, 27 아마 24+3(?)코드해석self.p
NeRF code review - def get_embedder (작성중)
multires는 encoding되는 frequency의 max frequency를 의미한다.NeRF paper에서 positon 정보(rays_o)가 encoding 될 때는 multires는 L=10, direction 정보(rays_d)가 encoding 될 때는
NeRF Code Review - def train() 내부 ray sampling (작성중)
NerRF pytorch의 ray sampling 함수 코드에 대한 설명입니다.