
3주차 과제 올리브영
Week3. 2주차에 선정한 기업을 기반으로 직무분석, 고객분석 진행하기 의도: SQL?, 파이썬? 언어에 대한 기술역량도 매우 중요하지만 가장 먼저 마인드셋이 되어야 하는 부분은 문제 정의 역량이며 개인 프로젝트 진행 전 간략히 비즈니스의 모델
3주차 과제 패션커머스
Week3. 2주차에 선정한 기업을 기반으로 직무분석, 고객분석 진행하기 의도: SQL?, 파이썬? 언어에 대한 기술역량도 매우 중요하지만 가장 먼저 마인드셋이 되어야 하는 부분은 문제 정의 역량이며 개인 프로젝트 진행 전 간략히 비즈니스의 모델
[프로젝트] 영화 순위 및 장르 분석
아래는 A 영화 회사의 신규 영화 촬영 시기가 다가오고 제작비를 효율적으로 관리하고 수익을 최대화하고 싶어한다. 매출을 극대화할 수 있는 성우를 찾기위해 영화의 순위와 영화에 캐스팅된 성우들에 대한 분석을 진행한 프로젝트이다.여러 개의 csv 파일로 분석을 진행하는 복
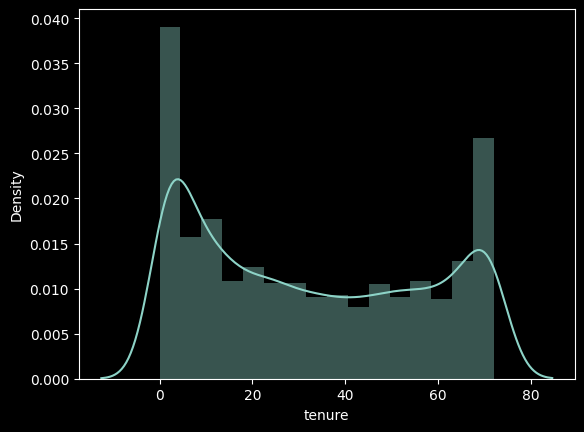
[프로젝트] 통신사 이탈 고객 분석
프로젝트 넷플릭스 사용자 선호 컨텐츠 분석아래는 A 통신사가 다양한 경쟁사가 등장함에 따라 M/S가 떨어지고 있고, 타 통신사로의 이탈률이 높아져가는 상황에서 이탈 가능성이 높은 고객을 분석하는 프로젝트이다.🔖A통신사는 업계 1위의 통신사였으나 그 명성이 무색해져가고
list comprehenssion 2
리스트 컴프리헨션은 파이썬에서 리스트를 간결하게 생성할 수 있는 강력한 문법이다. 특히 if문을 결합하여 특정 조건에 맞는 값만 필터링할 수 있다.0부터 19까지의 리스트 생성:0부터 19까지의 홀수 리스트 생성:리스트 컴프리헨션을 사용한 경우:리스트 컴프리헨션에 if
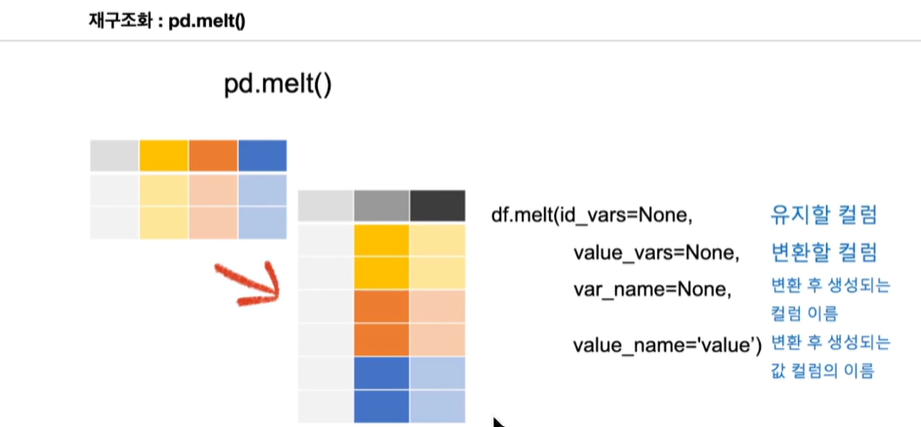
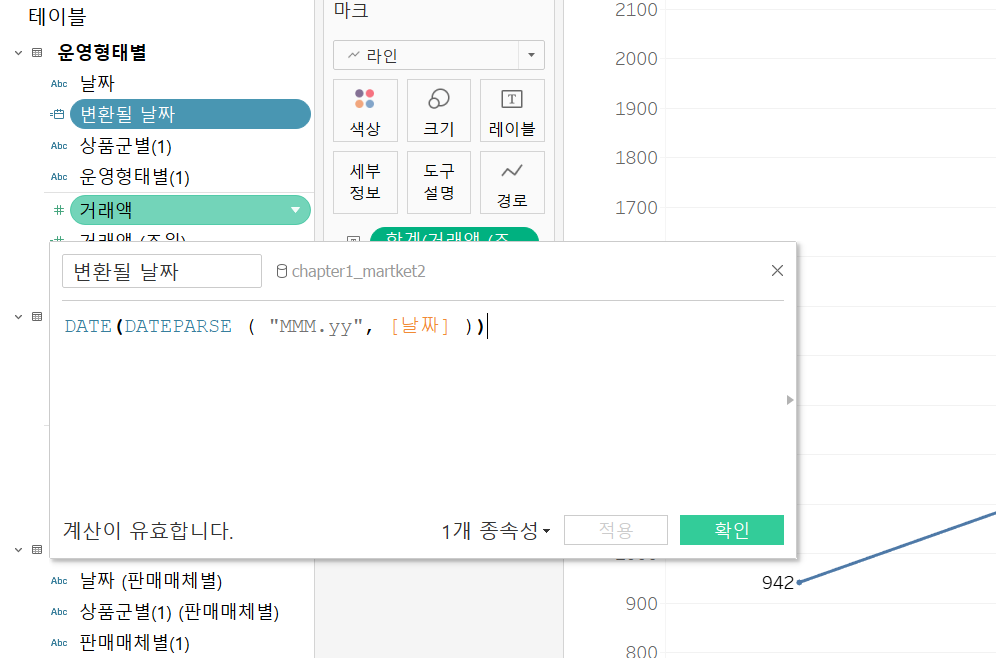
데이터셋 재구조화, pivot table, df.melt
이제부터 파이썬을 사용하여 데이터를 전처리하는 과정을 상세히 설명하겠다. 데이터셋의 문제점을 해결하고 이를 재구조화하는 과정을 단계별로 진행해보자.피벗 테이블을 사용하여 데이터를 요약하고, 멜트(melt) 메서드를 사용하여 데이터를 다시 세로로 긴 형태로 재구조화한다.
[프로젝트] 온라인 화장품 shop 고객분석
아래는 온라인 화장품 shop A사의 판매 전략을 개선하기 위해 고객의 행동 패턴과 선호도를 분석한 프로젝트이다.🔖A사는 온라인 화장품 shop의 판매 전략을 개선하기 위해 고객의 행동 패턴과 선호도를 분석하려 한다.⛳ 문제정의▶ 고객 이해에 대한 정보 부족▶ Q.
Feature selection 기법
피처 셀렉션 기법정의: 변수(피처)가 많아질수록 데이터의 복잡도가 높아지며, 이를 표현하기 위해서는 많은 데이터가 필요하게 되는 현상.문제점: 피처가 많아지면 모델이 오버피팅될 가능성이 높아짐. 트레이닝 데이터에서는 정확도가 높지만 테스트 데이터에서는 성능이 낮아짐.해
Model 평가 및 지표 해석
모델의 성능을 평가하고 비교하는 것은 모델 개발 과정에서 매우 중요하다. 여기서는 다양한 평가 지표와 그 해석 방법을 설명한다.정의: R-제곱 값은 모델이 종속 변수의 변동성을 얼마나 설명하는지를 나타낸다.범위: 0부터 1까지. 1에 가까울수록 모델이 데이터를 잘 설명
계수(β) 추정법
선형 회귀 모델은 종속 변수(y)가 독립 변수(x)들의 선형 결합으로 표현되는 모델이다.모델의 일반적인 형태는 다음과 같다:y = β0 + β1 \* x1 + β2 \* x2 + ... + βn \* xn + ey는 종속 변수x1, x2, ..., xn은 독립 변수들\
Linear regression, loss function
데이터 분석을 시작하기 전에, 데이터의 종류를 이해하는 것이 중요하다. 데이터는 크게 두 가지로 나눌 수 있다: '정형 데이터: 엑셀에서 볼 수 있는 테이블형 데이터로, 일반적으로 행과 열로 구성되어 있다. 이 데이터를 N x P 매트릭스라고도 부른다.N: 데이터의 개
[프로젝트] 넷플릭스 사용자 선호 컨텐츠 분석
아래는 2008~2021년 의 기간 동안 수집한 넷플리스의 메타데이터를 분석해 A회사가 컨텐츠 제작 및 구매 전략을 만들기 위해 사용자의 선호도와 시청패턴에 대해 이해하고 인사이트를 도출하기 위한 데이터 분석 프로젝트이다.🔖A사는 넷플릭스 플랫폼에서 제공하는 컨텐츠에
[머신러닝] : 선형대수학
선형대수학은 선형 연산을 다루는 수학 분야로, 선형대수학은 기초적으로는 연립방정식을 풀고, 행렬과 벡터의 연산을 다루는 것을 포함한다.선형대수학은 머신러닝, 딥러닝, 그리고 검색 엔진 알고리즘 등 현대 인공지능 기술의 기초가 된다. 그리고 선형대수학은 인공지능 알고리즘
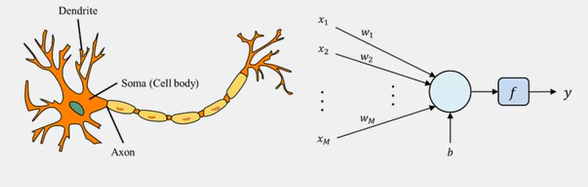
[머신러닝] : 인공지능, 인공신경망
인공신경망(ANN): 실제 신경망을 모사한 것으로, 인공지능의 한 종류이다. 실제 신경망을 "뉴럴 네트워크"라고 부르며, 앞에 "아티피셜"을 붙여서 "인공신경망"이라고 한다. 실제 신경망은 다음과 같이 구성되어 있으며 인공신경망은 아래의 구성요소들을 수학적으로 묘사하는
[머신러닝] : 머신러닝이란?
머신러닝은 명시적으로 프로그래밍하지 않고 컴퓨터가 스스로 규칙을 학습하는 연구 분야이다. 이 개념을 이해하기 위해 중고 스마트폰의 적정 가격을 예로 들어 설명하겠다.중고 스마트폰의 가격을 결정하는 요소에는 다음과 같은 것들이 있다:제조사모델명제조 연월화면 크기, CPU
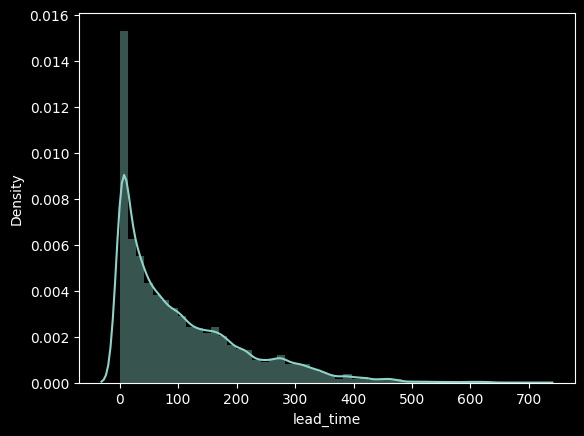
[프로젝트] 숙박예약 수요 분석
아래는 약 1년( 2015년 7월 ~ 2017년 8월 ) 의 기간 동안 수집한 A호텔의 고객 호텔 예약 데이터를 통해 노쇼/취소 고객의 증가를 막고 운영 비용을 노쇼와 취소고객을 예측한 결과에 맞춰 조정하기위해 RandomForestClassifier 모델을 사용한 머
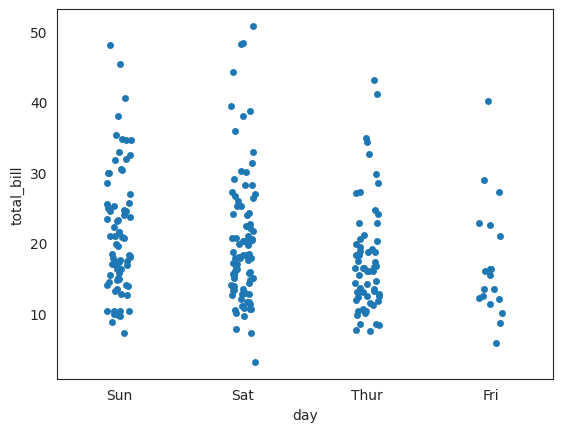
[Python] stripplot, 스트립 플롯 /
스트립플롯(strip plot)은 데이터 포인트를 각 카테고리별로 나란히 표시하는 플롯이다.이를 통해 데이터의 분포와 밀도를 시각적으로 확인할 수 있다. 주로 seaborn 라이브러리에서 제공하는 시각화 도구 중 하나이다.(1) 데이터 분포 확인: 각 데이터 포인트를