알고리즘
1.프로그래머스_이진 변환 반복하기
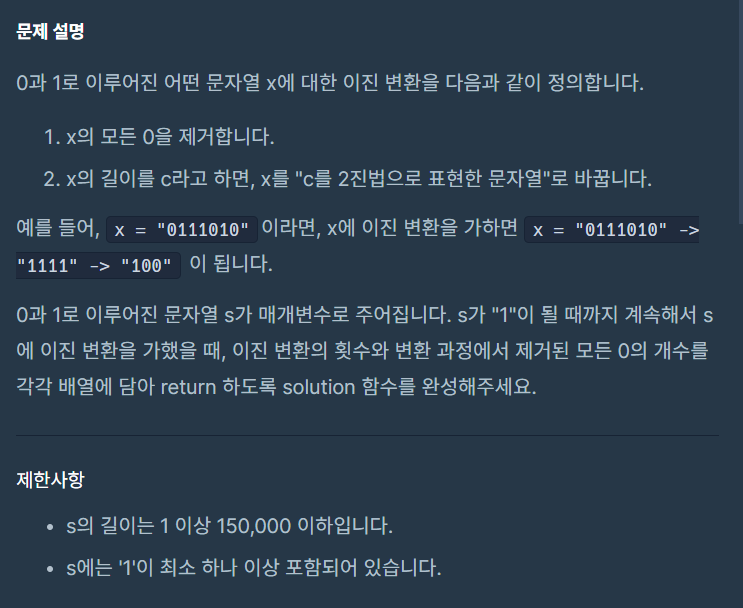
11
2.프로그래머스_올바른 괄호

해결 코드 쉬운 문제였다
3.프로그래머스_카펫
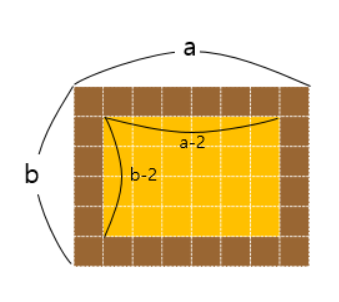
처음에 어떤 방식으로 시도해야할지 방향을 잡지 못했는데 인터넷에서 찾아보니 아래와 같은 방식으로 수식으로 접근하면 된다는 것을 알았다.ab = brown + yellow(a-2)\*(b-2) = yellowab - 2a -2b -4 = yellow2a + 2b = ab
4.프로그래머스_영어 끝말잇기
문제 설명1부터 n까지 번호가 붙어있는 n명의 사람이 영어 끝말잇기를 하고 있습니다. 영어 끝말잇기는 다음과 같은 규칙으로 진행됩니다.1번부터 번호 순서대로 한 사람씩 차례대로 단어를 말합니다.마지막 사람이 단어를 말한 다음에는 다시 1번부터 시작합니다.앞사람이 말한
5.프로그래머스_구명보트
문제 설명무인도에 갇힌 사람들을 구명보트를 이용하여 구출하려고 합니다. 구명보트는 작아서 한 번에 최대 2명씩 밖에 탈 수 없고, 무게 제한도 있습니다.예를 들어, 사람들의 몸무게가 70kg, 50kg, 80kg, 50kg이고 구명보트의 무게 제한이 100kg이라면 2
6.프로그래머스_N개의 최소공배수
최소공배수 내장 함수인 lcd을 사용하면 쉽게 풀수 있지만 사용할 수가 없었다 다행히 gcd 함수는 사용할 수 있어 쉽게 해결(gcd 함수도 구현할 수 있지만 좋은 내장 함수가 있는데 사용하지 않을 이유가)
7.백준_1463_1로 만들기(동적계획법)
처음 생각한 풀이우선 1~3까지는 횟수가 1번으로 정해져 있으므로 1로 dp 배열에 넣고 4부터 2로 나누어지면 2로 나눈 숫자의 횟수에 1을 더하고 3으로 나누어지면 3으로 나눈 숫자의 횟수에 1을 더한다 2, 3 둘다 나눠 지지 않으면 이전 숫자의 횟수에 1을 더하
8.백준_2798_블랙잭(브루트포스)
dfs로 해당 문제 해결!이전에 풀었던 방법이전에는 combination으로 해결했었다. 효율성을 비교해 보면이전의 방식이 더 효율적이다. 쉽게 풀었긴했지만 잊고 있었던 combination을 다시 한번 생각나게 해준 고마운 문제이다.
9.백준_2231_분해합(브루트포스)
단순히 for문들 돌면서 처음 답을 발견하면 break로 탈출하고 그렇지 않으면 0을 출력하게 작성했다. 어렵지 않은 문제였다.
10.백준_19532_수학은비대면강의입니다(브루트포스)
달리 생각할게 없는 문제였다.
11.백준_1018_체스판 다시 칠하기(브루트포스)
체스판의 크기는 8\*8 크기로 정해져 있으므로 처음에 2중 for문을 돌면서 각 체스판에 대해 바꿔야 하는 색깔의 숫자를 구하며 그 중 제일 작은 값이 문제의 정답이다각 체스판에 대해 바꿔야 하는 색깔의 숫자는 처음에 W로 시작하는 경우와 B로 시작하는 경우를 따로
12.백준_2839_설탕 배달(브루트포스)
while 문을 통해 3씩 빼가면서 5로 나누어 떨어질 때 마무리 하는 방식스스로 해결하지 못했다... 수학적인 사고로 문제 해결하는 것에는 아직 미숙한걸 느낀 문제였다.
13.백준_10989_수 정렬하기3(정렬)
당당하게 힙 정렬을 통해 풀었지만 메모리 초과가 났다.조건의 메모리가 입력 전부를 리스트로 받기에는 너무 작았다.N의 최대 갯수보다 N의 최대 크기가 더 작으므로 리스트를 숫자에 대한 리스트로 만들고 그 숫자에 대해 몇 개가 입력되었는지를 저장한다. 이렇게하면 나중에
14.백준_1010_다리 놓기(조합론)

처음에 직접 풀어봤을 때 factorial 관련해서 규칙이 있는 것을 파악해서 factorial을 사용해서 나눠보기도 하고 더해 보기도하고 지지고 볶았지만 해결하지 못했다. 인터넷에서 확인해 보니 조합 공식을 사용하면 풀 수 있는 문제였다. 확인해보니 DP로도 풀 수
15.백준_4949_균형잡힌 세상(Stack)

스택하면 빼 놓을 수 없는 괄호 문제!
16.백준_1874_스택 수열(Stack)
Stack이 비어있거나 Stack의 마지막 값보다 주어진 수가 크다면 스택에 주어진 수 까지 추가한다음 주어진 수는 바로 pop 함으로써 1부터 주어진 수까지 차례대로 꺼낼 수 있게한다.Stack에 숫자를 넣을 때는 어차피 마지막 숫자는 바로 pop 하므로 굳이 넣지
17.백준_2447_별 찍기(재귀)
직접 해결하지 못했다. 특히 "boarda\*i+t = boardt" 이 부분을 이해하는데 오래 걸렸다.풀이를 해보자면 k가 3일 때는 패턴 모양을 완성시키고 재귀 종료 조건으로 한다.그 다음 k의 크기가 몇이든 크게 9등분한다. 9등분을 재귀를 돌면서 패턴에 맞게 채
18.백준_N과 M(1~4)_(백트래킹)
백트래킹 맛보기 문제들!!
19.백준_9663_N-Queen(백트래킹)
처음 푼 방식 -> 메모리도 비 효율적일 뿐더라 답도 틀렸다.그래도 문제를 해결하려고 노력하면서 백트래킹에대해 많이 익숙해졌다. 예전에 풀때는 백트래킹 과정이 머리에 그려지진 않았는데 이번에는 머리 속으로 백트래킹이 어떻게 수행되는지 고민하면서 문제를 풀었다.
20.백준_2580_스도쿠(백트래킹)

아쉽게도 시간 초과된 코드이다.다른 분들의 코드를 보니 0인 값을 for문을 돌며서 찾는 것이 아니라 입력 받을 때 해당 정보를 따로 저장한다. 이렇게 하면 for문을 돌면서 찾을 때 보다 확실히 시간절약이 가능하다. check 과정에서 가로, 세로만 확인하는 것이 아
21.백준_1912_연속합(DP)
Dp의 기초 맛보기 문제이전 연속된 합들과 현재 값의 합, 현재 값을 비교해서 Dp에 저장시킨다.
22.백준_1149_RGB거리(DP)
2차원 배열을 쓰는 DP의 맛보기 문제같은 색이 중복되면 안되므로 이전 값들의 합을 저장할 때 같은 인덱스는 피해서 구해준다.
23.백준_2579_계단 오르기(DP)
dp 계획을 잘 세워야하는 문제이다.한 칸씩 가는건 연속으로 2번만 가능하고 그 뒤에는 반드시 두 칸을 이동해야한다.그래서 3계단 까지는 반복문이 아닌 직접 초기 값을 넣어줘아야한다.\-> 그래야 두 칸 이동한 상태와 한 칸 이동한 상태에 대해서 최대 값을 구할 수 있
24.백준_1463_1로 만들기(DP)
1부터 n까지 차례대로 구할 수 있는 최소한의 횟수를 구해나가는 방식이다.우선 숫자 n은 n-1로 부터 +1 하는 계산으로 구할 수 있다. 그 다음 3으로 나누어 떨어지는 숫자의 경우와 2로 나누어 떨어지는 숫자의 경우 각각 dpn//3, dpn//2으로 부터 그 값
25.백준_10844_쉬운 계단 수(DP)
우선 한 자릿수인 계단 수의 경우는 0으로 시작하는 수는 계단 수가 아니므로 1~9까지 총 9개이다.두번 째 자릿수 부터 Dp 값을 구하면 되는데 0과 9의 경우는 각각 1과 8에서 오는 경우 밖에 없다.따라서 0과 9인 경우는 그냥 1에서 오는 경우와 8에서 오는 경
26.프로그래머스 주식가격
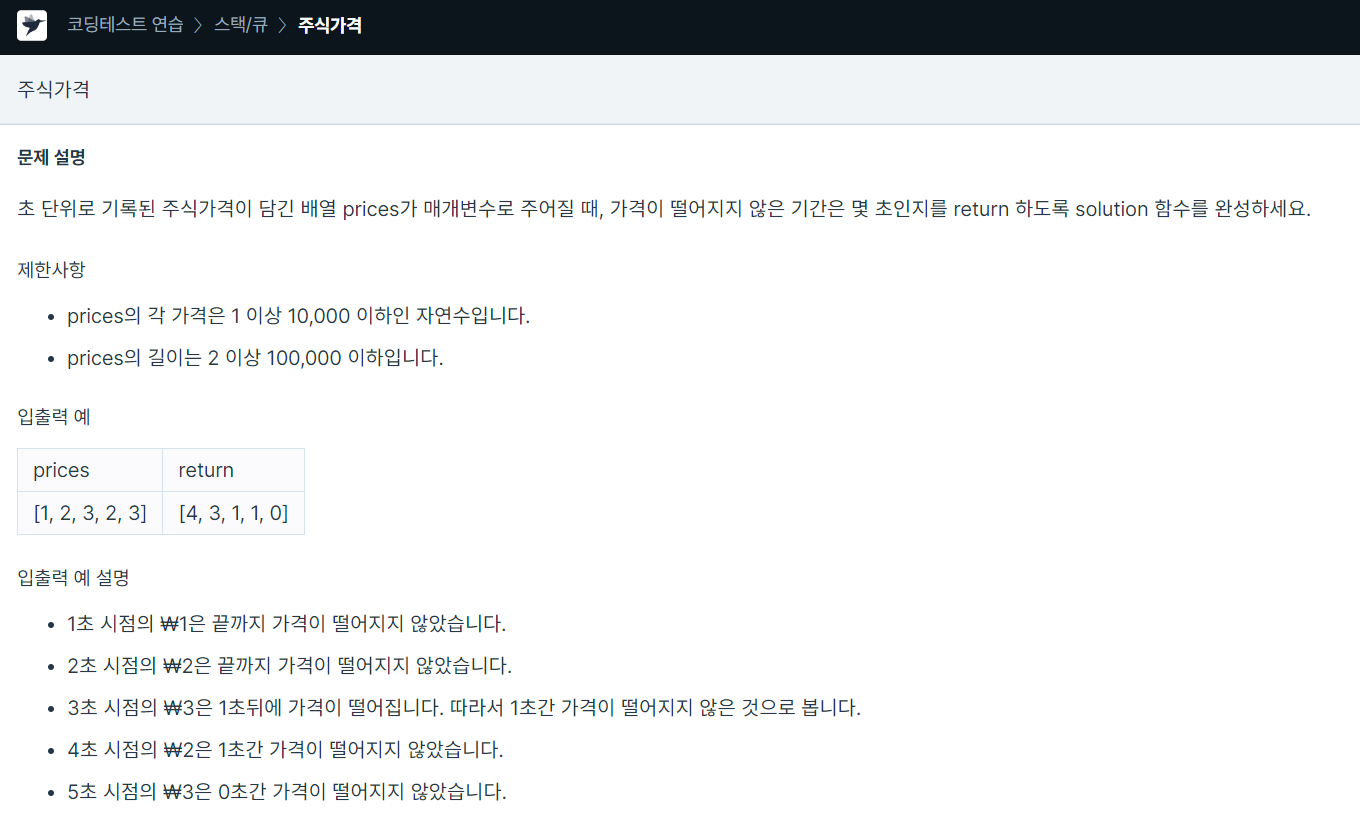
stack을 통해 해결했다.큰 값이 들어올 경우 stack에 index값을 저장하고 그렇지 않으면 stack에 pop 하면서 현재 i 값과 stack에 저장된 index 값을 뺌으로써 떨어지지 않는 시간을 구할 수 있다.i 가 마지막인 경우 stack에 넣을 필요 없으
27.프로그래머스 스킬트리
스킬 트리를 순회하면서 각 스킬에 대해서 스킬 순서를 확인한다 스킬 순서는 idx를 통해 순서대로 배우고 있는지 확인한다. for 문을 돌면서 현재 배워야 할 스킬이 아닌데 skill안에 있는 경우와 스킬을 다 배운 경우 for문을 계속해서 돌 필요가 없으므로 b
28.프로그래머스 땅따먹기
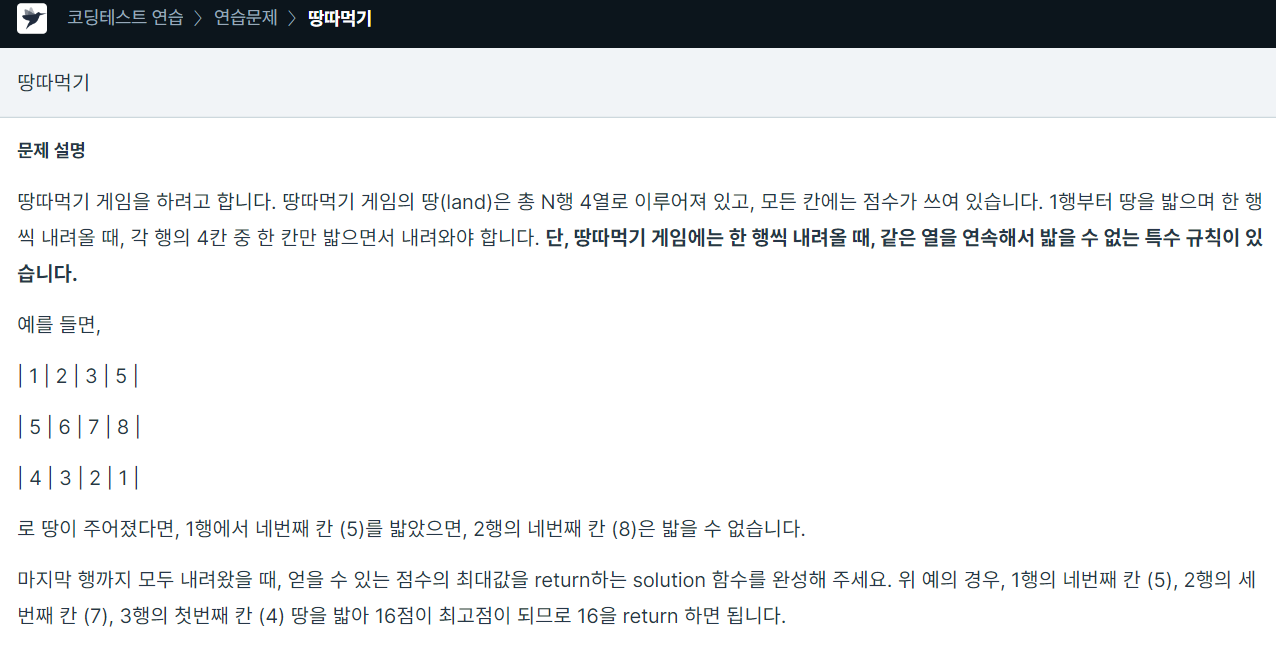
dp를 사용해 해결이전에 밟은 땅과 같은 index의 땅은 밟을 수 없으므로 이전 누적 dp에서 해당 index 뺀 것중 max 값을 가져와 계속 누적시켜준다.
29.프로그래머스 방문 길이
set 자료구조를 사용해 푼 문제이다.캐릭터에 현재 이동 방향을 더해서 만약 갈 수 있는 경우라면 set에 현재 위치와 이동할 위치를 넣어주고 현재 위치를 이동할 위치로 바꿔준다.set에 넣어줄때 반대 방향에 대해서도 같이 넣어줌으로써 나중에 반대 방향으로 이동하는 경
30.프로그래머스 [3차]파일명 정렬
정규식을 사용해서 숫자인 부분을 찾아서 head와 number를 나누었고 파일의 인덱스 정보도 같이 이용해서 총 3개를 통해 정렬하고 정렬한 결과를 anwer에 저장시킨다.숫자를 찾는 부분은 인터넷 검색을 통해 알았다.
31.백준_14888_연산자 끼워넣기(백트래캥)
\+, -, \*, %의 횟수가 숫자로 주어지므로 dfs는 각각의 기호를 하나씩 빼면서 진행된다.. 종료 조건은 4개의 기호가 모두 0이 될 때이다.
32.백준_2156_포도주 시식(DP)
dp 계획은 이전의 2개의 와인을 마시고 와 현재 와인을 마실 수 없는 경우, 2번째 전의 와인과 현재의 와인을 마시는 경우, 3번째 전의 와인을 마신 후 건너띄어서 이전 와인과 현재 와인을 마실 수 있는 경우 이렇게 3개의 경우 중 최대 값으로 구한다.
33.백준_11053_가장 긴 증가하는 부분수열(DP)
현재 i를 기준으로 그 다음 숫자들을 돌면서 i의 수보다 큰 수가 나오면 해당 인덱스의 dp에 1을 더해준다. 1을 더해줄 때 현재 dp와 1을 더한 수를 비교해서 더 큰 값을 저장하기 때문에 가장 긴 증가하는 부분수열을 구할 수 있다.예를들면 30의 경우 10 ->
34.백준_11054_가장 긴 바이토닉 부분수열(DP)

LIS 알고리즘과 똑같이 진행하는데 입력 배열을 뒤집어서 한 번더 진행한다.그 후 두 개의 LIS 결과를 더해 줌으로 써 증가했다 감소하는 수열의 최장 길이를 구할 수 있다.백준 문제 11053 문제에서 한 번더 꼰 문제https://www.acmicpc.ne
35.백준_11659_구간 합 구하기(누적합)
index로 매번 sum해서 풀게 되면 시간 복잡도가 O(n\*m)이므로 주어진 시간안에는 풀 수 없는 문제다.누적 합을 사용하면 쉽게 구할 수 있는 문제다
36.백준_14889_스타트와 링크(백트래킹)
백트래킹 문제이지만 주어진 combination으로 풀 수 있어 그냥 combination으로 해결했다.경우의 수를 combination을 사용해서 구한 후 각 경우에 대해 for문을 돌면서 각 팀의 능력치 값 차이의 최소 값을 구하는 방식이다.이전에 풀 때는 백트레킹
37.백준_2565_전깃줄(DP)
LIS로 구할 수 있는 문제이다.A를 정렬 한 후 LIS를 구하면 교차하지 않는 전선의 최대 수를 구할 수 있다.이렇게 구한 수를 N에서 빼면 교차하지 않기 위해 빼야하는 수를 구할 수 있다.
38.백준_9251_LCS(DP)
스스로 해결하진 못했다.https://myjamong.tistory.com/317 이 분이 설명을 너무 잘해 주셔서 이해하는데 많은 도움이 됐다.
39.백준_12865_평범한 배낭(DP)
냅색 알고리즘을 통해 해결할 수 있는 문제dp는 2차원 리스트를 쓴다. dp의 row는 가방의 들어갈 각각의 물건이고 column은 가방에 들어갈 수 있는 무게에 대해 0부터 최대 무게까지이다.dp에서 저장해 나갈 정보는 해당 무게에서 물건들에 대한 가치의 최대 값이다
40.백준_11660_구간 합 구하기(누적합)
이런 2차원 리스트의 누적 합을 구할 때 생각해야 할 점은초록색 부분의 누적 합을 구하기 위해서는 파란색 두 개를 더해 준 후 겹친 부분인 빨간 색 부분을 빼 줘야 하는 것이다.반대로 나중에 초록색 좌표의 누적 합을 구할 때는 구하고자 하는 좌표에서 파란색 두개를 빼주
41.백준_1931_회의실 배정(그리디)
끝나는 시간 정렬 후 시작 시간 정렬해서 구할 수 있는 문제끝나는 시간을 저장했다가 끝나는 시간과 같거나 큰 시작시간이 들어오면 바꿔주면서 숫자를 세는 방식으로 해결이 문제에서 주의할 점은 끝나는 시간만으로 정렬하면 안된다는 것이다.끝나는 시간만으로 정렬했을 때는 답이
42.프로그래머스 모음사전
첫 번째 방법은 재귀를 사용해서 사전에 순서대로 추가해 나가는 방식인데 해당 방식으로 푼 나 조차도 완벽하게 이해하지 못해서 그냥 itertools의 product를 사용해 풀었다.
43.백준_1541_잃어버린 괄호(그리디 )
덧셈과 뺄셈을 어떤 순으로 할지 생각해야 하는 문제이다.먼저 뺄셈으로 입력을 split 한 후 덧샘을 진행하면 최소값을 구할 수 있는데이렇게 구할 수 있는 이유는 덧셈을 먼저 계산하고 뺄셈을 진행하게 되기 때문에 제일 큰 수의 경우로 뺄셈을 진행하기 때문이다.
44.프로그래머스 게임 맵 최단거리
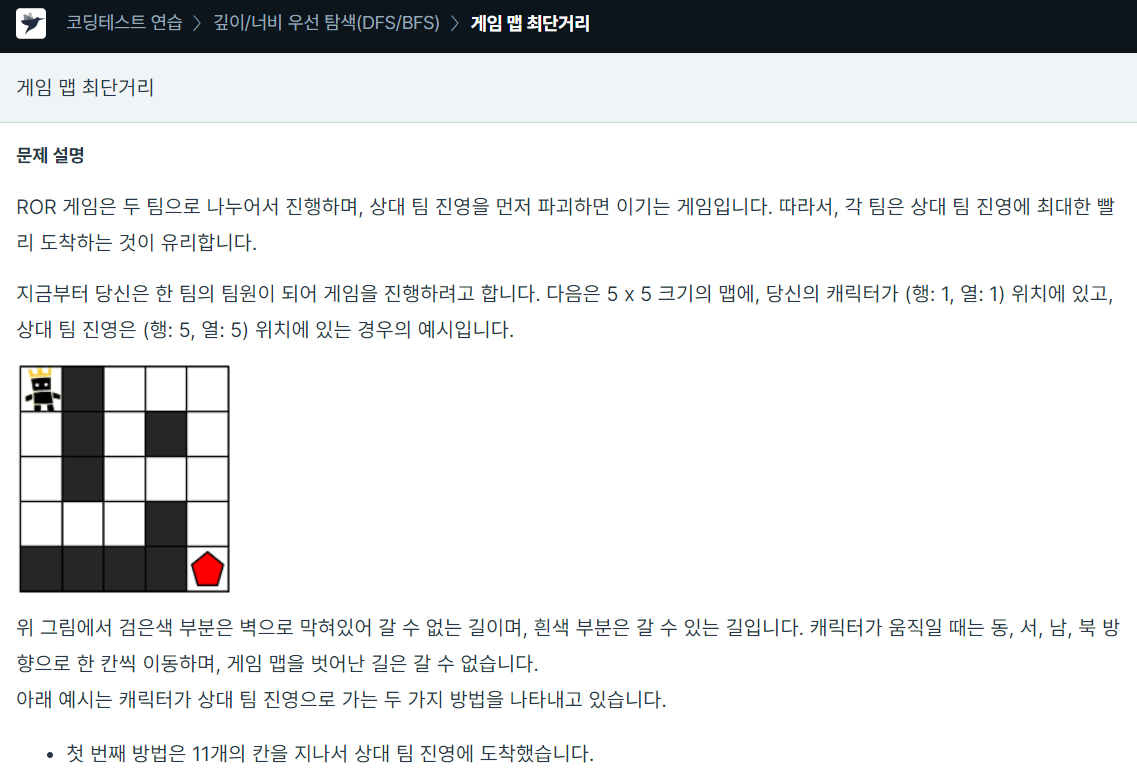
정확성 테스트의 경우 전부 정답이였지만효율성 테스트에서 전부 오답이 나왔다....dfs가 아닌 bfs를 통해 시도했지만 이번에도 효율성 테스트에서 전부 실패했다.결국 스스로 해결하지 못하고 인터넷에서 참조해서 풀었다.q에 저장할때 다음에 갈 map에 대해서도 미리 0으
45.백준 13305_주유소(그리디)

가격을 비교해 나가면서 현재 가격보다 싼 값이 나오면 그 가격으로 바꾸어준 후 진행해 나가면 된다.
46.백준 2630 색종이 만들기(분할 정복)

분할 정복을 통해 해결해나가는 문제분할 정복 함수의 경우 시작 좌표와 N을 주어진다.시작 좌표를 시작해서 N크기의 2중 for 문을 돌면서 시작 좌표와 다른 색이 존재한다면 4등분해서 정복해나간다.
47.백준 1992 쿼드트리 (분할정복)
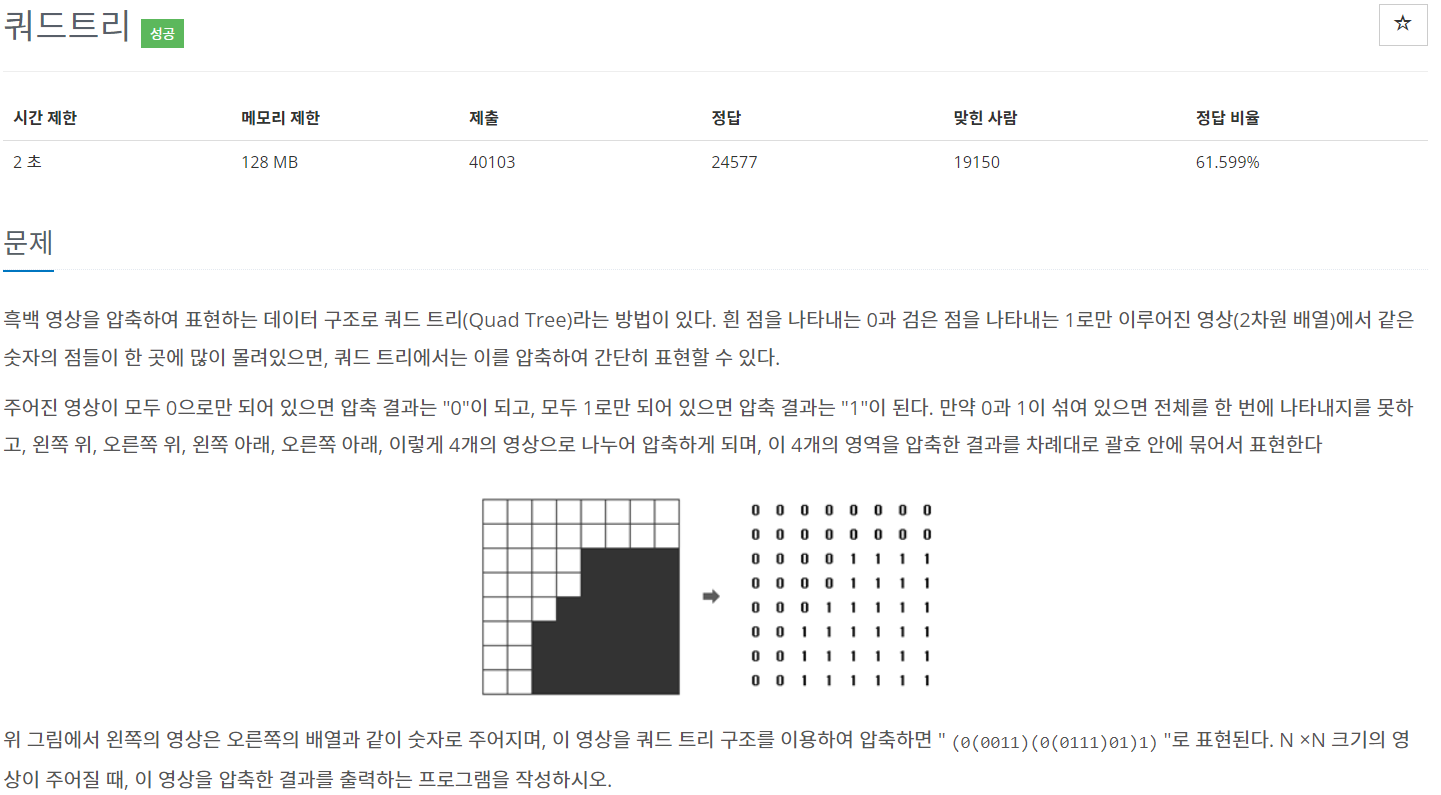
백준 색종이 만들기 문제와 매우 유사한 문제 색종이 만들기 문제를 풀 수 있다면 어렵지 않게 해결할 수 있는 문제이다.
48.백준 1920 수 찾기 (이분탐색)
이분탐색은 정렬된 배열에서 맞는지 아닌지로 답이 나뉘고 거기서 크다 작다로 나뉘는 경우 사용하는 알고리즘리스트의 mid 값을 비교하며 찾고자 하는 값이 mid 값 보다 크면 시작지점을 mid + 1로 작으면 mid -1로 하여 빠르게 배열을 탐색하는 방법이렇게 할 시
49.백준 10816 숫자 카드 (이분 탐색)
처음 N개의 카드를 입력 받을 때 딕셔너리를 통해 해당 카드의 개수를 같이 저장시키고 후에 이분 탐색으로 숫자를 찾고 있다면 딕셔너리에 저장해 놓은 개수를 출력한다.이전에 풀었던 방식인데 어차피 딕셔너리의 경우 key 값을 통해 저장된 값을 찾을때의 시간 복잡도는 O(
50.프로그래머스 2개 이하로 다른 비트
특별히 사용한 알고리즘은 없고 bit의 규칙을 찾아서 해결한 문제처음에 0의 뒤에서 부터의 위치를 찾는다. 만약 0이 없다면 bit로 변환한 수 앞에 0이 있다고 생각한다.만약 111 이라면 0111로 0의 위치는 3으로 생각하고10 이라면 0의 위치는 0으로 생각한다
51.백준 2805 나무 자르기
주어진 n과 m의 크기가 말도 안되게 크므로 이중 for문을 돌면서 답을 찾는 방식은 불가능하고 이분탐색을 사용하여 해결해야 한다.1과 주어진 나무 길이의 최대 값으로 start와 end값을 설정해준다.이후 나무들을 자르면서 자를 수 있는 나무의 자른 후의 값을 저장해
52.백준 2110 공유기 설치(이분탐색)
주어진 n, c가 너무 크기 때문에 완전 탐색으로는 해결이 불가능 하다.이 문제도 이분탐색으로 해결이 가능하다.우선 각 좌표에 대한 거리를 차례대로 구해야 하기 때문에 정렬을 진행한다.s, e를 각각 1과 좌표에서의 가장 큰 값으로 정한 후 이분탐색을 진행한다.여기서
53.백준 1520 내리막 길 (DP)

이 문제의 핵심은 DFS로 진행해 나갈 때 이미 진행했었던 길이라면 다시 계산하지 않는 것이다.이를 위해 dp 초기 값은 -1로 저장해 둔다. -1로 함으로서 해당 좌표에 대해 계산 수행할 때 계산을 했음에도 0인 경우와 구분할 수 있다. 즉 해당 좌표에 대해 방문 했
54.백준 2293 동전 1 (DP)
처음 시도 방법냅색 알고리즘을 통해 시도했다.dp를 2차원 List로 만들고 행은 coin의 개수 열은 0~K까지의 금액이다.2중 for 문을 돌면서 j 값이 현재 동전의 가치랑 같으면 이전 Dp 값에 + 1현재 동전의 가치보다 크다면 이전 Dp 값에 현재 행의 J -
55.백준 9935 문자열 폭발 (스택)
입력으로 주어진 문자열을 하나씩 stack에 저장하면서 만약 stack 폭발 문자열 길이 만큼의 뒷부분이 폭발 문자열과 똑같으면 pop하는 방법
56.프로그래머스 다리를 지나는 트럭
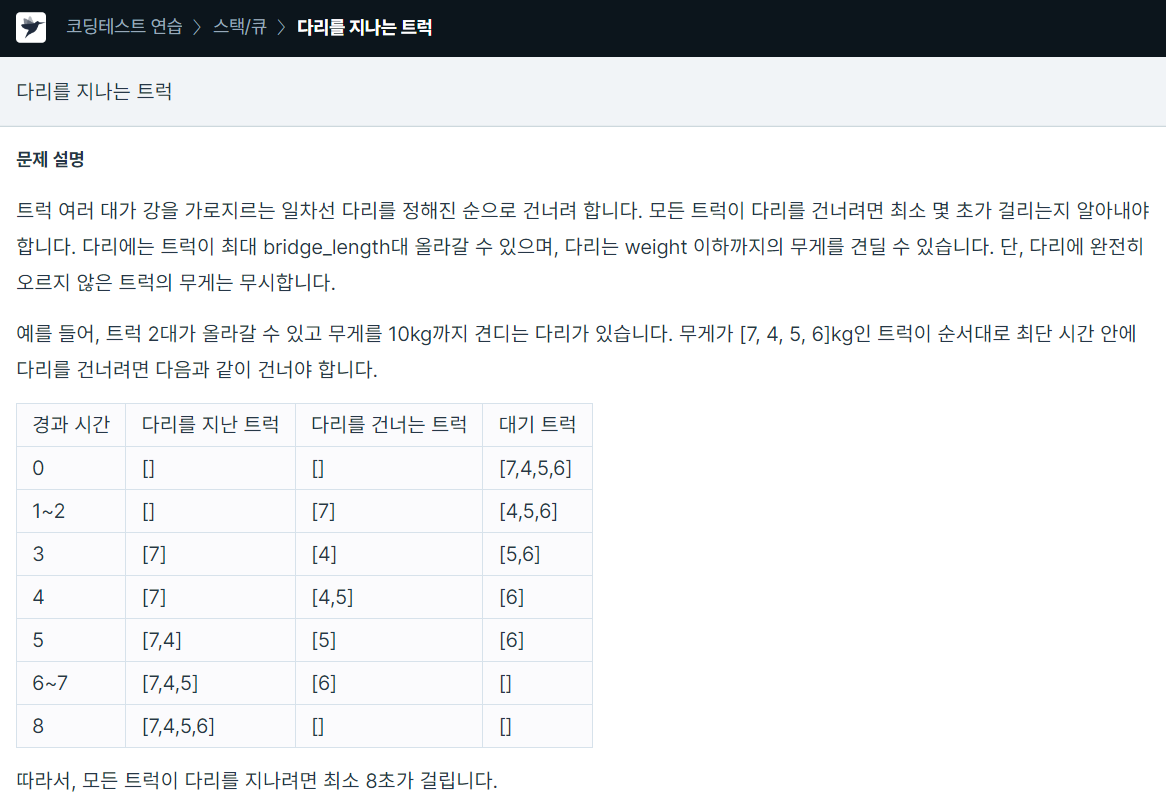
deque를 사용해서 문제 해결q에 birdge_lenth 정보와 트럭의 무게를 함께 저장해서 다리가 꽉 차 있는지, 트럭을 추가해도 되는지 확인하며 진행해나가는 방식이다.마직막에 while문을 통해 q를 비워주면서 다리 위에 남아있는 트럭이 모두 지나가는 것을 구현
57.프로그래머스 / 뒤에 있는 큰수
stack에서 인덱스를 저장하는 방식으로 해결할 수 있는 문제stack에 값이 아닌 인덱스를 저장시키고 stack에 마지막 인덱스의 수 보다 큰 수가 들어오면 계속해서 pop해준다.pop하면 인덱스 정보가 나오므로 answer 배열에서 해당 인덱스를 바꿔주는 방법으로
58.프로그래머스 / 가장 큰수
이 문제의 핵심은 3, 30, 34 이렇게 앞자리가 같은 숫자에 대해 어떻게 정렬하느냐이다.주어지는 numbers의 원소가 1000 이하이므로 sorted(numbers, key=lambda x: x\*3, reverse = True) 이렇게 문자를 3번 더한 것을 정
59.프로그래머스 / 소수 찾기
permutations을 사용해서 모든 경우의 수를 구한다음 set을 사용해서 중복되는 경우는 제거한다.그 다음 소수 찾는 알고리즘을 통해 총 개수를 구할 수 있다.
60.백준 / 17299 / 오등큰수 (Stack)
백준 17298 오큰수와 매우 유사한 문제이다. (https://www.acmicpc.net/problem/17298)이 문제는 등장한 횟수를 기준으로 수열을 구해야 하므로 dictionary를 통해 문제를 해결했다.dictionary에 횟수를 저장하기 위해선
61.백준 / 1725 / 히스토그램 (스택)

스택에 인덱스 값을 저장하면서 나간다. 만약 스택에 저장된 인덱스의 막대 크기보다 작은 크기의 인덱스 값이 들어온다면 뒤에서 부터 pop 하면서 넓이를 구하게 된다.이때 작은 값이 들어와야 pop()을 진행하는 것이므로 현재 막대의 높이는 pop() 진행하면서 작아지게
62.백준 / 2606 / 바이러스 (그래프)
그래프 알고리즘으로 해결 가능한 문제graph 알고리즘으로 간선 저장 후에 1번 컴퓨터로 시작해서 dfs로 진행visited로 방문 여부를 저장하므로 결과 값은 visited에서 방문한 노드의 수이다.(1번은 빼야 하므로 -1)
63.백준 / 1260 / DFS와 BFS (그래프)
dfs와 bfs 개념을 확실하게 다져줄 수 있는 문제
64.백준 / 2667 / 단지번호붙이기 (그래프, dfs)

DFS를 사용해 푼 문제주어진 지도를 2중 for문을 통해 돌면서 1을 찾으면 dfs 진행1을 찾기으면 result에 0을 append 해서 추가된 0을 dfs 진행 시 +1 해주면서 크기를 저장한다.visited를 통해서 방문 여부를 체크하는 것이 중요하다.
65.백준 / 1012 / 유기농 배추 (dfs)
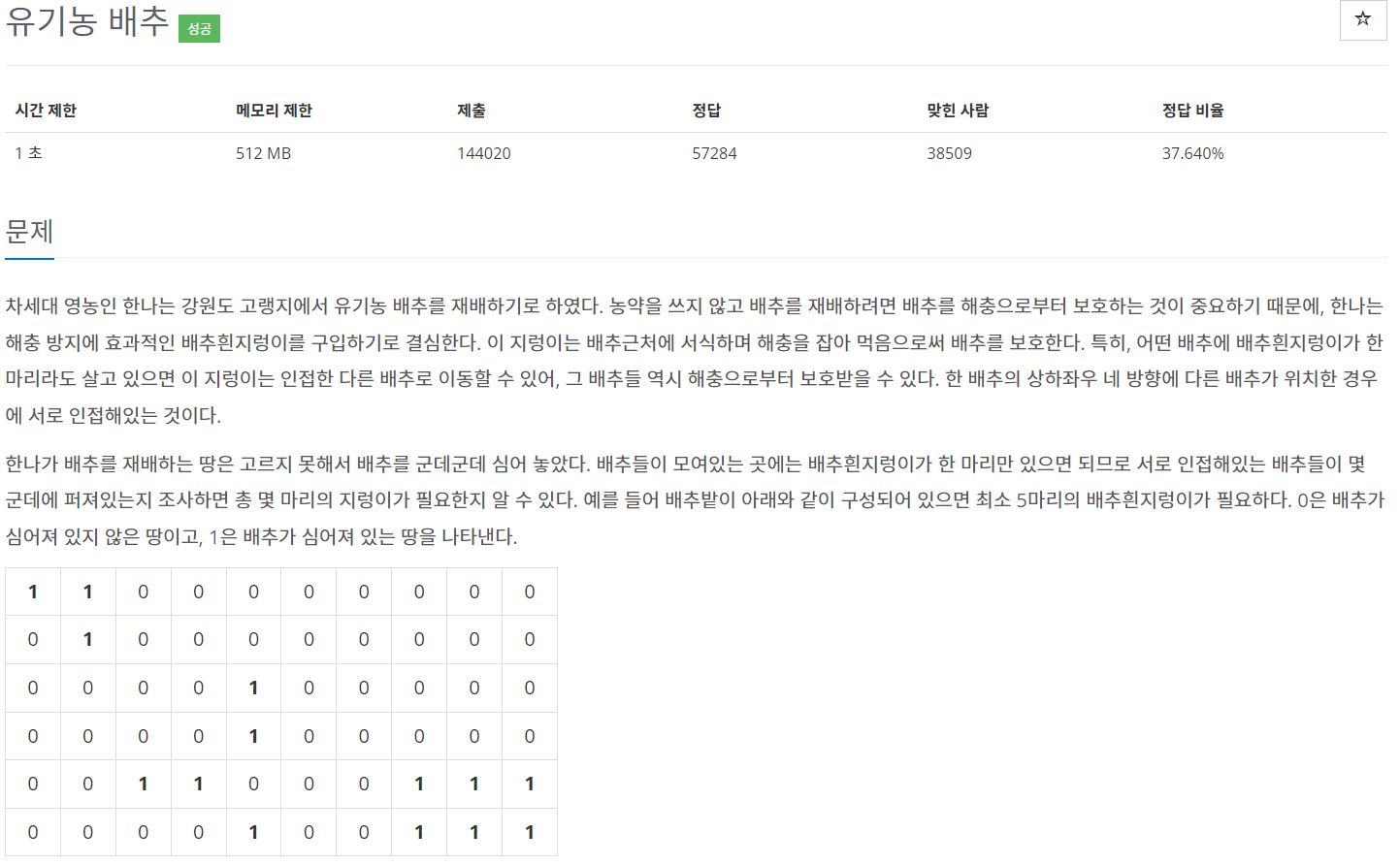
dfs로 해결한 문제n \* m 크기의 배열을 만든 후 배추 위치에 1을 두고 dfs 진행dfs를 이해하고 있다면 어렵지 않은 문제이다.
66.백준 / 2178 / 미로탐색 (bfs)
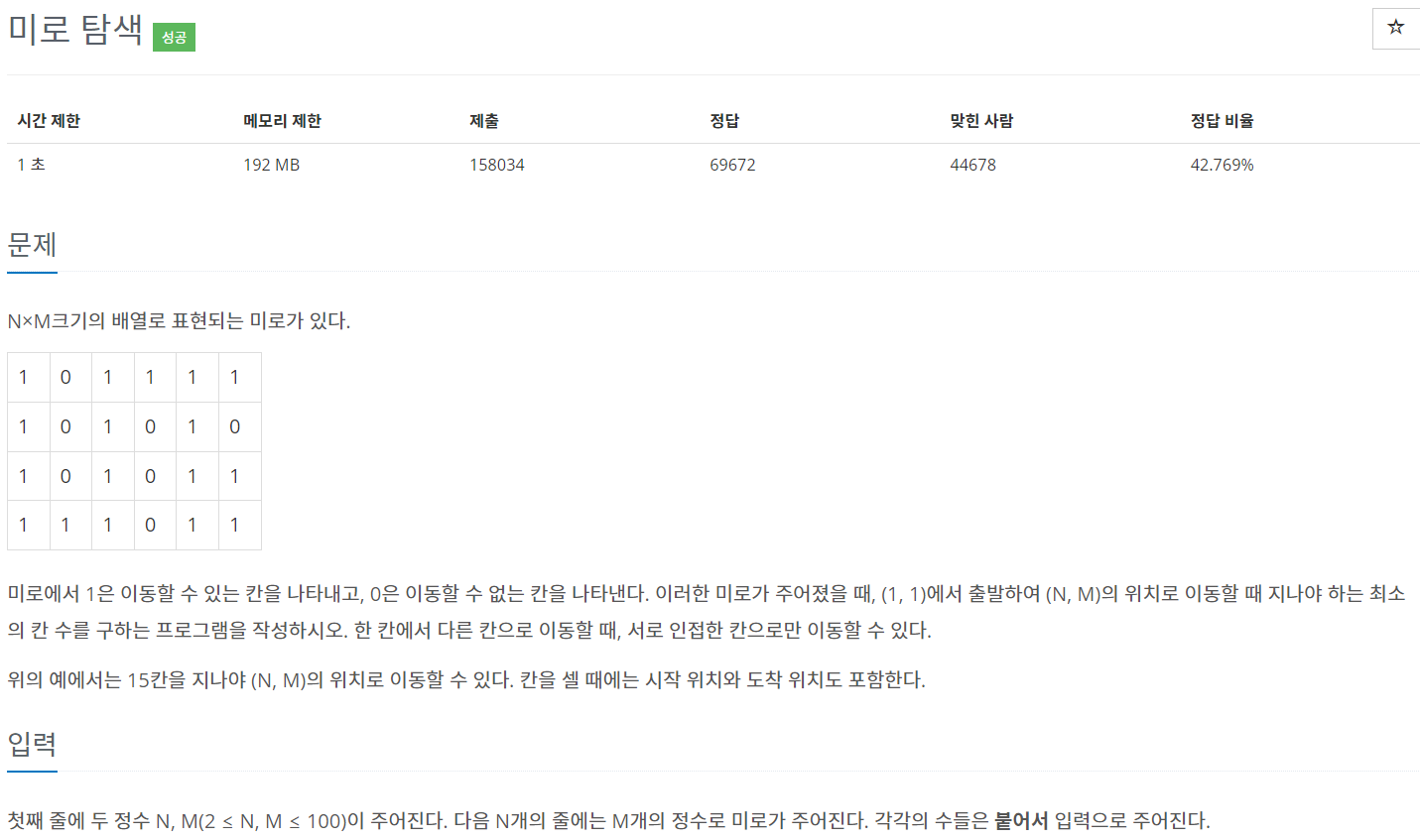
bfs를 진행하면서 1인 값을 찾은 후 해당 좌표 방문하고 방문한 좌표는 0으로 바꿔서 다시 방문하지 않게 한다. 방문 할때마다 deph +1을 해줘서 마지막 좌표에 도달하면 deph의 크기가 정답이다.
67.백준 / 1697 / 숨바꼭질 (bfs)
bfs로 해결하는데 이 문제에서 주의할 점은 길이이다. 시작 지점이 도착 지점보다 큰 경우 n 값으로 길이를 설정해 줘야한다. 시작 지점이 도착 지점보다 큰 경우는 빼는 경우 밖에 존재하지 않는다. 따라서 n+1 값으로 graph list의 길이를 설정하면 충분하다.시
68.백준 / 7576 / 토마토 (bfs)
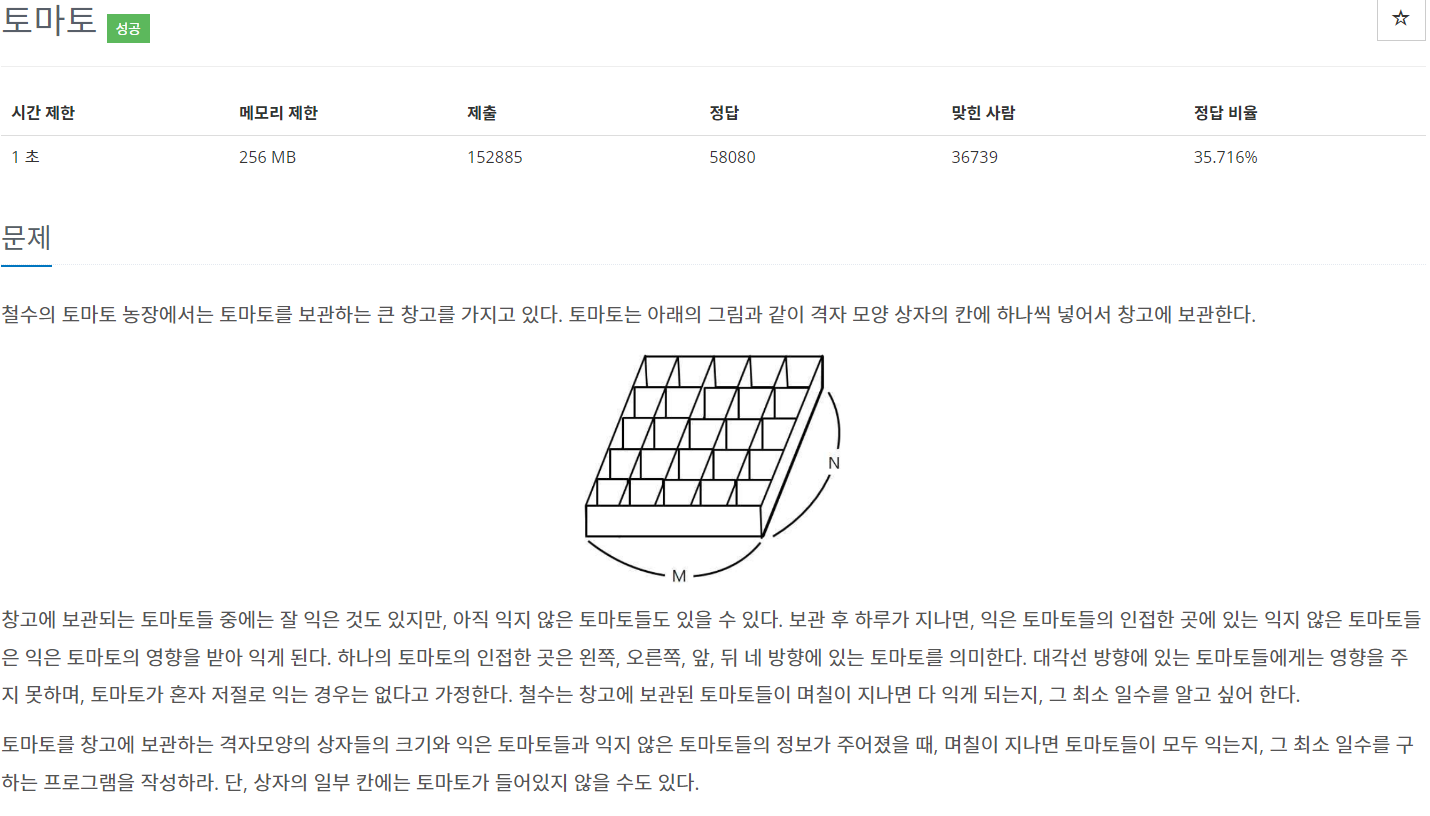
시작점이 여러개인 bfs 문제처음 deque에 1인 시작점을 모두 입력한 후 bfs 진행한다.이 점만 고려하면 일반적인 bfs 문제와 똑같다.하나 더 주의 할 점은 처음부터 모든 토마토가 익어있는 상태라면 즉 1 혹은 -1, 1 로만 채워져있다면 이 경우 0을 출력해야
69.백준 / 16928 / 뱀과 사다리 (bfs)

이 문제는 처음 좌표에서 주사위에 대한 for 문 현재 좌표에서 + 1~6 좌표를 돌면서 만약 사다리나 뱀에 해당하는 좌표를 만나면 이동하고 그렇지 않으면 q에 append 하는 것이다.여기서 중요한 것은 그렇지 않으면 q에 넣는 것이다.처음에 코드를 윗 부분을 아래
70.백준 / 2206 / 벽 부수고 이동하기 (bfs)
시간 초과뜬 처음 시도 코드bfs를 진행하면서 1 즉 벽을 만나면 현재 진행 상황을 복사한 후 해당 1을 0으로 바꿔서 진행해 보는 방식예제 입력에 대해서 답이 맞긴 했지만 코드도 복잡할 뿐더라 시간 초과가 당연해 보인 듯 하다....
71.프로그래머스 / 숫자 변환하기

이 문제를 해결하는 방법으로 크게 두가지를 떠올릴 수 있다. Dp와 bfs위 코드는 bfs로 푼 방법이다.위 이미즌 bfs 방식으로 제출한 것이고 아래 이미지는 DP 알고리즘으로 제출한 것이다. 생각해보면 이 문제는 최단 경로를 구하는 것이고 이런 경우에는 y 값까지
72.프로그래머스 / 요격 시스템 / python
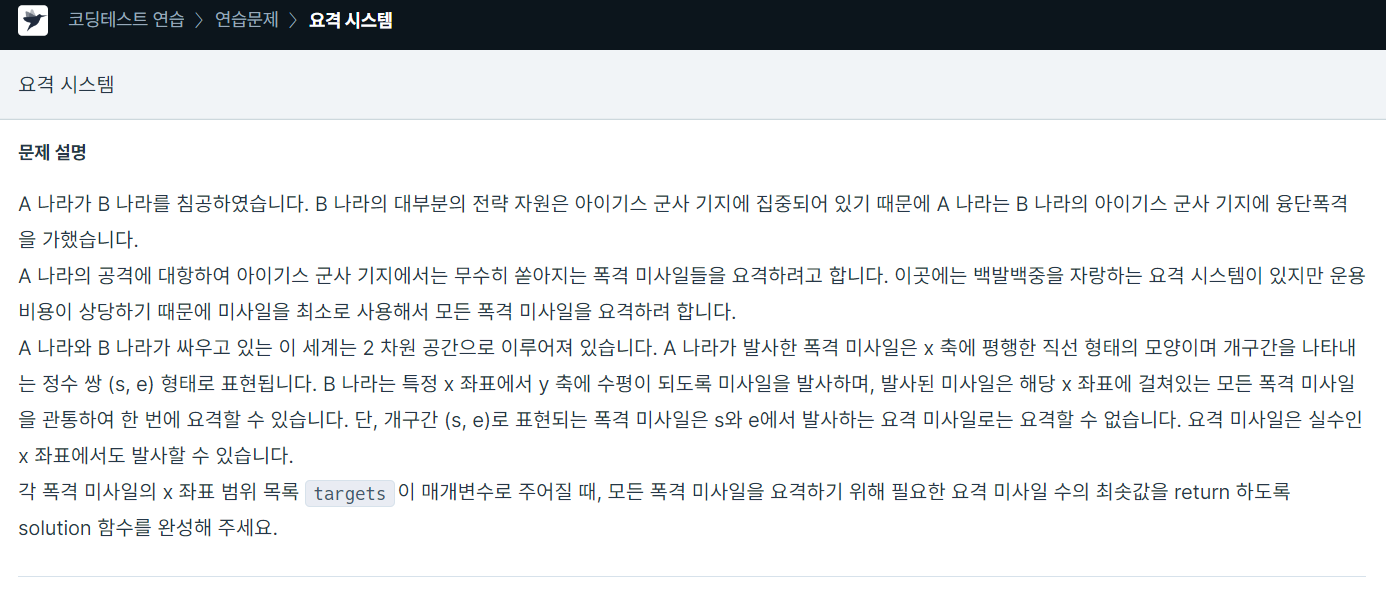
입출력 예 설명에서 힌트를 얻을 수 있다. 좌표 e를 기준으로 정렬한다.s, e가 겹치는 경우는 다른 범위 이기 때문에 for문을 돌면서 정렬된 미사일 좌표 s가 이전 미사일 e와 같거나 큰 경우는 같이 요격할 수 없으므로 정답을 +1 해주고 e 좌표를 업데이트 해준다
73.프로그래머스 / 두 원 사이의 정수 쌍 / python
주어진 입력 조건을 보면 r1, r2의 최대 값은 1,000,000이다. 전부 찾으려면 2,000,000 \* 2,000,000, 이므로 시간 복잡도가 너무 크다.위에 코드는 전부 구하는 대신 x, y 값이 양의 정수 일때만 구한 뒤 곱해주는 방법이다.하지만 이 방법도
74.프로그래머스 / 광물 캐기 / python
백트래킹으로 푼 문제각 곡갱이에 대해서 곡갱이가 존재한다면 dfs 진행하는 방식으로 해결더 이상 남은 곡갱이가 없거나 mineral을 끝까지 다 캔 상태라면 dfs 종료 종료시 최소 값을 저장해 나가면서 답을 구할 수 있다.
75.프로그래머스 / 미로 탈출 / python
처음 시도 한 코드위 작성한 코드의 방식은 레버에 방문하면 lever 변수를 True로 변경해줘서 lever가 True일 때 방문 여부를 확인하는 visited를 초기화 하고 그 이후 bfs를 마저 진행하면서 탈출하는 방법이다.이 코드의 반례는 아래와 같다.SEOOOO
76.프로그래머스 / 시소 짝궁 / python
시간 초과코드이 문제는 딕셔너리를 통해 구할 수 있다.주어진 weights를 순회하면서 중복 값이 나오면 +1 해주면서 정보를 저장해간다.그 후 key 값을 순회하면서 수평에 맞는 조건을 통해 answer를 구할 수 있다.스스로 풀지 못 한 문제 아직은 이 문제처럼 알
77.GET과 POST의 차이
GET은 데이터를 url 뒤에 ?와 함께 사용하며POST는 특정 양식(form)에 데이터를 넣어 전송하는 방법입니다.http://사이트\_주소?데이터=xxxhttps://comic.naver.com/search?keyword=%EC%8B%A0%EC%9
78.프로그래머스 / 이중우선순위큐 / python
최소 힙과 최대 힙 둘을 사용해서 해결했다.하지만 이게 효율적인 코드인지는 잘 모르겠다. 최대값이나 최소값을 제거할때 두개의 리스트가 연동되어야하므로 다른 하나에서 그 값을 제거하기 위해서 remove 연산을 하고 remove하면 heap 구조가 깨지므로 다시 heap
79.프로그래머스 / 최고의 집합 / python
처음 시도한 방법말도 안되는 방법이다. 모든 테스트 케이스에 대해 시간초과가 떴다.다시 생각해도 너무 말이 안돼서 뭐라 쓸 말이없다.다음 시도 코드수학적 사고로 해결해야할 문제이다.이 문제에서 생각할 바는 각 원소의 곱이 가장 큰 경우가 정답인 것이다. 즉 같은 수가
80.프로그래머스 / 네트워크 / python
DFS로 문제 해결n의 최대 개수가 200이므로 dfs로 접근하여도 recursion limit에 제한 받지 않으므로 dfs로 해결이 문제는 dfs의 깊이가 아닌 횟수로 답을 구할 수 있는 문제이다. dfs를 진행한 횟수를 구함으로서 분리되어 있는 노드들의 묶음(이 문
81.프로그래머스 / 야근 지수 / python
최대 힙을 통해 해결한 문제한 시간에 하니의 작업량 처리가능 하므로 n을 1씩 빼면서 works 중 하나의 작업 량도 하나 씩 뺀다.이때 야근 지수를 최소화 하려면 최대 값의 숫자를 빼야한다. 즉 최대힙을 통해 1씩 빼고 다시 넣어 주는 방법으로 해결 할 수 있다.
82.프로그래머스 / 단어 변환 / python

최소 몇 단계 변화로 target을 구할 수 있는지 찾는 문제. 즉 최단 경로 문제이므로 bfs로 해결할 수 있다.어럽진 않은 문제지만 주의할 점은 음...
83.프로그래머스 / 등굣길 / python
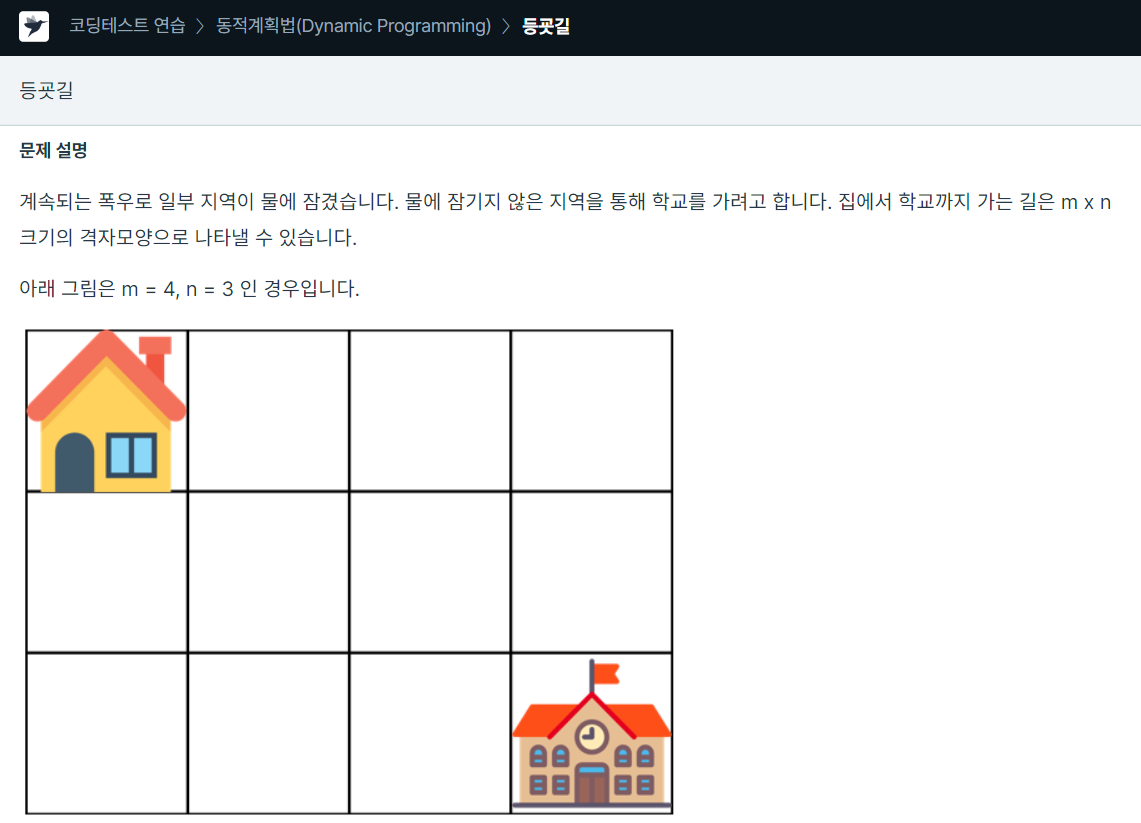
dfs와 dp로 해결한 문제처음에 n\*m 크기의 list를 0의 초기 값을 갖도록 만들어 준 후 물 운덩이에 해당하는 부분을 1로 둬서 나중에 해당 좌표는 탐색하지 않도록 한다.그 다음 dfs로 갈 수 있는 경로를 탐색한다.이 문제에서 dp는 top down 방법이다
84.프로그래머스 / 단속카메라 / python
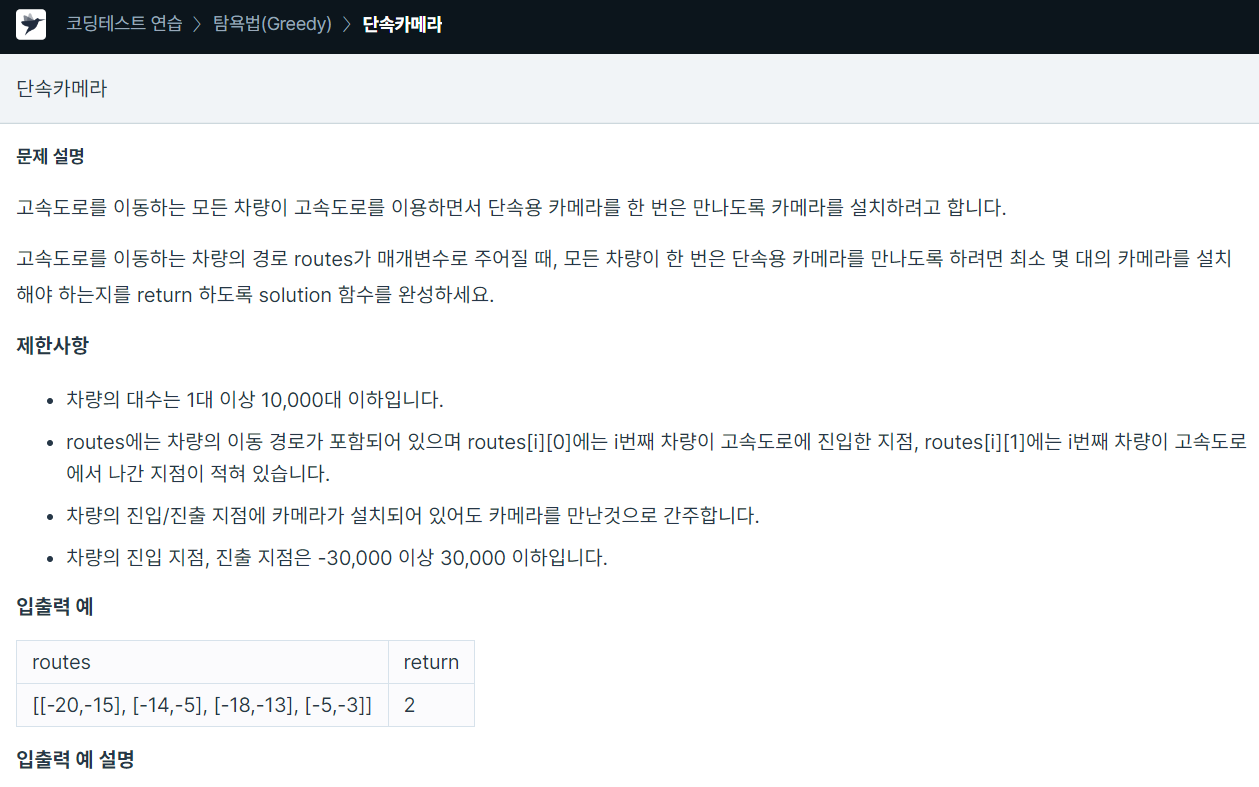
차량이 고속도로에서 나간 지점을 기준으로 정렬해서 만약 새로 들어온 차가 종료시간보다 크다면 다른 카메라가 필요한 경우이므로 answer + 1 해주고아니라면 q에 저장하는 방식으로 해결마지막에 q가 비워져있지 않다면 q에 남아있는 차량들이 하나의 단속 카메라로 감시할
85.프로그래머스 / 숫자 게임 / python
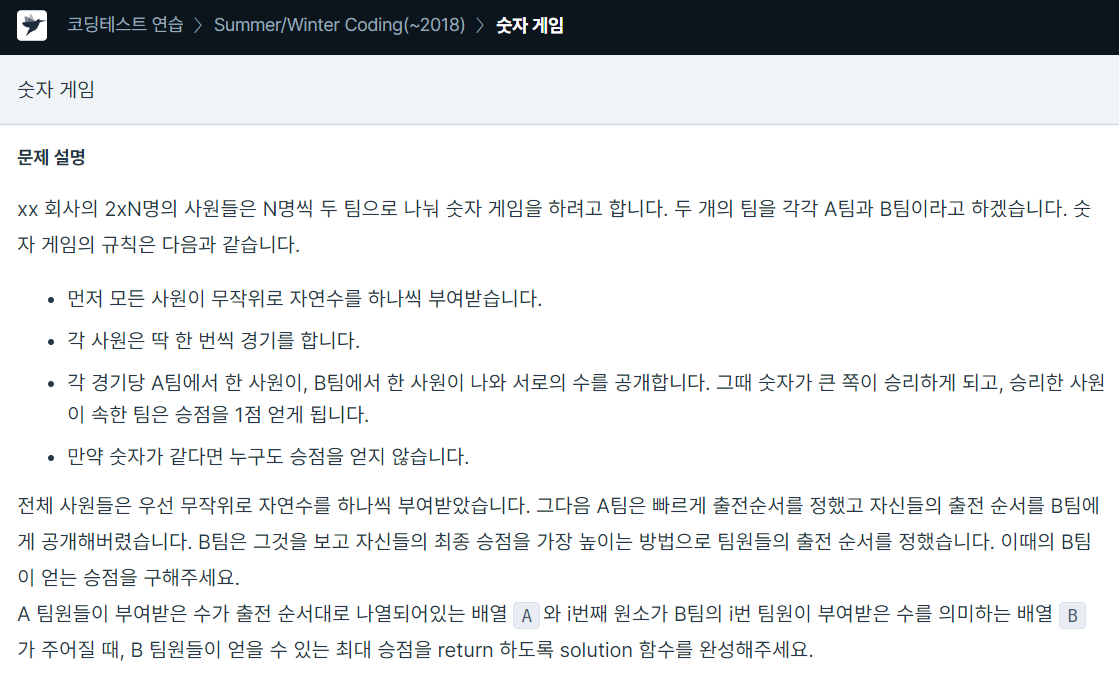
A, B의 길이가 최대 10만이기 때문에 완전 탐색으로는 풀 수 없다.그리디 알고리즘을 통해 해결한 문제주어지는 A 와 B를 모두 정렬한다.정렬한 후 만약 A와 B를 비교하는데 B가 크다면 A와 B를 비교하는 인덱스 값을 둘다 증가시키고 그렇지 않다면 A만 증가시킨다.
86.프로그래머스 / 베스트앨범 / python
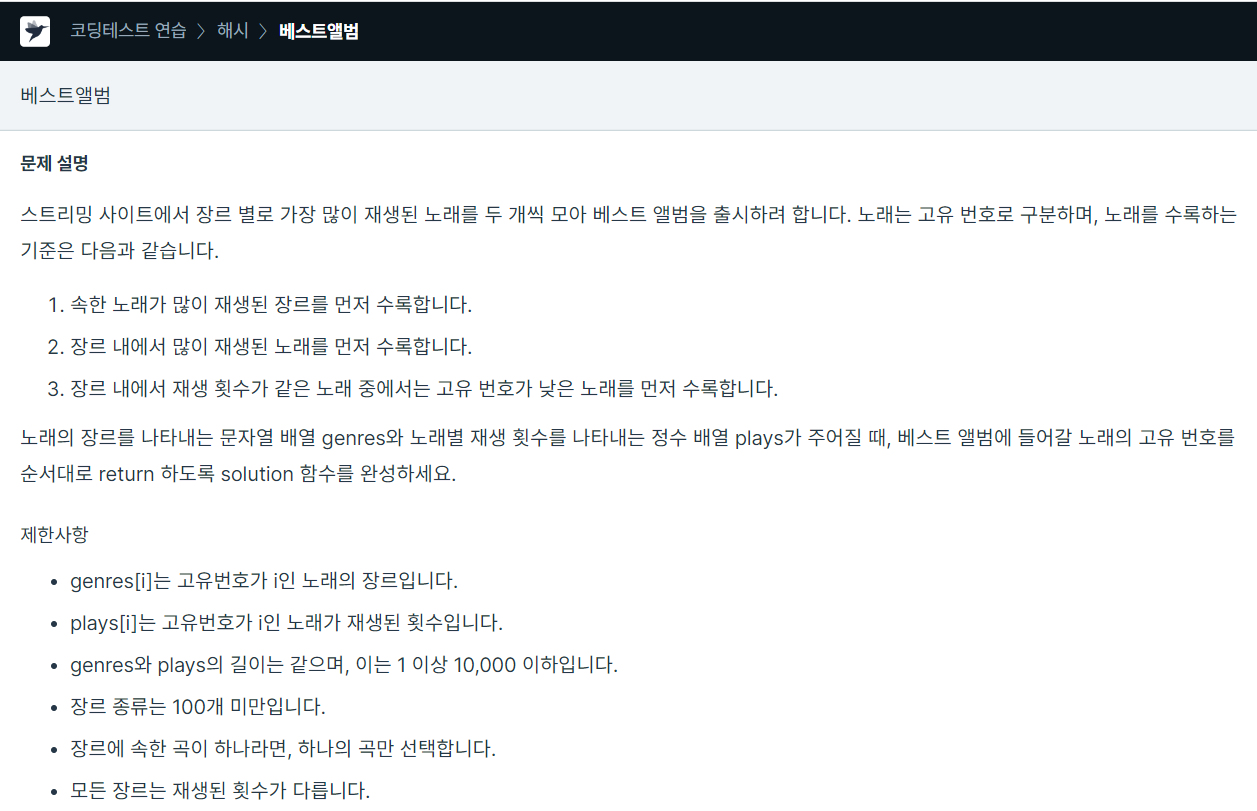
딕셔너리 자료구조를 통해 해결한 문제장르를 key 값으로 해서 딕셔너리를 만든다. value느 리스트로 해서 첫번째 인덱스는 해당 장르의 총 재생횟수를 저장하고 그다음 요소에 각 노래에 인덱스와 재생횟수를 저장저장 후에 총 재생횟수로 정렬하고 각 장르별 재생횟수로 정렬
87.프로그래머스 / 불량 사용자 / python
dfs를 통해 해결한 문제몇가지 경우의 수가 있는지를 물어보는 문제이므로 모든 경우를 찾아야 한다. 모든 경우를 탐색할 때는 dfs 알고리즘을 선호해서 dfs를 통해 문제를 해결했다.탐색하면서 uesr_id와 banned_id가 일치하는지 확인하고 일치한 갯수가 ban
88.백준 / 1753 / 최단경로 / python

다익스트라 알고리즘은 시작점으로 부터 나머지 정점까지 최단거리를 구할 때 사용하는 알고리즘으로 bfs와 구조는 비슷하지만 일반 리스트가 아닌 heapq를 사용하는 것에 차이가 있다.heapq에서 정렬되는 기준은 가중치이다. 가중치를 heapq로 사용함으로써 시작 정점에
89.백준 / 1504 / 특정한 최단 경로 / python
1번 노드에서 정점노드까지 가는 길에 반드시 주어지는 두 노드를 지나야한다.반드시 두 노드를 지나게 하는 방법은 시작점의 다익스트라 뿐 아니라 주어진 두 노드를 시작점으로 하는 다익스트라를 각각 구해준 후 두 노드를 지나는 경로를 직접 구해주면 된다.즉 시작점 -> v
90.백준 / 13549 / 숨바꼭질 3 / python
처음 시도 코드우선 다익스트라 알고리즘으로 해결이 가능해 보여서 다익스트라 알고리즘을 적용해서 풀었었다. 주어진 예제에 대해서는 맞았지만 제출 했을 때 indexError가 났다.이유를 생각해보니 k보다 n이 클 때 당연히 indexError가 난다.수정이번에는 Ind
91.백준 / 미확인 도착지 / python
다익스트라 문제 중 특정한 최단 경로와 굉장히 유사한 문제예술가는 반드시 시작점으로부터 최단경로로 이동해야 하며 g, h 사이에 있는 도로를 반드시 지나야한다.즉 g, h 노드를 지나면서 목적지 후보에 도착한 값이 시작점에서 목적지 후보에 도착한 값과 똑같으면 가능한
92.백준 / 11657 / 타임머신 / python
벨만-포드 알고리즘벨만-포드 알고리즘은 간선 중에 음수가 있을 시 사용하는 알고리즘이다.다익스트라 알고리즘으로 음수 가 있는 간선에서의 최단거리를 구하게 되면 음수에 의해 계속해서 수치가 작아지게되어 해당 경로에서 무한 루프에 갇히게 될 수가있다.벨만-포드 알고리즘은
93.백준 / 11404 / 플로이드 / python
다익스트라 풀이 플로이드 와샬 풀이 두개 알고리즘 메모리, 시간 비교 이 문제에서의 다익스트라 알고리즘의 시간 복잡도는 N^2 O(Elogn)이고 플로이드 와샬 알고리즘의 시간 복잡도는 O(n^3)이다. 이 문제의 경우
94.백준 / 1956 / 운동 / python
플로이드 와샬 알고리즘을 통해 해결할 수 있는 문제이 문제는 최단 사이클을 구해야 한다. 즉 모든 노드에 대해서 최단 경로를 구한 후 그 중 사이클이 가능한지 여부와 최단 사이클을 구해야한다.노드의 갯수가 적으므로 이 플로이드 와샬 알고리즘을 통해 모든 노드에서의 최단
95.백준 / 1956 / 운동 / python
플로이드 와샬 알고리즘을 통해 해결할 수 있는 문제이 문제는 최단 사이클을 구해야 한다. 즉 모든 노드에 대해서 최단 경로를 구한 후 그 중 사이클이 가능한지 여부와 최단 사이클을 구해야한다.노드의 갯수가 적으므로 이 플로이드 와샬 알고리즘을 통해 모든 노드에서의 최단
96.백준 / 3273 / 두 수의 합 / python
투 포인터 알고리즘 문제리스트의 처음과 끝을 인덱스로 갖는 두 개의 변수를 통해 정답을 구한다.두 인덱스의 리스트 값에 따라 인덱스를 변경하면서 정답을 구한다.
97.백준 / 2470 / 두 용액 / python
투 포인트 알고리즘을 사용해서 진행했으며 진행 결과를 딕셔너리에 담았다.절대 값을 key로 했기 때문에 key 중에 최소 값이 0에 가장 가까운 답이 된다.
98.백준 / 1806 / 부분합 / python
누적 합과 투 포인터 알고리즘을 사용해서 해결한 문제이 문제의 경우 아무리 투포인터를 사용한다고 해도 합을 매번 구하려면 연산량이 너무 많아진다.따라서 누적합을 미리 구해놓고 투 포인터를 사용하여 해결한다.
99.백준 / 1644 / 소수의 연속합 / python
소수 구하는 방법은 에라토스테네스의 체 알고리즘으로소수가 되는 경우를 찾는 거은 누적합과 투 포인터 알고리즘으로 해결했다.오랜만에 보는 "애라토스테네스의 체 알고리즘"n 크기의 true 배열을 만들고 소수인 경우는 true로 두고 해당 소수의 배수를 모두 False로
100.백준 / 12852 / 1로 만들기 2 / python
첫 시도방문여부를 확인하는 리스트를 만들어 불필요한 연산 제거
101.백준 / 14002 / 가장 긴 증가하는 부분 수열 / python
기존의 LIS 문제에서 그리디 알고리즘을 적용한 문제가장 긴 증가하는 부분 수열을 앞에서부터(작은 수 부터)그대로 출력하게 되면 값이 전혀 다르게 나온다.예를들어 수열 3 1 2에 대한 LIS 값은 1 1 2 이다. 그래서 앞에서 부터 출력하게되면 3, 2가 나오게된다
102.백준 / 14003 / 가장 긴 증가하는 부분 수열 / python
LIS의 시간복잡도인 O(n^2)로는 해결할 수 없는 문제이 문제의 경우 이분탐색을 통해 풀어야 한다.이분탐색 알고리즘을 사용해 풀어가면서 역추적도 해야하므로 수열 정보를 저장할 리스트도 필요하다.이분탐색은 최대 값을 구하는것이 아니므로 Lower Bound 방식으로
103.백준 / 13913 / 숨바꼭질 4 / python
첫 시도
104.백준 / 11779 / 최소비용 구하기 2 / python
정답이긴 하지만 이 방식은 노드를 계속해서 저장하고 있으므로 메모리를 비효율적으로 사용하게 된다. 이전에 사용한 방법처럼 지나온 경로를 저장하는 리스트를 사용하는 방식으로 해결후 방법이 메모리와 시간 면에서 좀더 효율적인걸 볼 수 있다.
105.프로그래머스 / 보석 쇼핑 / python
첫시도테스트 케이스는 넘어갔지만제출에서 처참한 결과가 나왔다.정확성도 맞지 않을 뿐더러 효율적이지도 않다고한다.....gems 배열 크기가 최대 100,000 이므로 위 코드의 시간 복잡도인 nO(logn)으로 해결 가능하다고 생각했는데 히든 케이스는 더 큰 크기의 리
106.프로그래머스 / 스티커 모으기(2) / python
처음 시도 방법dp와 bfs로 시도 했었다.테스트 케이스에 대해서는 맞았지만 히든 케이스에 대해서는 처참한 결과였다. dp 점화식을 잘 작성하면 굳이 dfs 필요없이 그냥 현재 상태에서의 최대값만을 저장해 나갈 수 있어서 메모리와 시간 둘다 아낄 수 있다.히든 케이스에
107.프로그래머스 / 징검다리 건너기 / python
첫 시도 코드처음에는 위와 같이 완전탐색 방식으로 풀었었다.결과는 효율성에서 0점이다. stones을 한 번씩 순회하면서 1씩 빼는 방법으로 하기에는 stones의 원소 최대 값이 너무 크다... 당연한 결과이다.이분탐색으로 풀이이 문제는 최소값을 찾는 문제이므로 이분
108.프로그래머스 / 가장 먼 노드 / python
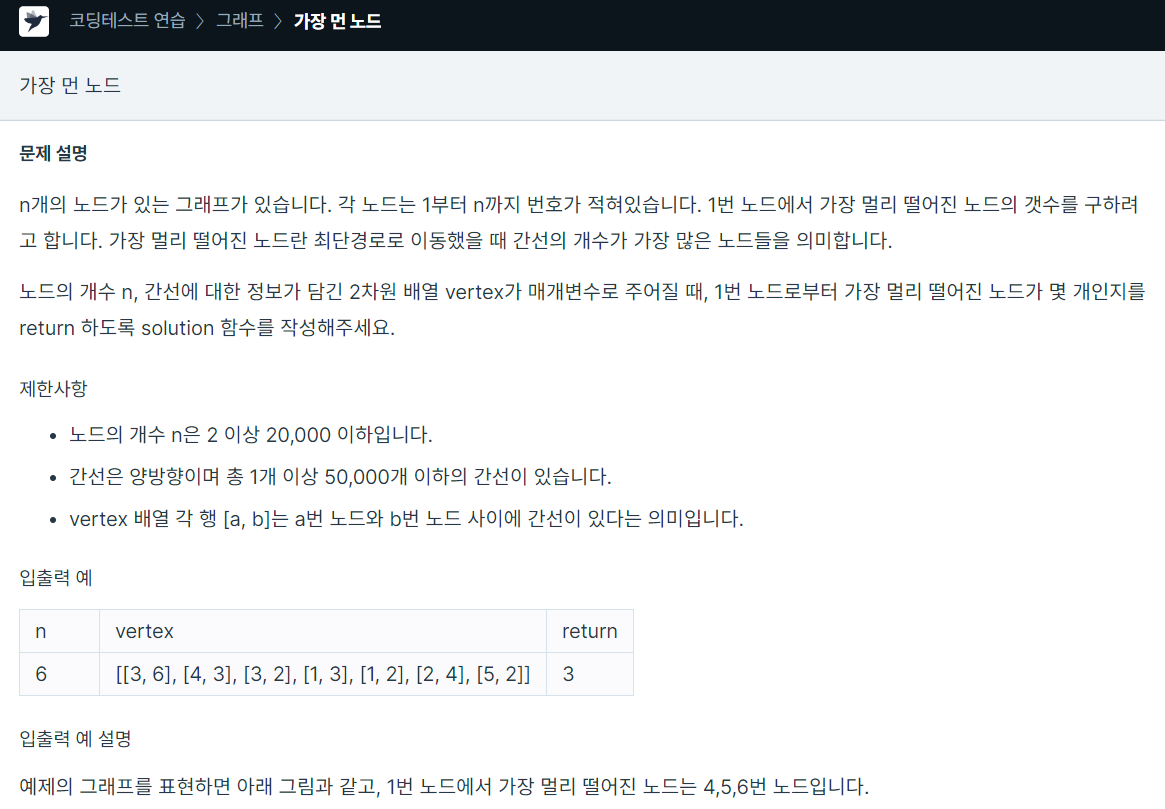
간단한 dfs 그래프 문제어렵지 않은 문제였다.
109.프로그래머스 / 섬 연결하기 / python
다른 분들이 많이 사용한 Kruskal 알고리즘Kruskal 알고리즘을 알고나면 어렵지 않게 풀 수 있는 문제이다.알고리즘 자체도 이해하기 쉬운 편이였다. 하지만 처음 떠올린 다익스트라 알고리즘으로 풀고 싶었다.다익스트라 알고리즘으로 해결한 코드기본적인 다익스트라와 다
110.프로그래머스 / 쿼드압축 후 개수세기
111.프로그래머스 / 택배상자 / python
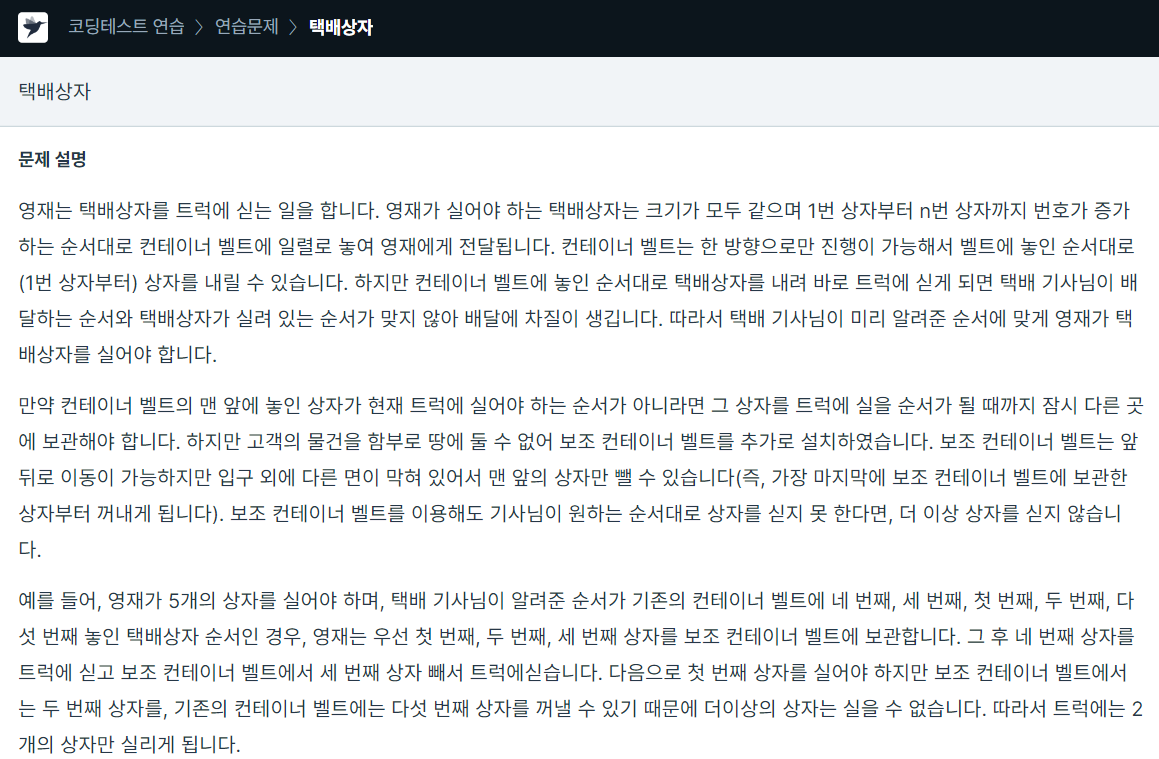
stack을 사용해서 해결한 문제현재 컨테이너 벨트에 있는 상자보다 트럭에 실어야하는 상자의 번호가 작다면 그 번호가 될때까지 임시 컨테이너 벨트에 옮긴다. -> 스택에 담는다.그 다음 스텍에서 뺀 후 다음 트럭에 실어야할 상자 번호를 확인한다.만약 계속해서 스택의 마
112.프로그래머스 / 큰 수 만들기 / python
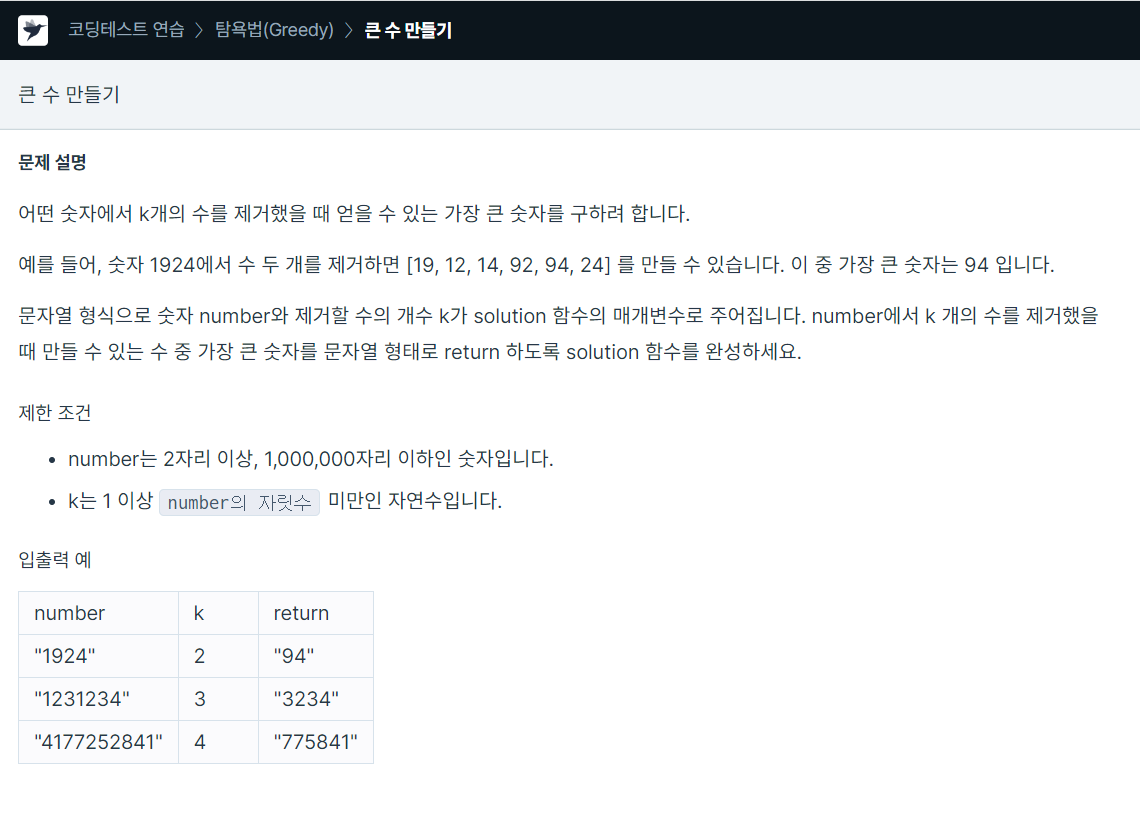
처음에넌 itertools의 combination을 사용해서 시도했다.당연하게도 히든케이스에 대해서 시간 초과가 많이 발생했다그 다음은 도저히 떠오르는 방법이 없어서 인터넷으로 검색해서 stack에대한 힌트를 얻고 바로 위와 같이 작성했다.stack이 채워진 상태이고
113.프로그래머스 / 삼각 달팽이 / python
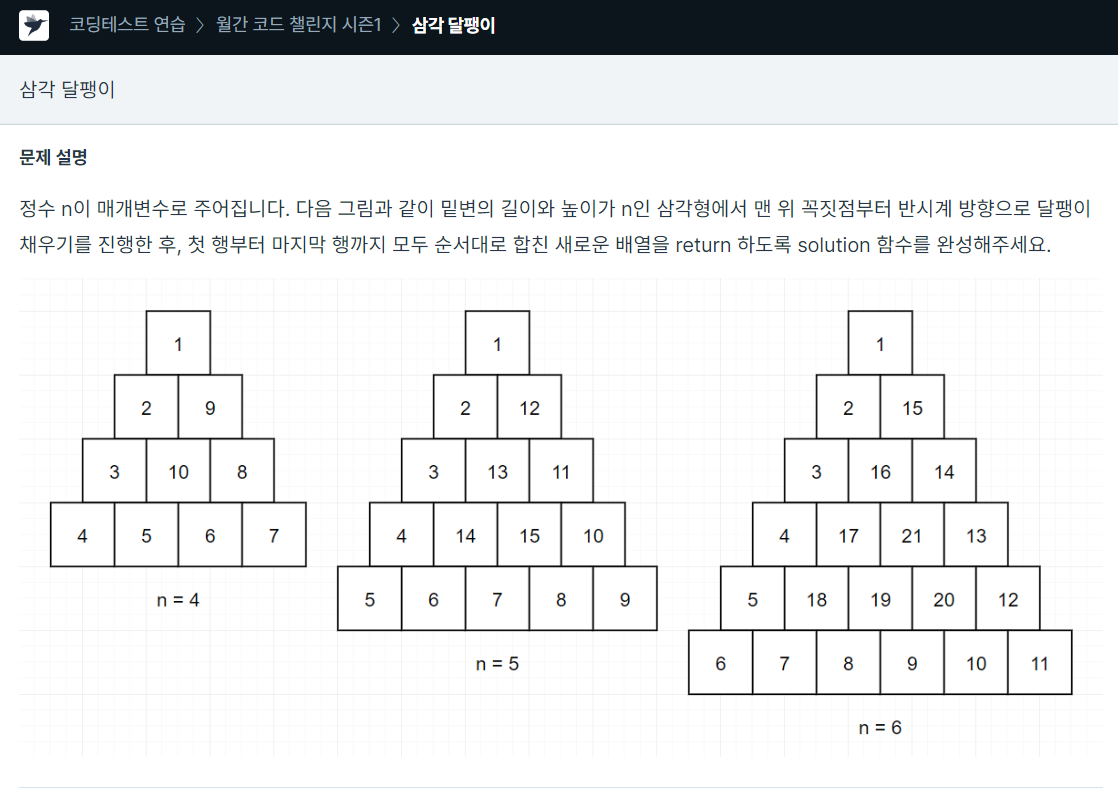
단순 구현 문제
114.프로그래머스 / 124 나라의 숫자 / python
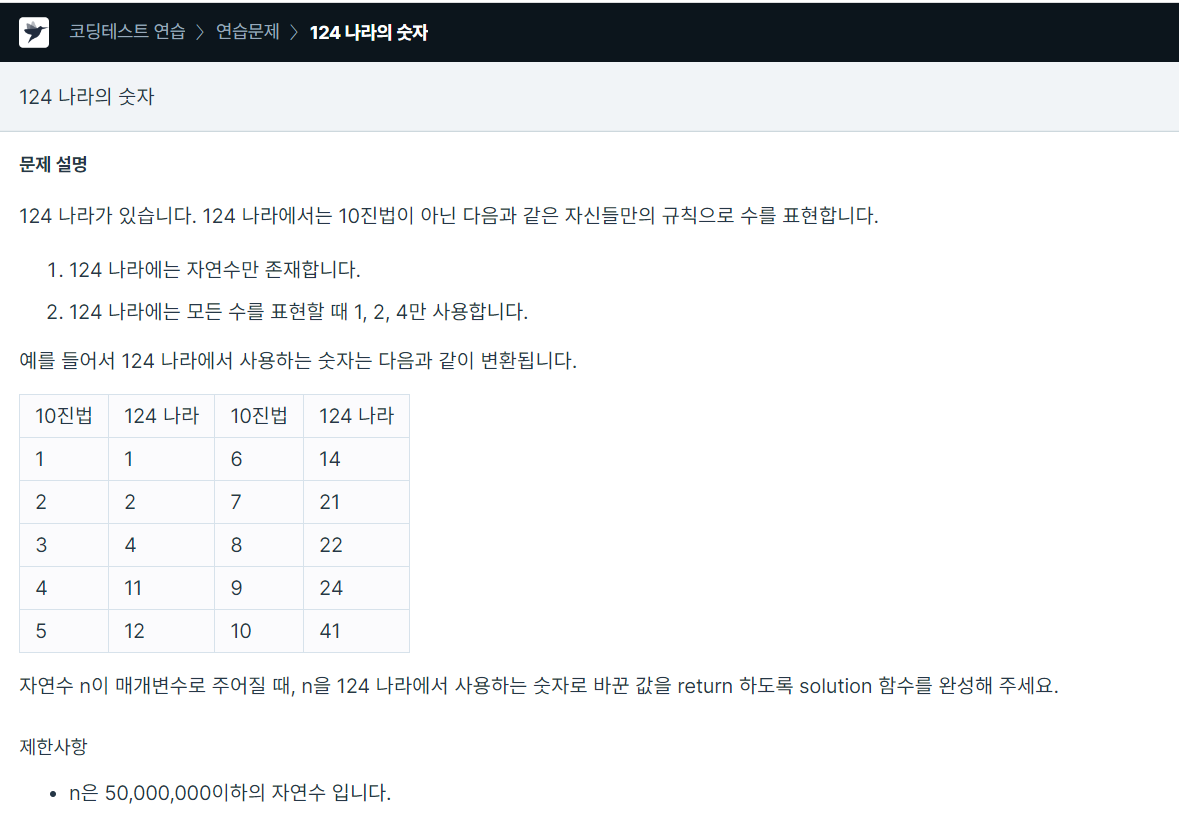
알고보면 진짜 단순한 문제이지만 스스로 풀진 못했다....
115.프로그래머스 / 연속된 부분 수열의 합 / python
처음 시도한 방법누적 합을 통해 처음에 시도했다.누적 합이기 때문에 시간 복잡도가 O(nlong)라고 생각해 충분히 풀 수 있다고 판단했지만 히든 케이스에서 많은 케이스가 시간 초과가 나왔다. 누적합을 사용했지만 2중 for문 조건을 보면 누적 합에서 k 보다 큰 경우
116.프로그래머스 / 두 큐 합 같게 만들기 / python
그리디 알고리즘과 deque를 사용해서 해결한 문제이 문제의 핵심은 두 개의 q를 같게하기 위해서 높은 쪽의 큐에서 pop 해서 작은 쪽에 append하는 것이 최적의 해라는 것이다.이 개념만 떠울리면 쉽게 해결할 수 있다.처음에 시간 초과가 났었는데 s1, s2 su
117.프로그래머스 / 메뉴 리뉴얼 / python
itertools를 사용한 구현문제주어진 제한사항의 배열 크기들이 굉장히 작기때문에 완전탐색으로 해결가능하다. 완전 탐색으로 itertools의 combinations를 사용
118.프로그래머스 / 무인도 여행 / python
dfs혹은 bfs로 해결 가능한 문제dfs로 풀 때는 재귀 조건때문에 setrecursionlimit를 설정해줘야한다.
119.프로그래머스 / [3차] 방금그곡 / python
빡 구현 문제주의 할 점은 #을 바꾸지 않으면 틀린 답이 나온다.
120.프로그래머스 / 괄호 변환 / python
121.프로그래머스 / 수식 최대화 / python
permutations 조합을 사용해서 해결한 구현문제우선 주어진 문자열에 대해 숫자와 연산자를 분리하고 차례대로 리스트에 저장한다. 분리할 때 연산자는 set에 저장한다.set에 저장한 연산자를 permutations를 통해 우선순의가 다른 모든 경우의 조합을 구한다
122.프로그래머스 / 전력망을 둘로 나누기 / python
주어진 조건을 보면 n이 최대 100개이기 때문에 완전 탐색으로 해결 가능한 문제이다. 완전 탐색 방법은 주어진 전선에 대해 하나씩 뺀 상태로 bfs를 진행한다. 이렇게 되면 시간 복잡도는 간선에 대한 2중 for문 \* bfs 시간 복잡도이므로 대략 n^3이다. 충분
123.프로그래머스 / 배달 / python
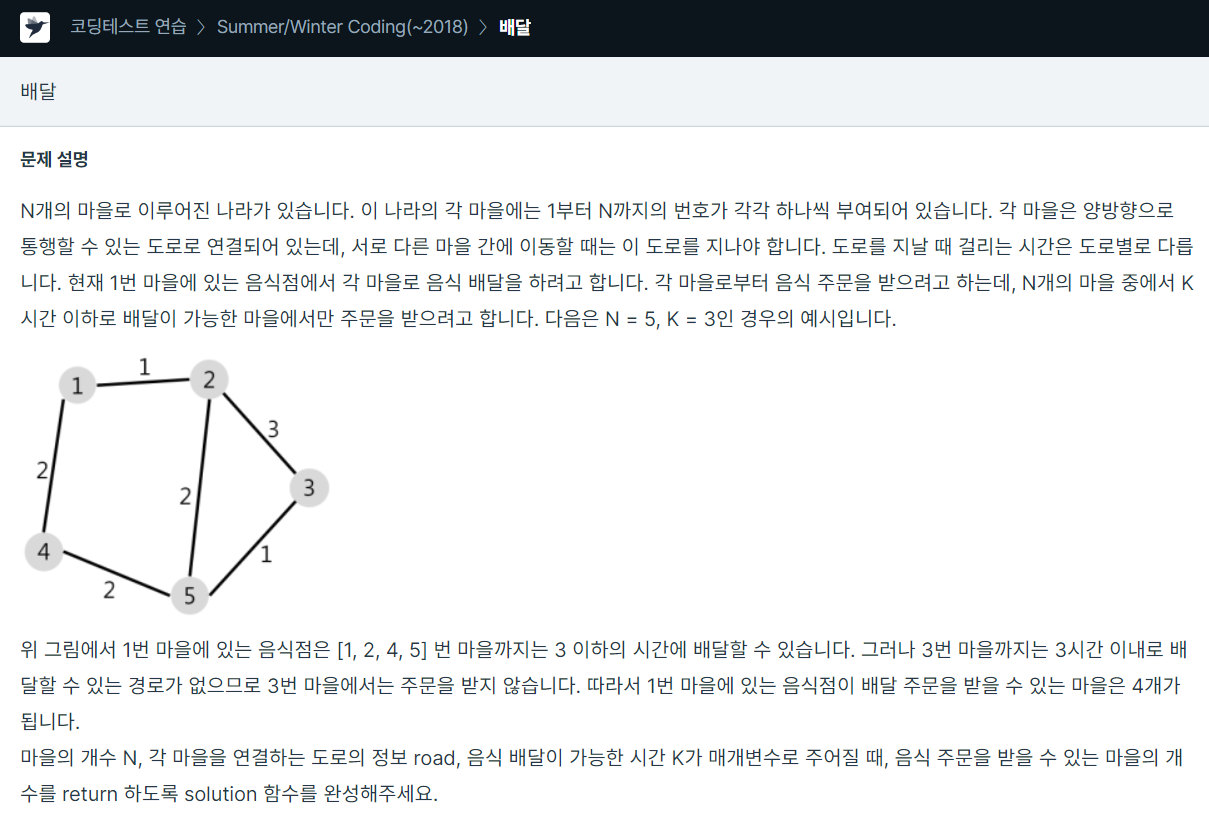
다익스트라 알고리즘 문제다익스트라 알고리즘을 숙지하고 있다면 바로 풀 수 있는 문제 그 외에 특별히 생각해야할 점은 따로 없는 문제
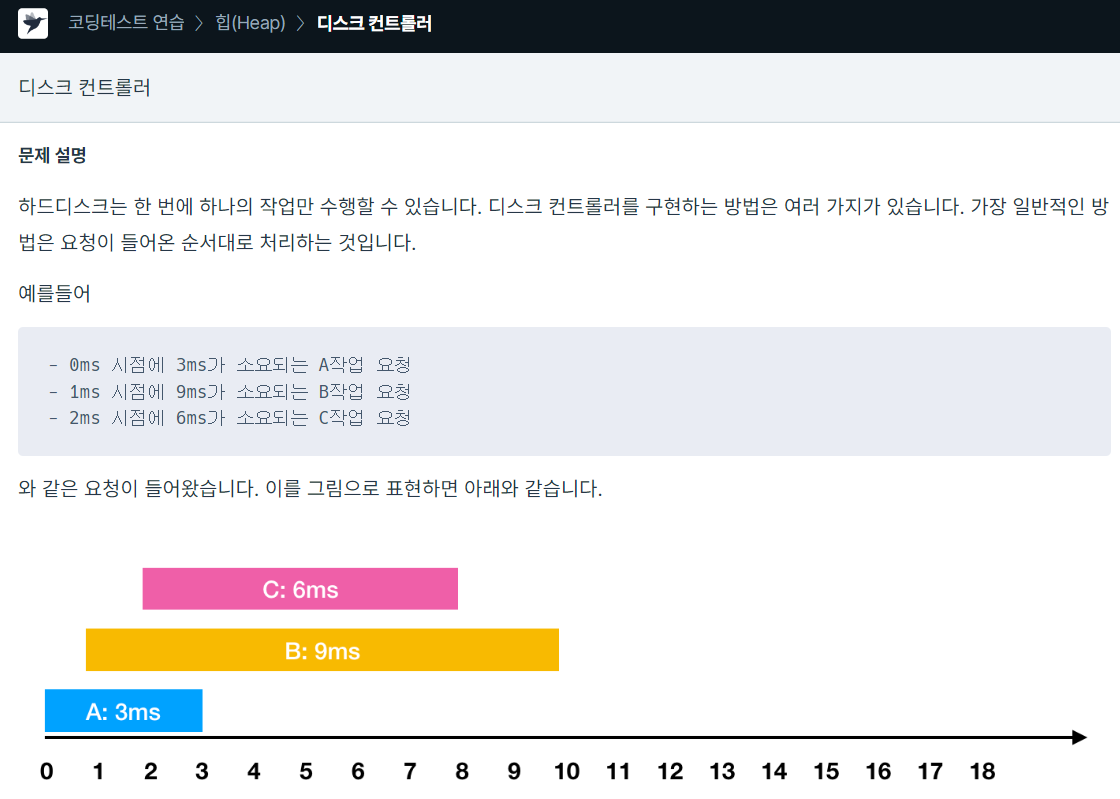
124.프로그래머스 / 디스크 컨트롤러 / python
125.프로그래머스 / 가장 큰 정사각형 찾기 / python
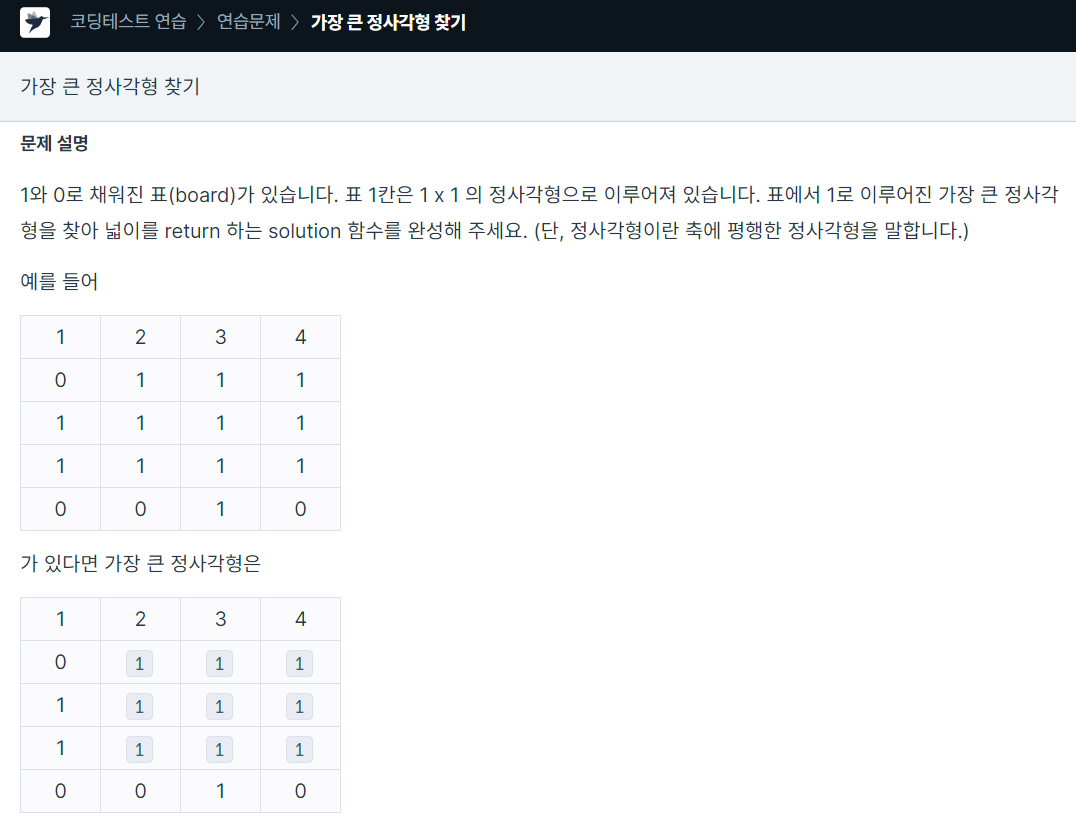
dp 알고리즘으로 해결한 문제완전탐색으로 문제를 해결할시 시간 복잡도는 O(N^2logn)이다. 최대 크기가 1000 \* 1000 이므로 완전탐색 방법으로는 불가능하다.dp로 해결해야하는데 주어진 board가 1일때 좌, 상, 좌상의 최소값에서 1을 더해준다. ->
126.프로그래머스 / 거리두기 확인하기 / python
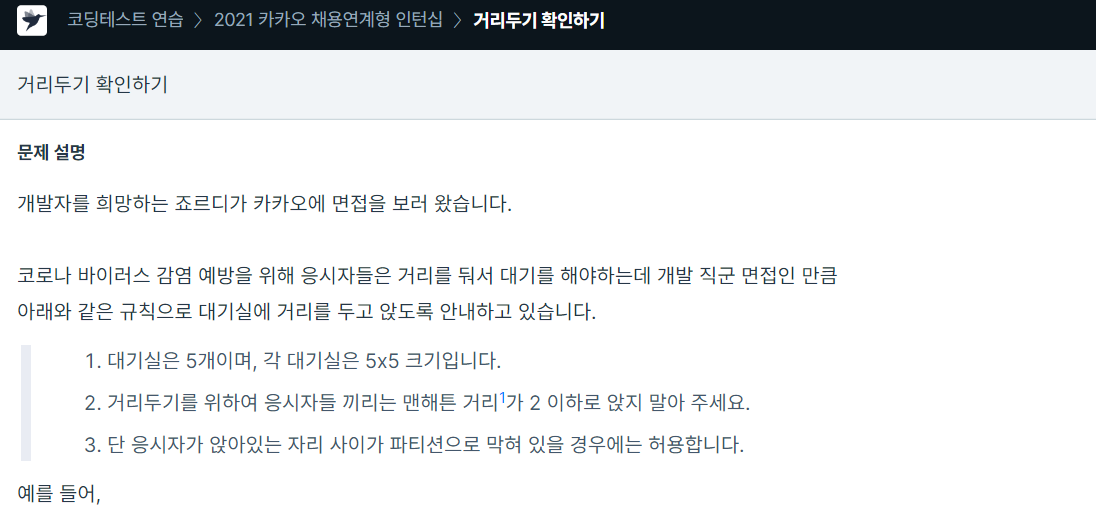
주어진 배열의 행, 열의 크기가 5이므로 완전탐색으로 풀이완전탐색은 bfs로 수행 -> P에서 bfs를 진행하는데 P를 만날때 진행 깊이가 2 이하이면 거리두기가 되지 않은 상태이므로 answer에 0을 저장한다.
127.프로그래머스 / 합승 택시 요금 / python
<img src="https://velog.velcdn.com/images/mang0206/post/fabce12c-92bc-4bd4-a612-619d9c9caa25/image.png" vertical-ali
128.프로그래머스 / 경주로 건설 / python
다익스트라 알고리즘으로 푼 문제일반적인 bfs로 풀라면 풀 수 있겠지만 bfs로 해결 할 시 최소값을 저장하고 있을 dp가 따로 필요하다. 그렇기 때문에 다익스트라 알고리즘으로 최소 값에 대해서 우선 계산할 수 있게 끔 해준다.
129.백준 / 17942 / 알고리즘 공부 / python

힙 자료구조를 통해 해결할 수 있는 문제항상 최소 값을 구하면서 진행해야하기 때문에 힙 사용현재 알고리즘 과목에 대해서 연계되어 빼야할 과목이 있는 경우 빼고 그 값을 저장함과 동시에 뺀 다음에 heap에 넣어 해당 과목에 대해 변경을 반영해 준다.처음 방식의 코드로
130.백준 / 14502 / 연구소 / python
우선 벽 3개를 세우기 위한 dfs 진행 벽 3개의 경우 주어지는 연구소 크기가 크지 않으므로 완전 탐색으로 진행이 가능하다.dfs를 통해 벽 3개를 세웠다면 이제 bfs를 통해 바이러스를 감염시키고 0의 갯수를 센다.bfs와 dfs를 잘 이해하고 있다면 어럽지 않은
131.프로그래머스 / 1865 / 웜홀 / python
처음시도 코드벨만 포드 알고리즘으로 시도 주어진 출발 지점이 없기 때문에 for 문을 통해 모든 노드를 시작점으로해서 탐색시간초과가 발생한다....시간 복잡도를 생각해보면 모든 노드에 대해서 탐색을 시작하므로 (n x 2m x w) x n이 된다. -> 500 x 50
132.프로그래머스 / 1655 / 가운데를 말해요 / python
heap 알고리즘을 사용하여 해결한 문제왼쪽 힙은 최대힙, 오른쪽 힙은 최소힙으로 하고 크기 비교는 항상 왼쪽 heap을 기준으로 하면 가운데 값을 계속 출력할 수 있다. 크기는 같거나 왼쪽이 하나 더 커야하므로 힙에 넣었을 때 크기를 비교해 줘서 맞춰준다.
133.백준 / 1398 / 동전 문제 / python
dfs로 해결한 문제
134.백준 / 1028 / 다이아몬드 광산 / python
첫 시도 코드완전 탐색 방식으로 시도 이중 for문을 돌면서 해당 좌표에서 1크기의 다이아 부터 최대 750 크기의 다이아를 계속 확인 하는 방법시간복잡도를 생각해보면 n^3으로 판단된다. 시간 초과가 발생한다.dp를 사용한 방법우선 대각선에 대한 누적 합을 저장한다.