
- 전체보기(27)
- 하나와영(6)
- NLP(5)
- video compression(5)
- multi-modal(4)
- Learned Image Compression(4)
- 논문리뷰(2)
- clip(2)
- BEiT(2)
- transformer(1)
- 데이터네트워크(1)
- Attention(1)
- Naver(1)
- VQA(1)
- 고전 코덱(1)
- Video Frame Interpolation(1)
- mode(1)
- 고려대 김현우 교수님(1)
- vision-nlp(1)
- 딥러닝(1)
- Optical Flow(1)
- LaneDetection(1)
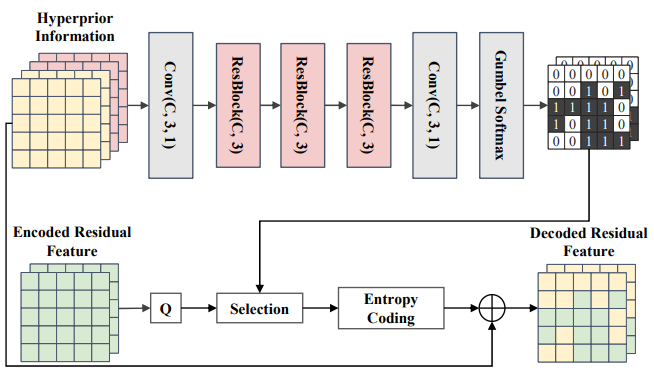
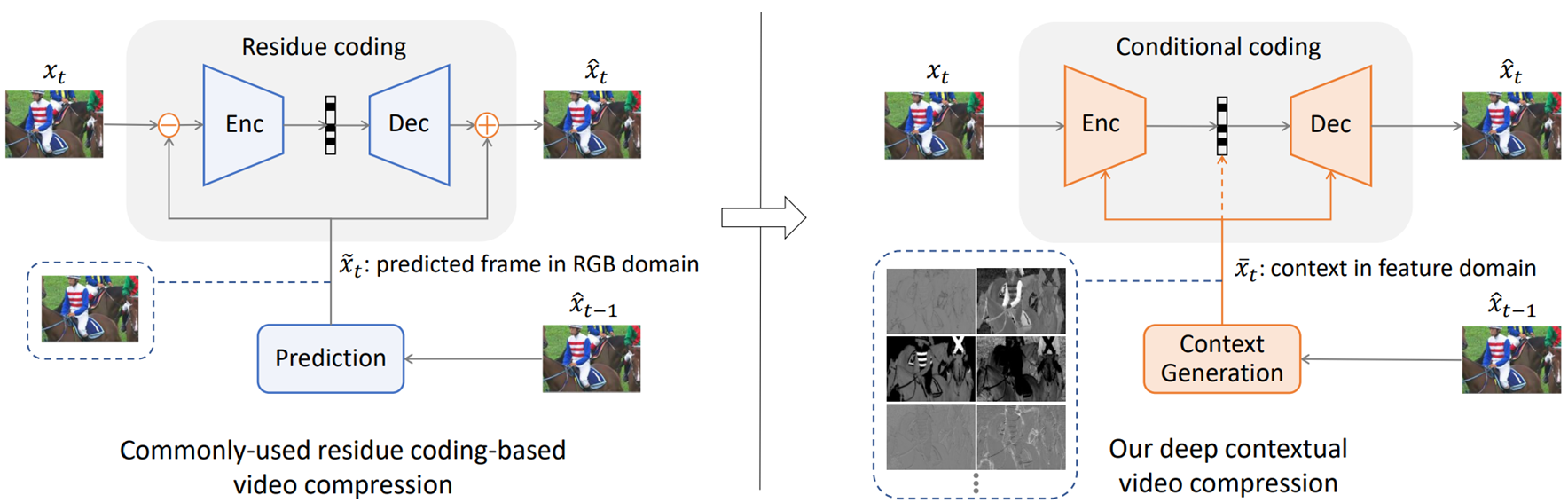
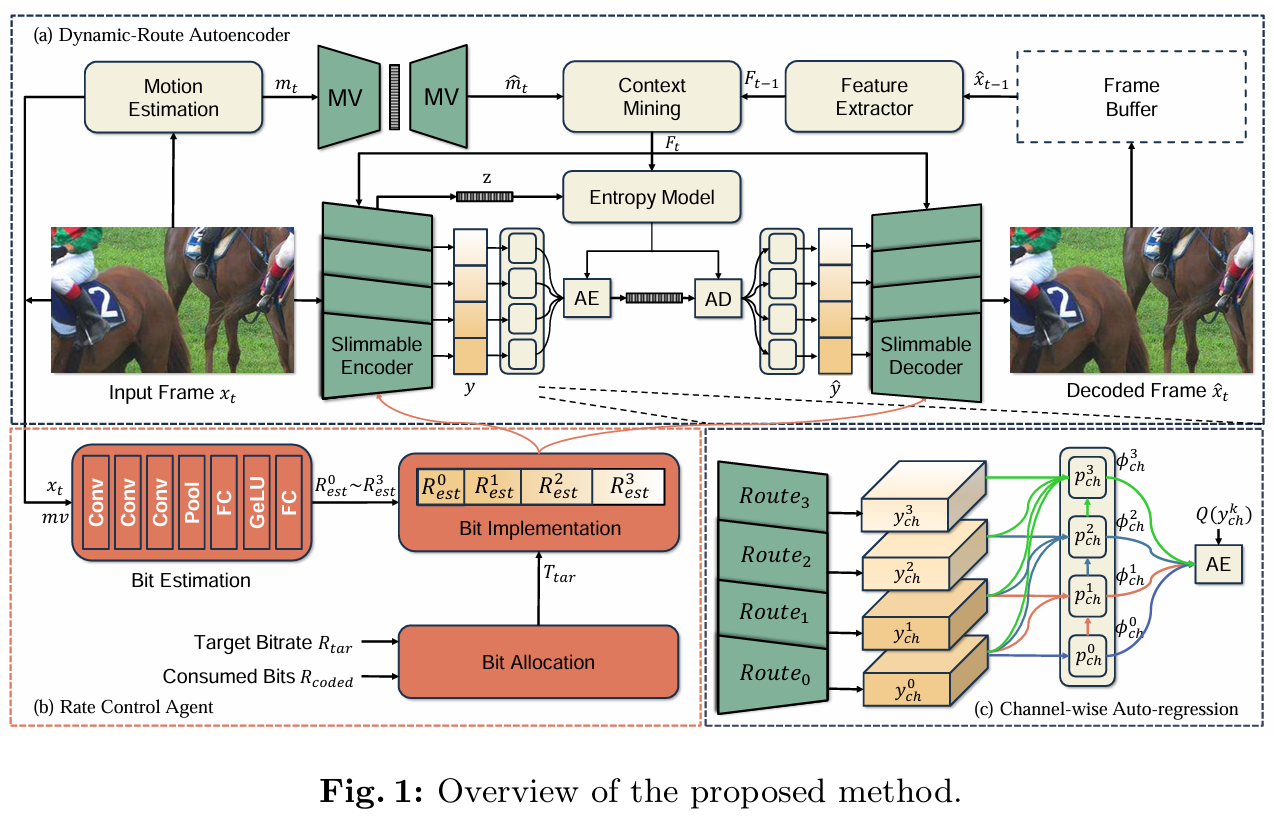
[논문 리뷰] Learned Rate Control for Frame-Level Adaptive Neural Video Compression via Dynamic Neural Network (ECCV 24)
논문 리뷰 ECCV 2024 video compression

[논문 리뷰] Learned Image Compression with Hierarchical Progressive Context Modeling (ICCV 2025)
논문 링크: https://arxiv.org/abs/2507.19125코드 링크: https://github.com/lyq133/LIC-HPCM/tree/masterDCVC-TCM을 쓴 Microsoft 팀에 계시던 저자분 두분이 학교에서 지도하신 논
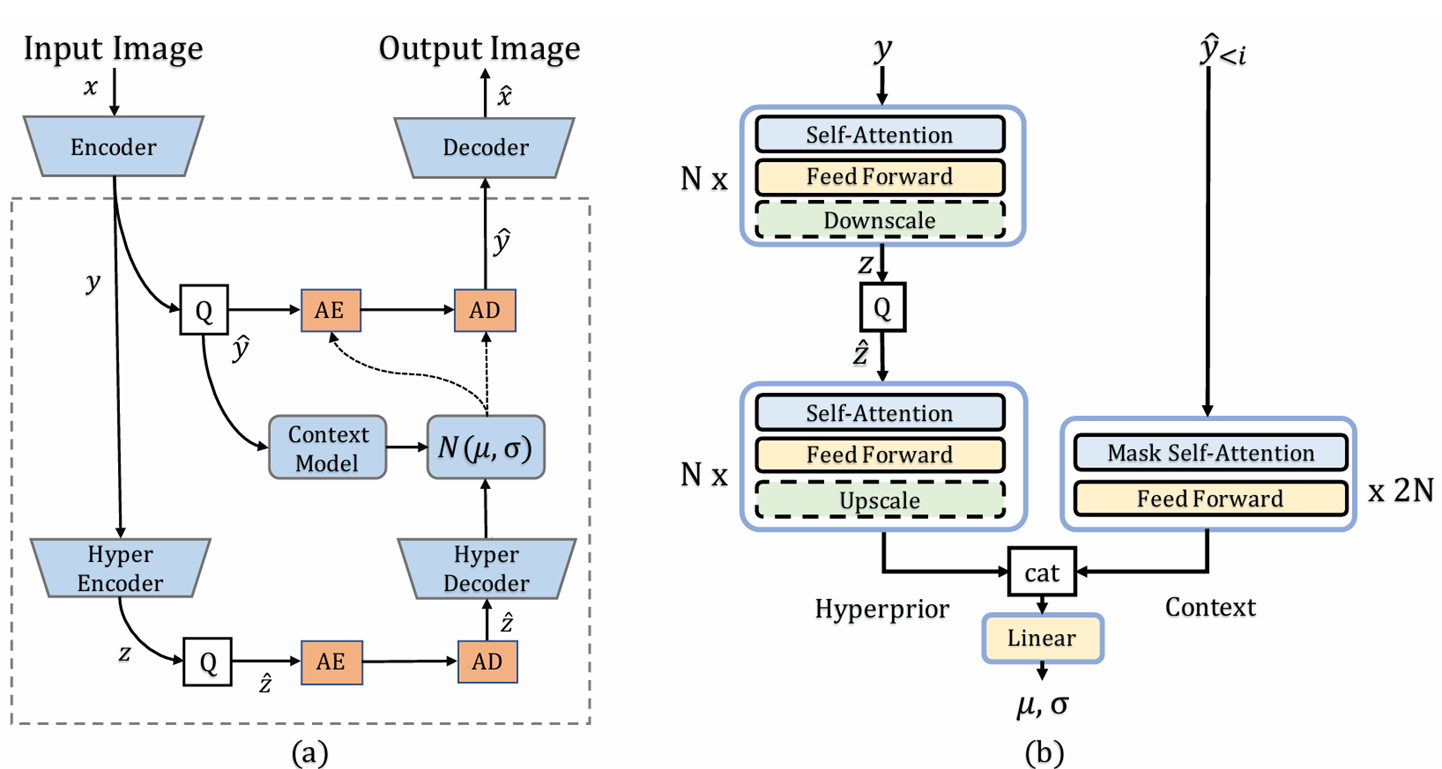
[논문 리뷰] Entroformer: A Transformer-based Entropy model for Learned Image Compression (ICLR 2022)
이 논문 역시 transformer 구조를 활용한 entropy model이다. 구조 자체는 hyperprior 기반의 autoregressive entropy model 과 동일하게, 인코더로 얻은 latent y 중 이미 전송한 $\\hat{y}$과 hyper e

[논문 리뷰] Learning Accurate Entropy Model with Global Reference for Image Compression (ICLR 2021)
해당 논문 이전의 Entropy model들은 모두 CNN 기반의 구조여서 local한 redundancy만 고려하고, global redundancy를 고려하지 못한다는 문제의식에서 시작한다.CNN 구조였던 Entropy model에 global 처리를 추가하는 첫
H.264 AVC
H.264 논문주로 보던 딥러닝 논문과는 다르게 엄청 자세한 알고리즘까진 언급이 안되어 있다. 아마 기존 고전 코덱들에서 쌓아 올려온 기술이기에 그런듯 하다. 인코더: Prediction -> transformation(ex. DCT) -> encoding(to bit
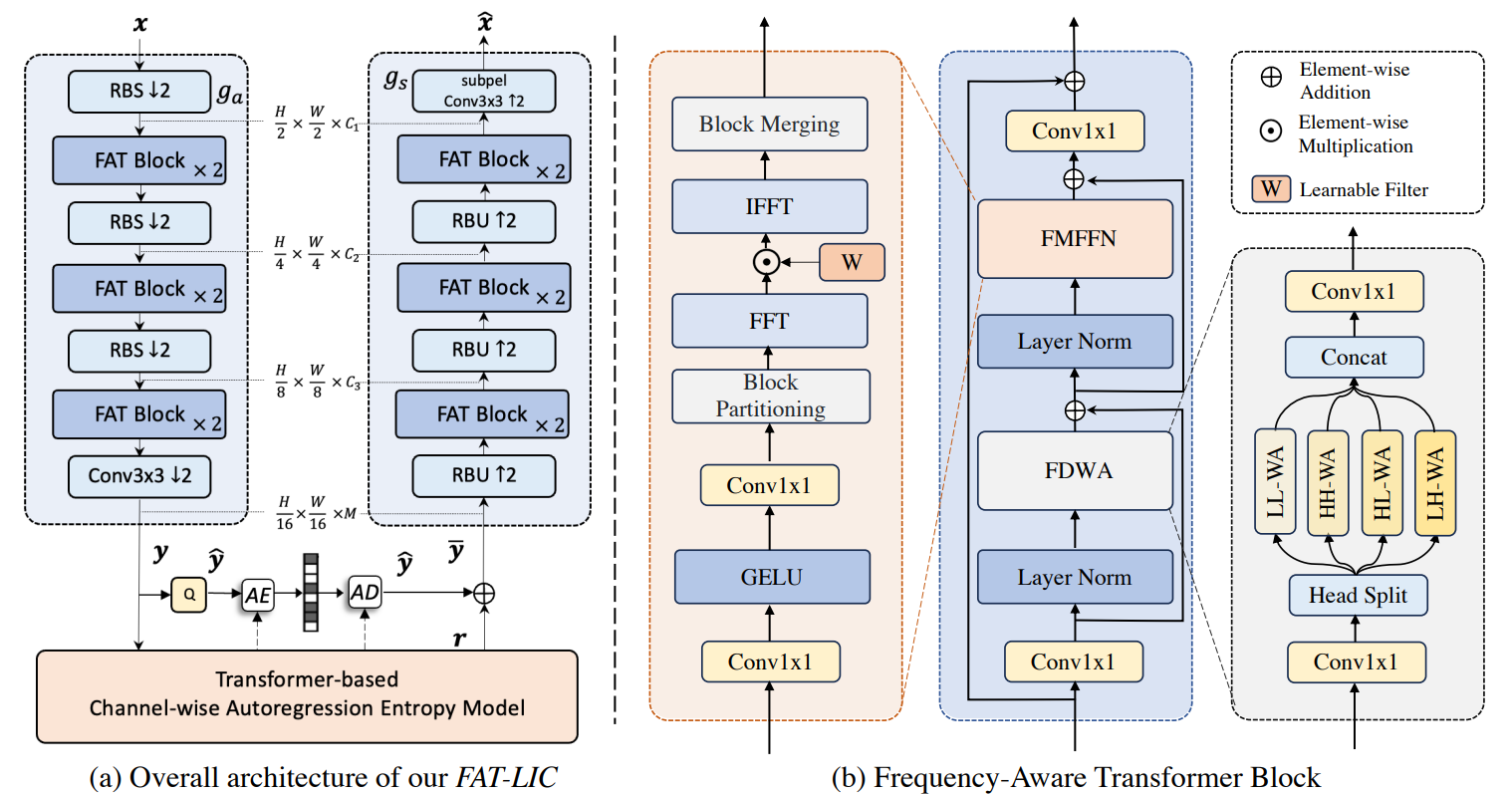
[논문 리뷰] Frequency Aware Transformer for Learned Image Compression (ICLR 24)
FTIC (ICLR 2024)ICLR 2024 논문으로 딥러닝을 이용한 이미지 압축 논문이다. (코드 O)인코더, 디코더 내에 Swin transformer의 4가지 형태로 윈도우 설정인코더 디코더 FFN 부분에 주파수 변환 -> linear -> 역변환 수행Entro
Video Compression 관련 논문
Optical FlowSPyNet: Spatial Pyramid Network for Optical FlowPWC-Net: CNNs for Optical Flow Using Pyramid, Warping, and Cost Volume RAFT: Recurrent All
3dLane Detection 논문들
데이터셋OpenlaneApolloSimOnce 등3d lane detection 구조 논문3D-LaneNet: End-to-End 3D Multiple Lane DetectionGen-LaneNet: A Generalized and Scalable Approach fo
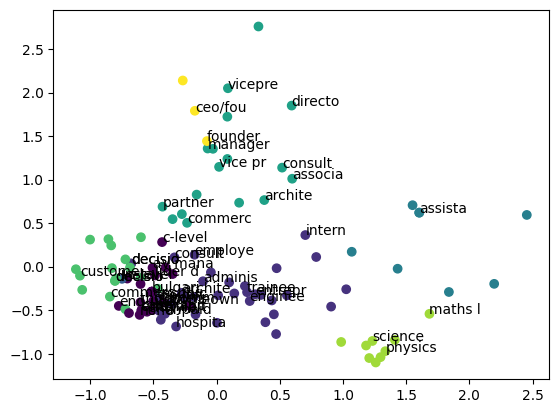
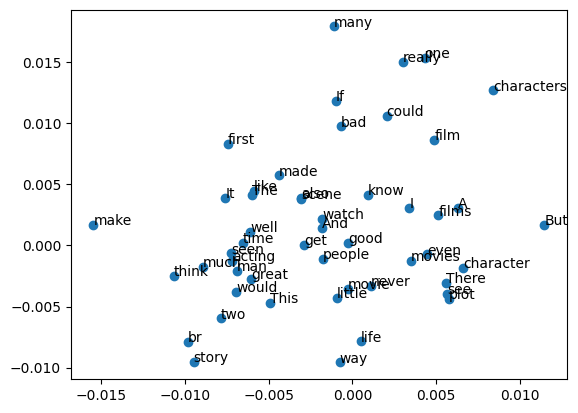
텍스트 임베딩으로 Clustering 하기
keras를 활용한 word2vec pre-trained 모델을 로딩하여 IMDB 감정분석 분류문제 해결하기이 글 많이 참조했습니다.Customer Position column에 있는 걸로 예를 들겠습니다.우선 전체적인 구조는 column에 unique를 찍어봤더니 아
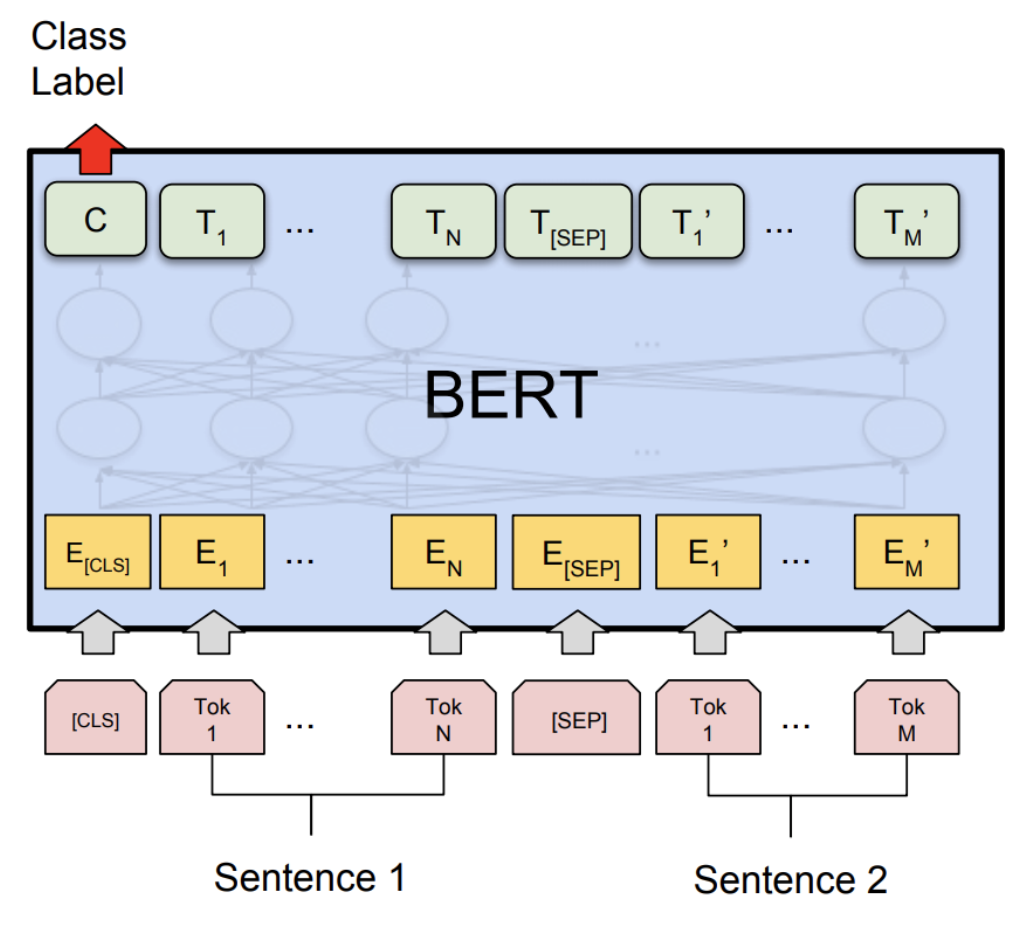
딥러닝을 이용한 자연어처리 입문 7시간 완성(6)
딥러닝을 이용한 자연어처리 입문 7시간 완성 - 메타코드M https://www.youtube.com/watch?v=Rf7wvs8ZbP4&ab_channel=%EB%A9%94%ED%83%80%EC%BD%94%EB%93%9CM 6회차는 GPT, BERT 입니다. 드디어
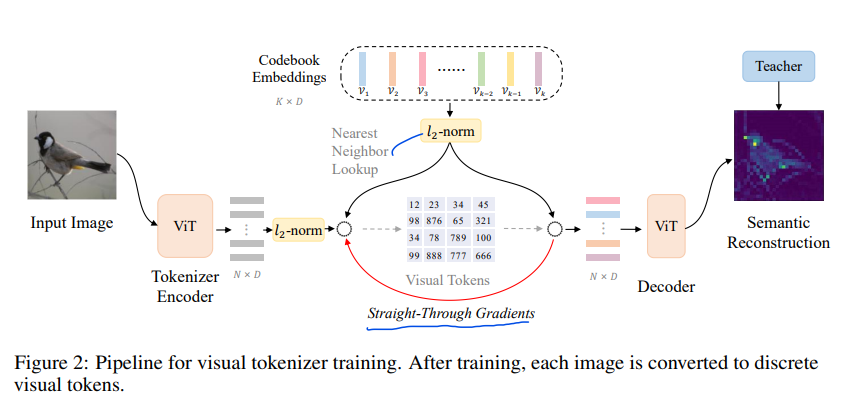
[논문 리뷰] BEIT v2: Masked Image Modeling with Vector-Quantized Visual Tokenizers
BEIT v3, v1을 읽고 읽었지만, 3개 중 가장 어려운 논문인거 같다.v1 리뷰 / v3 리뷰Knowledge Distillation이라는 처음보는 개념도 등장하는데, 일단 이 논문부터 하나씩 봐보자https://arxiv.org/abs/2208.0636
딥러닝을 이용한 자연어처리 입문 7시간 완성(5)
딥러닝을 이용한 자연어처리 입문 7시간 완성 - 메타코드Mhttps://www.youtube.com/watch?v=Rf7wvs8ZbP4&ab_channel=%EB%A9%94%ED%83%80%EC%BD%94%EB%93%9CM5회차는 attention 이론과 LS
[논문 리뷰] Visual Question Answering: A survey on Techniques and Common Trends in Recent Literature
https://arxiv.org/abs/2305.11033VQA 분야 23년 6월에 나온 survey논문이다.VQA가 뭐하는건지, 어떤 모델들이 있는지, 등 알아보자VQA는 아무래도 multi-modal task 이기에 다른 modality를 합친다는데에서 어
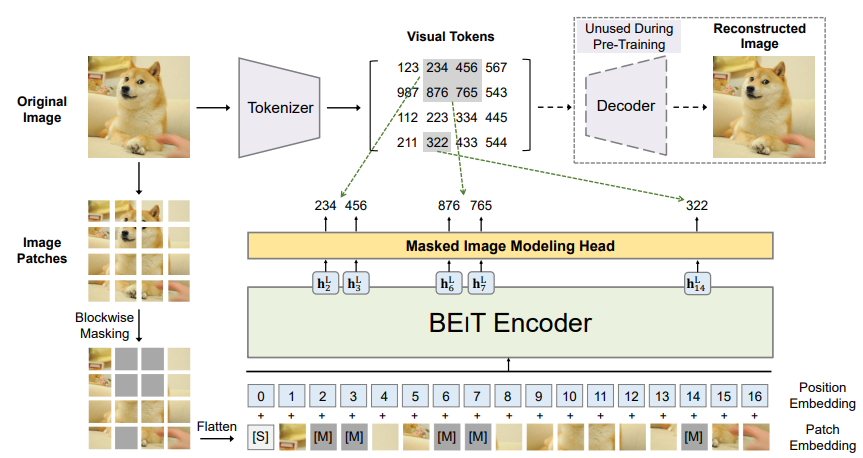
[논문 리뷰] BEIT: BERT Pretraining of Image Transformers
https://arxiv.org/abs/2106.08254Bidirectional Encoder representation from Image Transformers(BEIT)이미지를 image patches , visual tokens 이 두가지로 봐서 tr
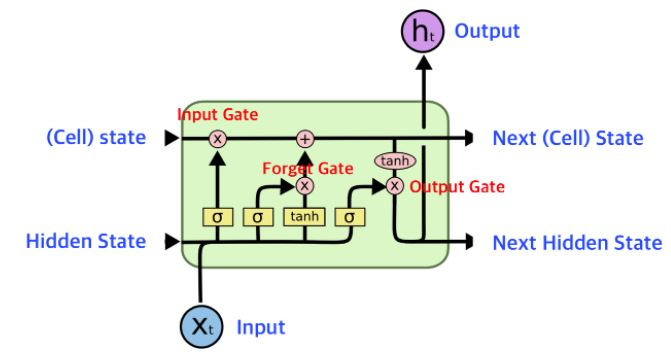
딥러닝을 이용한 자연어처리 입문 7시간 완성(4)
딥러닝을 이용한 자연어처리 입문 7시간 완성 - 메타코드Mhttps://www.youtube.com/watch?v=Rf7wvs8ZbP4&ab_channel=%EB%A9%94%ED%83%80%EC%BD%94%EB%93%9CM4회차 RNN, LSTM,GRU, se
[논문 리뷰] SentencePiece: A simple and language independent subword tokenizer and detokenizer for Neural Text Processing
https://arxiv.org/pdf/1808.06226.pdf https://github.com/google/sentencepiece BEiT에서 언어 토큰화 툴로 사용한 SentencePiece이다. python에 간단히 pip로 다운받아 사용가능 하다. Ab
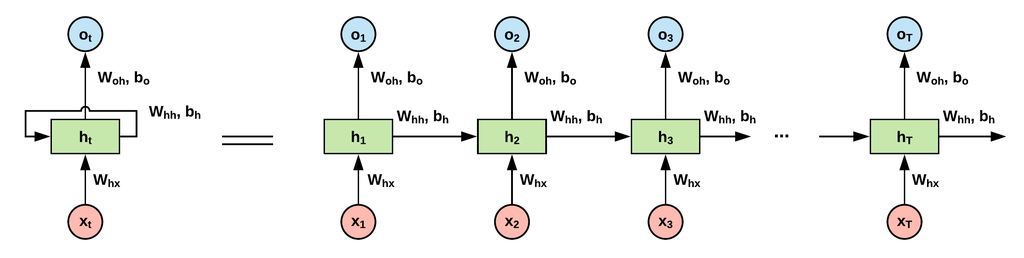
딥러닝을 이용한 자연어처리 입문 7시간 완성(3)
딥러닝을 이용한 자연어처리 입문 7시간 완성 - 메타코드Mhttps://www.youtube.com/watch?v=Rf7wvs8ZbP4&ab_channel=%EB%A9%94%ED%83%80%EC%BD%94%EB%93%9CM3회차는 지금까지 배웠던 전처리 실습입
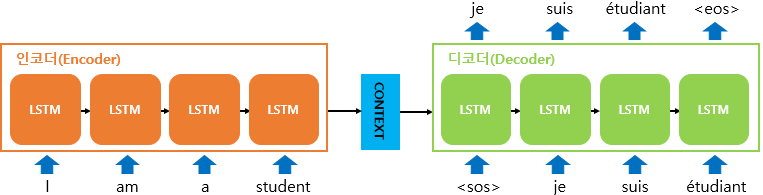
SEQ2SEQ, Attention
Transformer에 대해 알아보자대부분의 내용, 이미지는Seq2Seq: https://wikidocs.net/24996Attention: https://wikidocs.net/22893에서 참고하였습니다.일단 그 시초인 Seq2Seq에서 출발해 보